Extracting alignment data in open models
Abstract: In this work, we show that it is possible to extract significant amounts of alignment training data from a post-trained model -- useful to steer the model to improve certain capabilities such as long-context reasoning, safety, instruction following, and maths. While the majority of related work on memorisation has focused on measuring success of training data extraction through string matching, we argue that embedding models are better suited for our specific goals. Distances measured through a high quality embedding model can identify semantic similarities between strings that a different metric such as edit distance will struggle to capture. In fact, in our investigation, approximate string matching would have severely undercounted (by a conservative estimate of $10\times$) the amount of data that can be extracted due to trivial artifacts that deflate the metric. Interestingly, we find that models readily regurgitate training data that was used in post-training phases such as SFT or RL. We show that this data can be then used to train a base model, recovering a meaningful amount of the original performance. We believe our work exposes a possibly overlooked risk towards extracting alignment data. Finally, our work opens up an interesting discussion on the downstream effects of distillation practices: since models seem to be regurgitating aspects of their training set, distillation can therefore be thought of as indirectly training on the model's original dataset.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows that some open-source AI chat models can accidentally reveal parts of the special training data used to make them good at things like safety, following instructions, math, and long reasoning. The authors also show that when you judge “how similar” generated text is to the training data by its meaning (not just exact letters), you find much more leakage than people thought.
Key Objectives
The authors set out to answer a few simple questions:
- Can we trigger an open AI model to repeat pieces of its “alignment” training data (the data that teaches it behavior and skills)?
- Is checking meaning-based similarity better than checking exact text matches for finding this kind of leakage?
