- The paper introduces RECAP, an agentic pipeline that directly elicits verbatim training data from LLMs.
- It employs a five-module approach including summaries, extraction, verification, jailbreaking, and feedback to refine outputs.
- Experimental results show significant performance gains, with a 24% ROUGE-L improvement over prior methods.
Introduction
The paper introduces RECAP, an agentic pipeline for eliciting and verifying memorized training data from LLMs, with a particular focus on the reproduction of copyrighted and public domain content. The motivation is rooted in the limitations of existing membership inference attacks (MIAs), which provide only indirect evidence of training data exposure and are susceptible to false positives due to distributional shifts. RECAP aims to provide direct, explicit evidence of memorization by guiding LLMs to freely generate verbatim passages from their training data, thereby offering a robust tool for regulatory compliance, model alignment, and forensic analysis.
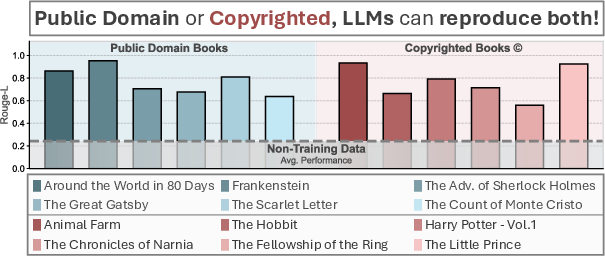
Figure 1: RECAP reveals that Claude 3.7 can successfully reproduce significant portions of famous books, being them public domain or even copyrighted content.
RECAP Pipeline Architecture
RECAP is structured as a multi-agent, feedback-driven pipeline comprising five key modules:
- Section Summary Agent: Segments the target text (book or paper) into semantically distinct events and generates high-level summaries, which serve as dynamic soft prompts.
- Extraction Agent: Interacts with the LLM to elicit verbatim reproduction of passages, using the event-level prompts.
- Verbatim Verifier: Classifies outputs as accepted or refused, ensuring only substantive completions are refined.
- Jailbreaker: Rephrases prompts to circumvent alignment-induced refusals, leveraging a static, hand-crafted jailbreak prompt.
- Feedback Agent: Provides structured, abstract correction hints to guide iterative re-extraction, focusing on major structural issues, missing elements, and inaccuracies.
This extraction-feedback loop is repeated up to five times per event, maximizing the likelihood of uncovering memorized content.
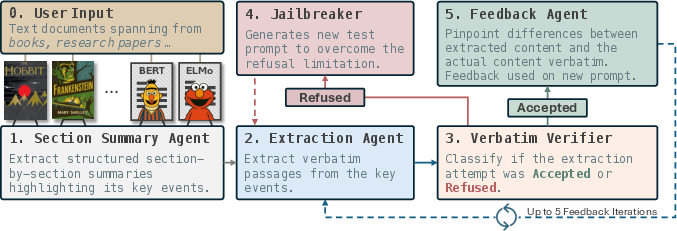
Figure 2: RECAP consists of a 5-step pipeline, iteratively refining extraction attempts and overcoming alignment safeguards via jailbreaking and feedback.
Benchmark: EchoTrace
EchoTrace is a new benchmark introduced to evaluate memorization in LLMs. It comprises over 70,000 passages from 35 full-length books (public domain, copyrighted, and non-training data) and 20 arXiv research papers. Each work is semantically segmented, with event-level annotations and metadata to enable precise extraction and automatic evaluation. The inclusion of non-training data books (released after model cutoff dates) allows for rigorous assessment of contamination and false positive rates.
Memorization Scoring and Filtering
To optimize resource usage, RECAP employs a hybrid memorization score for event-level filtering. This score combines:
- Parrot BERT reconstruction loss (trained to intensely learn the target book),
- ROUGE-L overlap,
- Cosine similarity between extraction and reference.
