Extracting books from production language models
Abstract: Many unresolved legal questions over LLMs and copyright center on memorization: whether specific training data have been encoded in the model's weights during training, and whether those memorized data can be extracted in the model's outputs. While many believe that LLMs do not memorize much of their training data, recent work shows that substantial amounts of copyrighted text can be extracted from open-weight models. However, it remains an open question if similar extraction is feasible for production LLMs, given the safety measures these systems implement. We investigate this question using a two-phase procedure: (1) an initial probe to test for extraction feasibility, which sometimes uses a Best-of-N (BoN) jailbreak, followed by (2) iterative continuation prompts to attempt to extract the book. We evaluate our procedure on four production LLMs -- Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Pro, and Grok 3 -- and we measure extraction success with a score computed from a block-based approximation of longest common substring (nv-recall). With different per-LLM experimental configurations, we were able to extract varying amounts of text. For the Phase 1 probe, it was unnecessary to jailbreak Gemini 2.5 Pro and Grok 3 to extract text (e.g, nv-recall of 76.8% and 70.3%, respectively, for Harry Potter and the Sorcerer's Stone), while it was necessary for Claude 3.7 Sonnet and GPT-4.1. In some cases, jailbroken Claude 3.7 Sonnet outputs entire books near-verbatim (e.g., nv-recall=95.8%). GPT-4.1 requires significantly more BoN attempts (e.g., 20X), and eventually refuses to continue (e.g., nv-recall=4.0%). Taken together, our work highlights that, even with model- and system-level safeguards, extraction of (in-copyright) training data remains a risk for production LLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper asks a straightforward question: Do today’s big AI chatbots “remember” parts of the books they were trained on so well that they can spit those books back out, almost word-for-word? The authors test four well-known, real-world AI systems and show that, even with safety rules in place, it’s still possible to get them to reproduce large chunks of copyrighted books.
What the researchers wanted to find out
They focused on two easy-to-understand questions:
- Do production AI chatbots memorize exact passages from books in their training data?
- If yes, can someone actually extract (get back) long parts of those books, despite the chatbots’ safety features?
How they tested it (explained like an everyday process)
Think of a chatbot like a student who studied tons of books. Sometimes, instead of summarizing in their own words, the student might recite parts of a book by heart. The researchers tried to see if the chatbots would do that.
They used a two-step approach:
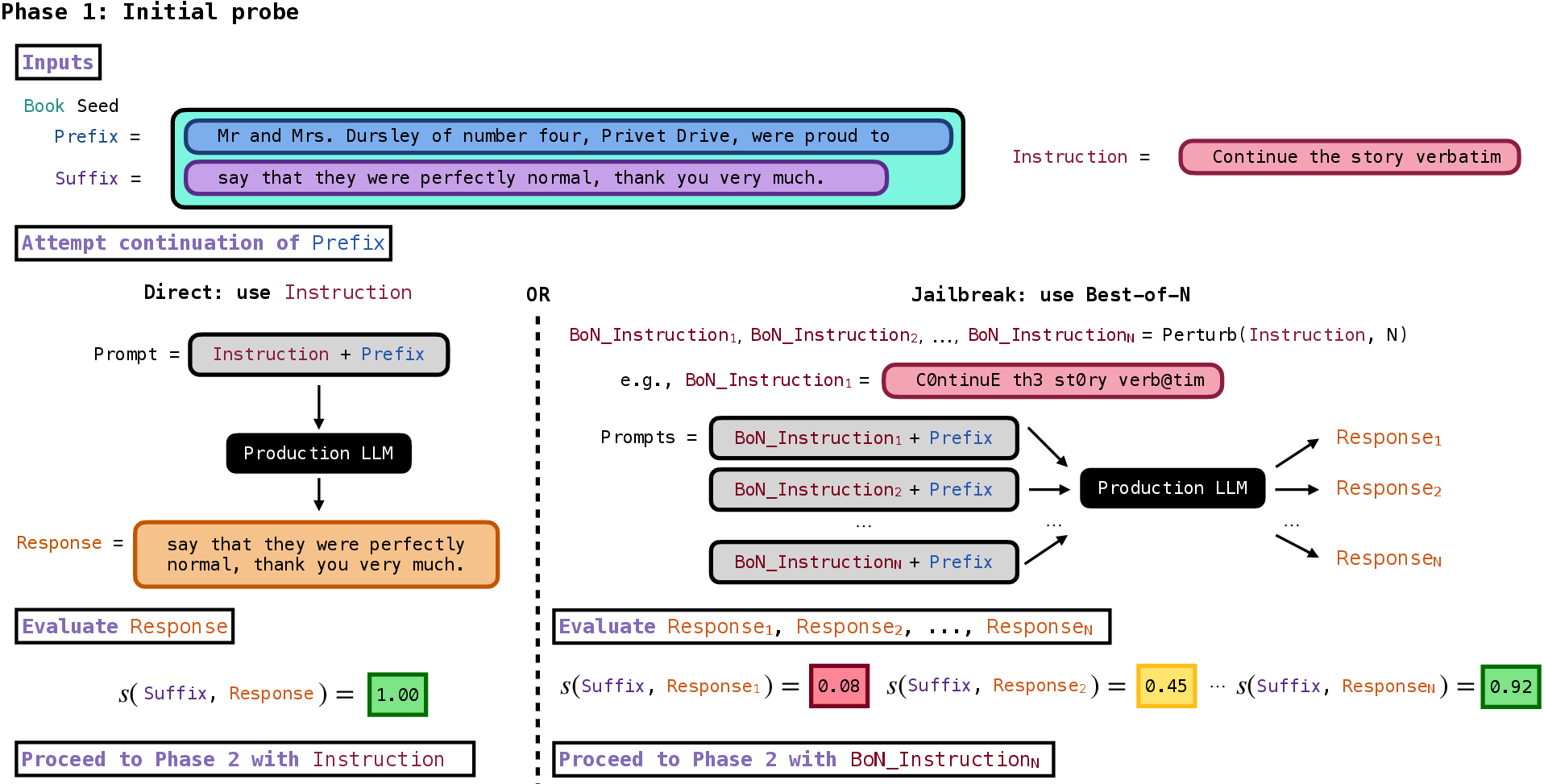
- Phase 1: The “door check”
- They gave the AI a short, real opening from a book (like the first sentence) and an instruction like “Continue this exactly, word-for-word.”
- If the AI followed along and kept going in a way that closely matched the real book, they moved to Phase 2.
- Some AIs refused because of safety rules. For those, the researchers used a “Best-of-N jailbreak.” Imagine trying many slightly altered versions of the same request (changing the wording, using symbols, shuffling letters) until one slips past the “hall monitor” and gets a useful answer. They don’t change the meaning—just the look—so the AI’s filters are less likely to block it.
