Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
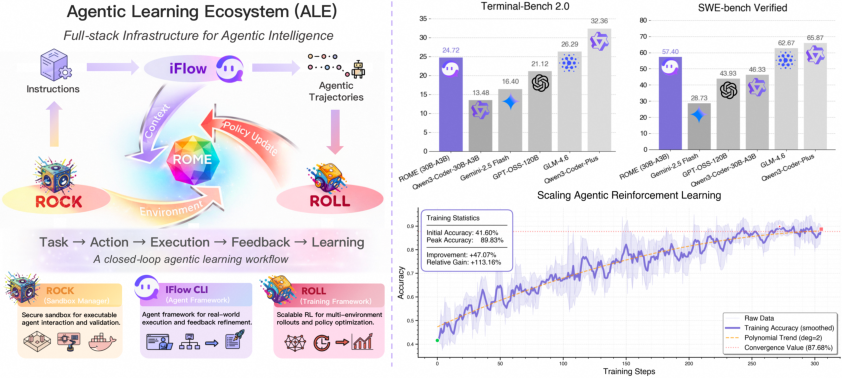
Abstract: Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about building smarter AI “agents” that can work through real tasks step by step, not just answer a single question. The authors created an open system called the Agentic Learning Ecosystem (ALE) that helps train, test, and deploy these agents. Using ALE, they built an agent model named ROME and showed it works well on tough, real-world tasks like writing and fixing code in software projects.
Goals: What the researchers wanted to do
- Make it easier and safer to train AI agents that act over many steps, try tools, and correct themselves.
- Create a full “workshop” for agents: a training engine, safe practice environments, and a practical interface to use tools and keep track of progress.
- Design better training data and a better learning method so agents can handle long, multi-turn tasks without getting confused.
- Test agents fairly and thoroughly using strong benchmarks.
Approach: How they built and trained the agents
Think of training an agent like teaching a student in a well-run lab:
- The “lab” consists of three main parts:
- ROLL: This is the training brain. It uses reinforcement learning (RL), which is like learning by trial and error—try something, see what happens, and get a score to improve next time. ROLL makes this fast and efficient, even for long tasks with many steps.
- ROCK: This is the safe practice room (a sandbox). Agents can run code, use tools, and interact with real environments without breaking anything outside. It keeps tasks isolated, schedules many tasks at once, and checks safety.
- iFlow CLI: This is the agent’s planner and interface. It organizes the agent’s “context” (what the agent knows so far), chooses tools, remembers progress, and keeps the work neat and consistent between training and real use.
