- The paper presents a novel scalable platform (ARE) that enables complex orchestration and reproducible evaluation of agent environments.
- It introduces Gaia2, a benchmark with 1,120 verifiable scenarios across multiple synthetic universes to assess diverse agent capabilities.
- Methodological innovations include an event-driven architecture, fine-grained action-level verification, and support for asynchronous multi-agent interactions.
The paper "ARE: Scaling Up Agent Environments and Evaluations" (2509.17158) introduces the Meta Agents Research Environments (ARE), a research platform designed to facilitate the scalable creation of agent environments, integration of synthetic or real applications, and execution of agentic orchestrations. The work also presents Gaia2, a benchmark built on ARE, targeting the evaluation of general agent capabilities in dynamic, asynchronous, and multi-agent settings. This essay provides a technical analysis of the ARE platform, the Gaia2 benchmark, their architectural and methodological innovations, and the implications for agentic AI research.
ARE is architected as a time-driven, event-based simulation platform, supporting asynchronous agent-environment interaction. The core abstractions are Apps, Environments, Events, Notifications, and Scenarios.
- Apps are stateful API interfaces encapsulating tools (read/write operations) and maintaining internal state, enabling reproducible experiments and facilitating integration with external APIs via Model Context Protocol (MCP) compatibility.
- Environments aggregate apps, their data, and governing rules, and are modeled as deterministic MDPs, supporting both single- and multi-agent setups.
- Events represent all state changes or actions, scheduled and executed via a DAG-based event queue, supporting absolute/relative timing, conditional execution, and validation.
- Notifications provide a configurable, asynchronous channel for agents to observe environment changes, supporting varying levels of observability and enabling proactivity.
- Scenarios are dynamic, multi-turn, temporally extended tasks, defined by initial state, scheduled events, and verification logic.
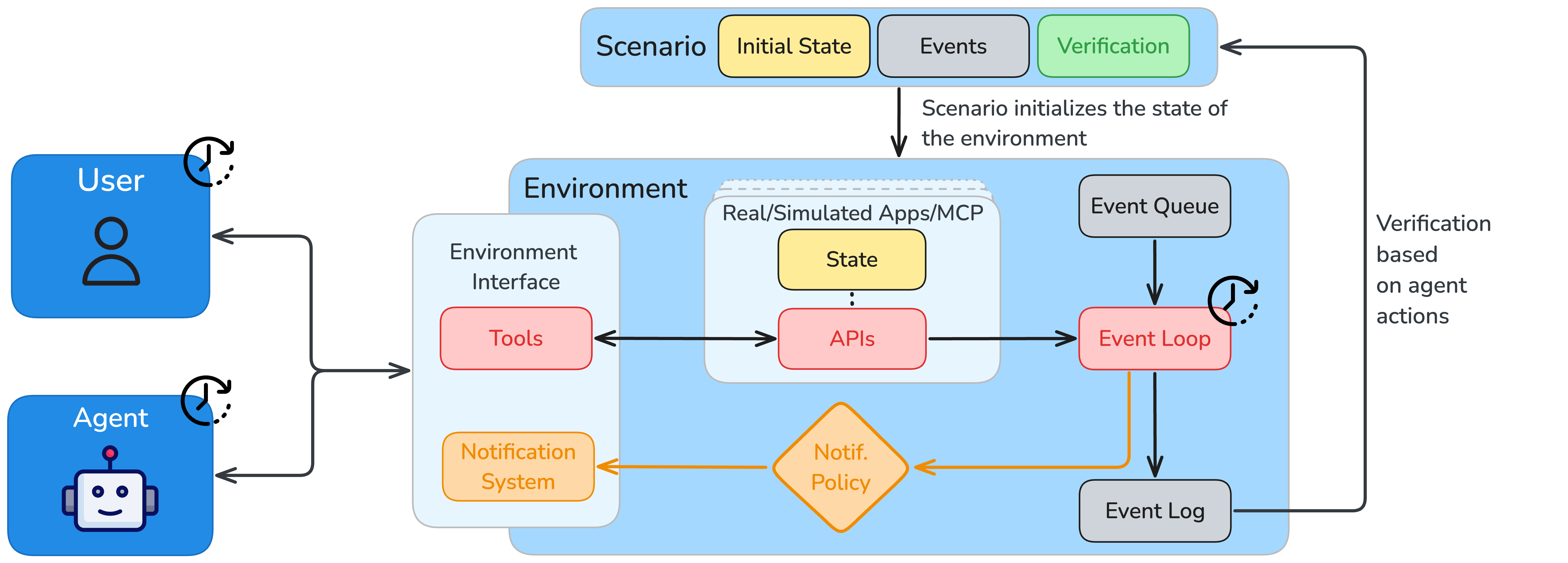
Figure 1: ARE environments are event-based, time-driven simulations, supporting asynchronous, tool-based agent-environment interaction and fine-grained logging for behavioral analysis.