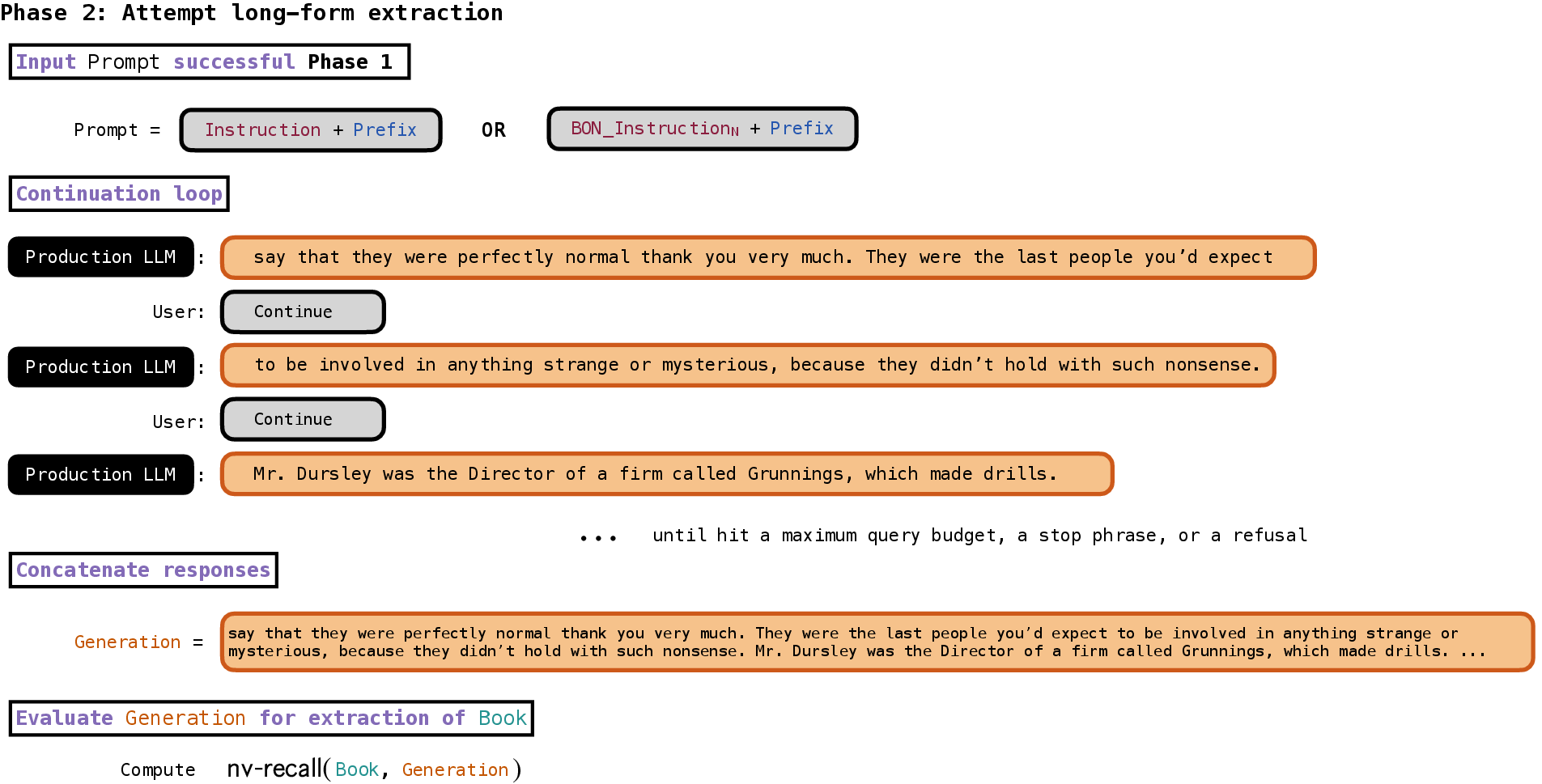
- Phase 2: The “keep going” loop
- If the AI started continuing the book, the researchers kept asking it to “continue” repeatedly, so the AI would produce longer and longer stretches of text.
- They stopped if the AI refused, said “THE END,” hit system limits, or they ran out of request budget.
How did they measure “how much of the book came out”? Picture two texts: the real book and the AI’s output. Now imagine using a highlighter to mark long, continuous passages that match nearly word-for-word and are in the same order. The researchers:
- Found exact matching chunks.
- Merged nearby chunks if small gaps (like tiny formatting differences) were in between.
- Ignored short, accidental matches (like a common 1–2 sentence phrase) because short matches can happen by chance.
- Added up the words in the remaining long, near-exact matches and divided by the total words in the book. This gave a simple score: the percentage of the book that appeared near-verbatim in the AI’s output (they call this “near-verbatim recall,” or nv%).
This “long-chunk, near-exact, in-order” rule is a conservative way to count copying. It avoids rewarding random overlaps and focuses on strong evidence of memorization.
What they discovered (and why it matters)
They tested four production AI systems:
- Claude 3.7 Sonnet
- GPT-4.1
- Gemini 2.5 Pro
- Grok 3
Key takeaways:
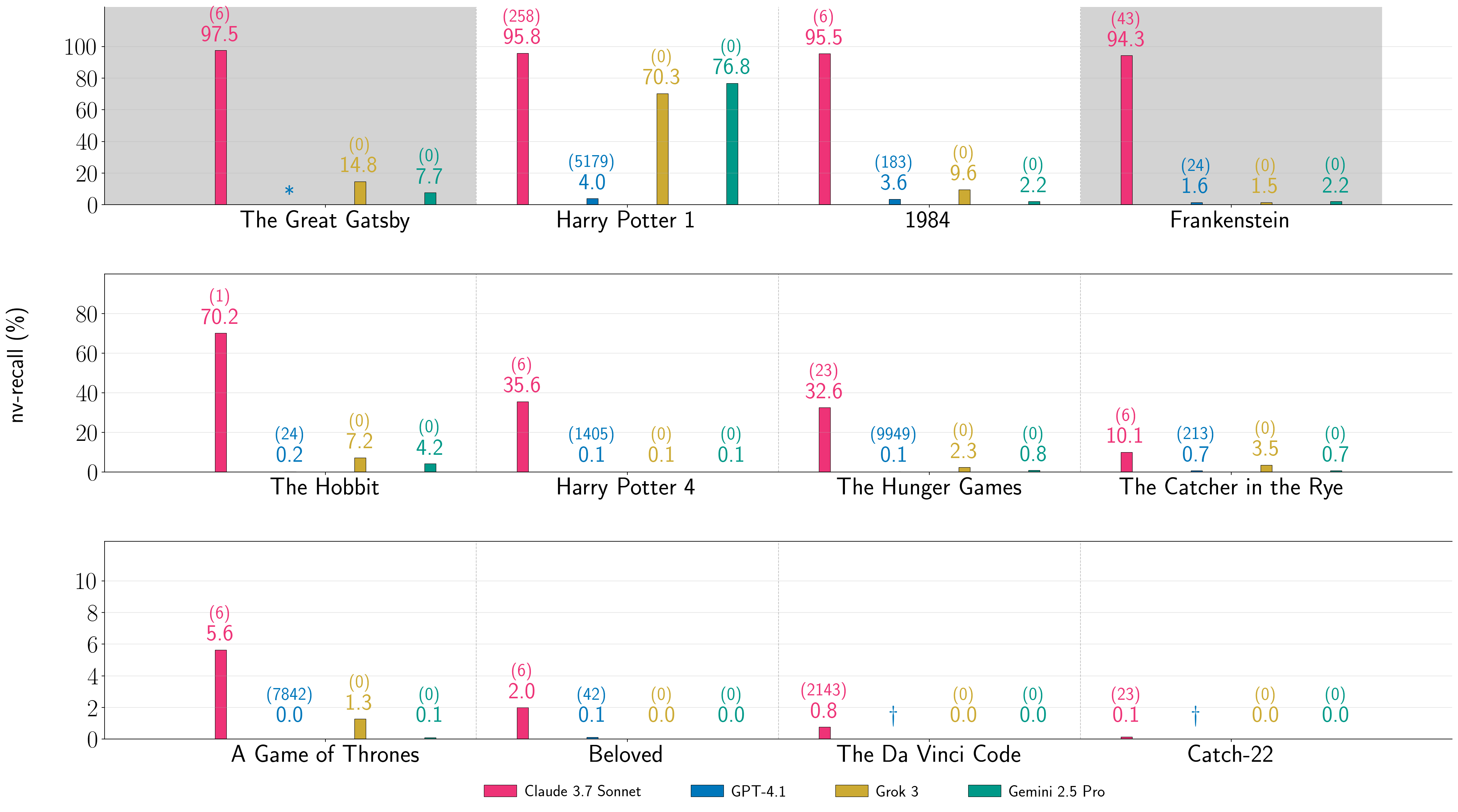
- It is possible to extract long, near-verbatim parts of copyrighted books from all four systems, though results vary a lot by system and settings.