- Training pipeline (the learning loop):
- The agent acts in the environment (like pressing buttons in a game or running a command in a terminal).
- The environment answers (like showing game feedback or test results).
- The agent gets a reward (a score) based on how well it did.
- The model updates its “brain” to do better next time.
- To save time, they overlap different steps and share GPUs (computers with lots of processing power) smartly so nothing sits idle.
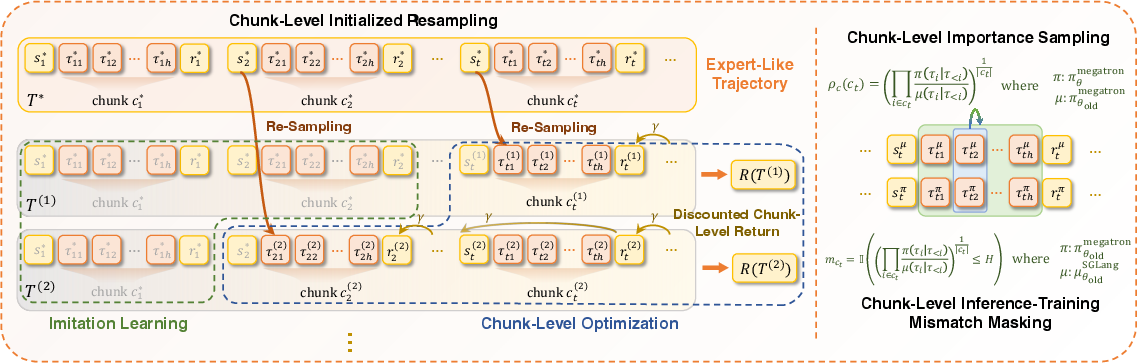
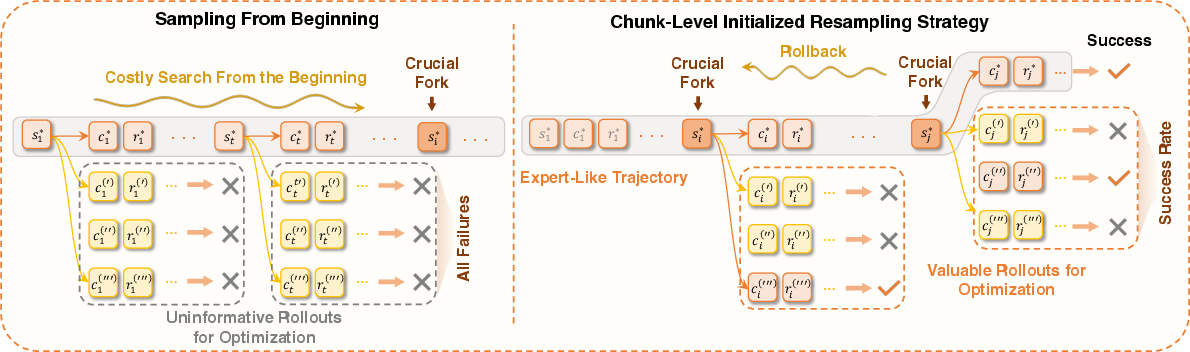
- A new learning trick called IPA (Interaction-Perceptive Agentic Policy Optimization):
- Instead of grading the agent letter by letter (token-by-token), they grade it by meaningful chunks (like sentences or actions). This makes learning more stable for long tasks because the agent gets credit for full ideas or steps, not tiny pieces.
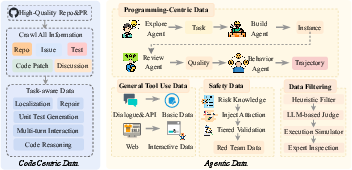
- Better data:
- Two layers of training data:
- Basic “code-centric” data: lots of high-quality code and project context to teach the agent to understand and write real software.
- Agentic data: multi-turn “trajectories” where the agent plans, acts, sees feedback (like failing tests), and fixes things. These are recorded in real environments with safety checks, so the agent learns from realistic, verifiable situations.
- Fair testing:
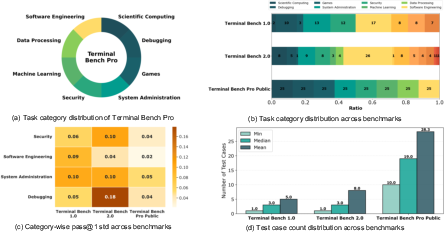
- They use existing benchmarks and introduce Terminal Bench Pro, designed to be bigger, cover more types of tasks, and avoid contamination (making sure the test isn’t too similar to the training material).
Findings: What they discovered
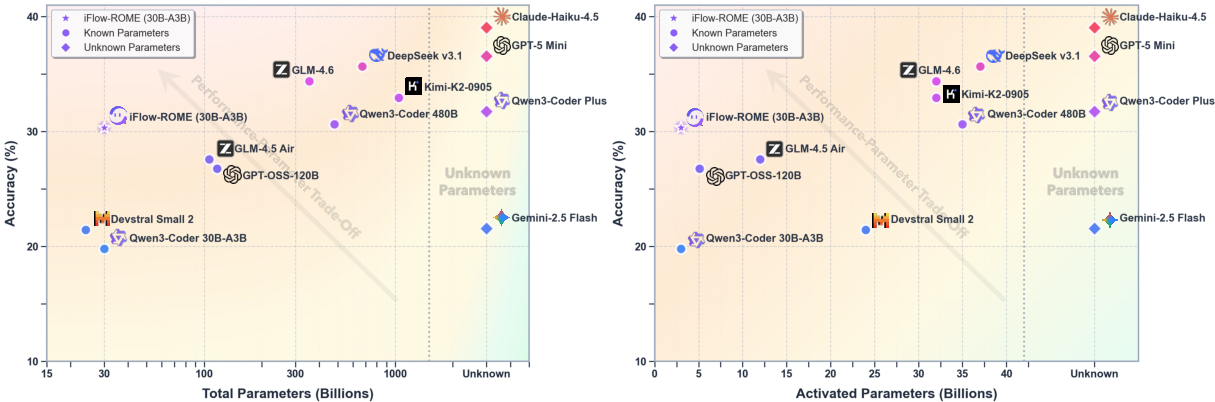
- ROME, trained within ALE, performs strongly on tough agent tasks:
- About 57.4% accuracy on SWE-bench Verified (fixing software bugs with tests).
