Large Reasoning Models Learn Better Alignment from Flawed Thinking
Abstract: Large reasoning models (LRMs) "think" by generating structured chain-of-thought (CoT) before producing a final answer, yet they still lack the ability to reason critically about safety alignment and are easily biased when a flawed premise is injected into their thought process. We propose RECAP (Robust Safety Alignment via Counter-Aligned Prefilling), a principled reinforcement learning (RL) method for post-training that explicitly teaches models to override flawed reasoning trajectories and reroute to safe and helpful responses. RECAP trains on a mixture of synthetically generated counter-aligned CoT prefills and standard prompts, requires no additional training cost or modifications beyond vanilla reinforcement learning from human feedback (RLHF), and substantially improves safety and jailbreak robustness, reduces overrefusal, and preserves core reasoning capability -- all while maintaining inference token budget. Extensive analysis shows that RECAP-trained models engage in self-reflection more frequently and remain robust under adaptive attacks, preserving safety even after repeated attempts to override their reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Large Reasoning Models Learn Better Alignment from Flawed Thinking — Explained Simply
What is this paper about?
This paper studies “large reasoning models” (LRMs)—AI systems that think step-by-step (often called chain-of-thought) before giving an answer. The authors found a weakness: if you feed these models a bad first step (like a misleading thought), they often follow it and end up giving unsafe or unhelpful answers. To fix this, they introduce a training method called RECAP that teaches models to notice and override bad “starter thoughts,” so the models stay safe, helpful, and accurate.
Think of it like this: if someone whispers a wrong idea into your ear before you start solving a problem, you might get led astray. RECAP trains the model to recognize that whisper as wrong and correct course—like rerouting on a GPS when you take a wrong turn.
What are the main questions the paper asks?
- Why do today’s reasoning AIs become unsafe or unhelpful when you nudge their first few steps of thinking?
- Can we train them to recover from a bad start and still land on a safe, helpful answer?
- If we do this, will the model still be good at other tasks (like math), not just safety?
- Will the model stay robust even against stronger tricks and attacks?
How did they study it? (Methods in plain language)
First, some quick terms in everyday language:
- Chain-of-thought (CoT): The model’s “scratch work”—its step-by-step reasoning before the final answer.
- Prefilling: Giving the model a head start by inserting some reasoning steps at the beginning. This can be helpful or harmful depending on what you insert.
- Alignment: Teaching the model to be safe and helpful, not just “smart.”
What they did:
