- The paper presents a novel, open-source system that detects unauthorized copyrighted passages in LLM training with enhanced paraphrase and selection methodologies.
- It employs BM25-driven passage extraction, diverse paraphrasing via LangGraph, and multiple-choice QA, achieving a 10–30% reduction in API processing overhead.
- Robust ROC/AUC statistical evaluation and systematic answer permutation enable reproducible detection, setting a benchmark for ethical AI development.
Copyright Detection in LLMs: Ethical Methods and Scalable System Design
Introduction
The proliferation of LLMs has amplified the urgency of detecting unauthorized use of copyrighted content within training corpora. Existing detection methodologies exhibit limitations regarding computational expense, accessibility, and robustness against paraphrase-based obfuscation. This paper presents an integrated, open-source platform for copyright detection in LLM training that improves upon frameworks such as DE-COP (Duarte et al., 2024), enhancing passage selection, paraphrase diversity, evaluation methodology, and overall cost efficiency.
Models trained on indiscriminately scraped corpora, including proprietary and copyrighted material, raise significant legal and ethical challenges concerning creator compensation and intellectual property acknowledgement. Empirical evidence substantiates that LLMs exceeding 100B parameters exhibit pronounced memorization, risking unauthorized reproduction of copyrighted passages.
Traditional plagiarism detectors and perplexity-based analyses are insufficient for identifying plagiarized or subtly paraphrased text, often producing inconclusive or non-specific results. Statistical watermarking, while promising for newly ingested data, fails to retroactively catalog content from existing datasets and is ineffective against paraphrased or reformulated passages.
DE-COP advances detection by employing a multiple-choice QA protocol that prompts an LLM to discern true passages from synthetically paraphrased candidates, serving as a proxy for memorization. However, DE-COP is computationally demanding, with per-document runtime scaling to hundreds of seconds, and suffers from noisy datasets, poorly controlled paraphrasing, and selection bias in answer permutations.
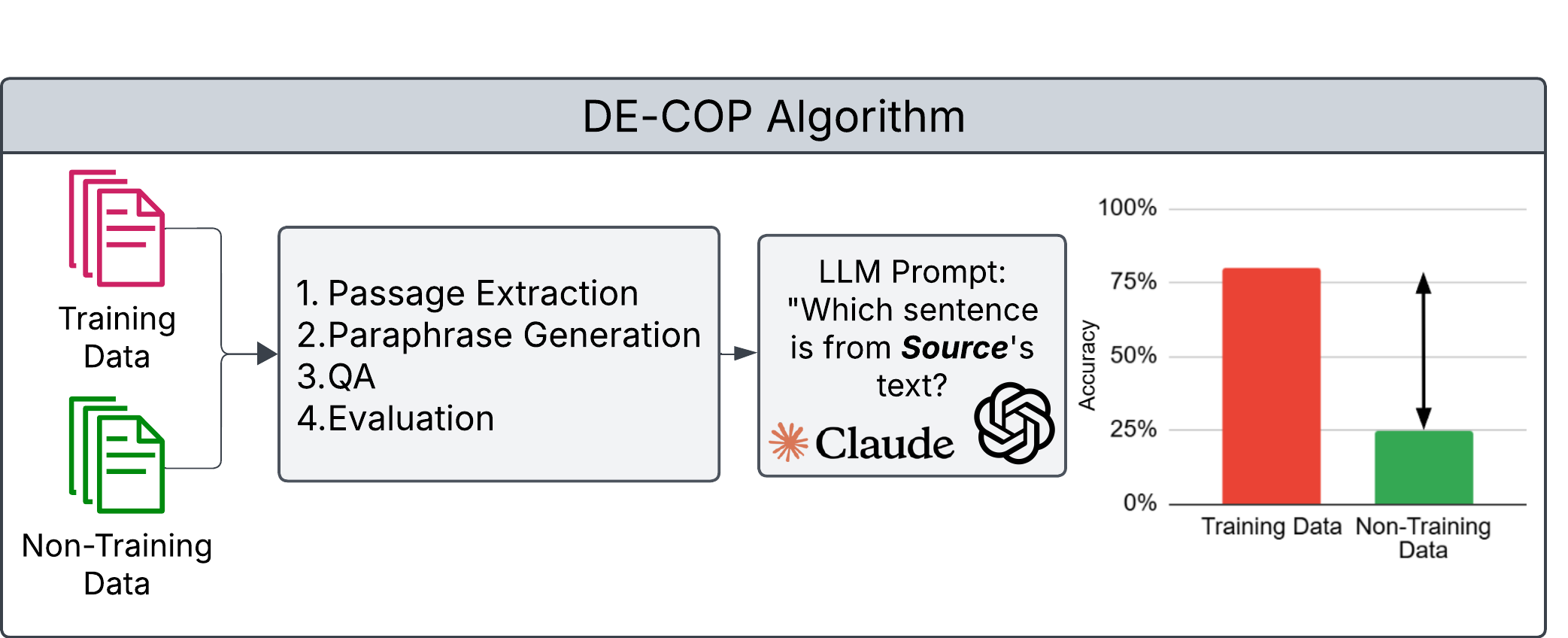
Figure 1: DE-COP’s procedural flow leverages multiple-choice discrimination to infer memorization of original passages by the LLM.
