- The paper introduces Hubble, an open-source suite that enables controlled experiments on LLM memorization through precise perturbation insertion in pretraining corpora.
- The paper demonstrates that dilution, exposure timing, and model scaling critically affect memorization risks, with larger models memorizing lower duplication levels and late data exposures increasing retention.
- The paper validates Hubble’s efficacy by benchmarking membership inference and unlearning methods, highlighting current limitations and informing policy and methodological improvements.
Hubble: A Model Suite to Advance the Study of LLM Memorization
Introduction and Motivation
The Hubble suite addresses a central challenge in the paper of LLM memorization: the lack of open, controlled, and scalable resources for systematically probing memorization risks across copyright, privacy, and test set contamination domains. Prior work has been limited either to small-scale, synthetic studies or to observational analyses of large, opaque models, both of which preclude precise causal measurement of memorization phenomena. Hubble fills this gap by releasing a suite of open-source LLMs, datasets, and evaluation protocols, enabling controlled experimentation at scale and providing a foundation for rigorous, policy-relevant research on memorization.

Figure 1: The Hubble suite provides a comprehensive, open-source platform for controlled studies of LLM memorization across multiple risk domains.
Perturbation Design and Data Insertion
Hubble's core innovation is the controlled insertion of perturbation data into the pretraining corpus. Perturbations are designed to emulate real-world memorization risks and span three domains:
- Copyright: Passages from popular/unpopular books and Wikipedia, as well as paraphrase pairs, to paper literal and non-literal memorization.
- Privacy: Synthetic and real biographies (YAGO, ECtHR) and chat logs (Personachat) to probe direct and indirect PII leakage.
- Test Set Contamination: Standard and novel benchmarks (PopQA, WinoGrande, MMLU, HellaSwag, PIQA, ELLie, MUNCH) to analyze contamination effects.
Perturbations are inserted at controlled duplication levels (0, 1, 4, 16, 64, 256), with randomized assignment to enable causal inference. The insertion process ensures that perturbations are treated as regular documents, are not truncated, and are surrounded by EOS tokens. Decontamination procedures remove any pre-existing overlap between perturbations and the base corpus, ensuring accurate measurement of duplication effects.
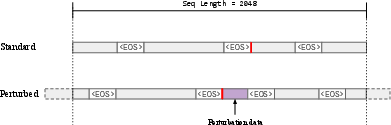
Figure 2: Visualization of the perturbation insertion process, ensuring controlled exposure and precise duplication counts.
Model Suite and Training Protocol
Hubble models are based on the Llama 3 architecture, with modifications for interpretability and efficiency (OLMo tokenizer, untied embeddings, increased depth for 8B models). The suite includes:
- Core Models: 1B and 8B parameter models, each trained on 100B or 500B tokens, in both standard and perturbed variants.
- Timing Models: 1B models with perturbations inserted at different pretraining phases to paper the effect of exposure timing.
- Interference, Paraphrase, and Architecture Models: Variants to isolate domain effects, test paraphrased knowledge, and analyze depth-width trade-offs.
All models are trained on the DCLM-filtered CommonCrawl corpus, with perturbations constituting a negligible fraction of total tokens (≤0.08% for 100B, ≤0.016% for 500B), avoiding performance degradation due to repeated data.
Empirical Findings: Dilution, Ordering, and Scaling
Dilution
A primary result is that memorization risk is a function of the frequency of sensitive data relative to corpus size. Increasing the training corpus size (dilution) reduces the likelihood of memorization for a fixed number of duplicates.
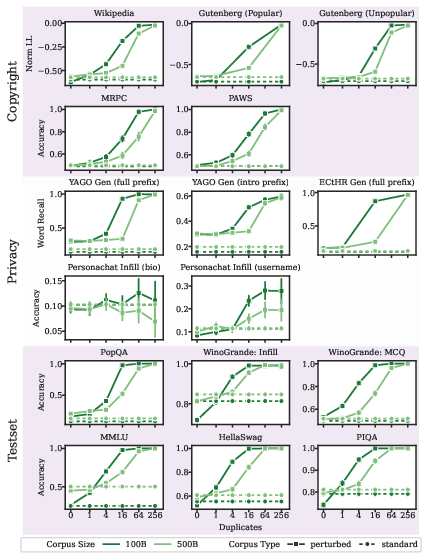
Figure 3: Memorization of sensitive data is significantly reduced in models trained on larger corpora, demonstrating the efficacy of dilution as a mitigation strategy.
Ordering
The timing of exposure to sensitive data is critical. Perturbations inserted only in early training are progressively forgotten, while those inserted late are more likely to be memorized and extractable.
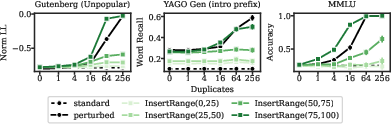
Figure 4: Sensitive data can be forgotten if not continually exposed; memorization decays when perturbations are limited to early training phases.
Model Scaling
Larger models (8B vs. 1B) memorize at lower duplication thresholds and exhibit stronger memorization for the same perturbation frequency, compounding risk as model size increases.
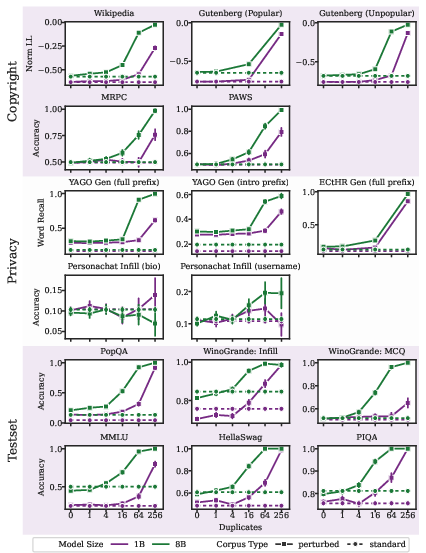
Figure 5: Larger models exhibit stronger memorization at lower duplication levels, highlighting scaling risks.