The event scheduling and dependency management via DAGs (Figure 2) enable modeling of complex, interdependent, and concurrent event flows, a critical requirement for realistic agent evaluation.
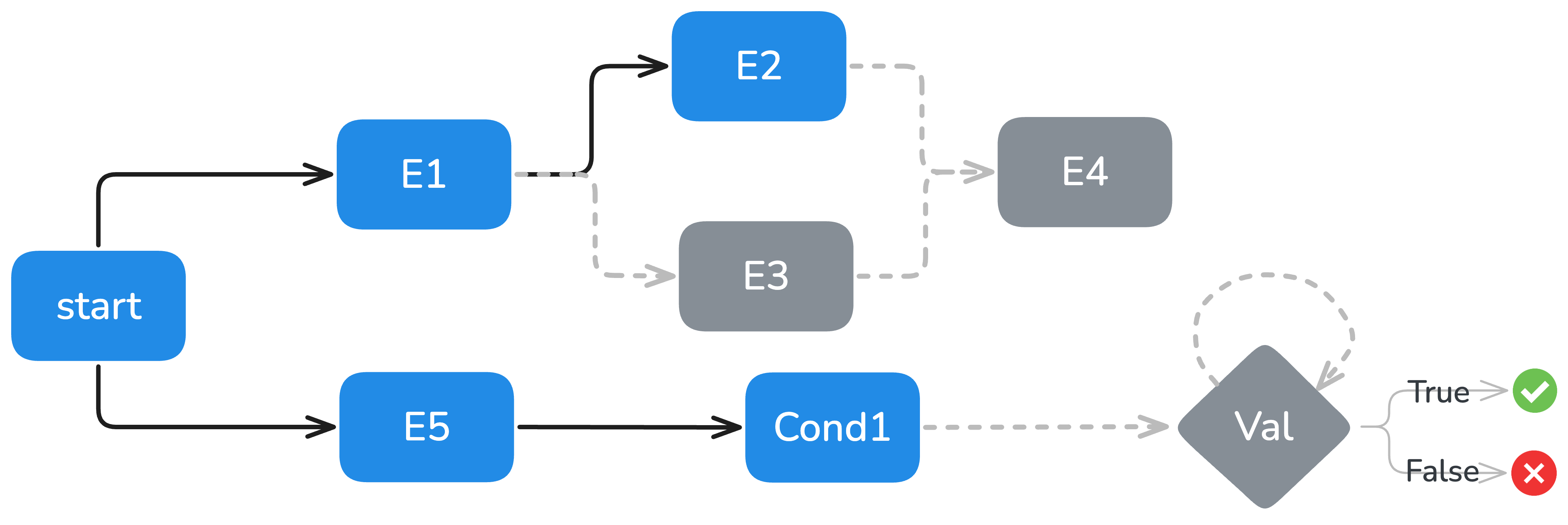
Figure 2: Event dependency graph illustrating parallel, conditional, and validation event scheduling in ARE.
Verification: Rubric-Based, Action-Level Evaluation
ARE introduces a robust, rubric-like verifier that operates at the level of write actions, comparing agent actions to annotated oracle actions. The verification pipeline enforces:
- Consistency: Hard (exact-match) and soft (LLM-judged) checks on action parameters.
- Causality: Ensures agent action order respects oracle dependency graphs.