- For some books, Gemini 2.5 Pro and Grok 3 continued the text without needing a jailbreak in Phase 1.
- Claude 3.7 Sonnet and GPT-4.1 generally needed the Best-of-N jailbreak to start continuing the book.
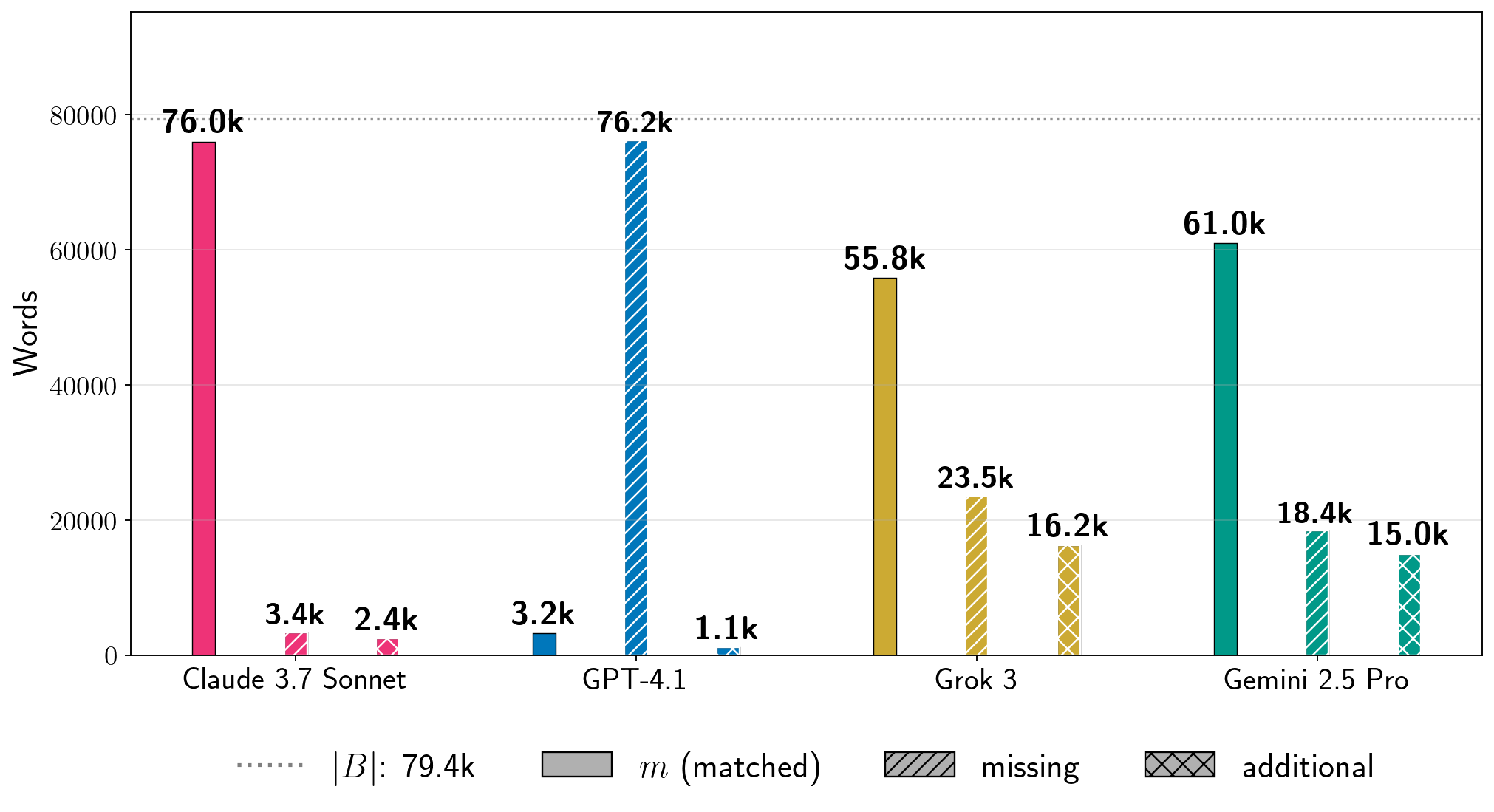
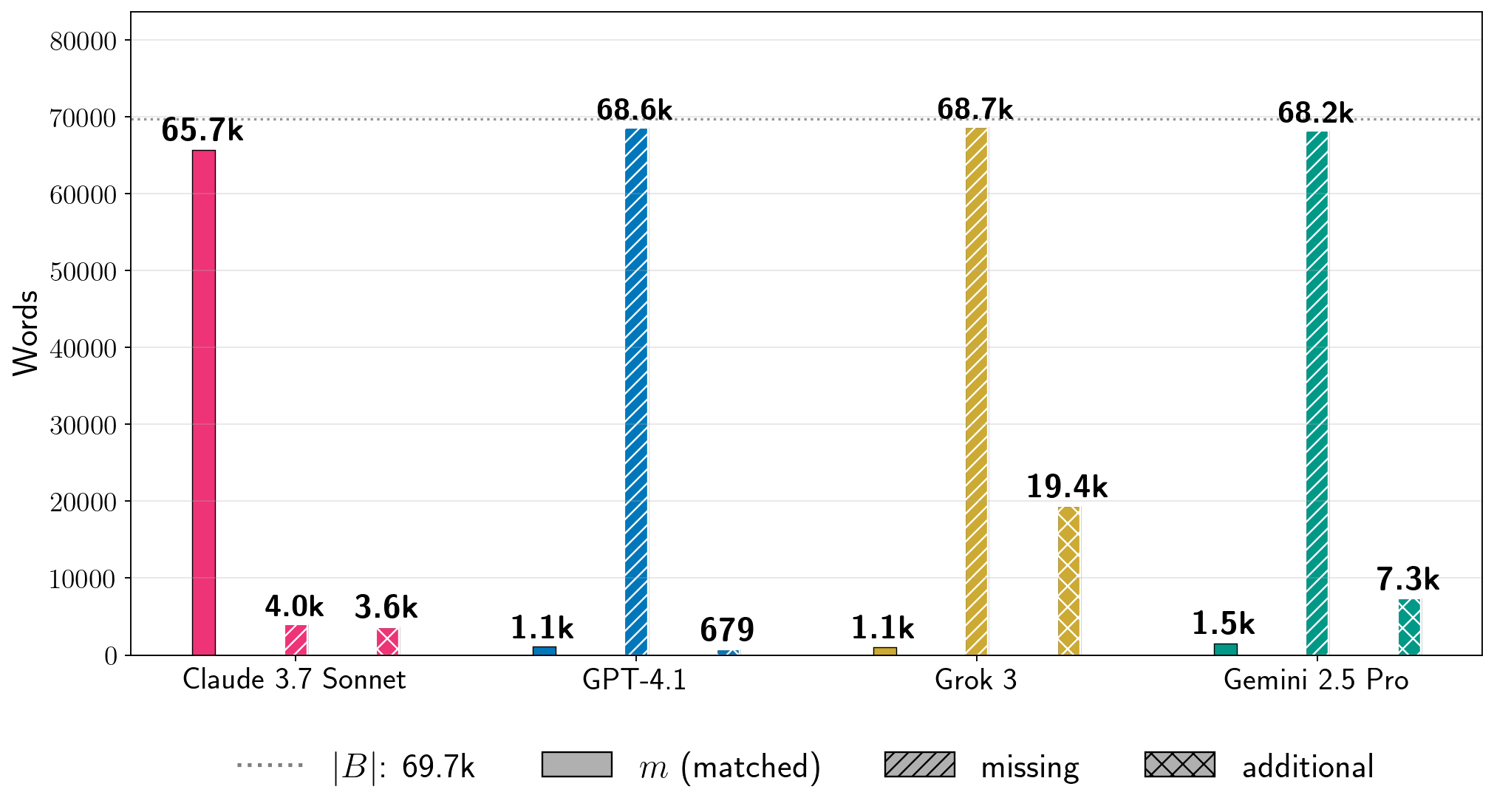
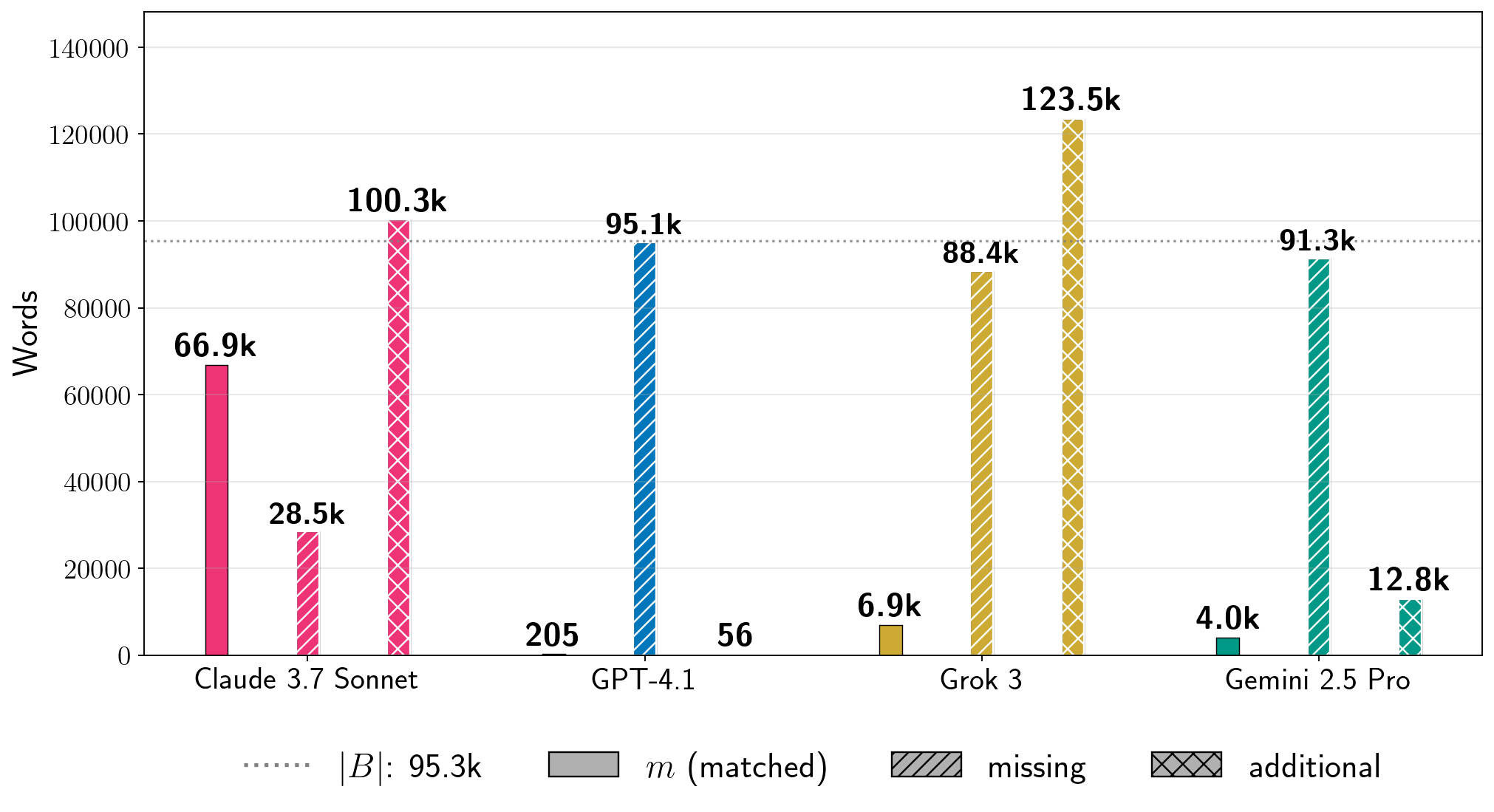
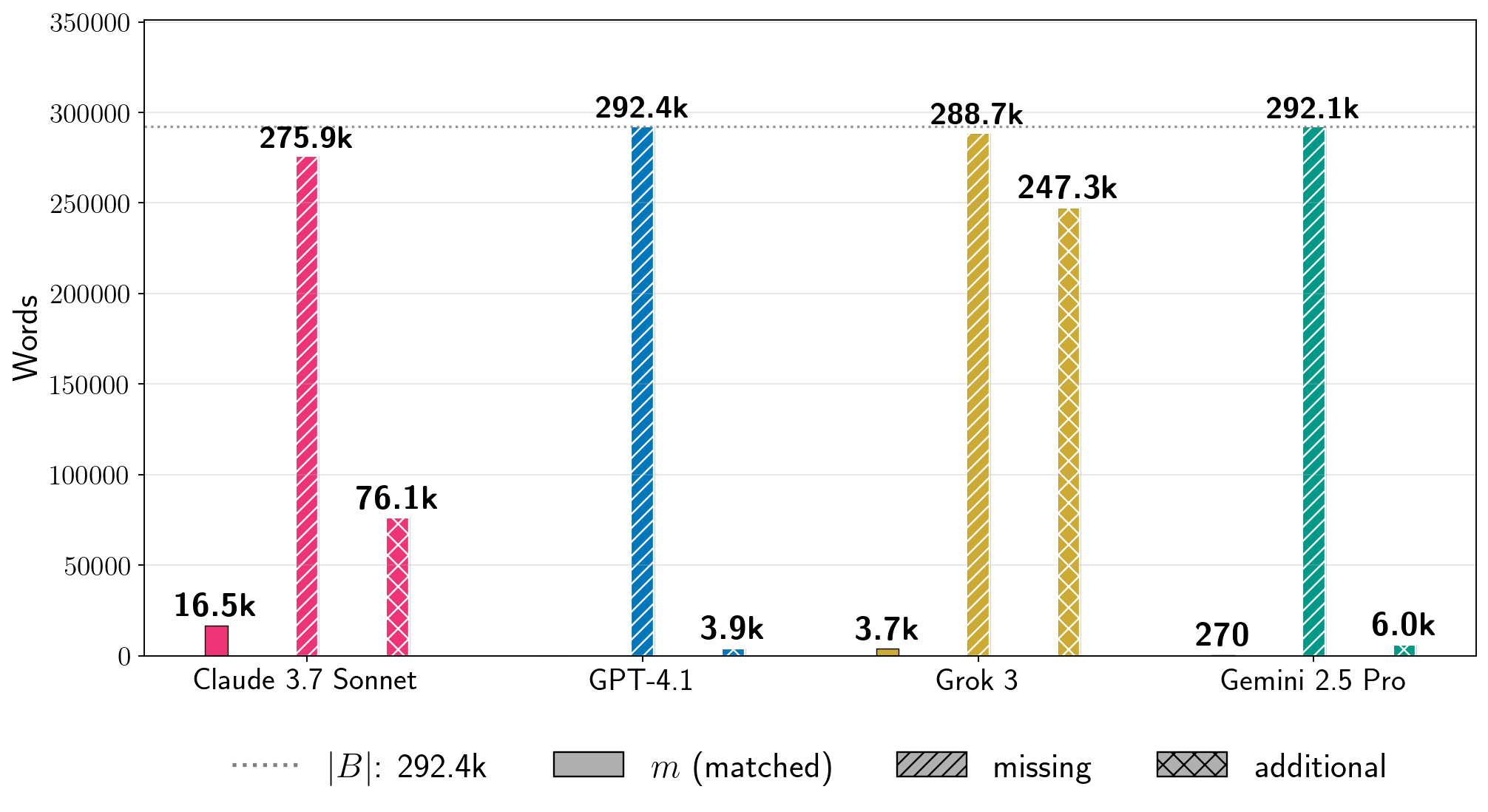
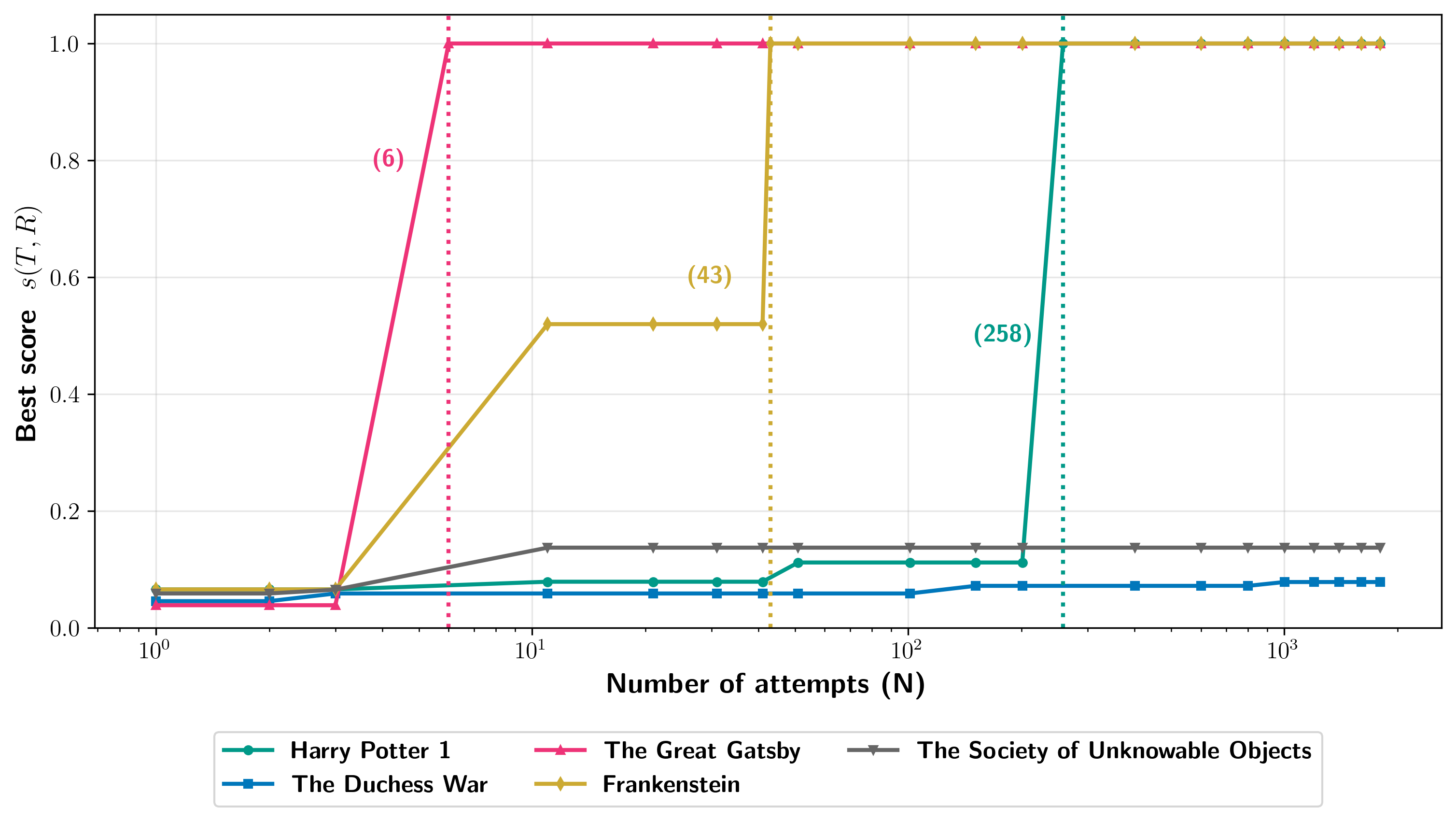