System Architecture and Methodological Innovations
The proposed system delivers a multi-layered, web-accessible architecture enabling efficient and scalable copyright verification. The design encompasses passage extraction, paraphrase generation, QA construction, multiple-choice evaluation, logging, and similarity search.
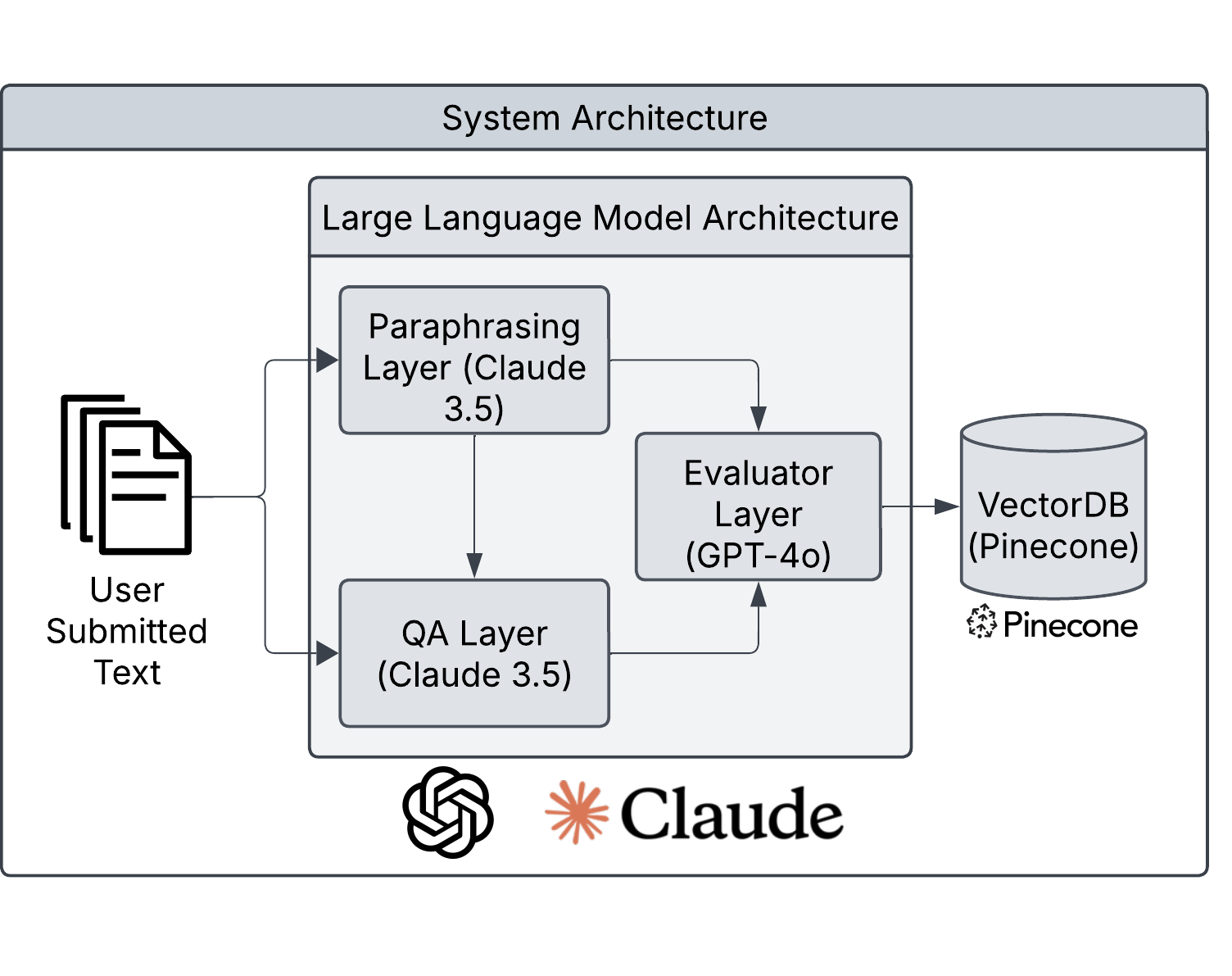
Figure 2: Modular system architecture integrating extraction, paraphrasing, QA, evaluation, and content logging for end-to-end copyright detection.