- If we can extract such data, can it help train another model to reach similar performance?
- Do models also memorize and regurgitate data from reinforcement learning (RL) training, not just supervised fine-tuning (SFT)?
Methods and Approach
Think of the model’s training data like a library of special examples that taught it certain skills. The authors tried to “get the model to remember” those examples using a few key ideas:
- Chat templates: Many chat models format conversations with special tags like
"<|user|>"and"<|assistant|>". These tags are typically introduced later in training (during “post-training”). The authors found that starting a prompt with parts of this chat format can nudge the model to produce outputs that look a lot like the alignment training data. - Generating and searching: They repeatedly prompted the model using the chat template prefix to produce lots of samples. Then, they compared each generated sample to the model’s post-training dataset to find the closest match.
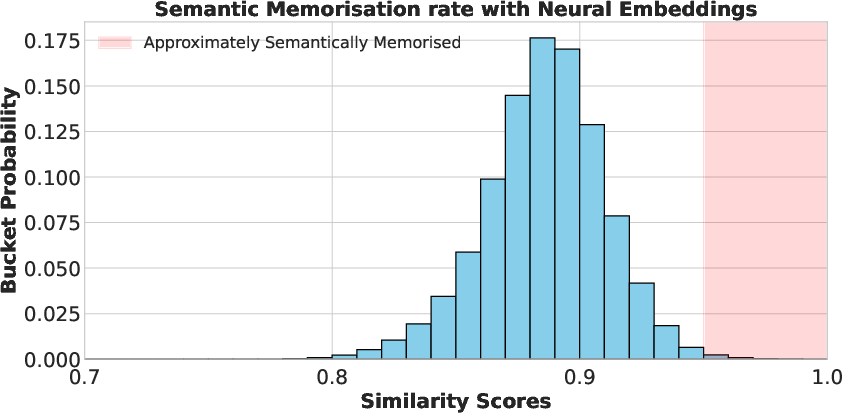
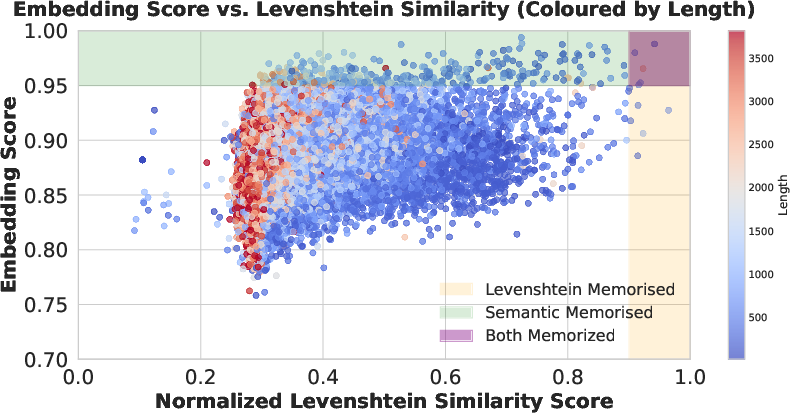
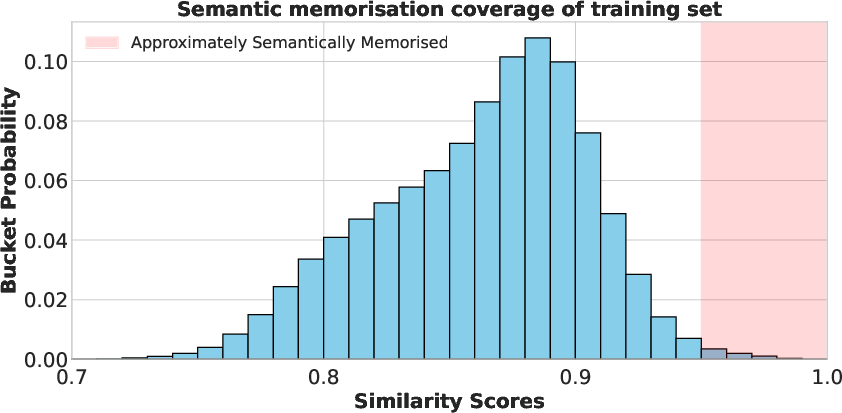
- Meaning-based comparison (embeddings): Instead of just checking letter-by-letter similarity (like “edit distance”), they used text embeddings. Think of embeddings as a “meaning fingerprint” for each piece of text. If two texts have similar fingerprints, they likely mean the same thing, even if the words differ. They used a strong embedding model and measured similarity by the dot product of normalized embeddings (values close to 1 mean very similar). They chose a high threshold (around 0.95) to count something as “approximately, semantically memorized.”
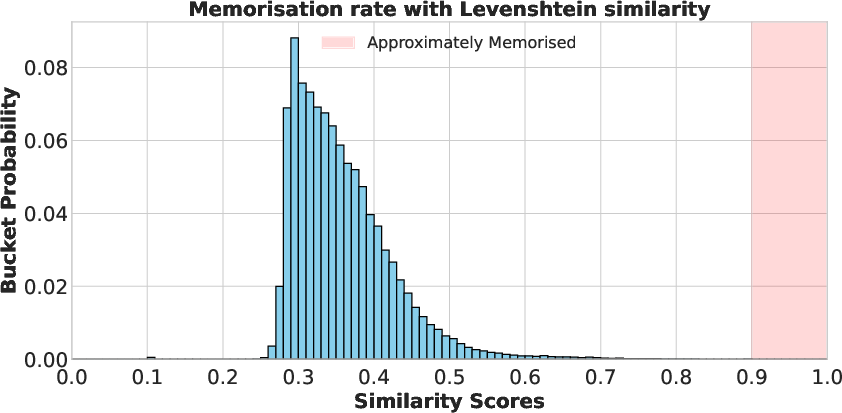
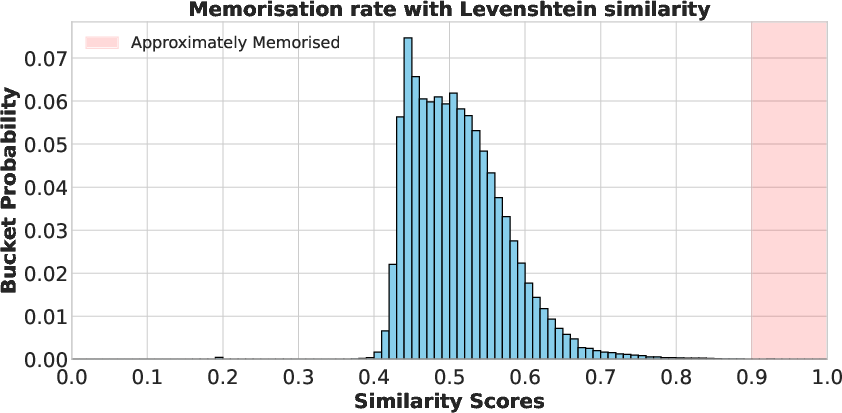
- String matching as a baseline: For comparison, they also used traditional string matching (like Levenshtein distance), which focuses on exact character overlaps. This method misses cases where the meaning is the same but the wording changes slightly.
- Case studies: They tested two open models with public training mixtures:
- SFT extraction with OLMo 2 (a model whose supervised fine-tuning data is available).
- RL extraction with Open-Reasoner-Zero (a model trained with reinforcement learning using public data).
