- The paper introduces FlowRL, which employs flow-based policy representation with Wasserstein-2 regularization for effective online reinforcement learning.
- It models policies as deterministic ODE trajectories from state-dependent velocity fields, capturing complex, multimodal action distributions to improve exploration.
- Empirical evaluations on benchmarks like DMControl and HumanoidBench show FlowRL outperforms or matches state-of-the-art baselines while ensuring stable, computationally efficient training.
Flow-Based Policy for Online Reinforcement Learning
The paper presents a novel framework for online reinforcement learning (RL) called FlowRL, which integrates flow-based policy representation with Wasserstein-2-regularized optimization. This approach is designed to enhance policy expressiveness in reinforcement learning by utilizing flow-based generative models to capture complex, multimodal action distributions.
Flow-Based Policy Representation
FlowRL represents policies using a state-dependent velocity field, generating actions through deterministic ordinary differential equation (ODE) integration from noise. This setup allows the modeling of policies as flow models, where actions are generated by integrating over a learned velocity field. The flow-based approach offers inherent stochasticity in generated trajectories, promoting enhanced exploration in RL tasks.
Constrained Policy Search
The core of FlowRL's method is a constrained policy search that maximizes expected returns while maintaining proximity to a high-value behavior policy derived from the replay buffer. This constraint is represented by bounding the Wasserstein-2 distance to an optimal behavior policy. FlowRL achieves this without direct sampling from the optimal behavior policy by employing implicit guidance through value function evaluations, thus efficiently aligning policy updates with value maximization.
Practical Implementation
FlowRL implements a Wasserstein-constrained policy optimization by using a flow-matching loss that guides policy updates via actions that have shown high empirical performance. This mechanism ensures that policies not only explore new actions but also exploit known high-value behaviors. The approach avoids explicit density estimation, thereby reducing computational complexity and enabling stable training.
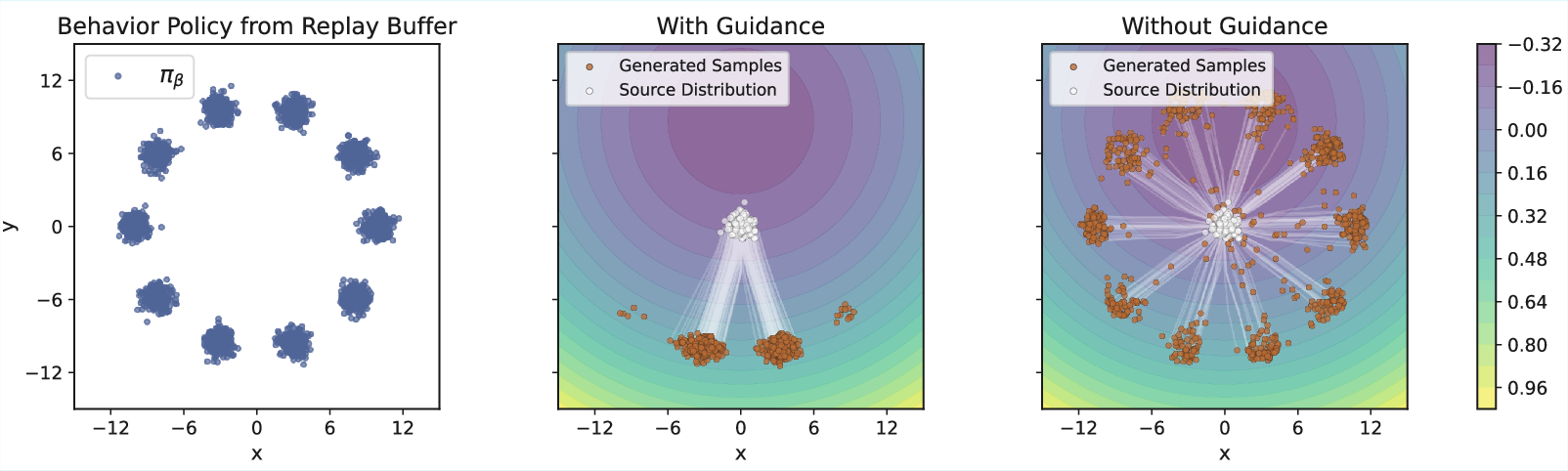
Figure 1: Illustration of Theorem 4.2 on a bandit toy example.
Experimental Evaluation
Empirical evaluations on challenging benchmarks like DMControl and HumanoidBench demonstrate that FlowRL outperforms or matches state-of-the-art baselines in online RL. The results indicate that FlowRL's integration of flow models leads to efficient and scalable policy learning without the need for extensive iterative sampling.