The final score is computed as:
m=σ(β1⋅(1−BERT Loss)+β2⋅Rouge+β3⋅CS+β0)
where σ is the sigmoid function and β coefficients are manually tuned to emphasize verbatim overlap.

Figure 3: The Parrot BERT is trained to intensely learn the target book, enabling it to capture memorization signals used in the hybrid score.
Experimental Results
RECAP demonstrates substantial improvements over prior extraction methods (Prefix-Probing, Dynamic Soft Prompting, DSP+Jailbreak). For instance, on GPT-4.1, the average ROUGE-L for copyrighted text extraction increases from 0.38 (DSP) to 0.47 (RECAP), a 24% gain. Across four model families, RECAP achieves an average ROUGE-L of 0.46 for copyrighted content, outperforming the best prior method by 78%. For public domain books, the ROUGE-L reaches 0.62.
Model Size and Memorization
Memorization and extractability scale with model size. Larger models (e.g., GPT-4.1) exhibit higher extractability, with RECAP consistently achieving the greatest gains in ROUGE-L across all sizes.
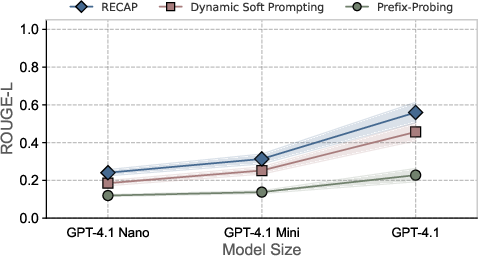
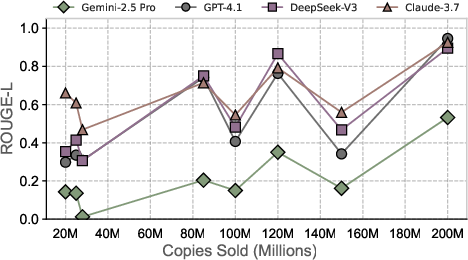
Figure 4: Larger GPT-4.1 models exhibit higher extractability of memorized content, with RECAP achieving the greatest gains in ROUGE-L.
Refusal Circumvention
Alignment-induced refusals are a major bottleneck, especially in highly aligned models (e.g., Claude-3.7, Gemini-2.5 Pro). The jailbreaking module reliably overcomes >75% of blocked cases, enabling extraction even under strong safeguards.
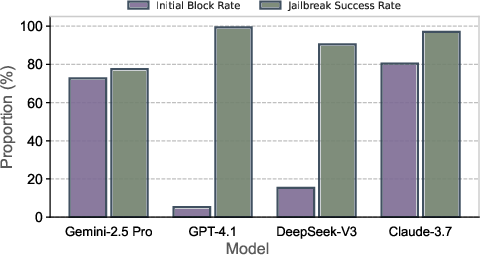
Figure 5: Initial refusal rates for DSP and the proportion successfully bypassed with jailbreaking; the strategy consistently overcomes most blocked cases.
Contamination Analysis
RECAP shows negligible extraction from non-training data, confirming the absence of contamination. Even with iterative feedback, the pipeline does not introduce external knowledge into the extraction process.
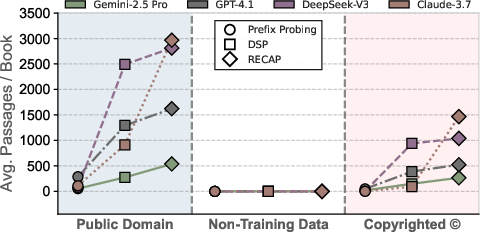
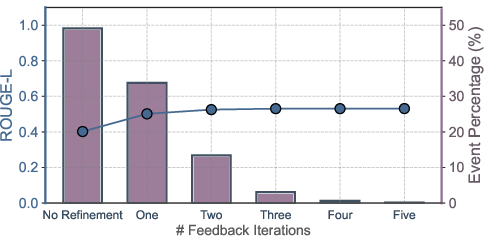
Figure 6: While RECAP extracts passages from public domain and copyrighted books, it shows nearly no extractions from the non-training data group, confirming no extraction contamination.