Domain-Specific Analyses
Copyright
Memorization is sensitive to the choice of metric. Loss-based metrics detect differences at lower duplication counts, while k-eidetic and ROUGE-L require higher duplication for significant effects. Contrary to the data density hypothesis, popular and unpopular books are memorized similarly at 1B scale, with only minor differences at 8B.
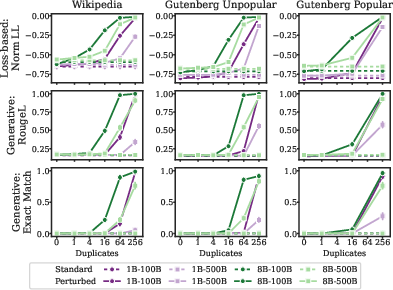
Figure 6: Memorization metrics for copyright passages reveal that verbatim generation requires higher duplication than loss-based detection.
Privacy
Attack success rates for PII extraction depend on the amount of auxiliary information available to the adversary. With full context, near-perfect extraction is possible at moderate duplication. Memorization varies across PII types (e.g., occupation, email, UUID), and indirect leakage via chat logs is possible but less effective.
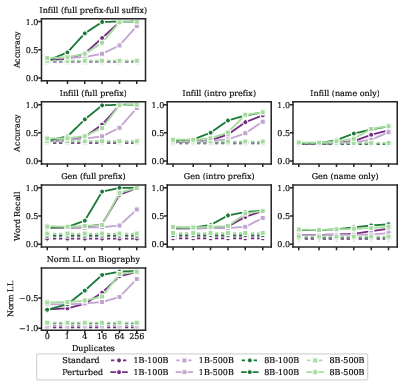
Figure 7: Attack success rates on YAGO biographies show that more auxiliary information yields higher PII extraction accuracy, with strong dependence on duplication level.
Test Set Contamination
Models begin to memorize test set examples with as few as one duplicate, but this does not translate to improved generalization on unseen examples. In some cases, contamination degrades performance on minimal pairs or alternative formats.
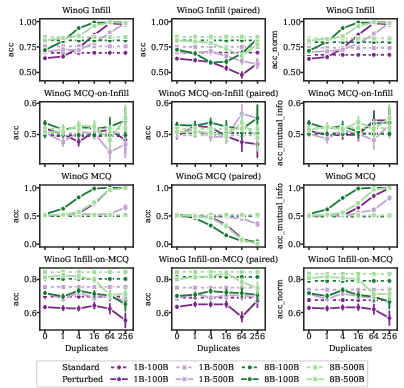
Figure 8: WinoGrande contamination experiments show that memorization does not generalize across formats and can degrade performance on related examples.
Hubble as a Benchmark for Membership Inference and Unlearning
Hubble's randomized perturbation design enables robust evaluation of membership inference attacks (MIAs) and machine unlearning methods. MIAs are only effective at high duplication levels; distinguishing single-duplicate members from non-members is near random, confirming recent findings that MIAs are weak in realistic LLM settings unless duplication is substantial.
Unlearning methods (e.g., RMU, RR, SatImp) fail to achieve targeted forgetting without collateral degradation of neighboring or general knowledge, indicating that current approaches lack the specificity required for practical deployment.
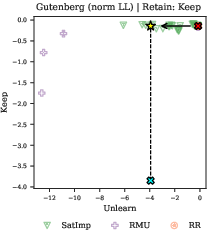
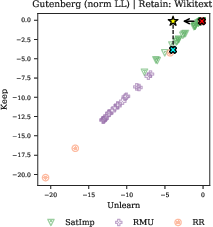
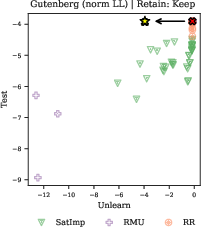
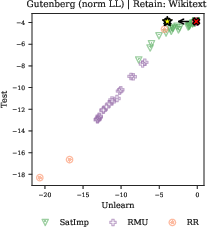
Figure 9: Unlearning methods do not achieve the desired trade-off between forgetting targeted data and retaining general knowledge, as shown for Gutenberg Unpopular passages.
Implications and Future Directions
Hubble establishes two best practices for mitigating memorization risk: (1) dilute sensitive data by increasing corpus size, and (2) order sensitive data to appear early in training. These findings have direct implications for copyright and privacy compliance, as well as for the design of future LLM training pipelines.
The suite provides a foundation for further research on:
- Mechanisms and localization of memorization in transformer architectures.
- Development and validation of robust memorization metrics.
- Evaluation and improvement of unlearning and knowledge editing methods.
- Policy-relevant analyses of LLM training practices and their legal ramifications.
Hubble's open-source release, with full transparency of data, code, and checkpoints, sets a new standard for reproducibility and scientific rigor in LLM memorization research.
Conclusion
Hubble represents a significant advance in the empirical paper of LLM memorization, providing the community with a scalable, controlled, and open platform for causal analysis across multiple risk domains. The suite's findings on dilution, ordering, and scaling inform both technical and policy responses to memorization risks. Hubble's design enables robust benchmarking of membership inference and unlearning, and its extensibility invites further research on the mechanisms, measurement, and mitigation of memorization in LLMs.