- About 24.7% on Terminal-Bench v2.0 (complex terminal tasks).
- These results beat similar-size models and come close to some much larger ones (over 100 billion parameters).
- ROME works well across domains and remains stable even on the stricter Terminal Bench Pro.
- The whole system (ALE) runs in production—meaning it’s not just a lab demo; it’s used for real work. That shows the ecosystem is practical and reliable.
Impact: Why this matters and what could come next
This work helps push AI beyond “one-shot answers” into trustworthy, multi-step problem solving. With ALE, people can build and improve agent models more easily, safely, and consistently. That means better AI helpers for software engineering today and, in the future, for other complex fields like data analysis, scientific research, or app development. The paper also encourages the community to focus on solid training pipelines, safe execution environments, and fair benchmarks—key building blocks for the next generation of capable, general-purpose AI agents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper—framed to be directly actionable for future research.
- Formalization of the IPA algorithm: precise mathematical specification (objective, policy update rule), chunk segmentation criteria, off/on-policy details, variance reduction strategies, and theoretical guarantees (e.g., convergence, stability) are not provided.
- Automatic chunking methodology: how “semantic interaction chunks” are detected/segmented from multi-turn logs, robustness to noisy tool outputs, cross-domain generality, computational overhead, and failure modes of chunk boundaries are unspecified.
- Reward design and shaping: the paper does not detail per-environment reward functions, handling of sparse/delayed rewards, negative rewards for harmful actions, or ablations comparing different reward designs.
- Bias from asynchronous training: discarding samples that violate staleness constraints may introduce sampling bias—no analysis, diagnostics, or mitigation strategies are presented.
- Sensitivity analysis of asynchronous ratio and multiplexing: empirical studies quantifying how staleness bounds and dynamic GPU partitioning affect sample quality, learning curves, and final performance are missing.
- Data composition protocols: concrete dataset statistics (size per source/task, language distribution, tools covered), synthetic vs human data proportions, deduplication, contamination checks, and data quality filters (including acceptance/rejection rates) are not reported.
- Safety/security verification of trajectories: the criteria, tooling, and measurable outcomes for “rigorous security, safety, and validity verification” are not described or benchmarked; adversarial and red-team evaluations are absent.
- Licensing and compliance of GitHub data: repository license handling, PR/Issue content licensing, removal of sensitive information (PII/secrets), and downstream usage constraints are not addressed.
- Contamination control details: Terminal Bench Pro’s contamination detection methodology, guardrails, audit processes, and effectiveness are not specified; contamination risks for SWE-bench Verified and other benchmarks are not discussed.
- Benchmark design and reporting: Terminal Bench Pro’s task taxonomy, scale, domain coverage, scoring protocol, time budgets, partial credit policy, seeds, and variance reporting (confidence intervals) are not provided.
- Generalization beyond code-centric tasks: despite claims of broader applicability (GUI, mobile, travel, tools), there is no rigorous evaluation or datasets for non-code agentic workflows or multimodal interactions.
- Multi-agent training and coordination: ROCK supports multi-agent environments, but the paper adopts a single-agent iFlow design; conditions under which multi-agent collaboration helps, coordination protocols, and empirical comparisons remain unexplored.
- Deployment reliability and safety: production metrics like task success rate, mean time to failure, latency distributions, tool-call error rates, near-miss/destructive action interception rates, and postmortem analyses are not reported.
- Robustness to nondeterminism: handling flaky tests, network variability, non-deterministic tools, caching/pinning strategies, and their impact on training/evaluation are not discussed.
- OOD adaptation and continual learning: mechanisms and results for handling distribution shift (new tools, evolving environments), catastrophic forgetting, and integrating user feedback (RLHF/RLAIF) are not presented.