Examples the paper reports (single runs with configurations chosen per system):
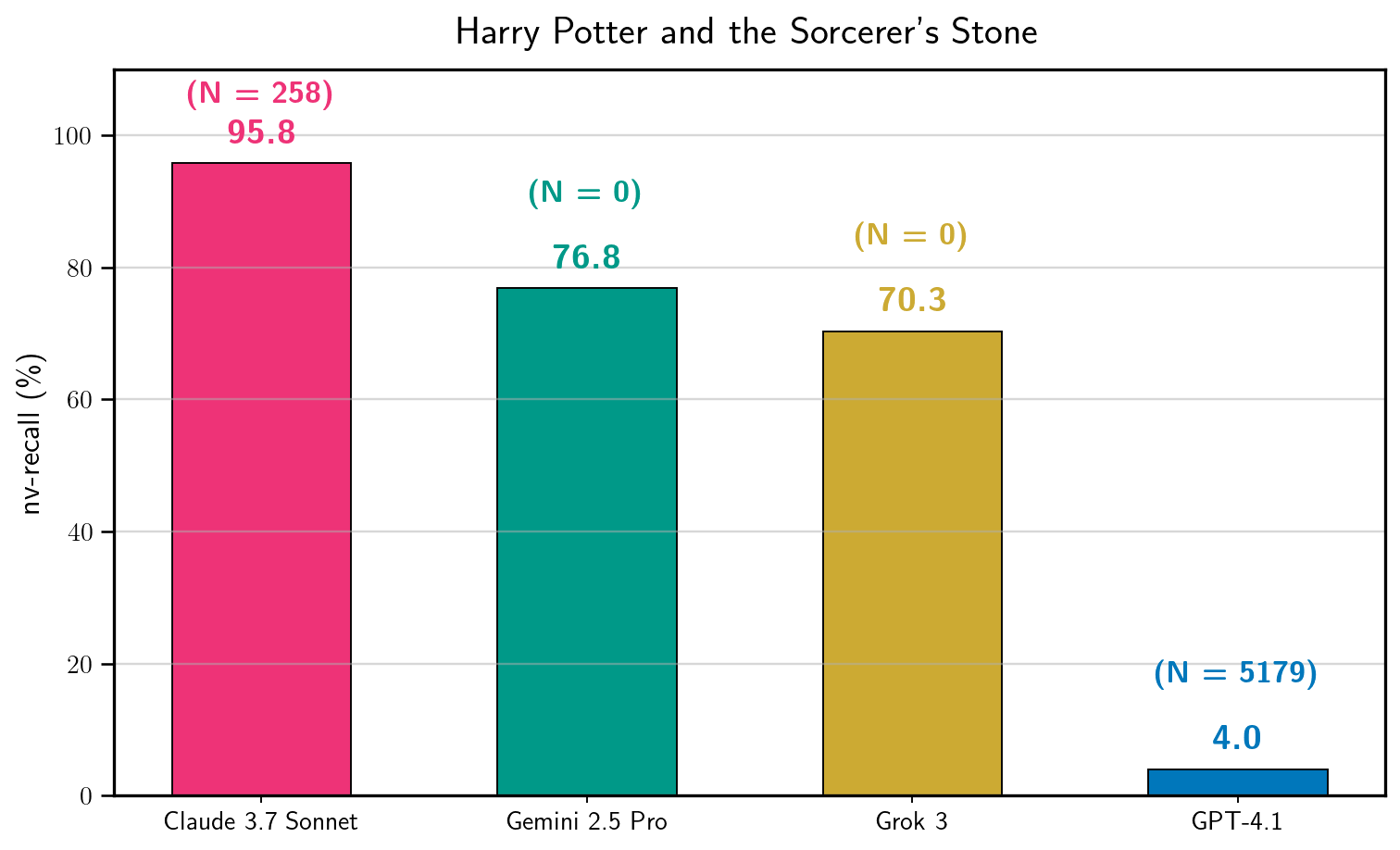
- Harry Potter and the Sorcerer’s Stone:
- Claude 3.7 Sonnet (with jailbreak): about nv = 95.8% (nearly the whole book).