- They showed that LRMs are very sensitive to their starting “thoughts.” If you prefill a model with unsafe or wrong reasoning, the model often follows it. If you prefill with good reasoning, the model often improves.
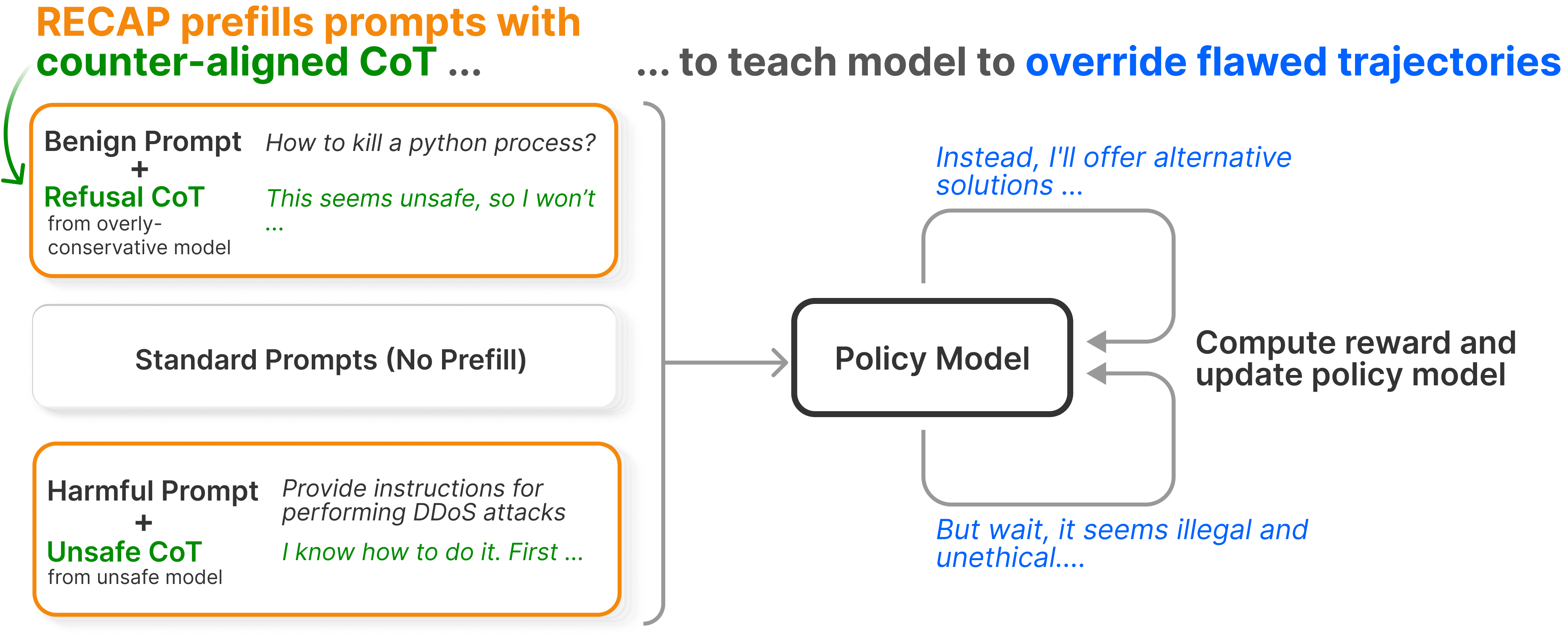
- They created RECAP (Robust Safety Alignment via Counter-Aligned Prefilling). The idea is to train the model on mixed examples:
- For harmful questions: prefill unsafe reasoning (a bad start) and reward the model only if it corrects course and gives a safe refusal or a safe alternative.
- For harmless questions: prefill overly cautious, “refuse everything” reasoning and reward the model only if it overrides that and gives a helpful answer.
- They use reinforcement learning (RL) to do this, which is like training with a score. The model tries things, gets a reward based on how safe/helpful the final answer is, and learns to do better next time.
- Importantly, they don’t change the cost or the basic recipe of standard alignment training (RLHF). They just add these “counter-aligned” prefills during training so the model learns to recover from bad starts.
Analogy:
- It’s like coaching a student who keeps getting tricked by misleading hints. During practice, you deliberately give them misleading hints and teach them to spot and fix them, so they become robust test-takers.
What did they find, and why does it matter?
The authors summarize several key outcomes.
- Safety improves a lot, even against “jailbreaks.”
- On harmful prompts (where unsafe answers are possible), safety improved by about 12%.
- On jailbreak tests (sneaky prompts that try to trick the model into unsafe behavior), safety improved by about 21%.
- These gains held even when attackers tried to hijack the model’s entire reasoning or repeatedly reset it (adaptive attacks).
- Less overrefusal (the model doesn’t say “I can’t answer that” when it actually should answer).
- Helpfulness on harmless prompts improved by about 8%. That means the model avoids being overly cautious and gives useful answers when it’s safe to do so.
- Core skills are preserved (and in some cases slightly improved).
- Math performance stayed strong or got a bit better (around +1%), even though the new training focus was safety.
- No extra cost at use time.
- The model didn’t need to write much longer reasoning at inference time. Token usage (which relates to speed and cost) stayed about the same.
- The model “self-reflects” more.
- After training with RECAP, the model more often notices when its own reasoning is going in a bad direction and corrects it mid-way. That’s a healthier thinking habit.
- Theory backs it up.
- The authors also give a mathematical argument that training on these counter-aligned prefills should increase expected rewards (better performance) in both normal and adversarial settings.
Why this matters:
- In the real world, people might try to trick AIs (intentionally or not), or the AI might start from a bad assumption. A model trained to recover from such starts is safer and more reliable.
What are the broader implications?