- Memory and context management effects: the performance impact and privacy implications of iFlow’s persistent memory (todo files, project/user/global state), retention policies, and retrieval quality are not evaluated.
- Tool integration reliability: failure detection and recovery for tool-call errors, retries/backoff strategies, sandbox timeouts, and policies for destructive operations beyond “hooks” lack quantitative assessment.
- Model architecture and resource profile: ROME’s exact parameter count, MoE configuration (experts, gating), inference/training compute (GPU-hours), throughput, memory footprint, quantization, and energy/carbon costs are not disclosed.
- Scaling laws and cost–performance: no analysis of model/data/compute scaling behavior, marginal gains from more trajectories, and trade-offs between RL vs SFT vs CPT is provided.
- Comparative baselines and significance: head-to-head comparisons with similarly sized open models under identical settings, statistical significance tests, and detailed ablations (e.g., removing IPA, removing context engineering) are missing.
- Reward proxy correctness: reliance on test suites as rewards may miss spec adherence or induce overfitting; methods to detect spurious pass cases, side effects, and broader functional correctness are not discussed.
- Security of ModelProxyService: the threat model, isolation guarantees, prevention of prompt/context leakage, cross-tenant risks, and attack surfaces (e.g., proxy manipulation, API misuse) are not analyzed.
- EnvHub reproducibility: image provenance, pinned dependencies, build instructions, reproducibility checks, and versioning for long-term stability are not documented.
- Data and benchmark availability: clarity on the public release of ALE components, EnvHub images, Terminal Bench Pro, datasets (and their licenses), and step-by-step reproducibility instructions is lacking.
- Human-in-the-loop evaluation: protocols for measuring user satisfaction, minimal clarification question quality, interaction ergonomics, and integrating human feedback into training are not described.
- Multilingual performance: although multilingual data is mentioned, per-language performance, code-language breakdowns, and cross-lingual transfer evaluations are not reported.
- Failure mode analysis: systematic taxonomy of agent failures (planning, tool selection, execution, adaptation), root cause analyses, and targeted mitigation strategies are absent.
- Ethical and governance considerations: policies for safe agent operation in real environments, compliance requirements, guardrails for harmful tasks, and governance frameworks are not articulated.
Practical Applications
Immediate Applications
Below are concrete applications that can be deployed now, leveraging the paper’s systems (ROLL, ROCK, iFlow CLI), model (ROME), datasets/protocols, and benchmarks.
- Software CI/CD Sandboxed Agents (software, security, DevOps)
- Use ROCK to spin up per-PR sandbox environments that run builds/tests, reproduce issues, and validate proposed fixes. Pair with iFlow CLI to orchestrate a “PR Fix” workflow and ROME to propose diffs that pass tests.
- Potential products/workflows: “CI Agent” that runs in GitHub/GitLab; ephemeral PR sandboxes with egress policies; auto-generated fix proposals with test-backed validation.
- Assumptions/dependencies: Reliable test suites; curated sandbox images per stack; strong egress/network policies; human-in-the-loop code review.
- Auto bug triage and patch suggestion bot (software)
- Combine iFlow CLI’s context engineering with ROCK to parse issue threads/PRs, run failing tests, localize faults, and suggest patches using ROME; integrate hooks to prevent destructive actions.
- Potential products/workflows: “Triage Copilot” for issue routing and first-pass patches; test-log interpretation workflow.
- Assumptions/dependencies: Sufficient logs/tests; repo access; enforcement of safe commands via iFlow hooks.
- Continuous agent post-training with ROLL (software infrastructure)
- Use ROLL’s fine-grained rollout, asynchronous training, and GPU multiplexing to fine-tune internal agent models on enterprise trajectories, improving long-horizon reliability at lower cost.
- Potential products/workflows: “AgentOps” training pipeline; continuous learning loop from production traces.
- Assumptions/dependencies: RL reward design aligned with business metrics; GPU availability; data governance for user traces.
- Agent-native consistency testing (QA/reliability)
- Leverage ROCK’s ModelProxyService to ensure identical context handling between training and deployment (iFlow CLI), catching regressions caused by prompt/context drift.
- Potential products/workflows: “Prompt/Context Regression Suite” that replays production contexts during training/eval.
- Assumptions/dependencies: Stable iFlow configurations; versioned prompts/tools; logging for replay.