- Distillation tests: They took the model-generated, meaning-matched samples and used them as training data to teach a separate base model, to see if performance would recover.
Main Findings
Here are the core results, explained simply:
- Models can be prompted to produce text that is extremely close to or even identical to their alignment training samples. Using the chat template tags as a prompt was especially effective.
- Meaning-based similarity (embeddings) reveals much more memorization than simple string matching. If you only check exact text matches, you can miss a lot—by roughly 10×, according to their conservative estimate.
- Training a new model on the extracted, synthetic data recovers a meaningful amount of the original model’s performance. In both SFT and RL settings, the new model gets close to the original on standard benchmarks.
- Surprisingly, RL-trained models also regurgitate their training prompts and answers. Even though RL doesn’t directly optimize “repeat this exact text,” the RL process still increases the likelihood of those training prompts appearing.
- The chat template prefix (for example, starting with
"<|endoftext|><|user|>\n") shifts the model’s outputs toward the post-training distribution, making extraction easier. - Some training samples are memorized more than others—especially ones that appear in similar forms across multiple training phases or that are common problem types.
Why This Matters
- Competitive risk: If a model’s advantage comes from its private alignment data, but the model later leaks similar data, that advantage can be copied. Another team could “distill” a model by training on the leaked patterns, indirectly learning from the original dataset.
- Better measurement: Focusing only on exact text matches creates a false sense of safety. Meaning-based checks (embeddings) are more realistic for spotting useful, “near-copy” training data.
- Policy and safety: This kind of leakage isn’t just about personal info; it’s about models sharing the special recipes that make them strong. That has implications for intellectual property and responsible release practices.
- Scope: The attack relies on controlling the chat template, which is typically possible in open-weight models. Closed models usually don’t let users control these tags, so the same trick doesn’t immediately apply—but related methods might still work with effort.
In short, the paper warns that open models can unintentionally reveal valuable training data through their outputs, and the problem looks much bigger when you measure similarity by meaning, not just exact text. This suggests model builders should rethink how they evaluate and protect against memorization, and it highlights that distillation can act like “data distillation,” spreading training data patterns from one model to another.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and open questions left unresolved by the paper that future work could address:
- External validity beyond the two case studies: Assess whether the extraction findings generalize across more model families (e.g., Llama, Mistral, Qwen variants, DeepSeek), sizes (7B–70B+), and post-training recipes (SFT, DPO, PPO, RLVR, RLAIF).
- Closed-model applicability: Empirically test whether spoofing or approximating chat-template tokens enables similar extraction on closed APIs (and characterize feasibility, reliability, and detection risk).
- Verification without ground-truth training sets: Develop evaluation protocols to measure extraction success when the defender’s training mixture is unknown (e.g., clustering, reconstruction quality, human audits) rather than relying on nearest-neighbor search over known datasets.
- Embedding-model dependence and bias: Replicate results with diverse embedding models (open and closed), quantify inter-model agreement, and measure how embedding choice and domain calibration affect false positives/negatives.
- Threshold calibration and reliability: Replace the ad-hoc 0.95 similarity cutoff with human-annotated calibration sets; report ROC/PR curves, CIs, and task-specific thresholds; study sensitivity to prompt length and content.
- False positive controls: Estimate the base rate of “semantic matches” by comparing generations to large corpora known not to be in training (e.g., held-out, time-split datasets), and quantify how often embeddings spuriously match common templates.
- String-matching baselines: Add stronger baselines beyond Levenshtein/Indel (e.g., BLEU, ROUGE, chrF, BERTScore, MoverScore) to isolate when lexical metrics fail vs when they suffice.
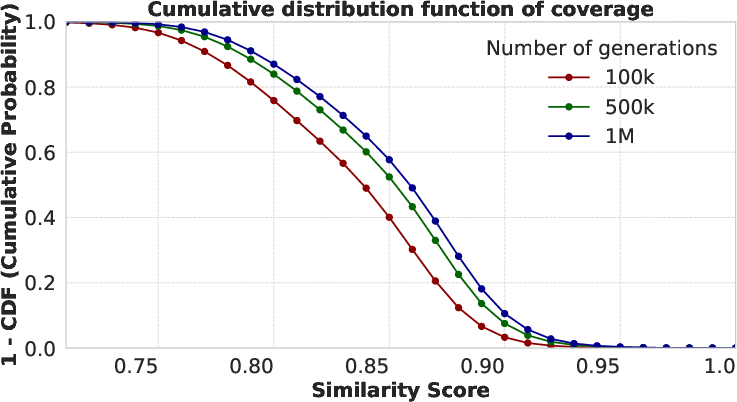
- Coverage scaling laws: Measure how extraction coverage scales with number of generations, decoding strategy, and temperature; provide sample-efficiency curves and compute budgets to achieve X% coverage.