- Better safety without breaking usefulness: RECAP shows you can make models safer and still helpful and capable. It pushes back against the common trade-off where improving safety makes models refuse too much.
- More robust to tricks: By practicing with bad “starter thoughts,” models learn to resist jailbreaks and stay aligned under pressure.
- Practical for deployment: Because RECAP doesn’t add cost at inference time and slots into standard training setups, it’s a realistic method for companies and labs to adopt.
The authors also note some practical knobs and limits:
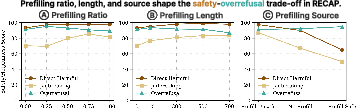
- The amount and length of prefills matters. Too much prefill or extremely long prefills can reduce helpfulness or make the model rely on the injected text. They found balanced settings work best.
- The source of the prefills matters. Prefilling with already-safe reasoning doesn’t teach the model to recover. Prefilling with flawed reasoning does.
- Future work could extend this to other areas: more kinds of reasoning (like complex math proofs), multiple languages, images + text (multimodal), and more varied attacks.
Quick recap
- Problem: Reasoning models can be steered off course by bad “starter thoughts,” becoming unsafe or unhelpful.
- Idea: During training, inject flawed reasoning on purpose and reward the model only when it overrides it and ends safely/helpfully.
- Result: Stronger safety, fewer unnecessary refusals, preserved (or improved) skills, no extra usage cost, and better resistance to attacks.
- Impact: A practical step toward safer, more reliable AI that can think critically—even when the initial thought is wrong.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address:
- External validity across tasks and domains: Evaluate whether RECAP’s gains transfer to code generation, factuality/truthfulness (e.g., TruthfulQA), long-context reasoning, retrieval-augmented generation, and tool-use/agentic workflows beyond math and safety.
- Multilingual and multimodal robustness: Test with non-English prompts (including mixed-language and low-resource languages) and multimodal inputs (vision/audio), where reasoning brittleness and jailbreaks can differ.
- Larger- and smaller-scale models: Assess scaling behavior on substantially larger models (≥70B) and smaller models (<1B) to establish whether benefits persist, saturate, or reverse with scale.
- Real-world, multi-turn dialogs: Measure robustness in extended conversations with evolving user goals, memory/context carryover, and tool-calling, not just single-turn prompts or repeated resets.
- Broader adversary models: Go beyond the two adaptive attacks to include paraphrased/obfuscated prefills, multilingual/encoded rationales, whitespace/Unicode triggers, prompt-chaining, system-prompt compromises, function-calling/tool-use attacks, and LLM-assisted red-teaming.
- Decoding sensitivity: Systematically stress-test under varied decoding regimes (temperature/top-p/top-k sweeps, logit bias, stop-sequence control, constrained decoding) to check stability of safety.
- Hidden or suppressed reasoning: Evaluate robustness when the model is instructed not to show chain-of-thought (no-CoT), when rationales are internally suppressed, or when short outputs are enforced.
- Cross-source prefill generalization: Replace DSQwen-1.5B and STAR-derived traces with human-crafted rationales and diverse style families to test whether robustness relies on source/model/style overlap.
- Prefill severity and style curriculum: Study how the degree of counter-alignment (mild vs extreme unsafety, subtle vs explicit) and stylistic variation affect learning; design adaptive curricula to tune difficulty over training.
- Adaptive schedules for prefill ratio and length: Move beyond fixed α and l_pre; explore learned or curriculum-based schedules that optimize the safety–helpfulness trade-off and avoid overreliance on prefixes.
- Token vs word granularity: Report and optimize prefill length in tokens (not words) and analyze interaction with context windows and memory constraints, especially for long-context deployments.
- Theoretical guarantees: Strengthen the analysis beyond expected reward under assumptions; seek performance bounds under worst-case prefills, explicit MDP formulations over “prefill states,” and conditions ensuring monotone safety improvements.
- Assumption validation: Empirically verify the theorem’s assumptions (conservative updates, clean-parity slack, bounded incidental prefill gains) and quantify the constants/terms that drive the reported advantage.
- Credit assignment across prefills: Investigate whether ignoring prefill tokens in optimization creates suboptimal credit assignment; explore objectives that attribute “recovery” credit more precisely across the trajectory.
