- The paper introduces a probabilistic extraction methodology using an (n,p)-discoverable framework to precisely quantify memorization risk in LLMs.
- Empirical results reveal significant, book- and model-dependent variability, with some models nearly extracting entire copyrighted texts.
- The study connects technical extraction capabilities with copyright law, highlighting nuances critical for both academic research and legal policy.
Introduction and Motivation
This paper provides a comprehensive empirical and legal analysis of verbatim memorization of copyrighted books by open-weight LLMs, focusing on the Books3 dataset. The authors address the oversimplified narratives in ongoing copyright litigation, where plaintiffs allege LLMs are mere copy machines and defendants claim models only encode statistical correlations. The work leverages a probabilistic extraction methodology to quantify the extent and nature of memorization, with direct implications for both technical understanding and legal arguments regarding copyright infringement.
Probabilistic Extraction and Memorization Metrics
The core technical contribution is the application and extension of the (n,p)-discoverable extraction framework [hayes2025measuringmemorizationlanguagemodels], which quantifies the probability pz that a model, when prompted with a prefix from a training example, will generate the exact target suffix. This approach moves beyond binary, greedy extraction metrics and enables fine-grained measurement of memorization risk as a probabilistic phenomenon.
The extraction probability for a suffix of length k is computed as:
pz=∏t=a+1a+kp(zt∣z1:t−1)
where z1:a is the prefix and za+1:a+k is the suffix. This metric is efficiently computable via a single forward pass through the model, enabling large-scale analysis.
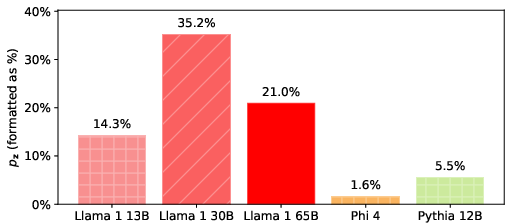
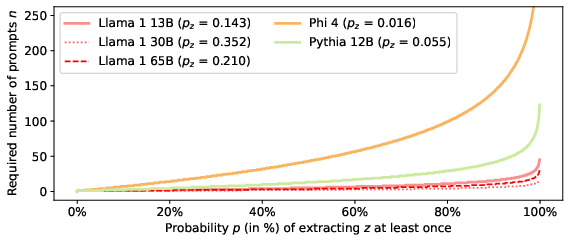
Figure 1: Extraction probability pz for the "careless people" quote from The Great Gatsby across models, illustrating substantial inter-model variance in memorization.
The authors demonstrate that even for relatively long suffixes, some models assign surprisingly high pz values, indicating memorization that cannot be attributed to chance. For example, Llama 1 30B yields pz≈35.2% for a 50-token suffix from The Great Gatsby, implying that, in expectation, fewer than three queries suffice to extract the verbatim text.
Empirical Findings: Model and Book Variability
The study systematically applies probabilistic extraction to 17 open-weight LLMs and 50 books from Books3, including works at the center of ongoing litigation. The results reveal several key patterns:
- Average extraction rates across Books3 are low for all models, with large models (65–70B) achieving maximum (n,p)-discoverable extraction rates of 1–2% for 100-token examples. However, these averages obscure significant heterogeneity.
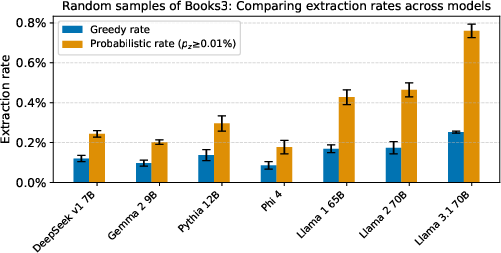
Figure 2: Average extraction rates for Books3 text across models, showing both greedy and probabilistic extraction rates.
- Memorization is highly book- and model-dependent. For most books, even large models do not memorize substantial verbatim content. However, for certain popular works (e.g., Harry Potter and the Sorcerer's Stone, 1984, The Great Gatsby), Llama 3.1 70B and Llama 3 70B exhibit extensive memorization, with over 90% of Harry Potter extractable at pz≥1%.
