- The paper introduces an intent-centric framework that leverages LLMs and multi-task fine-tuning to enhance recommendation quality in industrial-scale systems.
- It employs hierarchical sequence compression, curriculum learning, and a tri-tower retrieval design to efficiently manage ultra-long user histories and semantic alignment.
- Empirical results on Taobao show significant improvements in user engagement, fairness, and key performance metrics compared to traditional log-fitting approaches.
RecGPT: An Intent-Centric LLM Framework for Industrial-Scale Recommendation
Introduction and Motivation
RecGPT introduces a paradigm shift in industrial recommender systems by centering the recommendation pipeline on explicit user intent, leveraging LLMs for end-to-end reasoning across user interest mining, item retrieval, and explanation generation. The framework is motivated by the limitations of traditional log-fitting approaches, which overfit to historical co-occurrence patterns, reinforce filter bubbles, and exacerbate long-tail and Matthew effects. RecGPT addresses these issues by integrating LLMs with domain-specific alignment and a human-LLM cooperative judge system, enabling scalable, interpretable, and intent-driven recommendations in a real-world e-commerce environment (Taobao).
System Architecture and Workflow
RecGPT operationalizes an LLM-driven closed-loop pipeline comprising four core modules: user interest mining, item tag prediction, item retrieval, and recommendation explanation generation.
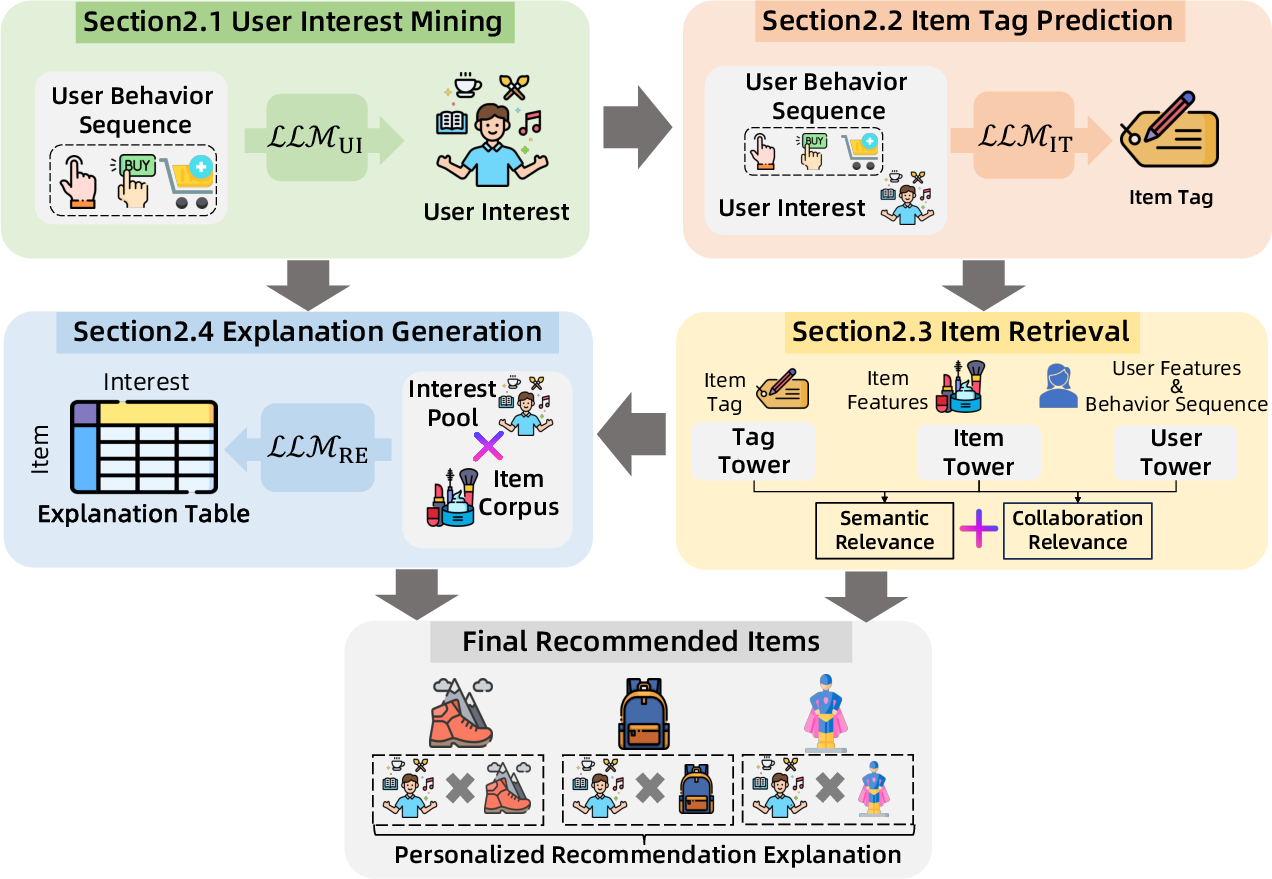
Figure 1: The overall workflow of RecGPT, showing the integration of LLMs for user interest mining, item tag prediction, and explanation generation.