- Benchmarking and vendor evaluation with Terminal Bench Pro (enterprise procurement, policy)
- Adopt Terminal Bench Pro for contamination-controlled model evaluation; include SWE-bench Verified runs for software agent capability audits.
- Potential products/workflows: Internal model scorecards; third-party vendor bake-offs; compliance-aligned evaluation gates.
- Assumptions/dependencies: Access to benchmark images; reproducible environment provisioning; standardized scoring.
- IDE-integrated single-agent workflows (developer productivity, daily life)
- Deploy iFlow CLI as an IDE plugin to run structured workflows (e.g., code search → implement → test → refine), using persistent memory and safe hooks to reduce destructive commands.
- Potential products/workflows: “Dev Loop” workflow; todo-file memory; context compression for limited context windows.
- Assumptions/dependencies: Stable local dev environments; permissions to invoke tools; user supervision.
- Safe trajectory synthesis for training (industry, academia)
- Use ROCK to generate verified, tool-grounded trajectories with built-in safety/security/validity checks; seed ROLL post-training and domain-specific SFT.
- Potential products/workflows: Dataset generation pipelines; trajectory QA dashboards; reproducible EnvHub images.
- Assumptions/dependencies: Validation harnesses; license-compliant data; contamination controls.
- AIOps runbook automation in sandboxes (IT operations)
- iFlow CLI triggers diagnosis/remediation steps for incidents inside ROCK sandboxes; ROLL fine-tunes behavior from incident trajectories.
- Potential products/workflows: “Runbook Agent” that executes scripts, analyzes logs, and proposes mitigations safely.
- Assumptions/dependencies: Accurate runbooks; constrained network egress; escalation thresholds.
- Secure RAG/tooling via MCP integrations (enterprise apps)
- Extend iFlow CLI with MCP tools (e.g., internal APIs, databases) and context retrieval, enabling agents to perform cross-system tasks within a controlled loop.
- Potential products/workflows: “Ops Copilot” for ticketing/data lookups; “Compliance Checker” using static analyzers/linters.
- Assumptions/dependencies: Tool APIs; access control; audit trails.
- Courseware and labs for agentic systems (academia, education)
- Use ROCK to deliver identical, reproducible agent environments; teach context engineering (iFlow CLI) and RL with ROLL/IPA on long-horizon tasks.
- Potential products/workflows: Lab-in-a-box images; GEM API–compatible assignments; graded benchmarks.
- Assumptions/dependencies: Institutional compute; standardized course images; student isolation policies.
- Security research sandboxes (security)
- Apply ROCK’s fault isolation and egress controls to study security behavior of code-executing agents (e.g., dependency-conflict resolution, unsafe command detection via iFlow hooks).
- Potential products/workflows: Safe red/blue team drills; automated SBOM/licensing checks.
- Assumptions/dependencies: Hardened images; logging; explicit guardrails against weaponization.
- Research on long-horizon RL with IPA (academia)
- Adopt IPA’s chunk-level credit assignment in ROLL to stabilize training on multi-turn tasks (e.g., planning, tool use, long-context code changes).
- Potential products/workflows: Open experiments comparing token-vs-chunk credit; ablations on horizon length.
- Assumptions/dependencies: Implementation availability; compute budgets; consistent reward shaping.
Long-Term Applications
The following opportunities are feasible but require additional research, scale, reliability, or ecosystem development.
- Autonomous repository maintenance and release engineering (software)
- Agents perform issue triage, dependency upgrades, flaky-test repair, changelog generation, and release cuts end-to-end using iFlow workflows and ROCK validation loops.
- Potential products/workflows: “Release Agent” with staged gates; multi-repo maintenance bots.
- Assumptions/dependencies: Higher model reliability than current ROME; policy gating; organizational change management.
- Self-healing infrastructure (AIOps)
- Agents monitor systems, run remediations in ROCK sandboxes, validate effects, and promote fixes to production via controlled gates.
- Potential products/workflows: Closed-loop incident remediation; canary + rollback integrations.
- Assumptions/dependencies: Real-time telemetry; formal safety checks; robust rollback; liability frameworks.