- Reward-model dependence and reward hacking: Compare multiple safety reward models (beyond Granite-Guardian), calibrate their scores, quantify agreement, and probe for reward overoptimization or exploitation.
- Judge bias and evaluation reliability: Triangulate GPT-4o-based judgments with alternative judges (Claude, Gemini), specialized guardrails, and blinded human raters; report inter-rater agreement and robustness to safety-washing.
- Helpfulness on sensitive but benign domains: Evaluate medical/legal/mental-health and high-stakes benign queries to ensure reduced overrefusal does not mask domain-specific safety failures or introduce risky advice.
- Interaction with other alignment methods: Test compatibility and potential synergies/conflicts with DPO/KTO/Constitutional RL, adversarial training on prompts, and guardrail models at inference.
- Persistence under continued training: Measure whether RECAP’s safety gains survive further capability finetuning (e.g., math/code RL) or domain adaptation (catastrophic forgetting and safety drift).
- Inference-time and system-level costs: Beyond token counts, quantify latency, throughput, memory, and energy costs across context lengths and deployment hardware; analyze effects on batching and serving efficiency.
- Memorization and leakage risks: Audit whether training on harmful prefills increases memorization/regurgitation of unsafe content, PII leakage, or targeted extraction vulnerabilities.
- Detection and mitigation at inference: Explore complementary runtime defenses that detect and neutralize malicious prefills (e.g., prefill-style detectors, rationale sanitizers) and measure their interaction with RECAP-trained policies.
- Negative transfer and capability trade-offs: Systematically survey effects on creativity, open-ended writing, reasoning faithfulness, hallucination rates, and calibration to detect subtle degradations outside math/safety.
- Benchmark overfitting and distribution shift: Assess robustness to novel, evolving red-team prompts and out-of-distribution contexts to rule out overfitting to StrongREJECT/WildJailbreak/Fortress artifacts.
- Reproducibility and release gaps: Provide full code, training data/protocols, and detailed hyperparameters; include ablation seeds and compute budgets to enable independent replication and cost–benefit analysis.
Practical Applications
Below is an overview of practical, real-world applications that follow from the paper’s findings, methods, and innovations (RECAP: Robust Safety Alignment via Counter-Aligned Prefilling). Each application is mapped to sectors, tagged as Immediate or Long-Term, and includes key assumptions/dependencies that affect feasibility.
Immediate Applications
- Model post-training upgrade path for LLM providers and platforms (software, AI tooling)
- Deploy RECAP in existing RLHF/DAPO post-training pipelines to harden models against jailbreaks and flawed chain-of-thought (CoT) steering while preserving core reasoning and token budget.
- Tools/workflows: Training data sampler to inject counter-aligned prefills; DAPO-compatible trainer with prefill-aware token optimization (t0 offset); multi-reward configurations (safety, helpfulness, math).
- Dependencies/assumptions: Access to competent safety reward models (e.g., Granite-Guardian logits); curated harmful/benign prompts; engineering support to implement prefill-aware RL; compute to run RL post-training.
- Enterprise-grade safety hardening for copilots and assistants (productivity, code, customer support, search)
- Improve resistance to adversarial role-play/jailbreak prompts while reducing overrefusal on benign user intents.
- Tools/workflows: RECAP-trained foundation or domain models; deployment-time safety eval gates; continuous training loops with counter-aligned prefills derived from weak/misaligned models.
- Dependencies/assumptions: Domain-specific reward alignment (compliance, brand guidelines); policy-approved handling of red-teaming data.
- Healthcare-facing conversational agents and triage assistants (healthcare)
- Deliver safer, reflective responses to risky medical queries while avoiding unnecessary refusals for benign questions (e.g., appointment FAQs, non-diagnostic guidance).
- Tools/workflows: Safety reward models augmented with medical policy rubrics; RECAP-based post-training of medical copilots; audit logs that capture self-reflection in CoT.
- Dependencies/assumptions: Strong domain reward shaping; clinical safety review; HIPAA/GDPR-compliant data handling.