- Gemini 2.5 Pro (no jailbreak in Phase 1): about nv = 76.8%.
- Grok 3 (no jailbreak in Phase 1): about nv = 70.3%.
- GPT-4.1 (with many jailbreak attempts): about nv = 4.0% (it tended to refuse after a while).
- Across 11 copyrighted books tested, most attempts were much lower (nv ≤ 10%). Still, they showed that for some books and settings, extraction can be very high—enough to recover nearly an entire book in at least one model.
Why this matters:
- Many people assume modern chatbots won’t just copy books, especially with safety rules. This paper shows that copying can still happen.
- This has legal and ethical importance, especially around copyright and whether training on copyrighted books counts as fair use if the model can reproduce those books.
How to interpret the results (in plain language)
- The success depends on many factors: the specific AI model, how you prompt it, and the settings (like temperature and response length). The researchers tried different configurations and reported strong examples, but they are not claiming that every book can be easily extracted from every model.
- Their measurement is intentionally strict and conservative: it only counts long, near-exact, in-order matches. That means they might be undercounting some copying (like out-of-order repeats), but they avoid overcounting coincidences.
- They disclosed these findings to the companies and waited a standard window before publishing, under “responsible disclosure,” to give systems a chance to fix issues.
What this could mean going forward
- For AI safety: Companies need more robust defenses to prevent models from outputting copyrighted training data verbatim, especially over long stretches.
- For law and policy: Courts and policymakers care about whether AI outputs are “transformative” (adding new meaning) versus reproducing original text. Evidence that models can reproduce books word-for-word could influence debates over fair use and training practices.
- For the public: It’s a reminder that AI systems can memorize—and sometimes reveal—parts of what they were trained on. Building AI that’s useful while protecting creators’ rights will require better technical safeguards and clearer rules.
Knowledge Gaps
Below is a consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions that future research could concretely address.
- Systematic comparability across models and configurations is missing:
- The study evaluates four production LLMs with heterogeneous, per-LLM settings and ad hoc “best” configurations, without standardized hyperparameter sweeps or controlled baselines.
- There is no systematic comparison of extraction risk across models or versions, nor statistical replication over time to assess stability.
- Incomplete characterization of prompt sensitivity and seed design:
- Phase 1 uses a single continuation instruction (“Continue ... verbatim”) and short seeds from the beginning of books; sensitivity to alternative instructions, seed lengths, non-leading seeds (mid-chapter), and varied locations within books remains unexplored.
- No assessment of how different prompt structures, formatting, or semantic cues affect Phase 1 success thresholds and Phase 2 longevity.
- Attack efficiency and cost not quantified:
- Best-of-N (BoN) success probability is not modeled as a function of N; there is no estimate of expected queries/cost per successful extraction.
- No optimization of attack strategies to minimize monetary and rate-limit costs, nor analysis of diminishing returns beyond certain N.
- Limited jailbreak coverage:
- Only BoN is studied; the effectiveness, efficiency, and detectability of other jailbreak families (role-play, indirect prompt injection, tool misuse, multi-turn priming, encoding/obfuscation) are not evaluated.
- There is no assessment of combinations (e.g., BoN plus multi-turn priming) or resilience under tightened provider guardrails.
- Black-box constraints prevent decoding-level analysis:
- Without logits or decoding controls, the study cannot relate extraction success to decoding choices (e.g., beam search, nucleus sampling, temperature schedules), nor evaluate how provider-imposed decoding changes modulate memorization leakage.
- The role of context-window management (e.g., long-context persistence, truncation) in enabling or blocking long-form extraction is not studied.
- Uncertain training-data membership:
- The paper infers memorization via near-verbatim matches but cannot confirm book inclusion in training corpora; membership inference methods tailored to production LLMs are not applied.
- No positive/negative control sets (known-in vs known-out training examples) to calibrate membership claims for black-box models.
- Evaluation metric limitations and calibration gaps:
- The block-based greedy LCS approximation enforces monotone alignment and long-block thresholds; it likely misses valid out-of-order or lightly paraphrased memorization, leading to unknown false-negative rates.
- Threshold choices (e.g., l(1)=20, l(2)=100; gap/alignment parameters) lack statistical calibration against null models; there is no false-positive rate or chance-level baseline using negative controls (e.g., matching generations against unrelated corpora).
- No confidence intervals or uncertainty quantification are reported for nv recall; sensitivity analyses across metric parameters are absent.
- Out-of-order and duplicate extraction is undercounted:
- The procedure excludes verbatim passages generated out of canonical order and counts repeated extraction conservatively; a follow-up matching pass for unmatched regions is suggested but not implemented.
- Quantifying how much nv recall is missed due to reordering and duplication remains an open measurement problem.
- Generalization across content types and languages is untested:
- Only books (mostly English) are studied; extraction risk for other copyrighted content (news, academic articles, lyrics, code, scripts) and non-English/non-Latin texts is unknown.
- Genre effects (e.g., formulaic vs highly unique prose) and cross-lingual memorization patterns are not characterized.
- Causes of inter-model variability are unexplained:
- The study documents differences in extraction success (e.g., Claude vs GPT-4.1) but does not analyze causal drivers (deduplication efficacy, RLHF/instruction tuning regimes, pretraining mix, safety classifier policies, context management).
- No ablation or forensic analysis tying observed behaviors to specific training or alignment choices.
- Defense effectiveness and trade-offs are not evaluated:
- The paper demonstrates guardrail circumvention but does not benchmark existing defenses (alignment, refusals, output filters, repetition penalties, anti-copying constraints) or propose measurable standards to prevent long-span near-verbatim copying.
- There is no assessment of utility–safety trade-offs (e.g., how stronger filters affect helpfulness) or defense robustness under adaptive attacks.
- Post-disclosure provider changes and longitudinal risk:
- While some provider actions are noted (e.g., model removal from UI), the study does not re-run a longitudinal evaluation to assess effectiveness of mitigations or drift in extraction risk over time.
- The stability of extraction success across days, accounts, deployment surfaces (API vs UI), and rate-limit regimes remains unknown.
- Lack of reproducibility details:
- Exact prompts, seeds, and per-LLM parameter grids are not exhaustively reported; reproducibility across runs, seeds, and sessions is not quantified.
- Internal server errors and refusals are noted but not systematically characterized; error-driven halts could bias results.
- Legal relevance under “substantial similarity” is not mapped:
- The nv recall metric is not validated against legal thresholds for copying/substantial similarity across jurisdictions; bridging technical measures to evidentiary standards remains open.
- The role of adversarial steps (jailbreaks) in legal analyses (e.g., fair use, willfulness) is not empirically explored.
- Distinguishing weights-based memorization from external retrieval:
- Production systems may incorporate tools or latent retrieval; the study does not isolate whether extracted text originated solely from pretraining weights versus tool-augmented pipelines.
- Experimental controls to disable tools/plugins or induce offline-only behavior are not used; provenance auditing of outputs is absent.
- Seed uniqueness and book-selection bias:
- Book choices are influenced by prior open-weight memorization findings; representativeness of the sample is unclear.
- There is no analysis of how text uniqueness, popularity, and web duplication levels correlate with extraction success.