- Regulated-domain agentic workflows (healthcare, finance, gov)
- Configure iFlow CLI with compliance-aware prompts/workflows; ROCK enforces strict data egress and audit logging; IPA/ROLL fine-tunes on domain trajectories.
- Potential products/workflows: EHR form handling assistants; regulatory filing preparation; KYC/AML review support.
- Assumptions/dependencies: Domain datasets with consent; privacy-preserving sandboxes; auditable decision logs; regulatory approval.
- Automated policy and compliance auditing (policy, governance)
- Agents codify and check policies across code, infra, and data flows; use Terminal Bench–style suites for adherence verification.
- Potential products/workflows: “Compliance Copilot” with continuously updated rulebases; policy-to-test transcompilation.
- Assumptions/dependencies: Machine-readable policies; standardized benchmarks; oversight procedures.
- Multimodal and embodied extensions of IPA (robotics, manufacturing)
- Extend chunk-level credit assignment to sensorimotor “interaction chunks” for long-horizon tasks (assembly, maintenance).
- Potential products/workflows: IPA-driven control policies trained in sim, evaluated in ROCK-like sim sandboxes before real-world deployment.
- Assumptions/dependencies: Multimodal models; sim-to-real transfer; safety certifications.
- Scientific automation pipelines (R&D)
- Agents design, run, and iterate on computational experiments within ROCK, logging provenance and automatically generating reports.
- Potential products/workflows: “AutoLab” for hypothesis testing and reproducible research packages.
- Assumptions/dependencies: Domain toolchains; dataset access; reproducibility standards; compute governance.
- Sector-specific benchmark suites and certifications (policy, standardization)
- Terminal Bench Pro inspires certified, contamination-controlled suites for healthcare coding, financial reporting, or embedded systems.
- Potential products/workflows: Third-party certifications; public scorecards; procurement standards.
- Assumptions/dependencies: Curated datasets; environment licensing; neutral governance.
- Energy grid and industrial ops planning (energy, industrial engineering)
- Agents run simulators in ROCK to propose operations plans, sensitivity analyses, and contingency strategies; ROLL tunes policy from operator feedback.
- Potential products/workflows: “Grid Planner” sandbox; schedule optimization workflows.
- Assumptions/dependencies: Simulator integrations; accurate models; strict safety/oversight.
- Personal OS-level agent with strong safety (daily life)
- An iFlow-driven assistant that manages files, shell commands, and local apps with hooks to block destructive actions and ROCK-like local sandboxes for risky tasks.
- Potential products/workflows: “Desktop Agent” with memory, retrieval, and safe execution mode.
- Assumptions/dependencies: OS integrations; local sandboxing; privacy controls; on-device or private inference.
- Marketplace of reusable agent workflows/specs (software, education)
- Share, version, and certify iFlow Workflows (Specs) for domains (mobile app dev, data engineering, bioinformatics).
- Potential products/workflows: Spec registries; reputation/verification systems; enterprise curation.
- Assumptions/dependencies: Community adoption; IP/licensing; compatibility/versioning guarantees.
Glossary
- Admin control plane: The centralized orchestration layer that governs servers, provisioning, and scheduling in a distributed system. "the server tier is governed by the Admin control plane, which serves as the orchestration engine: it provisions sandboxed environments, performs admission control, and manages cluster-wide resource scheduling and allocation."
- admission control: A mechanism that decides whether to accept or reject requests or jobs based on policies and resource availability. "performs admission control"
- agent LLM: A LLM designed to act autonomously in multi-turn environments, taking actions and adapting based on feedback. "During rollout, the agent LLM interacts with the environment by emitting tokens that represent actions."
- Agent Native Mode: A deployment and training consistency mode where the agent’s native context management is preserved by proxying model calls through the environment. "The agent native mode connects the agentic RL training with the ROCK."
- Agentic Continual Pre-training (CPT): A pre-training phase tailored for agent models that extends learning using agent-specific data and settings. "integrating Agentic Continual Pre-training (CPT), Supervised Fine-tuning (SFT), and Interaction-Perceptive Agentic Policy Optimization(IPA) RL algorithm"
- agentic crafting: A paradigm where LLMs plan, act, observe outcomes, and iteratively refine artifacts in real environments over multiple turns. "Agentic crafting, unlike one-shot response generation for simple tasks, requires LLMs to operate in real-world environments over multiple turns—taking actions, observing outcomes, and iteratively refining artifacts until complex requirements are satisfied."