- Decoding strategy ablations: Systematically vary temperature, top-k/p, repetition penalties, beam search, and nucleus sampling to identify extraction-optimal decoding settings.
- Minimal triggering prefixes: Identify the minimal set of tokens needed to induce leakage; ablate system/user/assistant tokens, BOS/EOS, and chat markers; test multi-turn and partial-template prompts.
- Tokenizer effects: Evaluate extraction across tokenizers (byte-level vs subword, different vocabularies) and under constraints where the attacker cannot alter tokenization.
- Stage attribution: Disentangle how much leakage originates from pre-training vs SFT vs RL by tracing likelihood shifts and extraction rates per stage on controlled, stage-specific datasets.
- Mechanisms of RL-induced memorization: Determine why PPO/RL increases prompt likelihoods (e.g., role of KL penalties, advantage normalization, reward shaping, reference-model choice); run controlled ablations isolating each factor.
- Extracting reasoning traces: Quantify whether RL “thinking traces” themselves are memorized or merely re-synthesized; design ground-truthable setups where traces are known, then test extraction.
- Defense efficacy studies: Evaluate defenses such as randomized/rotating chat templates, multi-template training, template obfuscation, deduplication, DP-SGD, stronger KL regularization in RL, and inference-time filtering or anomaly detection.
- Attacker without vector search: Propose and test pipelines that reconstruct alignment datasets without access to the defender’s data (e.g., self-clustering, deduping, template mining, and iterative active sampling).
- Distillation as data reconstruction at scale: Quantify the proportion and uniqueness of recovered samples in student models trained on teacher generations; measure overlap with the teacher’s alignment data across tasks.
- Extracted-data quality and coverage: Diagnose gaps like the observed IFE underperformance; design targeted prompting or active sampling to boost underrepresented capabilities in the extracted dataset.
- Benchmark contamination checks: Measure and report contamination between extracted data and evaluation benchmarks; provide decontamination procedures and re-run evaluations where needed.
- Cross-domain and multilingual scope: Extend analysis to code, safety alignment, long-context tasks, tool use, non-English data, and multimodal settings; quantify domain-specific extraction difficulty.
- Scaling with model capability: Characterize how extraction rates change with model size and alignment strength; test whether larger/stronger models leak more or less under comparable prompts.
- Cost, compute, and reproducibility: Report end-to-end costs (generation, filtering, embedding retrieval), seeds, and open-source implementations; benchmark against budget and time constraints.
- Dependence on closed tools: Replace Gemini embedding and filtering with open alternatives; quantify performance loss or gain to improve reproducibility and accessibility.
- Deduplication and frequency effects: Test how dataset duplication and pattern frequency in pre/mid/post-training influence memorization; run controlled experiments varying duplication levels.
- Inference-time defenses and monitoring: Explore detection and throttling of suspicious prompts (e.g., template-prefill patterns), response shaping, and watermarking to deter or trace extraction.
- Longitudinal dynamics: Track memorization and leakage across checkpoints during post-training (SFT/RL), and study forgetting/remembering dynamics under continued training.
- Legal and licensing boundaries: Analyze whether extracted alignment data may violate licenses or data-use policies even for “open” models; propose auditing and compliance frameworks.
- Robustness of “order-of-magnitude undercount” claim: Provide precise, cross-model quantification of the factor by which string matching undercounts leakage, with statistics and uncertainty estimates.
- Minimal data release risks: Evaluate whether partial disclosure (e.g., chat templates, tokenizer artifacts, or training logs) materially increases extraction risk, and propose safer release practices.
- Adversarial prompting beyond templates: Investigate alternative attack families (activation steering, jailbreak-style prompts, gradient-free adversarial search) that might extract different slices of alignment data.
Practical Applications
Immediate Applications
Below is a set of actionable use cases that can be deployed now based on the paper’s findings, methods, and innovations. Each bullet links to sectors and notes assumptions or dependencies that may affect feasibility.
- Alignment data extraction toolkit for open-weight models
- Sector: software/AI tooling, cybersecurity, academic research
- What: Build a workflow that uses chat-template-based prompting to induce alignment-like generations, then ranks them against known or candidate datasets using high-quality embedding models and vector search.