High-uniqueness passages are algorithmically selected using the BM25 vector-space model, prioritizing segments with minimal intra-document overlap to maximize memorization detection sensitivity and eliminate generic text confounds.
Paraphrase Generation
LangGraph’s StateGraph framework, interfaced with Claude 3.5 Sonnet at calibrated temperature, underpins a paraphrasing module with templated strategies: passive-to-active conversion, question-driven restructuring, and simplified language variants. Diverse paraphrasing enhances the adversarial robustness of the QA protocol, with XML formatting introduced for more structured downstream handling.
Question Answering and Multiple-Choice Protocol
QA generation is operationalized through LangGraph automation, supporting exact-text matched and custom question creation, output in structured JSON. Multiple-choice answer formatting is refined via enhanced permutation logic, fully randomizing answer presentations and mitigating selection bias inherent to prior DE-COP implementations.
Evaluation and Statistical Analysis
The evaluation layer leverages GPT-4o via LangGraph, incorporating ROC/AUC metrics and formal hypothesis testing. Answer permutations and modular evaluation prompts improve detection reliability. These controls address previously observed statistical and dataset inconsistencies, enabling more reproducible inferences regarding training data memorization.
Logging, Similarity Search, and Data Processing
Document embeddings are generated with all-MiniLM-L6-v2 and managed in Pinecone, supporting rapid ANN queries and metadata-driven content tracing. Data preprocessing with SBERT and cosine similarity normalizes passage lengths and semantic content, dynamically filtering out malformed paraphrases and eliminating dataset noise, substantially improving accuracy and operational cost metrics.

Figure 3: Extraction and paraphrasing pipeline produces distinctive passage variants, scored for likelihood of inclusion in model training.
Empirical Results
The system demonstrates notable improvements over DE-COP and comparable methodologies:
- Detection accuracy is enhanced via robust paraphrasing and improved question structuring protocols.
- API processing overhead decreased by 10–30% due to streamlined evaluation of four-way choices and passage normalization.
- Reproducibility is advanced by the removal of dataset inconsistencies, systematic answer permutation, and statistical evaluation.
- Scalability and accessibility are realized through an open-source, web-based interface with embedded content logging and duplication detection.
These results substantiate the system’s potential for broad deployment among individual content creators and small organizations, overcoming prior technical and computational challenges.
Implications and Future Directions
The framework provides a foundation for transparent, ethical AI development and practical copyright enforcement. By operationalizing detectable memorization evidence, it addresses ongoing regulatory concerns and supports fair compensation mechanisms for content creators.
Future research should pursue selective knowledge removal protocols (e.g., UNLEARN (Lizzo et al., 2024)), enabling retroactive purging of copyrighted material from LLMs. Further integration with regulatory datasets (C4 (Abdulrahman et al., 2020), Pile) and harmonization with evolving copyright legislation are recommended. Scalability across diverse model architectures and adaptation to jurisdictional compliance demands are key opportunities for increased impact.
Conclusion
This work delivers a modular, scalable, and cost-efficient framework for LLM copyright detection, outperforming prior art in memorization inference, operational overhead, and usability. By strengthening similarity metrics, controlling evaluation bias, and eliminating data inconsistencies, it advances both the technical rigor and ethical transparency of generative AI development. The public availability and extensibility of this system facilitate conscientious stewardship and legal compliance as the LLM landscape matures.