- agentic ecosystem: An integrated infrastructure that unifies data, training, and deployment for agent-based systems. "the absence of a scalable, end-to-end agentic ecosystem."
- agentic RL: Reinforcement learning tailored for agent workflows and multi-turn interactions in realistic environments. "Agentic RL training pipeline."
- asynchronous ratio: A bound controlling how stale a sample’s generating policy version can be relative to the current training policy during asynchronous training. "introduces asynchronous ratio to configure the per-sample staleness during the asynchronous training."
- asynchronous training: A training pipeline where rollout and optimization proceed concurrently, trading off staleness and throughput. "ROLL’s asynchronous training can effectively balance training accuracy and throughput."
- CI/CD-style environment delivery: Delivering and updating environments using continuous integration/continuous deployment practices. "tooling for debugging and CI/CD-style environment delivery."
- chunk-aware credit assignment: Assigning RL credit to semantically meaningful interaction segments rather than individual tokens. "supporting multi-environment rollouts, chunk-aware credit assignment, and stable policy updates for long-horizon agentic tasks."
- closed-loop execution: An execution model where agents act, receive feedback, and update behavior within the same controlled environment. "environment-driven trajectory generation and validation for data synthesis and closed-loop execution during training."
- Cluster abstraction: A programming interface that represents and controls a distributed cluster with heterogeneous workers. "ROLL exposes a Cluster abstraction and adopts a single-controller programming model."
- contamination control: Measures to prevent training data leakage into evaluation benchmarks for fair assessment. "which enforces stricter contamination control and improved domain balance"
- context compression: Techniques to condense conversation or state into a smaller prompt while retaining salient information. "The Compress performs context compression for limited prompt budgets."
- context engineering: Systematic structuring of prompts, tools, and workflows to supply precise, high-quality context to agents. "iFlow CLI is an agent framework that enables configurable and efficient context engineering for environment interaction."
- controller: The coordinating component that manages worker roles, deployment, and lifecycle in distributed training. "The controller coordinates heterogeneous workers and handles corresponding deployment and lifecycle management"
- credit assignment: RL process of attributing rewards to actions or decisions to guide learning. "assigns credit over semantic interaction chunks rather than individual tokens"
- data composition: The design and synthesis of datasets from multiple sources and protocols to train agents. "we curate a suite of data composition protocols"
- deterministic builds: Reproducible compile and test processes that yield the same results given the same inputs. "through deterministic builds and tests"
- dynamic GPU partition: Time-varying allocation of GPUs between rollout and training to reduce resource bubbles and improve utilization. "we introduce time-division multiplexing with a dynamic GPU partition between rollout and training."
- egress policies: Rules that control outbound network traffic from sandboxed environments for security. "and enforces egress policies."
- EnvHub: A centralized registry of environment images to enable reproducible provisioning and fast startup. "ROCK provides EnvHub, a centralized registry for environment images that enables reproducible provisioning and faster cold starts."
- environment execution engine: A system that manages and runs sandboxed environments for agent interaction and data generation. "ROCK is the environment execution engine that provides secure, sandboxed environments for agentic interaction."
- GEM API: A standardized API for RL environments enabling make, reset, step, and close semantics. "ROCK exposes two primary API services for programmatic control, namely the Sandbox API and the GEM API."
- GEM RL environment semantics: The standard interaction semantics for RL environments defined by the GEM protocol. "aligned with standard GEM RL environment semantics."
- inference service: A backend that processes model requests and returns generated outputs during training or deployment. "The proxy then forwards these requests to the appropriate inference service — be it ROLL inference workers during training or an external API (e.g., GPT, Gemini) during deployment."
- Interaction-Perceptive Agentic Policy Optimization (IPA): An RL algorithm that optimizes policies over semantic interaction chunks to improve long-horizon stability. "we propose Interaction-Perceptive Agentic Policy Optimization (IPA), a novel algorithm that optimizes policies over semantic interaction chunks"
- iFlow CLI: A command-line agent framework for context management, tool orchestration, and user interfaces for agent workflows. "iFlow CLI is the agent framework that manages the context for environment interactions and delivers an end-to-end agentic crafting experience to complete a given workflow."