User Interest Mining
The user interest mining module employs a dedicated LLM (LLMUI) to process lifelong, multi-behavior user sequences. To address context window limitations and domain knowledge gaps, RecGPT introduces a hierarchical behavioral sequence compression pipeline:
- Reliable Behavior Extraction: Filters for high-signal behaviors (e.g., purchases, add-to-cart, detailed views, search queries), excluding noisy clicks.
- Hierarchical Compression: Compresses item-level and sequence-level data, partitioning by time and aggregating by behavior and item, reducing sequence length while preserving temporal and co-occurrence structure.
This process enables 98% of user sequences to fit within a 128k-token context window, with a 29% improvement in inference efficiency.
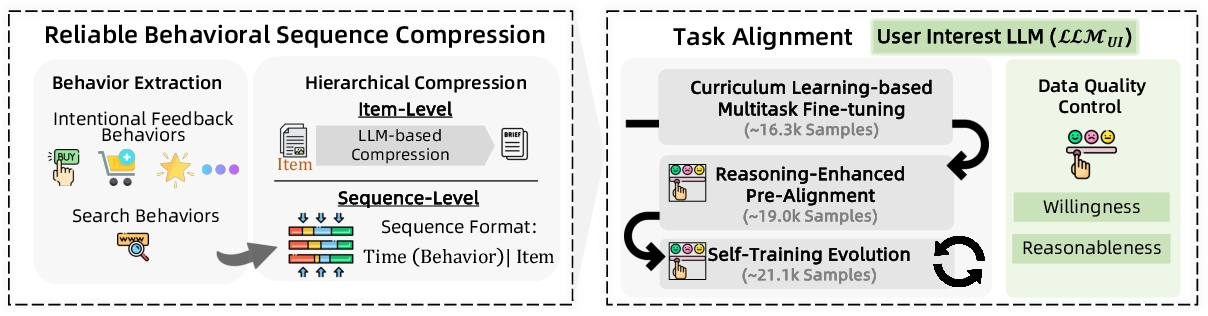
Figure 2: Compression and alignment in user interest mining, including behavior extraction and hierarchical compression.
A multi-stage alignment framework is used for LLMUI:
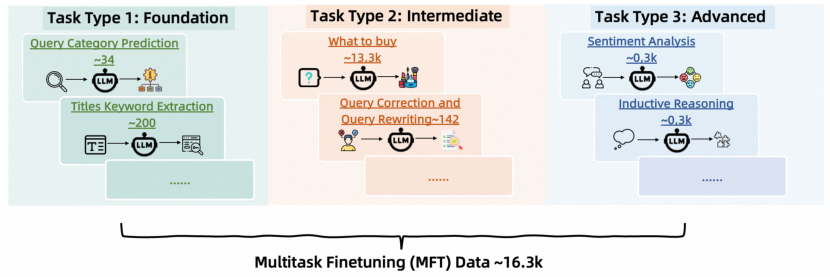
- Curriculum Learning-based Multi-task Fine-tuning: 16 subtasks, topologically sorted by difficulty, build foundational and reasoning skills.
- Reasoning-Enhanced Pre-alignment: Knowledge distillation from a strong teacher LLM (DeepSeek-R1) with manual curation.
- Self-Training Evolution: Iterative self-generated data, filtered by a human-LLM judge, further refines the model.
Prompt engineering incorporates chain-of-thought (CoT) reasoning, and data quality control enforces criteria on willingness and behavioral correlation to mitigate hallucination and spurious interests.