- Model size and generation do not guarantee memorization. While larger and newer models tend to memorize more, exceptions exist. For example, Phi 4 (14B, synthetic data) memorizes less than Llama 1 13B, and some books are not memorized even by the largest models.
- Memorization is not uniform within books. Heatmaps and sliding window analyses reveal "hot-spots" of high-probability extraction interspersed with regions of low memorization.
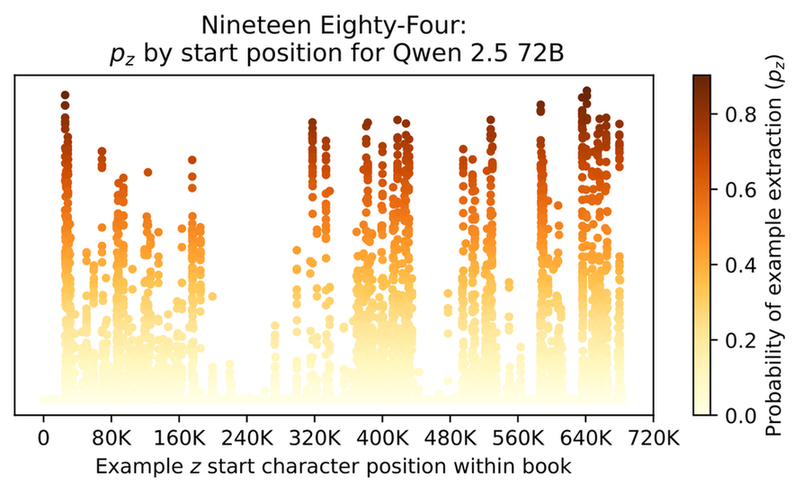
Figure 3: Visualization of memorization in 1984, showing extraction probability pz as a function of position in the book for Qwen 2.5 72B.

Figure 4: Example of a long, high-probability verbatim sequence from Harry Potter extracted from Llama 3.1 70B.
A particularly notable result is the demonstration that Llama 3.1 70B can be used to reconstruct the entire text of Harry Potter and the Sorcerer's Stone near-verbatim, using only the first line of chapter 1 as a seed prompt and beam search decoding. The generated text achieves a cosine similarity of 0.9999 (TF-IDF) and a word-level sequence match of 0.992 with the ground truth, with differences limited to minor formatting and spelling.
This finding constitutes strong evidence that the model has memorized the entire book in a form that is directly extractable.
Legal and Policy Implications
The paper provides a nuanced analysis of the intersection between technical memorization and U.S. copyright law:
Methodological and Implementation Considerations
The authors' implementation achieves significant computational efficiency by computing per-token log probabilities in a single forward pass, enabling large-scale analysis across models and books. The approach is robust to different decoding schemes (e.g., top-k sampling, temperature) and can be extended to non-verbatim extraction in future work.
The (n,p)-discoverable extraction metric provides a principled way to relate extraction probability to the expected number of queries required for successful extraction, facilitating risk quantification.
Limitations and Future Directions
- The analysis is limited to verbatim extraction; non-verbatim and paraphrased memorization remain open areas.
- Only 50 books were analyzed in detail, out of nearly 200,000 in Books3.
- The study focuses on open-weight, non-chatbot models; alignment and RLHF effects are not addressed.
- The legal analysis is U.S.-centric and does not address international copyright regimes.
Conclusion
This work provides a rigorous, data-driven account of memorization in open-weight LLMs, demonstrating that while most models do not memorize most books, some models memorize specific works to a degree that enables near-complete extraction. The findings challenge both simplistic legal narratives and prior technical assumptions, highlighting the need for nuanced, probabilistic metrics in both research and policy. The results have direct implications for model training, dataset curation, and the legal status of open-weight LLMs, and motivate further research into non-verbatim memorization, mitigation strategies, and the development of more sophisticated extraction risk assessments.