- Timing: Enforces temporal constraints with tolerance windows.
This approach provides fine-grained control, supports RL from verifiable rewards, and is robust to reward hacking, as demonstrated by adversarial agent behaviors (Figure 3).
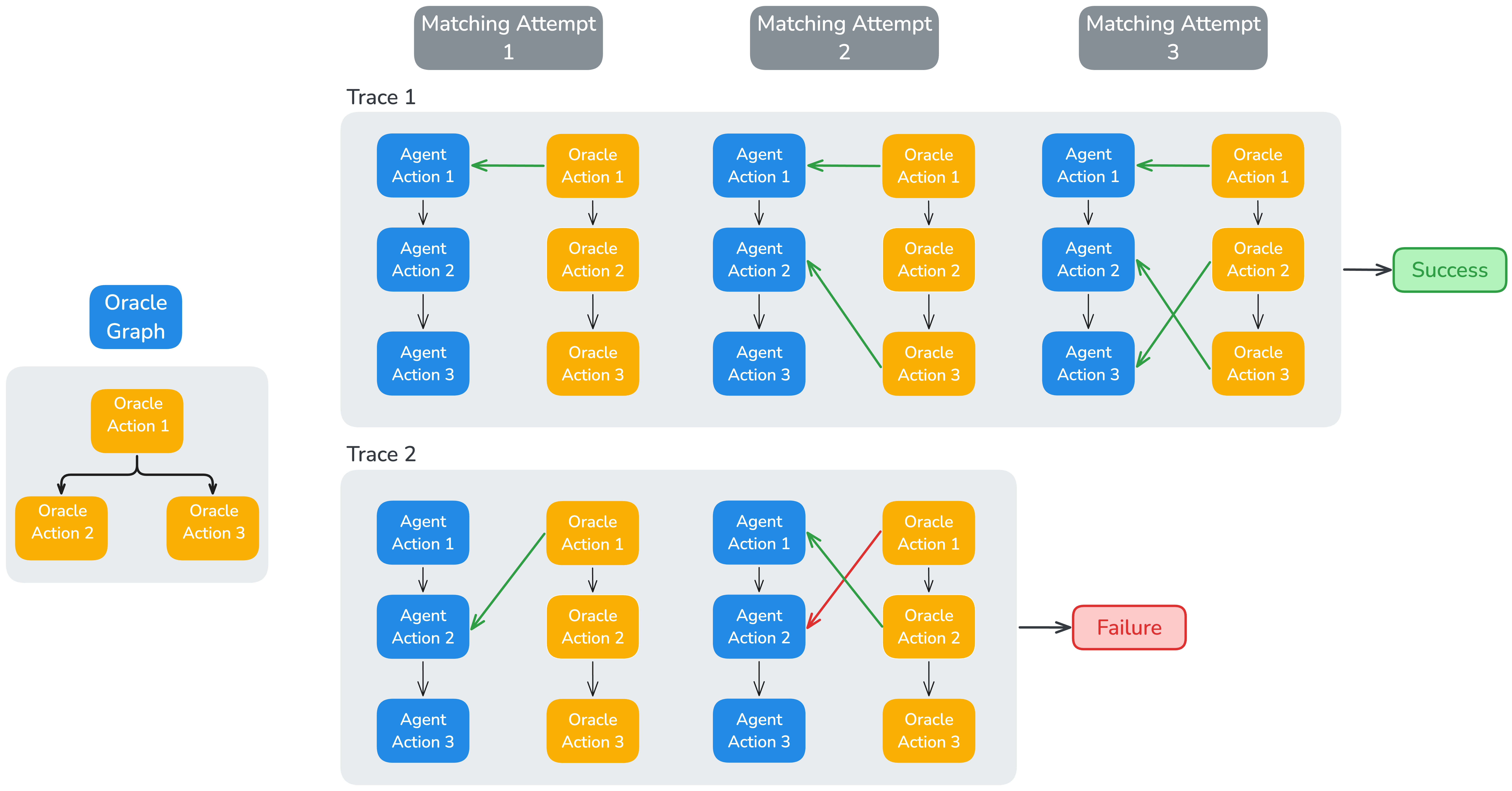
Figure 3: Illustration of a failure (top) and a success (bottom) in the action matching process during verification.