Item Tag Prediction
The item tag prediction module (LLMIT) generates fine-grained, semantically rich item tags aligned with inferred user interests. The alignment process mirrors that of user interest mining, with additional constraints in prompt design to enforce:
- Interest consistency
- Diversity (minimum 50 tags)
- Semantic precision
- Temporal freshness
- Seasonal relevance
Tags are generated as (modifier + core-word) triplets, each linked to a user interest and rationale. Data quality control enforces relevance, consistency, specificity, and validity.
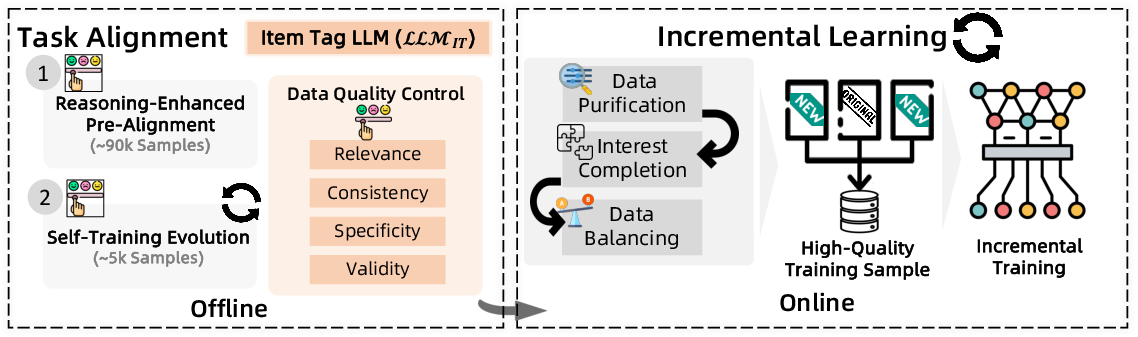
Figure 3: Two-stage alignment and incremental learning for item tag prediction, with data cleaning and adaptation to online feedback.
A bi-weekly incremental learning strategy adapts LLMIT to evolving user and item distributions, using data purification, interest completion, and data balancing to construct high-quality, balanced training sets. This yields a 1.05% improvement in HR@30 for tag prediction accuracy.
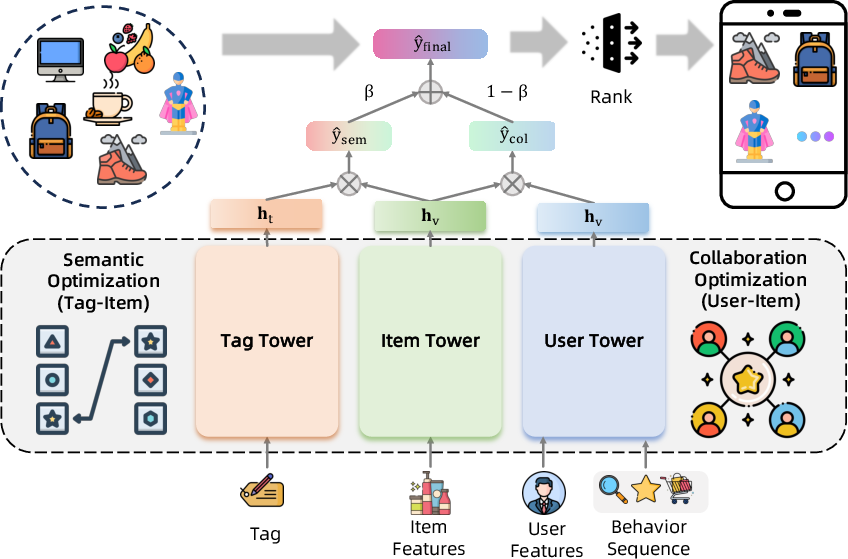
User-Item-Tag Retrieval
RecGPT introduces a tri-tower retrieval architecture, jointly optimizing user, item, and tag representations:
Retrieval scores are computed as:
- Collaborative: y^col=huThv
- Semantic: y^sem=htThv
Optimization combines collaborative and semantic contrastive losses, with category-aware regularization. Online inference fuses user and tag tower outputs via a tunable β parameter, enabling dynamic control over semantic vs. collaborative emphasis.
Recommendation Explanation Generation
A dedicated LLM (LLMRE) generates personalized, context-aware explanations for each recommendation, enhancing transparency and user trust. The alignment process includes reasoning-enhanced pre-alignment and self-training, with prompt engineering enforcing relevance, factuality, clarity, and safety.