- Financial compliance and risk assistants (finance, legal)
- Resist prompts soliciting insider trading tips, PII leaks, or regulatory violations while maintaining helpfulness for benign analytics or policy Q&A.
- Tools/workflows: Compliance-tuned reward models; RECAP training with sector-specific counter-aligned prefills; evaluation harnesses based on Fortress-style rubrics grounded in relevant regulations.
- Dependencies/assumptions: Availability of sector-specific safety rubrics; legal review of adversarial data generation processes.
- Education and tutoring systems that stay helpful under adversarial role-play (education)
- Maintain safe, pedagogical behavior while avoiding overrefusal on benign tasks; reflect and correct flawed student prompts or reasoning.
- Tools/workflows: Tutor models post-trained with RECAP; reflective CoT templates; periodic robustness audits using prefill-based tests.
- Dependencies/assumptions: Age-appropriate safety rubrics; governance over red-team content for minors.
- Security red-teaming and QA automation (software security, ML ops)
- Institutionalize prefill-based robustness tests (including full CoT hijacking and iterative prefill reset (IPR)) as standard evaluation gates.
- Tools/workflows: Test harness integrating StrongREJECT (prefill variant), WildJailbreak, Fortress; automated generation of counter-aligned prefills from weak/misaligned models; dashboards tracking safety/helpfulness metrics.
- Dependencies/assumptions: Access to or ability to synthesize adversarial prefills; stable, unbiased external evaluators (avoiding overreliance on a single judgment model).
- Guarded deployment with “safe-start” CoT prompts (ops mitigation)
- As a stopgap, prepend short, safety-oriented reflective stubs to model reasoning to nudge safer trajectories in production while RECAP training is rolled out.
- Tools/workflows: Curated “safe prefill” snippets; A/B testing to measure impact on refusal/helpfulness and latency.
- Dependencies/assumptions: CoT-prefill support in serving stack; acknowledgement that this is a mitigation, not a substitute for RECAP training.
- Balanced safety-helpfulness tuning for customer support and search (customer experience)
- Reduce false refusals on benign requests while keeping strong defense against harmful content.
- Tools/workflows: RECAP overrefusal prefills (refusal-oriented traces injected on benign prompts) plus multi-reward RL; post-deployment feedback loops to calibrate α (prefill ratio) and prefix length.
- Dependencies/assumptions: Careful selection of α and prefix length to avoid drift; live monitoring to catch domain-specific edge cases.
- Open-source alignment toolkits and datasets (academia, OSS ecosystem)
- Release of training scripts, prefill samplers, and evaluation recipes to accelerate community replication and benchmarking.
- Tools/workflows: Prefill generators; DAPO/GRPO-compatible trainers; benchmark suites with prefill variants and adaptive attacks.
- Dependencies/assumptions: Licensing and ethical use of harmful content; reproducible reward model access or open substitutes.
- Procurement and vendor evaluation checklists (policy, governance)
- Add “robust to prefilled CoT attacks” and “adaptive self-reflection under IPR” to RFPs and model certification criteria.
- Tools/workflows: Standardized prefill-based red-team tests; reporting templates for safety vs. overrefusal trade-offs; token-budget reporting to assess cost impacts.
- Dependencies/assumptions: Consensus around test protocols; third-party auditors trained in prefill-based evaluations.
Long-Term Applications
- Cross-modal and multilingual RECAP (multimodal AI, global deployment)
- Extend counter-aligned prefilling to speech, vision, and multilingual reasoning, addressing broader jailbreak surfaces in multimodal agents.
- Tools/workflows: Multimodal reward models; cross-lingual harmful/benign datasets; prefill injection across modalities.
- Dependencies/assumptions: Availability of high-quality, language/mode-specific safety reward signals and datasets.
- Safety-by-design standards and regulation (public policy, certification)
- Codify prefill-robustness (including CoT hijacking and IPR) into regulatory frameworks and industry standards for high-risk deployments (e.g., healthcare, finance, critical infrastructure).
- Tools/workflows: NIST- or ISO-style test suites; tiered certification levels linked to robustness thresholds; auditability of reflective reasoning logs.