- Tools/products/workflows:
- Prompt generator using model’s chat template tokens
- Embedding-based semantic matching (e.g.,
gemini-embedding-001, text-embedding-3-large, Cohere, or similar) - Vector database and search (e.g., FAISS, Milvus, Weaviate)
- LLM-based filtering and grading for data quality (correctness, completeness)
- Uses:
- Reconstruct SFT or RL datasets for further fine-tuning
- Bootstrap targeted capability datasets (math, reasoning, long context) without manual collection
- Competitive analysis for open models’ alignment mixtures
- Assumptions/dependencies: Access to open weights and controllable chat templates/tokenization; sufficient compute to sample and embed (up to 1M+ generations); high-quality embedding model; legal review for data reuse.
- Embedding-based memorization audit service for open releases
- Sector: compliance/legal, policy, software
- What: Offer pre-release audits that assess approximate semantic memorization rather than string-matching, producing coverage reports and leakage risk ratings.
- Tools/products/workflows:
- Memorization dashboard with histogram and CDF of embedding similarities
- Threshold calibration for “approximate semantic memorization” (e.g., ≥0.95 cosine/dot for unit-normalized embeddings)
- Automated reports and governance artifacts for release gating
- Uses:
- Vendor and OSS maintainers validate risk of regurgitating proprietary alignment data
- Procurement teams assess compliance before adopting open models in regulated sectors (healthcare, finance, education)
- Assumptions/dependencies: Strong embeddings; access to reference datasets or proxies; agreed thresholds and governance policies.
- Cost-reduced model post-training via extracted datasets (SFT and RL)
- Sector: software/AI training, academia, startups
- What: Use extracted synthetic datasets to fine-tune a base model to recover a meaningful portion of the original’s performance (as demonstrated for OLMo 2 7B SFT and Qwen2.5 7B RL).
- Tools/products/workflows:
- End-to-end pipeline: generation → embed → match → filter → SFT/RL training → benchmarking (BBH, MMLU, GSM8K, MATH500, OlympiadBench, etc.)
- RL workflow with Dr. GRPO or PPO using extracted question–answer pairs
- Uses:
- Rapid capability replication and iteration
- Academic reproduction of alignment effects without manual data collection
- Assumptions/dependencies: Base model availability; compute for training; data filtering quality; legal/ethical compliance.
- Release hardening for open-weight models (defensive controls)
- Sector: cybersecurity, software devops/ML ops
- What: Implement inference wrappers and tokenization controls to reduce regurgitation risk via chat templates.
- Tools/products/workflows:
- Server-side enforcement of chat templates (prevent user-controlled special tokens)
- Template randomization/obfuscation and inference-time masking
- Output filtering using embedding similarity to “known alignment corpus”
- Uses:
- Reduce alignment data leakage before release
- Improve safety posture for open-source model maintainers
- Assumptions/dependencies: Control over deployment environment; acceptance of small capability trade-offs; monitoring for false positives/negatives.
- Dataset recovery and forensics
- Sector: ML ops, software engineering
- What: Recover or approximate lost or fragmented alignment datasets by inducing semantic neighbors from the model itself and clustering them.
- Tools/products/workflows:
- Embedding clustering for topic/style extraction
- Deduplication and canonicalization of recovered samples
- Uses:
- Model reproduction after accidental loss
- Post-mortems on training data provenance
- Assumptions/dependencies: Model still accessible; sufficient compute; legal OK for recovered data use.
- RL pipeline debugging and curation
- Sector: AI research, software/ML ops
- What: Use extraction and likelihood comparison pre/post-RL to identify overrepresented prompts and topics causing memorization and rebalance datasets.
- Tools/products/workflows:
- Likelihood tracking for prompts before and after RL
- Decontamination/deduplication with embedding-based similarity
- Uses:
- Improve RL data diversity and reduce overfit/regurgitation
- Assumptions/dependencies: Access to base and RL models; instrumentation to measure prompt likelihoods.
- Academic methodology for semantic memorization measurement
- Sector: academia, standards bodies
- What: Replace near-verbatim thresholds (e.g., Levenshtein ≥0.9) with embedding-based criteria focused on semantic equivalence.
- Tools/products/workflows:
- Public benchmarks and code for embedding-based leakage measurement
- Threshold selection protocols and human-in-the-loop validation
- Uses:
- More accurate research on memorization and generalization
- Assumptions/dependencies: High-quality embeddings; open datasets; reproducible protocols.