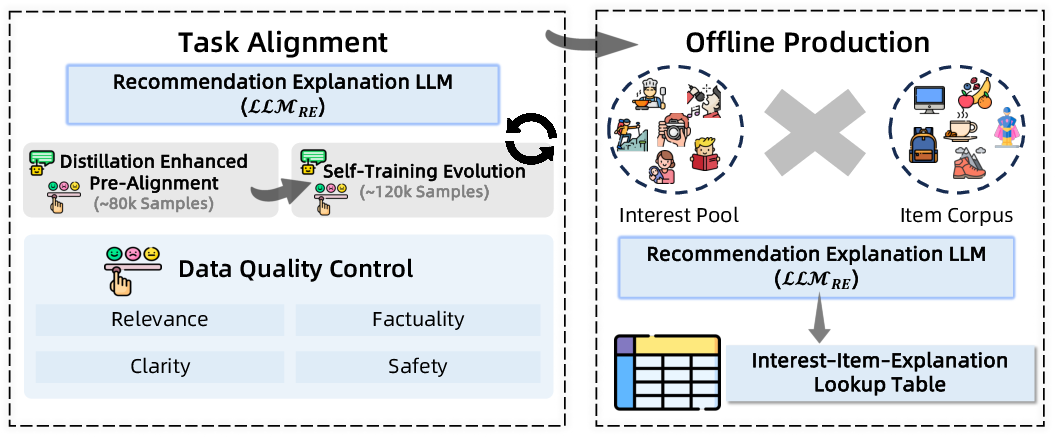
Figure 5: Task alignment and offline production for recommendation explanation generation.
To meet latency constraints, explanations are precomputed offline for interest-item pairs and served via a lookup table at inference time.
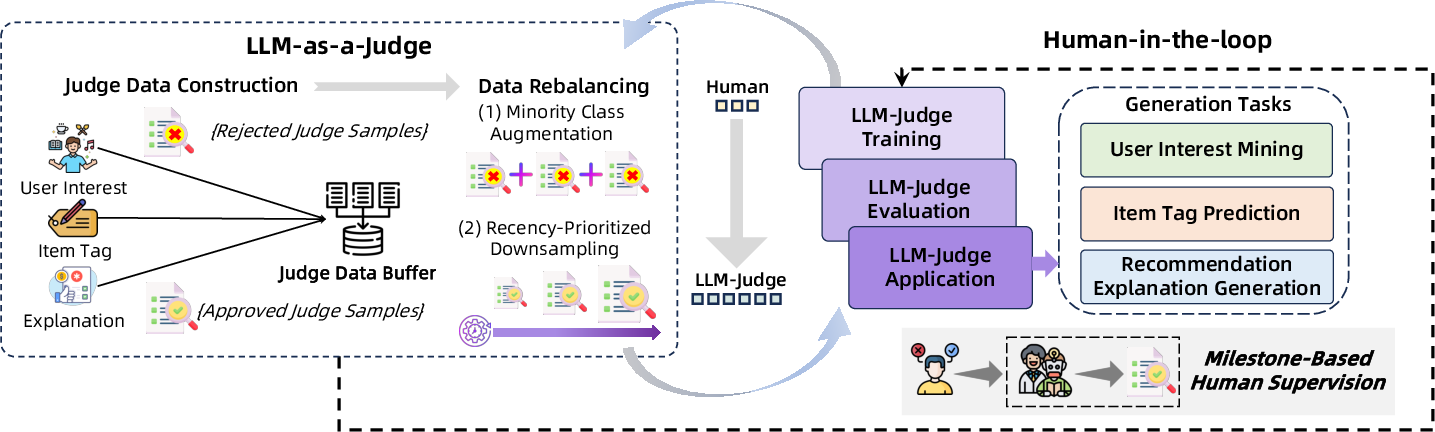
Human-LLM Cooperative Judge System
To ensure data and model quality at scale, RecGPT employs a hybrid human-LLM judge system:
This system enables efficient, reliable evaluation and curation across user interest mining, item tag prediction, and explanation generation, with strong alignment to human standards.