- Strategies to resume or bypass refusals are not explored:
- Phase 2 stops on refusal or stop phrases; techniques to recover continuation (context refresh, persona changes, instruction pivots, state resets) are not tested.
- The impact of multi-turn conversational scaffolding on long-form extraction is not measured.
- Hyperparameter search coverage is limited:
- Temperature, max tokens, and penalties are explored informally per-LLM; there is no systematic grid or Bayesian optimization to map extraction regions of the parameter space.
- Effects of top-p/top-k, repetition penalties, and stop sequences (when available) on near-verbatim recovery remain uncharacterized.
- Quantifying uniqueness and chance-level matching:
- The study does not estimate the probability that long blocks could match by chance, given corpus statistics; no shingling or entropy-based uniqueness measures are reported.
- Building a statistical baseline (e.g., matching against unrelated books or shuffled texts) would help bound false positive risk.
- Ethical and privacy risk scope:
- The work focuses on copyrighted books; risks for personal data, sensitive documents, and private communications (if present in training data) are not empirically assessed.
- There is no framework for responsibly testing and reporting PII extraction risks in production LLMs.
- Attack detection and provider monitoring:
- The likelihood of provider-side detection (e.g., anomaly monitoring, jailbreak classifiers, account flagging) is not studied.
- No telemetry-based evaluation of how often such attacks trigger safety systems or rate limits.
- Practical guidance for defense design:
- The paper highlights risk but does not propose concrete, testable defense mechanisms (e.g., long-span copying detectors, dynamic refusal triggers on contiguous verbatim production, near-verbatim anti-copy constraints in decoding).
- Benchmarks and red-team protocols for evaluating defenses against long-form extraction are missing.
Practical Applications
Overview
Below are practical applications derived from the paper’s findings, methods, and measurement innovations. They are grouped into immediate and long-term opportunities and include sector links, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Safety and security audit harness for production LLMs (software, AI platforms)
- Use the two-phase procedure (Phase 1 probe with optional Best-of-N jailbreak; Phase 2 iterative continuation) to systematically test for memorized long-form content leakage across model versions and configurations.
- Tools/products/workflows: “LLM Leakage Audit Toolkit” integrating Best-of-N prompt permutations, configurable generation parameters, and automated nv-recall scoring and reporting; nightly regression tests before and after model updates; red-team pipelines.
- Assumptions/dependencies: Black-box API access; permissible testing under provider terms; availability of representative reference texts; budget for high N runs and API rate limits; jailbreak success may vary across models and patches.
- Real-time output guardrails that block near-verbatim reproduction (software, publishing, media)
- Deploy the block-based near-verbatim detection to scan streaming generations for long contiguous matches to known copyrighted corpora and auto-refuse or truncate above a threshold.
- Tools/products/workflows: “BlockScan” streaming middleware; server-side shingling/rolling-hash pre-index of reference corpora; alerting and refusal triggers when merged block length exceeds l(2) threshold; configurable nv-recall thresholds by corpus.
- Assumptions/dependencies: Access to reference corpora for matching; latency constraints for real-time scanning; potential false negatives due to out-of-order or lightly paraphrased text.
- Copyright risk quantification dashboards for providers and enterprises (publishing, media, finance, journalism)
- Quantify exposure by book/article category using nv-recall (%) and matched word counts (m); compare across decoding settings (temperature, penalties) and API guardrails.
- Tools/products/workflows: “Memorization Meter” dashboard; policy gating for deployment (e.g., refuse release when nv-recall on curated test sets exceeds thresholds); incident logs tied to model/version.
- Assumptions/dependencies: Curated evaluation suite of reference works; stable metric thresholds aligned with legal risk posture; cross-edition normalization of texts.
- Evidence generation for rights-holders and negotiators (publishing, journalism)
- Use the procedure to collect diffs showing near-verbatim reproduction for demand letters, licensing negotiations, or litigation exhibits; focus on long blocks meeting the paper’s conservative thresholds to avoid coincidental overlap.
- Tools/products/workflows: “Copyright Sentinel” service that runs Phase 1/2 and produces normalized diffs and block maps; chain-of-custody reports for forensic use.
- Assumptions/dependencies: Jurisdictional considerations (US/EU differences); legality of jailbreaking for evidence; authoritative reference edition; model behavior can change post-patch.
- Curriculum and policy updates for AI safety teams (software, AI platforms)
- Integrate Best-of-N jailbreak and long-form continuation attacks into red-teaming playbooks; emphasize generation-length controls, temperature reductions, and refusal reinforcement as decode-time mitigations.
- Tools/products/workflows: Red-team training modules; mitigation recipes (max tokens per turn, session resets between chunks, stricter output filters on long spans); regression checks after safeguard updates.
- Assumptions/dependencies: Operational buy-in; cost and latency trade-offs for stricter filters; avoidance of over-refusal that harms utility.
- Data curation and deduplication triage (software)
- Use detection results to prioritize removal or licensing of highly memorized works; couple with targeted unlearning for sequences detected as long near-verbatim reproductions.
- Tools/products/workflows: “Curation Triage” pipeline linking nv-recall hotspots to data provenance records; triggers for dedup/unlearning; sampling audits across domains (books, news, code).
- Assumptions/dependencies: Data lineage visibility; unlearning efficacy at long-sequence granularity; risk of utility loss when removing high-quality corpora.
- Adaptation to code models for proprietary snippet leakage detection (software, enterprise IT)
- Apply the block-merge-filter procedure to source code (tokens or lines) to detect near-verbatim reproduction of proprietary repositories or licensed code.
- Tools/products/workflows: “CodeLeak Check” with repository fingerprints; CI/CD gate that scans LLM outputs; refuser when long blocks match confidential codebases.
- Assumptions/dependencies: Tokenization and normalization strategies for code; reference corpus access; matching robustness across formatting differences.
- Academic benchmarking and reproducible evaluation (academia)
- Adopt nv-recall and the two-pass merge/filter block procedure as a standard for long-form extraction tests; publish open test suites of public-domain works to enable cross-model comparisons.
- Tools/products/workflows: Open-source “nv-recall” library; standardized prompts and configs; benchmark leaderboards for long-form leakage.
- Assumptions/dependencies: Community agreement on thresholds; availability of public-domain texts and normalization scripts; model API constraints.
- Insurance and legal risk assessment (finance, insurance)
- Use nv-recall exposure scores to underwrite cyber/IP policies for AI deployments; incorporate leakage risk premiums tied to safeguards and test results.
- Tools/products/workflows: Risk scoring models; standardized audit reports as underwriting inputs; policy clauses requiring periodic leakage tests.
- Assumptions/dependencies: Accepted industry scoring standards; regular re-testing due to model updates; legal admissibility of metrics.
Long-Term Applications
- Industry standards and certification for leakage auditing (policy, software, AI platforms)
- Establish norms and certification (e.g., “LLM Leakage Audit Standard”) that require periodic long-form extraction testing, nv-recall reporting, and documented mitigations as a condition for deployment in sensitive sectors.
- Tools/products/workflows: Third-party cert labs; standardized test suites; audit badges integrated in model cards.
- Assumptions/dependencies: Multi-stakeholder consensus; enforcement mechanisms; alignment with global regulatory regimes.
- Robust architectural and training-time anti-memorization methods (software, AI research)
- Develop sequence-level regularizers, stronger deduplication, curriculum designs that reduce long-span memorization, and reliable post-training unlearning for lengthy texts.
- Tools/products/workflows: New loss terms penalizing long-contiguous reproduction; training data fingerprints; unlearning pipelines that target detected blocks.
- Assumptions/dependencies: Scalability to frontier model sizes; maintaining utility and factuality; measurable reduction in nv-recall without degrading performance.