- Risk assessment for adopters in regulated sectors
- Sector: healthcare, finance, education, public sector
- What: Evaluate whether using open-weight models exposes proprietary or sensitive alignment data via regurgitation, informing procurement and deployment decisions.
- Tools/products/workflows:
- Memorization audit reports
- Policy checklists for release/usage
- Uses:
- Mitigate IP, privacy, and compliance risk in sensitive domains
- Assumptions/dependencies: Organizational governance; clarity on data ownership/licensing; expert review.
- Education and content generation with originality checks
- Sector: education
- What: Generate math and reasoning practice material using template-based prompting, then verify originality via embedding comparison against known corpora.
- Tools/products/workflows:
- Generation + embedding-based dedup/originality scoring
- Teacher dashboards for safe reuse
- Uses:
- Create practice sets while minimizing unintended regurgitation of proprietary content
- Assumptions/dependencies: Access to reference corpora; clear policy on acceptable similarity.
Long-Term Applications
These applications require further research, scaling, or ecosystem development before widespread deployment.
- Closed-model leakage adaptation
- Sector: cybersecurity, software
- What: Develop methods to spoof or approximate closed-model chat templates and tokenization to test for alignment-data leakage.
- Tools/products/workflows:
- Template inference via behavioral probing
- Side-channel embedding-based extraction workflows
- Assumptions/dependencies: Partial control over client libraries; legal/ethical constraints; evolving vendor defenses.
- Standardization of embedding-based memorization metrics and certifications
- Sector: policy, standards, compliance
- What: Establish thresholds, protocols, and audits for “approximate semantic memorization” in model releases, replacing or augmenting string matching.
- Tools/products/workflows:
- Certification programs and audit guidelines
- Public test suites for semantic leakage
- Assumptions/dependencies: Consensus among regulators, industry, and researchers; stable metric definitions.
- Alignment dataset watermarking and provenance
- Sector: software/AI tooling, policy
- What: Embed watermarks or provenance signals in alignment datasets that survive paraphrase and style transfer, detectable via specialized embedding models.
- Tools/products/workflows:
- Robust semantic watermarks
- Provenance validators integrated into model outputs
- Assumptions/dependencies: Technical viability of watermarking under semantic transformations; no major performance regressions; community adoption.
- Privacy-preserving post-training objectives (SFT/RL) that mitigate memorization
- Sector: AI research
- What: Redesign objectives and regularization (e.g., DP-SGD variants, likelihood constraints, penalizing regurgitation) to preserve capability while reducing memorization.
- Tools/products/workflows:
- Training-time memorization monitors and penalties
- Post-training debiasing via curriculum or augmentation
- Assumptions/dependencies: Maintaining performance; computational overhead; empirical validation across tasks.
- Coverage-aware training data curation
- Sector: software/ML ops
- What: Use coverage histograms and embedding similarity to rebalance post-training datasets (reduce repeated problem archetypes; increase underrepresented skills).
- Tools/products/workflows:
- Coverage dashboards
- Automated data selection/sampling policies
- Assumptions/dependencies: Access to full training mixture; continuous data pipelines; acceptance of rebalanced distributions.
- Marketplace for “alignment capsules” (targeted skill datasets)
- Sector: AI products, education, enterprise training
- What: Productize curated synthetic datasets that target specific capabilities (math, long-context reasoning, safety), extracted and filtered for quality and originality.
- Tools/products/workflows:
- Quality grading, correctness verification, originality checks
- Licensing and compliance frameworks
- Assumptions/dependencies: Clear legal environment; robust filtering to avoid proprietary leakage; sustained demand.
- Governance updates for open-weight releases
- Sector: policy/regulation
- What: Best-practice guidelines that address tokenization control, template exposure, release documentation of alignment mixtures, and required leakage audits.
- Tools/products/workflows:
- Model release checklists and enforcement mechanisms
- Model cards that include memorization audit results
- Assumptions/dependencies: Community and platform buy-in; alignment with OSS licensing norms.
- Red-teaming suites for regurgitation and semantic leakage
- Sector: cybersecurity
- What: Penetration-testing products specialized to uncover alignment-data regurgitation in text models (and eventually multimodal).
- Tools/products/workflows:
- Attack libraries using template cues and semantic prompts
- Automated reporting and remediation recommendations
- Assumptions/dependencies: Access to test instances; scalable automation; defense-response cycles.
- Specialized embedding models for memorization detection
- Sector: AI research/tooling
- What: Train embeddings tuned for detecting semantic regurgitation under style/format variations, surpassing general-purpose embeddings for leakage audits.