- long-horizon: Tasks or training regimes involving long sequences and delayed rewards, challenging stability. "stable policy updates for long-horizon agentic tasks."
- long-tail latency distribution: A performance pattern where a small fraction of tasks exhibit very long completion times, dominating resource usage. "Rollout typically exhibits a pronounced long-tail latency distribution"
- Model Context Protocol (MCP): A protocol to integrate tools and external capabilities into LLM contexts. "via the Model Context Protocol (MCP)."
- ModelProxyService: A service within ROCK that intercepts and forwards LLM requests, preserving native agent context. "we have implemented a ModelProxyService within the ROCK environment."
- orchestrator-worker architecture: A system design where a central orchestrator manages workers that execute tasks. "iFlow CLI adopts an orchestrator-worker architecture built around a single-agent design principle"
- pinned environment: A fixed, reproducible environment specification attached to a task instance for execution and evaluation. "embeds requirements in pinned, executable environments"
- policy optimization: The RL process of improving a policy using collected trajectories and rewards. "we ... propose a novel policy optimization algorithm IPA"
- policy version: An identifier for the current policy used to generate trajectories, tracked to manage staleness. "gap in policy version numbers between the current policy and the policy version that initiated generation of that sample."
- RESTful: An architectural style for APIs using stateless operations and standard HTTP methods. "All endpoints follow a RESTful design and use JSON for data interchange."
- reward computation: The stage that evaluates trajectories and outputs scalar rewards in RL. "ROLL supports asynchronous reward computation during rollout"
- ROCK: A secure, scalable environment manager that orchestrates sandboxed environments for agent training and evaluation. "ROCK is the environment execution engine that provides secure, sandboxed environments for agentic interaction."
- Rocklet: A lightweight proxy mediating communication between the agent SDK and sandboxes, including network governance. "Rocklet is a lightweight proxy that mediates communication between the agent SDK and sandboxes, governs outbound network access, and enforces egress policies."
- ROLL: An agentic RL training framework supporting scalable multi-environment rollouts and stable policy updates. "ROLL is the agentic RL training framework that supports scalable and efficient RL post-training with multiple environments, multi-turn sampling, and policy optimization."
- rollout: The phase where the agent interacts with environments to generate trajectories for training. "During rollout, the agent LLM interacts with the environment by emitting tokens that represent actions."
- sample buffer: A storage queue holding completed trajectories used by the training stage in asynchronous pipelines. "ROLL maintains a sample buffer to store the completed trajectories"
- sandbox runtime: The execution layer inside a sandbox that manages local hardware and process isolation. "they run the sandbox runtime and manage local hardware resources."
- sandboxed environments: Isolated execution contexts that contain faults and restrict access for safety and reproducibility. "provides secure, sandboxed environments"
- staleness: The lag between the policy used to generate a sample and the current training policy. "configure the per-sample staleness"
- staleness bound: A limit on permissible policy age for in-flight trajectories to control accuracy in asynchronous training. "the staleness bound caps the number of in-flight trajectories"
- Supervised Fine-tuning (SFT): Post-training with labeled examples to align model behavior to desired outputs. "integrating Agentic Continual Pre-training (CPT), Supervised Fine-tuning (SFT), and Interaction-Perceptive Agentic Policy Optimization(IPA) RL algorithm"
- Terminal Bench Pro: A benchmark for terminal-centric agent tasks with stricter contamination control and domain balance. "we introduce Terminal Bench Pro, a benchmark with improved scale, domain coverage, and contamination control."
- trajectory: A sequence of actions and observations collected during agent-environment interaction. "producing a trajectory of interleaved actions and observations."
- Train--Rollout Multiplexing: Dynamically reassigning GPUs between training and rollout stages to reduce bubbles and improve throughput. "Train--Rollout Multiplexing."
- weight synchronization: Updating rollout workers with the latest trained model parameters during asynchronous pipelines. "immediately after weight synchronization, when many new trajectories are launched"
- Worker nodes: Machines running sandbox runtimes and managing local resources under the orchestration plane. "Worker nodes deployed on each machine; they run the sandbox runtime and manage local hardware resources."
Collections
Sign up for free to add this paper to one or more collections.