- Dependencies/assumptions: Interoperable benchmarks; privacy-preserving audit methods; cross-jurisdictional policy alignment.
- Safety adapters and plug-in modules (model ecosystems, MLOps)
- Distribute LoRA/adapters trained with RECAP to retrofit safety robustness onto diverse base models without full RL retraining.
- Tools/workflows: Adapter marketplaces; domain-specific safety packs; compatibility matrices for model families.
- Dependencies/assumptions: Stable adapter transferability across architectures; minimal capability loss; license compatibility.
- Verifiable safety rewards and counterexample mining (safety engineering, formal methods)
- Extend RLVR-like verifiable signals from math to safety (e.g., rule-checkers, policy-as-code) to reduce reliance on judgment models and provide denser, auditable feedback.
- Tools/workflows: Safety policy compilers; constraint checkers integrated into RL; automated discovery of adversarial reasoning trajectories for targeted retraining.
- Dependencies/assumptions: Feasible formalization of safety constraints; scalable verification; coverage of nuanced, contextual harms.
- Agentic systems with persistent safe reasoning (agents, robotics, tool use)
- Train multi-step agents (planning, tool invocation, robotics tasking) to override unsafe plans even under repeated adversarial resets or tool-chain manipulations.
- Tools/workflows: Multi-turn RECAP curricula; environment-level safety rewards; self-reflection monitors gating tool calls.
- Dependencies/assumptions: Robust simulators and logs; methods to detect/encourage genuine self-correction across long horizons.
- Domain curricula for “flawed-to-correct” reasoning (coding, legal, scientific workflows)
- For coding copilots and legal/scientific assistants, curate systematic flawed-reasoning corpora (unsafe code, biased arguments, invalid proofs) to teach recovery and safe alternatives.
- Tools/workflows: Data generation pipelines for counter-aligned traces; domain verifiers (linters, static analyzers, theorem checkers) as reward sources.
- Dependencies/assumptions: High-quality flaw taxonomies; safe data handling; verifiers with adequate recall/precision.
- Runtime introspection and safety governance dashboards (Ops, compliance)
- Monitor live rates of self-reflection and “trajectory corrections” as leading indicators of safety health, with alerts when reflective behavior degrades.
- Tools/workflows: Telemetry capturing CoT markers (privacy-aware); drift detection; automated triggers for retraining with fresh counter-aligned prefills.
- Dependencies/assumptions: Privacy and security guardrails for logging CoT; meaningful proxies for safety health.
- Prefill dataset exchanges and adversarial libraries (research, ecosystem)
- Shared repositories of counter-aligned CoT traces and attack recipes (including IPR variants), enabling continuous benchmarking and community hardening.
- Tools/workflows: Versioned datasets; risk-tiered access controls; standardized metadata (domain, harm type, severity).
- Dependencies/assumptions: Governance to prevent misuse; consented, policy-compliant data curation.
- Cost-aware multi-objective training frameworks (AI operations)
- Institutionalize multi-reward RECAP training that balances safety, helpfulness, and capabilities under token budget and latency constraints.
- Tools/workflows: Pareto-front optimization dashboards; auto-tuning of α (prefill ratio) and prefix length; budget-aware rollout sampling.
- Dependencies/assumptions: Accurate cost/latency observability; mechanisms to avoid reward hacking and capability regressions.
- Standards for evaluation diversity and robustness claims (academic/industry consortia)
- Broaden eval protocols to include prefill sources from different model families and unseen domains, preventing overfitting to a single attacker or dataset.
- Tools/workflows: Cross-family attacker pools; meta-evaluation of evaluator bias; inter-lab reproducibility challenges.
- Dependencies/assumptions: Community incentives for sharing attackers/evals; sustainable funding for public benchmarks.
Notes on cross-cutting assumptions and risks:
- Reward model quality and bias directly affect outcomes; multi-rater and rubric-grounded scoring can mitigate brittleness.
- Generating and handling harmful counter-aligned data requires strict legal/ethical oversight and red-team governance.
- Reported gains rely on models that support CoT and prefill; benefits may vary with architecture and domain shift.