- Tools/products/workflows:
- Contrastive training on paraphrase and template variations
- Evaluation suites for detection robustness
- Assumptions/dependencies: High-quality training data; benchmark standardization.
- Sector-specific compliance integrations (healthcare, finance, education)
- Sector: healthcare, finance, education
- What: Embed leakage audits, template hardening, and originality checks into sector-specific platforms (EHR assistants, financial analytics copilots, tutoring systems).
- Tools/products/workflows:
- Compliance UI and automated audit pipelines
- Incident response for detected regurgitation
- Assumptions/dependencies: Regulatory constraints; vendor cooperation; model deployment control.
Notes on Assumptions and Dependencies (cross-cutting)
- Open-weight requirement: The core extraction method relies on user control over chat templates/tokenization; closed models often prevent this, limiting immediate applicability.
- Embedding quality: Feasibility hinges on robust embedding models that capture semantic similarity; threshold calibration affects measured leakage and audit outcomes.
- Compute and scale: Large-scale sampling (e.g., 1M generations) and embedding index construction require non-trivial compute and storage.
- Legal/ethical considerations: Reuse of extracted data may be restricted by licensing, IP, or privacy policies; organizations must conduct legal reviews.
- Model/data variability: Memorization rates and extraction utility depend on training mixtures, repeated archetypes, and the presence of similar content across pre-, mid-, and post-training.
- Performance trade-offs: Defensive measures (template enforcement, output filters) may slightly reduce model flexibility or capability; monitoring and tuning are necessary.
Glossary
- Alignment Data: Targeted data used to steer model behavior and improve capabilities (e.g., safety, instruction following, reasoning, math) often used during alignment/post-training phases. "For the purpose of this work, we refer to this data as `alignment' data."
- Approximate semantic memorisation: Memorisation measured via embedding-based semantic similarity rather than literal string overlap. "we call this a measure using embeddings a measure of approximate semantic memorisation."
- Approximate string matching: Fuzzy text similarity methods (e.g., edit distance variants) that compare character sequences rather than meaning. "approximate string matching would have severely undercounted (by a conservative estimate of ) the amount of data that can be extracted"
- Chat Template: Structured prompt format using special tokens (e.g., <|user|>, <|assistant|>) typically introduced during post-training. "Chat Template: A specific structure used to format prompts by wrapping user, assistant, or system messages in special tokens (e.g., <|user|>, <|assistant|>)."
- Coverage: The extent to which generated samples match or retrieve items from the post-training dataset. "We now check the coverage of the post-training data, where for each post-training sample, we report the largest embedding score out of the 1M generated samples."
- Direct Preference Optimisation (DPO): A post-training method that optimizes a model to prefer higher-quality responses based on preference data. "then a Direct Preference Optimisation~\citep{rafailov2023direct} step is conducted with 378k samples"
- Distillation (model distillation): Training a new model using outputs/behavior of a stronger model, effectively transferring knowledge and potentially data patterns. "It is also important from the point of view of the commonplace practice of model distillation, where a competitor may use a strong model to train their own."
- Dr. GRPO: A reinforcement-learning-style post-training method used to train reasoning models; a variant related to PPO-style optimization. "We start by post-train using Dr.~GRPO \citep{liu2025understanding} the Qwen2.5 7B base model using the ORZ 57k dataset \citep{hu2025open}."
- Embedding model: A neural model that maps text to vectors capturing semantic meaning for retrieval/similarity tasks. "Embedding scores are generated by an embedding model and can be tuned for different tasks."
- Embedding Score: Dot-product similarity between unit-normalized text embeddings used as a semantic similarity metric. "Embedding Score: A metric we use to measure memorisation based on the semantic similarity between two pieces of text, calculated using the dot product of neural text embeddings."
- gemini-embedding-001: A specific high-quality text embedding model used to compute semantic similarity in this study. "We use the gemini-embedding-001 model~\citep{lee2025gemini} in all of our experiments as it is a general and strong embedding model."
- Indel similarity: A normalized string similarity metric related to edit distance that penalizes insertions and deletions (and treats substitutions differently). "the normalised Indel similarity defined as $1 - Indel(A, B) / (len(A) + len(B))$."