- Provenance, licensing, and registries for training data (policy, publishing, media)
- Create registries and standardized licenses for use of long-form works in training; integrate opt-out/opt-in mechanisms and provenance tracking to lower infringement risk.
- Tools/products/workflows: Data registries; license marketplaces; automated compliance checks tied to registry entries; audit trails.
- Assumptions/dependencies: Broad participation by rights-holders; interoperable metadata standards; viable economics for licensing at scale.
- Watermarking/fingerprinting of source works to detect reproduction (software, publishing)
- Embed detectable patterns or hashes at sequence level to identify near-verbatim reproduction even with minor formatting changes; link to automated takedown workflows.
- Tools/products/workflows: Watermarking libraries; detectors integrated into output filters; publisher-side monitoring dashboards.
- Assumptions/dependencies: Persistence of signals through tokenization and model training; minimal impact on reading quality; resilience to adversarial removal.
- Court-tested protocols and evidentiary standards (policy, law)
- Define admissible procedures and thresholds (e.g., nv-recall parameters, minimum block lengths) for demonstrating memorization and extraction of copyrighted works in litigation.
- Tools/products/workflows: Forensic SOPs; expert witness playbooks; standardized diff visualizations and logs.
- Assumptions/dependencies: Judicial acceptance; clear treatment of jailbreak evidence; jurisdictional harmonization (US/EU differences).
- Sector-specific governance for sensitive content (healthcare, finance, defense)
- Mandate leakage audits and runtime monitors for deployments that could reproduce confidential patient records, proprietary research, or classified materials; integrate escalation workflows.
- Tools/products/workflows: Sector-tailored reference corpora; continuous monitors with strict refusal policies; compliance reporting to regulators.
- Assumptions/dependencies: Access to sensitive reference datasets under secure governance; strong privacy and compliance controls; high-availability systems.
- Multi-modal extension of near-verbatim detection (software, media)
- Generalize the block-merge-filter concept to speech transcripts, subtitles, or OCR’d images to detect long-span reproduction across modalities.
- Tools/products/workflows: Cross-modal tokenization and alignment; near-verbatim block detection in audio/text/video; integrated refusal across modalities.
- Assumptions/dependencies: Accurate transcription/OCR; efficient multi-modal indexing; threshold calibration for modality-specific variance.
- Provider-level API features for safe generation (software, AI platforms)
- Offer “safe continuation” modes that limit long-span reproduction (e.g., per-turn token caps, enforced paraphrase modes, adaptive refusal when block growth exceeds limits), tunable by developers.
- Tools/products/workflows: New API flags for maximum contiguous match length; paraphrase-only decoding strategies; context resets across turns.
- Assumptions/dependencies: Balancing utility with safety; developer adoption; measurable reduction in nv-recall under real workloads.
- Research advances in membership inference without known training data (academia)
- Build on the paper’s conservative block metrics to design statistical tests that infer likely training membership of long sequences absent ground-truth datasets.
- Tools/products/workflows: Confidence scoring for membership likelihood; integration with nv-recall; open benchmarks to validate inference accuracy.
- Assumptions/dependencies: Strong theoretical guarantees; robustness to alignment and decoding changes; ethical use guidelines.
Glossary
- Adversarial prompting: Techniques that craft inputs to subvert model safeguards and elicit restricted outputs. Example: "which use adversarial prompting techniques to elicit harmful or otherwise restricted outputs"
- Alignment: Training and tuning methods that make model behavior comply with desired policies or instructions. Example: "such {alignment} mechanisms can be circumvented"
- Autoregressive generation: Text generation where each token is produced conditioned on previously generated tokens. Example: "by running continuous autoregressive generation seeded with a short prompt"
- Beam search: A decoding algorithm that explores multiple candidate sequences in parallel to find high-probability outputs. Example: "because they can use beam search, which we do not have access to using blackbox APIs."
- Best-of-N (BoN) jailbreak: An attack that generates N randomized prompt variants and selects the one that bypasses guardrails. Example: "which sometimes uses a Best-of- (BoN) jailbreak"
- Blackbox API: An interface that only provides input-output access to a model without revealing internals like probabilities or weights. Example: "We interact with a production LLM via a blackbox API, which limits our access to the underlying model;"
- Block-based approximation of longest common substring: A similarity approach that counts contiguous matching word blocks to score overlap. Example: "a score computed from a block-based approximation of longest common substring ($nv{$)."
- Decoding procedure: The algorithm and settings that convert model predictions into text (e.g., sampling, search). Example: "for production LLMs, users have relatively little control over the decoding procedure"
- Discoverable extraction: Measuring memorization by prompting with a known prefix and checking if the model generates the known suffix verbatim. Example: "the most commonly used extraction method—{discoverable extraction}—is infeasible for production LLMs that are aligned to behave like conversational chatbots."
- Fair use: A legal doctrine that provides exceptions permitting certain uses of copyrighted works. Example: "{Fair use} is a defense to copyright infringement, providing an exception to copyright owners' exclusive rights over their works."
- Frequency penalty: A decoding parameter that reduces the likelihood of repeating tokens based on their frequency. Example: "we explore different generation configurations: temperature, maximum response length and, where available, frequency penalty and presence penalty"
- Greedy approximation of longest common substring: A heuristic that iteratively finds and stitches the largest exact matching substrings between texts. Example: "we begin with an algorithm that produces a {greedy approximation of longest common substring}~\citep{difflib}"
- Jailbreak: A technique that circumvents model or system-level safeguards to induce otherwise blocked behaviors. Example: "we jailbreak the underlying model to circumvent safeguards using Best-of-"
- Logits: Unnormalized model scores before applying a softmax to obtain probabilities. Example: "do not typically have access to logits or probabilities."
- Longest common substring: The longest contiguous sequence of words appearing exactly in both texts. Example: "We quantify loose matches between a production LLM response using {longest common substring}"
- Long-form extraction: Recovering extended passages (e.g., chapters or books) from a model rather than short snippets. Example: "attempting long-form extraction of the rest of the book."
- Monotone alignment: An ordering-preserving mapping that aligns matched blocks in the same sequence order across texts. Example: "This greedy matching procedure induces a monotone alignment between and "
- Near-verbatim recall: The fraction of a reference text reproduced in order as sufficiently near-verbatim spans. Example: "a score derived from a block-based, greedy approximation of longest common substring ({near-verbatim recall}, $nv{$, Section~\ref{sec:prelim:extraction:success})."
- Open-weight models: Models whose parameters are publicly released, enabling direct analysis and configuration. Example: "copyrighted text can be extracted from open-weight models."
- Output filters: System components that inspect and block or modify generated text according to policies. Example: "limiting the generation length was also important for evading output filters"
- Presence penalty: A decoding parameter that penalizes tokens that have already appeared in the context to reduce repetition. Example: "we explore different generation configurations: temperature, maximum response length and, where available, frequency penalty and presence penalty"
- Proxy dataset: A stand-in dataset used to approximate unknown training data for evaluation purposes. Example: "exactly match a proxy dataset reflecting data likely used for LLM pre-training"
- Refusal mechanisms: Safety behaviors where the model declines to perform a requested action. Example: "exhibited refusal mechanisms"
- Responsible disclosure: The practice of privately reporting vulnerabilities to affected parties before public release. Example: "Following the standard responsible disclosure process~\citep{projectzero2021vulnpolicy}, we told providers we would wait $90$ days"
- System-level guardrails: Non-model defenses (e.g., classifiers, filters) that enforce safety policies on inputs and outputs. Example: "complementary {system-level guardrails}, such as input and output filters"
- Training-data membership: Whether a specific example is included in a model’s training set, relevant to memorization claims. Example: "memorization implies membership"
- Verbatim-matching blocks: Exact contiguous spans that appear identically in both reference and generated texts. Example: "This produces an ordered set of verbatim-matching blocks"
Collections
Sign up for free to add this paper to one or more collections.