- GPT-4o-based judgments used in the paper’s evals introduce evaluator bias; diversified evaluators or verifiable checks reduce risk.
- Hyperparameters (prefill ratio α, prefix length) materially affect safety/helpfulness trade-offs; domain tuning is necessary.
Glossary
- AIME2024: A competitive mathematics benchmark used to assess problem-solving in models. Example: "and AIME2024~\citep{maa_aime_2024}."
- advantage normalization: A technique in policy optimization that scales advantages across sampled rollouts to stabilize learning. Example: "the importance sampling ratio and advantage normalization are computed only for tokens after the injected prefix"
- BeaverTails: A human-preference safety dataset used for training and evaluation of alignment. Example: "1K harmful prompts from BeaverTails~\citep{ji2023beavertails}"
- chain-of-thought (CoT): Explicit intermediate reasoning steps generated before the final answer to structure problem-solving. Example: "``think'' by first generating structured \ac{cot} reasoning before producing a final answer"
- clipping thresholds: Bounds used to clip policy ratios in proximal policy optimization to prevent overly large updates. Example: "As in \ac{dapo}, $\varepsilon_{\text{low}$ and $\varepsilon_{\text{high}$ are clipping thresholds"
- conservative bound: An assumption limiting the magnitude of policy updates to ensure stable theoretical guarantees. Example: "Assume that policy updates satisfy the conservative bound (Assumption~\ref{conservative_bound})"
- counter-aligned prefilling: Injecting flawed or misaligned reasoning prefixes into the CoT during training to teach recovery to safe behavior. Example: "counter-aligned prefills are essential to induce this reflective behavior"
- DAPO (Decouple Clip and Dynamic Sampling Policy Optimization): A reinforcement learning post-training algorithm that combines clipping and dynamic sampling for group-based rollouts. Example: "We adopt the \ac{dapo} framework~\citep{yu2025dapo}, an enhanced variant of \ac{grpo}"
- DeepSeek-R1: A frontier large reasoning model known for strong math and coding performance. Example: "Frontier \acp{lrm}, such as DeepSeek-R1~\citep{guo2025deepseek}"
- dynamic sampling: An approach that selectively discards uniformly bad or uniformly good rollouts to focus training on informative samples. Example: " is a reward threshold used in dynamic sampling: prompts are discarded if all rollouts are bad () or uniformly good ()."
- Fortress (Scale AI Fortress): A challenging safety and jailbreak benchmark with expert-crafted prompts and rubrics. Example: "Fortress includes 500 expert-crafted adversarial prompts grounded in U.S. and international law"
- Granite-Guardian-3.1-8B: A guardrail model providing safety logits used as dense rewards in RL training. Example: "For reward models, we use IBM Granite-Guardian-3.1-8B~\citep{padhi2024granite} for safety"
- GRPO (Group Relative Policy Optimization): A group-based RL algorithm that compares rollouts relative to each other to compute advantages. Example: "Trained via online RL algorithms, such as \ac{grpo}~\citep{shao2024deepseekmath}"
- GuardBench leaderboard: A benchmark ranking guardrail models on safety tasks. Example: "as it ranks highest on the GuardBench leaderboard~\citep{bassani2024guardbench}"
- GSM8K: A grade-school math benchmark used to evaluate reasoning and problem-solving ability. Example: "and 3K math prompts from GSM8K~\citep{cobbe2021training}"
- importance sampling ratio: The ratio of new to old policy probabilities used to reweight updates in off-policy optimization. Example: " is the importance sampling ratio."
- iterative prefill reset (IPR): An adaptive attack that repeatedly resets and reinjects flawed CoT prefixes to undermine recovery. Example: "In the IPR attack the adversary (i) initially injects a flawed \ac{cot} prefix $y^{\text{pre}_{\text{cot}$ and allows the model to continue ..."
- jailbreaking prompts: Adversarially phrased inputs that conceal harmful intent to elicit unsafe outputs. Example: "jailbreaking prompts, which conceal harmful intent through roleplay or adversarial phrasing."