- Levenshtein similarity: A normalized similarity derived from the Levenshtein (edit) distance between two strings. "We consider the normalised Levenshtein similarity defined as $1 - Levenshtein(A, B) / max(len(A), len(B))$"
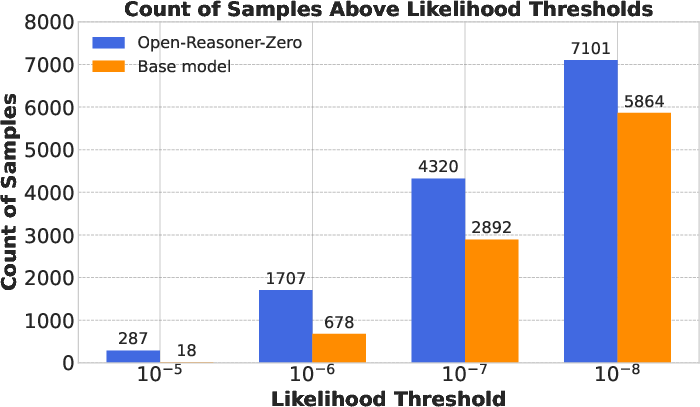
- Likelihood: The probability assigned by a model to data sequences, used here to gauge changes in memorisation after RL. "we measure the likelihoods of each PPO training sample question under the Qwen 2.5 base model and the Open-Reasoner-Zero model."
- Magpie: A technique that uses chat-template-based prompting to synthesize alignment-like data from models. "This provides an explation for why techniques such as Magpie \citep{xu2024magpie} are possible:"
- Memorisation: The phenomenon where a model reproduces training data or its patterns/templates, not necessarily verbatim. "Memorisation~\footnote{We make no statement with regard to whether or not a model `contains' its training data in a bit-wise or code-wise sense, nor in the sense that any arbitrary instance of training data can be perfectly retrieved.:} This refers to the phenomenon where a model can regurgitate or recite its training data."
- OLMo 2: An open LLM with publicly available training mixtures used to study SFT memorisation and extraction. "We focus our SFT memorisation study on OLMo 2 \citep{olmo20242}\footnote{Licensed by AllenAI under the Apache License, Version 2.0.}."
- Open-Reasoner-Zero: An RL-trained reasoning model (from Qwen 2.5) with publicly available post-training data. "We use the Open-Reasoner-Zero~\citep{hu2025open} model, which was trained from the Qwen 2.5 base model with PPO~\citep{schulman2017proximal} using post-training data that is publicly available."
- Open-weight models: Models with accessible weights that allow user control over tokenization and prompting templates. "By exploiting the fact that in open-weight models, the end user controls tokenization, and that the chat template structure is only introduced during post-training, we use a simple attack"
- Post-training: Alignment stages after large-scale pre-training (e.g., SFT, DPO, RL) that steer model behavior. "Post-training: This refers to the training stages that occur after the initial large-scale pre-training phase."
- Prefix: An initial token sequence used to condition model generation toward certain distributions. "we then generate a number of samples simply by prompting the model using our chosen prefix repeatedly."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm commonly used for post-training LLMs. "trained from the Qwen 2.5 base model with PPO~\citep{schulman2017proximal}"
- Reasoning trace: The intermediate chain-of-thought steps produced during solving, often not included in RL training datasets. "the reasoning traces not part of the training dataset as they are artifacts of the training rollout."
- Reinforcement Learning (RL): Post-training paradigm optimizing behavior via rewards rather than supervised targets. "We are able to extract data ranging from reinforcement learning (RL) prompts and associated traces"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL post-training method using verifiable/programmable reward signals. "and finally a RL with Verifiable Rewards (RLVR) step with 29.9k samples."
- Semantic similarity: Similarity in meaning (as opposed to surface form), often measured via embedding cosine/dot-product. "Distances measured through a high quality embedding model can identify semantic similarities between strings that a different metric such as edit distance will struggle to capture."
- String matching: Literal or near-literal comparison of text sequences to detect overlap or memorisation. "the majority of related work on memorisation has focused on measuring success of training data extraction through string matching"
- Style-transfer: Rewriting that preserves semantics while changing surface form, often evading string-matching detectors. "string matching has been shown to be vulnerable to `style-transfer' \citep{ippolito2022preventing}, where semantics are preserved whilst easily evading string matching checks."
- Supervised Finetuning (SFT): Post-training via supervised learning on curated instruction/reasoning datasets. "such as Supervised Finetuning (SFT) and Reinforcement Learning (RL) datasets"
- Tokenization: The process of converting text into tokens used by the model during training/inference. "in open-weight models, the end user controls tokenization"
- Vector search engine: An embedding-based retrieval system that finds nearest neighbors via vector similarity. "constructing a vector search engine."
Collections
Sign up for free to add this paper to one or more collections.