Gaia2: A Comprehensive Benchmark for General Agent Capabilities
Gaia2 is a large-scale, scenario-based benchmark implemented in ARE, comprising 1,120 verifiable scenarios across 10 synthetic "universes" in a Mobile environment. Each scenario is annotated with ground-truth action DAGs and targets one of several core agent capabilities:
- Search: Multi-step fact gathering and aggregation.
- Execution: Ordered, multi-action state modifications.
- Adaptability: Dynamic response to environment changes.
- Time: Temporal awareness and deadline adherence.
- Ambiguity: Recognition and clarification of ill-posed tasks.
- Agent2Agent: Multi-agent collaboration via message passing.
- Noise: Robustness to tool errors and irrelevant events.
Gaia2 scenarios are dynamic, with asynchronous environment events and continuous time, requiring agents to adapt, plan, and coordinate in realistic settings. The Agent2Agent mode (Figure 4) replaces apps with autonomous app-agents, enforcing communication-based collaboration.
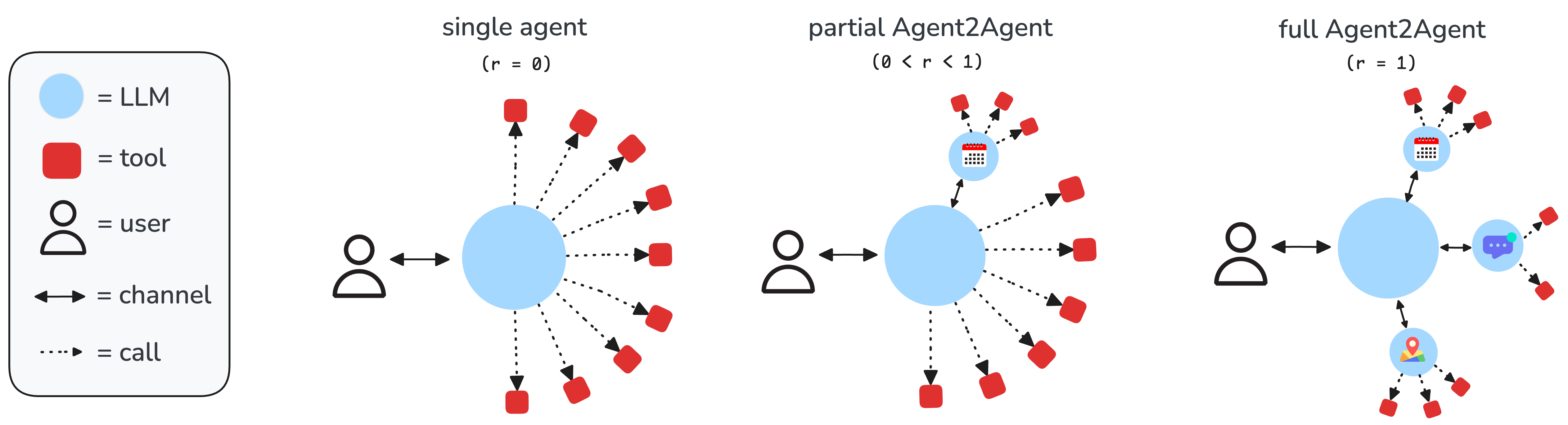
Figure 4: In Agent2Agent scenarios, apps are replaced by autonomous agents, requiring the main agent to coordinate via message passing.
The evaluation of state-of-the-art proprietary and open-source LLMs on Gaia2 reveals several key findings:
- No single model dominates across all capabilities or cost regimes (Figure 5, Figure 6). Stronger reasoning models (e.g., GPT-5 high, Claude-4 Sonnet) achieve higher scores on complex tasks but incur higher latency and cost, and often underperform on time-sensitive tasks due to slower inference.
- Frontier models excel at instruction-following and search, but struggle with ambiguity, adaptability, and collaboration. For example, only Gemini 2.5 Pro and Claude-4 Sonnet achieve non-trivial scores on the Time split.