Empirical Results and Analysis
Online A/B Testing
RecGPT was deployed in the "Guess What You Like" scenario on Taobao, serving 1% of top active users. Key findings:
- User Experience: CICD +6.96%, DT +4.82%, EICD +0.11%
- Platform Metrics: CTR +6.33%, IPV +9.47%, DCAU +3.72%, ATC +3.91%
- Merchant Fairness: More uniform CTR and PVR across item popularity groups, mitigating the Matthew effect and improving long-tail exposure
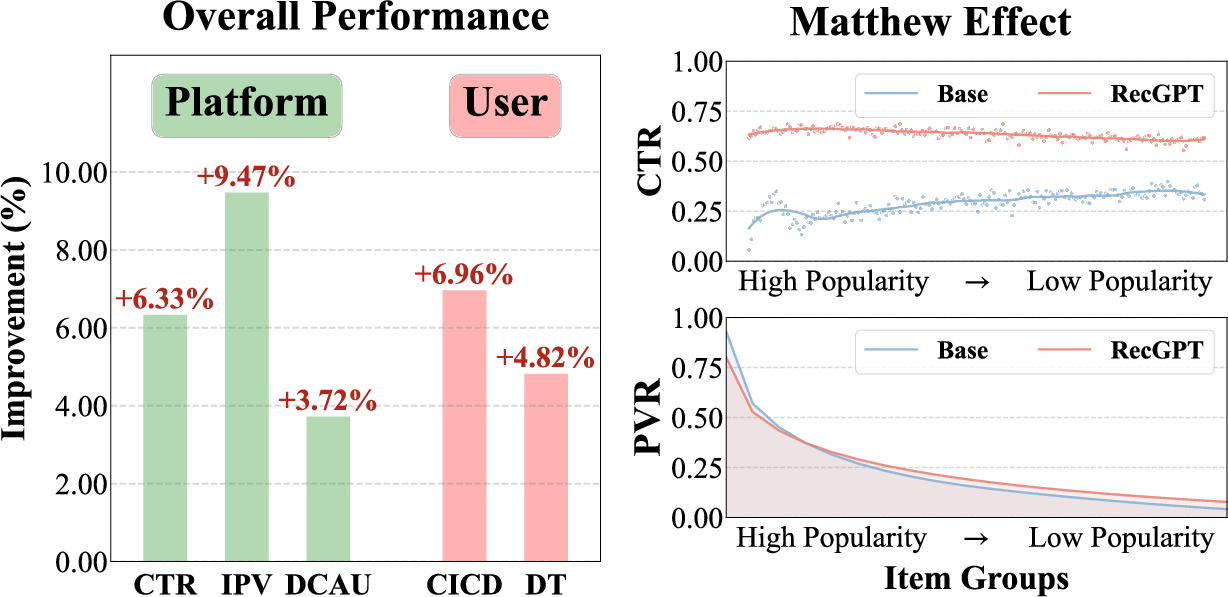
Figure 7: Online performance of RecGPT vs. baseline, showing improvements in CTR, IPV, DCAU, CICD, and DT, and more equitable performance across item popularity groups.
Human and LLM-Judge Evaluation
Fine-tuned LLM judges (Qwen3-Judge-SFT) achieve high agreement with human annotators across all tasks (e.g., 93.08% accuracy for item tag prediction, 89.76% for explanation generation), enabling scalable, reliable evaluation.
Case Studies

Figure 8: Case studies demonstrating RecGPT's ability to mine nuanced interests and generate contextually relevant recommendations and explanations.
User Experience Investigation
A user study with 500 participants showed a reduction in perceived recommendation redundancy (from 37.1% to 36.2%), with the effect more pronounced in top recommendation slots and when controlling for ad interference.
Implementation Considerations
- Model Efficiency: FP8 quantization, KV caching, and MoE architectures (e.g., TBStars-42B-A3.5B) enable scalable deployment with only 3.5B active parameters per inference.
- Sequence Handling: Hierarchical compression and context engineering are critical for fitting ultra-long user histories within LLM context windows.
- Incremental Learning: Regular online adaptation is necessary to track evolving user and item distributions.
- Evaluation: Automated LLM-judge systems, aligned with human standards, are essential for scalable, high-quality curation and monitoring.
Limitations and Future Directions
Conclusion
RecGPT demonstrates that intent-centric, LLM-driven recommendation pipelines can be deployed at industrial scale, yielding measurable improvements in user experience, platform engagement, and merchant fairness. The architecture's modularity, interpretability, and adaptability—enabled by systematic alignment, efficient model design, and scalable evaluation—provide a robust foundation for future research and deployment of LLM-based recommender systems. The framework's success in a billion-scale real-world environment validates the practical viability of LLMs-for-RS and sets a new standard for intent-driven, explainable, and fair recommendation in dynamic, large-scale ecosystems.