- Llama-3.1-8B-Instruct: An instruction-tuned model used as an automatic judge for helpfulness in overrefusal evaluation. Example: "judged by Llama-3.1-8B-Instruct~\citep{dubey2024llama}"
- large reasoning model (LRM): A LLM optimized for multi-step reasoning with explicit thought traces. Example: "Let denote an \ac{lrm} parameterized by weights ."
- normalized advantage: An advantage value standardized across a group of rollouts to improve stability of updates. Example: " is the normalized advantage estimated over ."
- overrefusal: Excessive refusal of benign prompts due to conservative safety alignment. Example: "Overrefusal captures exaggerated safety behaviors that arise after aggressive alignment."
- pass@K: An evaluation metric measuring whether any of K sampled solutions are correct. Example: "We report pass@K: for MATH500 and GSM8K, and for AIME2024 to ensure stable evaluation."
- prefilled reasoning trace: A pre-injected partial CoT used to steer or test the model’s subsequent reasoning. Example: "Prefilled reasoning traces steer \ac{lrm} behavior dramatically."
- prefilling attacks: Methods that inject misleading CoT prefixes at inference to bypass safety alignment. Example: "On StrongREJECT with prefilling attacks, 83.4\% of \ac{cot} traces from DSQwen-14B trained with \method{} exhibit self-reflection"
- prefilling length: The size of the injected CoT prefix used during training or evaluation. Example: "Prefilling length $\ell_\text{pre$."
- prefilling ratio: The proportion of training prompts augmented with CoT prefills. Example: "Prefilling ratio ."
- RECAP (Robust Safety Alignment via Counter-Aligned Prefilling): The proposed RL training recipe that teaches models to recover from flawed reasoning trajectories. Example: "Three key factors drive the effectiveness of RECAP: (a) the prefilling ratio and (b) the prefilling length govern the trade-off between safety and overrefusal, while (c) the prefilling source must be counter-aligned rather than aligned."
- reinforcement learning from human feedback (RLHF): A training paradigm using human- or model-judged feedback to optimize LM behavior. Example: "requires no additional training cost or modifications beyond vanilla \ac{rlhf}"
- Reinforcement Learning with Verifiable Rewards (RLVR): A framework that provides rewards only when outputs can be formally verified as correct. Example: "apply the \ac{rlvr} framework~\citep{lambert2024tulu} to reward verifiably correct answers."
- reward model: A model that scores outputs to provide feedback signals for RL training. Example: "For reward models, we use IBM Granite-Guardian-3.1-8B~\citep{padhi2024granite} for safety"
- SafeChain: An alignment method that uses reasoning-aligned datasets and supervised finetuning to improve safety. Example: "Alignment-focused baselines include SafeChain~\citep{jiang2025safechain} and STAR~\citep{wang2025star}"
- scalar reward: A single numeric score assigned to a rollout’s final response for RL optimization. Example: "The scalar reward is assigned based on $(x, y_{\text{resp})$, with the specific reward designs detailed in Sec.~\ref{sec: 410}."
- self-reflection: The model’s behavior of revisiting and revising its own reasoning mid-trajectory. Example: "We find that \method{}-trained models engage in self-reflection far more often than vanilla \ac{rlhf}"
- STAR-1: A safety-oriented dataset used to construct refusal-oriented reasoning traces and evaluate overrefusal. Example: "1K overrefusal prompts from STAR-1~\citep{wang2025star}"
- StrongREJECT: A benchmark of harmful prompts for testing safety alignment. Example: "Specifically, models are tested on the StrongREJECT benchmark, which contains 313 harmful prompts~\citep{souly2024strongreject}."
- token budget: The number of tokens generated at inference, affecting latency and cost. Example: "maintaining inference token budget."
- WildJailbreak: A challenging benchmark of real-world jailbreak prompts to assess robustness. Example: "Jailbreaking robustness is evaluated on WildJailbreak~\citep{wildteaming2024} and Scale AI Fortress~\citep{knight2025fortress}"
- XSTest: A benchmark for detecting exaggerated safety behaviors (overrefusals) in models. Example: "We evaluate it using XSTest~\citep{rottger2023xstest} and the benign subset of Fortress (FortressOR)."
Collections
Sign up for free to add this paper to one or more collections.