- Cost-performance tradeoffs are pronounced (Figure 7). Some models (e.g., Kimi-K2) offer strong cost-normalized performance despite lower raw scores.
- Exploration (tool call frequency) and output token count correlate with success, but some models (Claude-4 Sonnet, Kimi-K2) achieve high efficiency with fewer tokens (Figure 8).
- Agent2Agent collaboration benefits weaker models (Llama 4 Maverick), improving pass@k scaling, but does not yield cost-normalized gains for stronger models (Claude-4 Sonnet) (Figure 9).
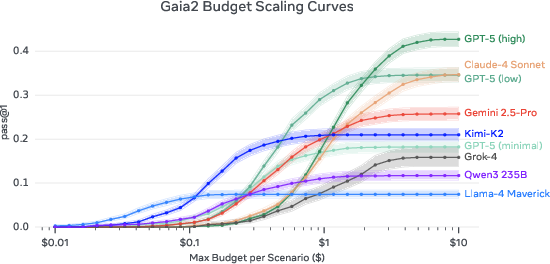
Figure 5: Gaia2 budget scaling curve: no model dominates across the intelligence spectrum; all curves plateau, indicating missing ingredients for sustained progress.
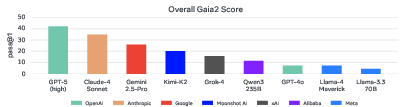
Figure 6: Overall Gaia2 benchmark performance: proprietary frontier models outperform open-source alternatives, but no model is robust across all capabilities.
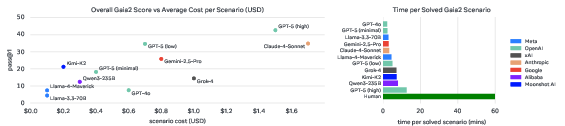
Figure 7: Left: Gaia2 score vs average scenario cost. Right: Time to solve scenarios compared to humans, highlighting efficiency tradeoffs.
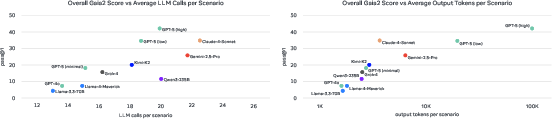
Figure 8: Left: Pass@1 vs average model calls per scenario. Right: Pass@1 vs output tokens per scenario; efficiency varies widely across models.
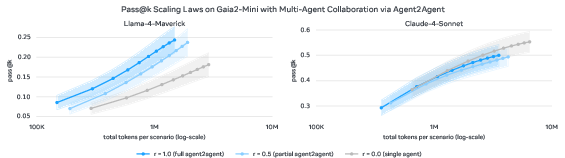
Figure 9: Increasing multi-agent collaborators improves pass@k scaling for Llama 4 Maverick, but not for Claude 4 Sonnet.
Asynchronous, Realistic, and Extensible Evaluation
ARE's asynchronous simulation and notification system (Figure 10) enable real-time, event-driven agent evaluation, supporting scenarios where environment and user events occur independently of agent actions. This is critical for modeling real-world deployment conditions, where agents must be always-on, proactive, and robust to interruptions.