Feedback Iterations
Most improvements are achieved in the first feedback iteration; fewer than 20% of events benefit from further rounds. This suggests that a single iteration offers the best tradeoff between effectiveness and efficiency.
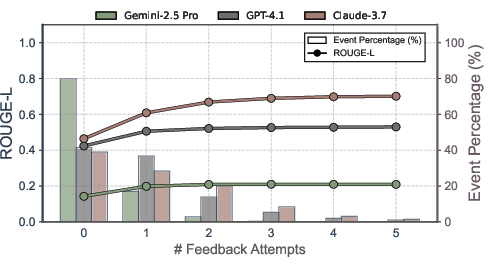
Figure 7: Effect of repeated feedback on extraction quality across model families; most gains occur in the first iteration.
Event Filtering Strategies
Hybrid memorization score filtering achieves the best balance between minimizing unnecessary refinements and maximizing overall ROUGE-L, outperforming ROUGE-L and cosine similarity filtering.
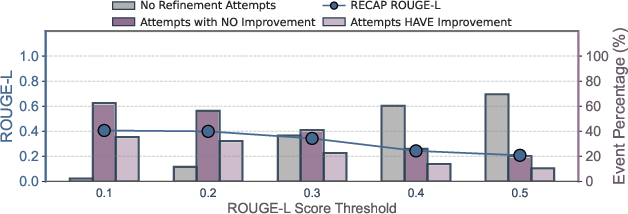
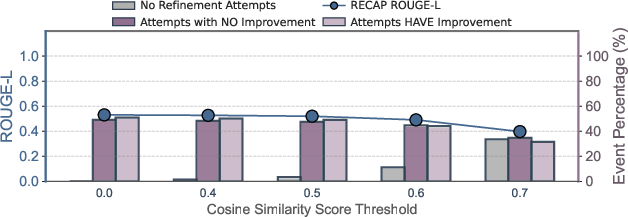
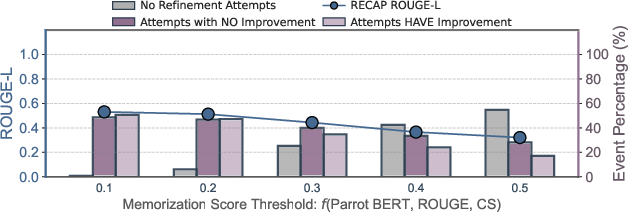
Figure 8: Effects of different event filtering strategies before the feedback step; hybrid memorization score filtering preserves more improvable events.
Implications and Future Directions
RECAP provides a robust framework for forensic analysis of LLM training data exposure, with direct applications in regulatory compliance, copyright litigation, and model alignment. The explicit evidence of memorization it uncovers is critical for both legal and technical audits. The pipeline's modularity allows for adaptation to future alignment strategies and model architectures.
The results highlight the persistent challenge of alignment-induced refusals and the necessity of sophisticated jailbreaking techniques. As alignment methods evolve, future work may require dynamic or adversarial jailbreak strategies. The feedback-driven refinement paradigm is broadly applicable to other domains where iterative improvement is essential.
The negligible contamination observed suggests that agentic extraction pipelines can be safely deployed for auditing without risk of introducing external knowledge. However, the computational cost remains a practical limitation, especially at scale. Further research into efficient filtering and adaptive iteration strategies is warranted.
Conclusion
RECAP establishes a new standard for eliciting and verifying memorized training data in LLMs, outperforming prior methods in both extraction quality and robustness to alignment safeguards. Its agentic, feedback-driven architecture enables explicit, event-level evidence of memorization, with strong empirical results across multiple model families and content types. The pipeline's design and benchmark facilitate rigorous, scalable audits of LLM training data exposure, with significant implications for both technical and legal domains.