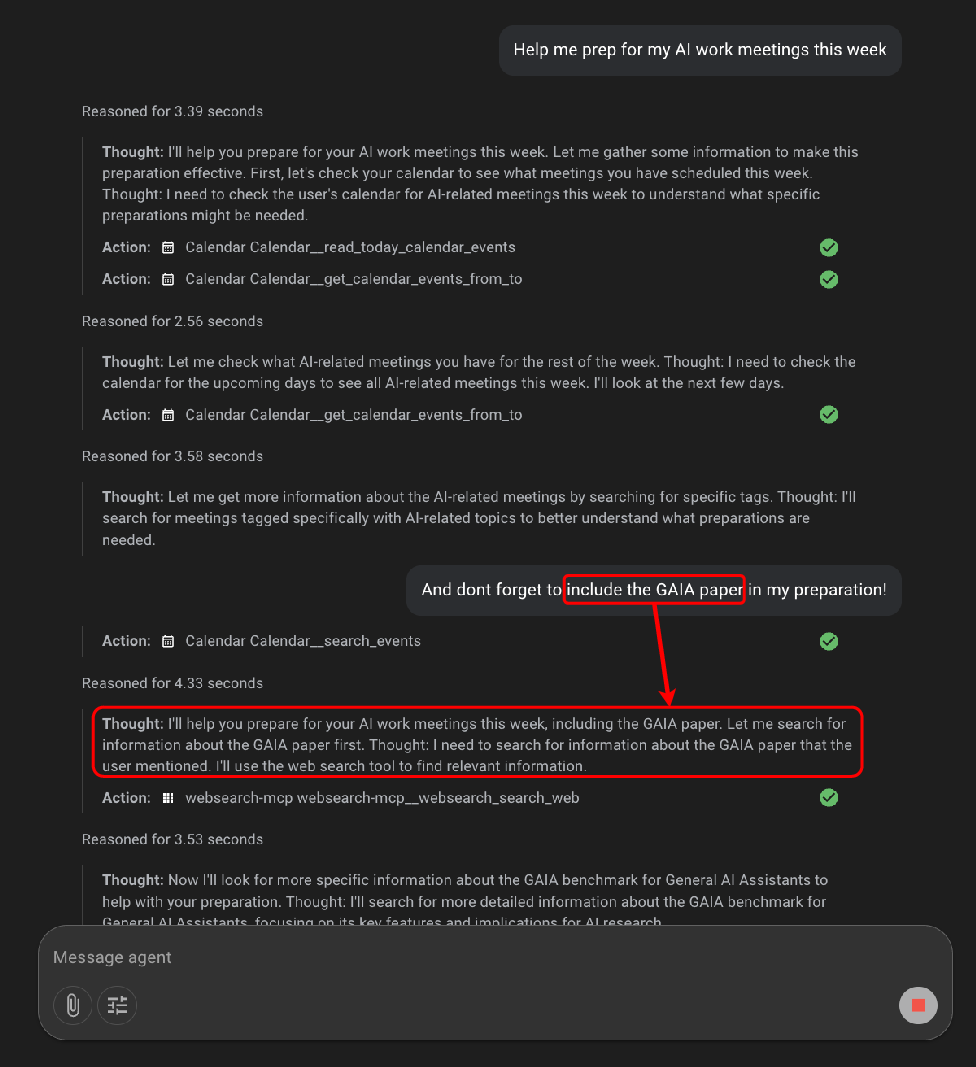
Figure 10: The notification system injects user follow-up instructions into the agent context during execution, enabling asynchronous adaptation.
The platform's extensibility is demonstrated by the ease of porting existing benchmarks (e.g., τ-bench, BFCLv3) and the ability to generate new scenarios via augmentation (e.g., Agent2Agent, Noise) without additional annotation.
Implications and Future Directions
The ARE platform and Gaia2 benchmark represent a significant advance in agentic AI evaluation, addressing key limitations of prior work:
- Bridging the gap between static, idealized benchmarks and dynamic, real-world environments by supporting asynchronous, event-driven, and multi-agent scenarios.
- Enabling RL from verifiable rewards via robust, action-level verification, facilitating scalable agent training and evaluation.
- Highlighting the need for adaptive compute strategies: Stronger reasoning models are slower and less efficient on time-sensitive tasks, motivating research into adaptive computation and model selection.
- Providing a foundation for future research on memory, long-horizon planning, and self-improvement, as ARE supports large-scale, temporally extended, and multi-agent scenarios.
The results indicate that robustness, ambiguity resolution, and collaboration remain open problems for current LLM-based agents, and that cost, latency, and efficiency must be considered alongside raw accuracy in practical deployments.
Conclusion
ARE and Gaia2 provide a scalable, extensible, and realistic platform for agent environment creation and evaluation. The work demonstrates that no current system achieves robust, efficient, and general agentic intelligence across all dimensions, and that progress will require advances in asynchronous agent architectures, adaptive compute, and robust verification. The platform's open-source release and extensibility are poised to accelerate research on practical, deployable agentic AI systems.