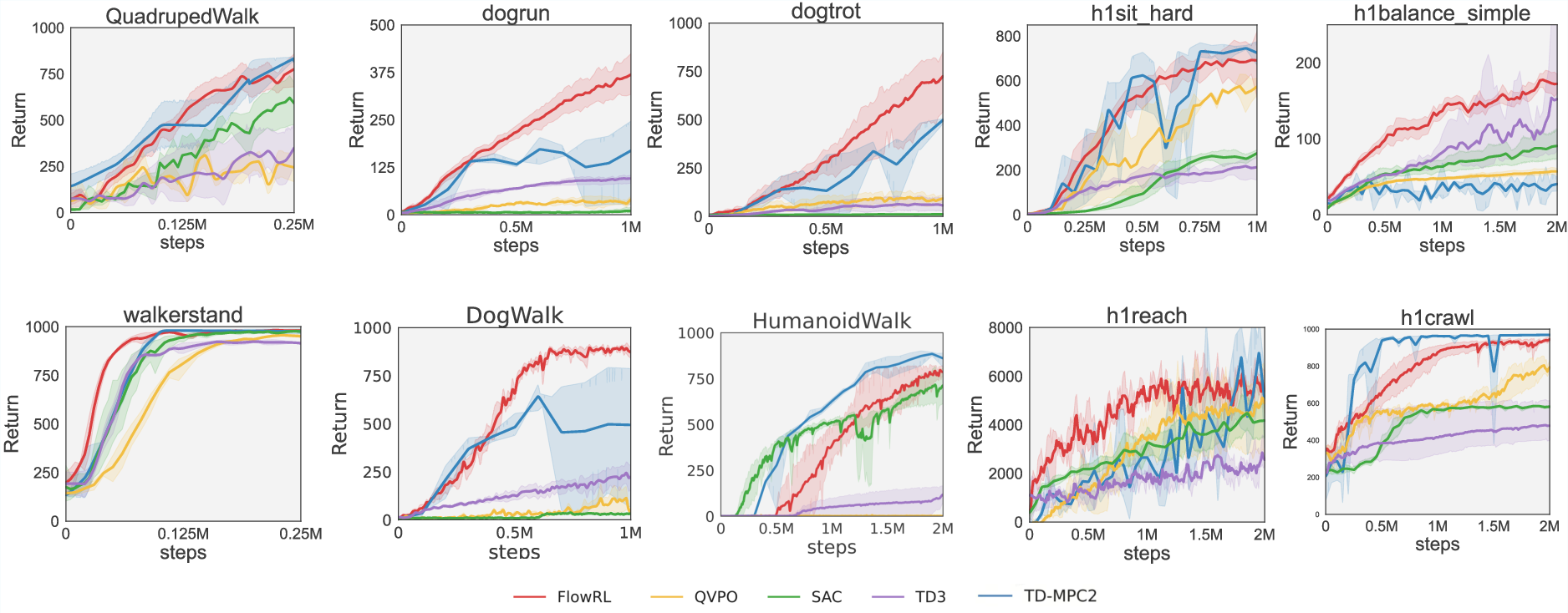
Figure 2: Main results across various challenging RL tasks.
Ablations and Sensitivity Analysis
Ablation studies explore the necessity of the policy constraint mechanism, which proves crucial for improved performance by effectively regularizing policies. Additionally, sensitivity analyses indicate robustness to the number of flow steps, affirming that single-step inference is generally sufficient for stable training outcomes.
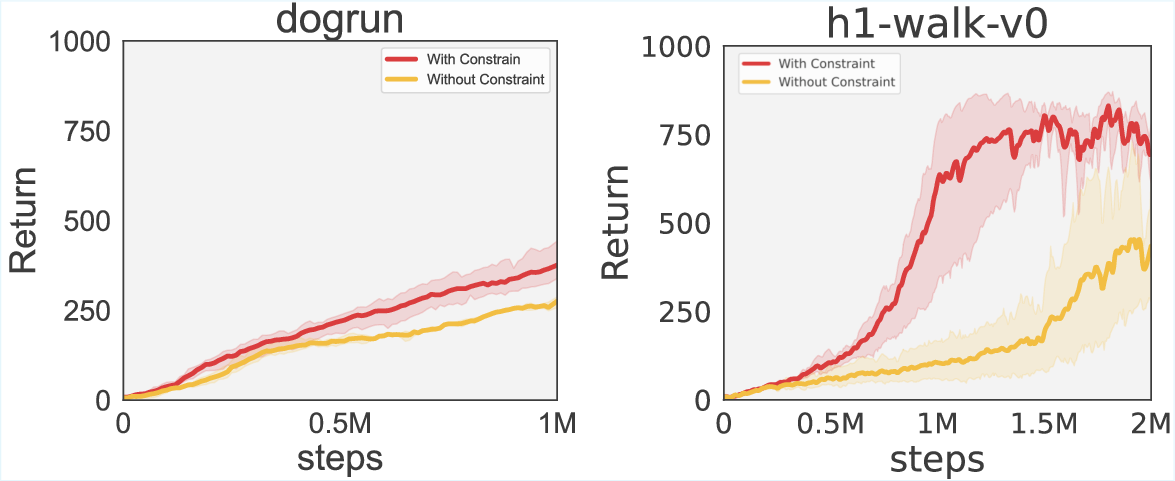
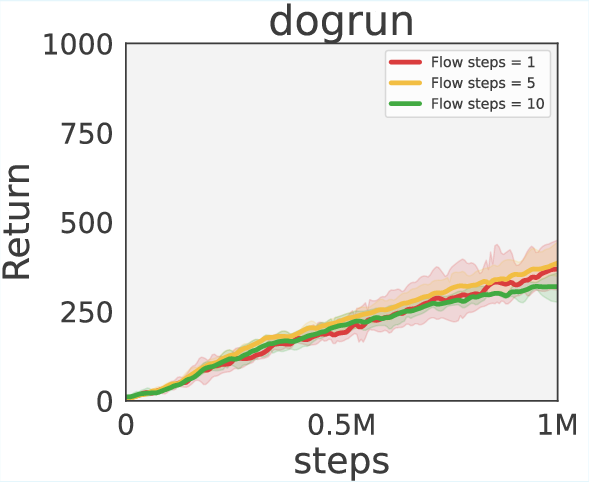
Figure 3: Effect of the constraint on performance.
Conclusion
FlowRL sets a practical pathway for integrating expressive generative models into online RL, leveraging the advantages of flow models to achieve competitive performance and improved sample efficiency. The framework underscores the importance of combining exploration with effective exploitation of high-value behaviors for robust RL algorithms.
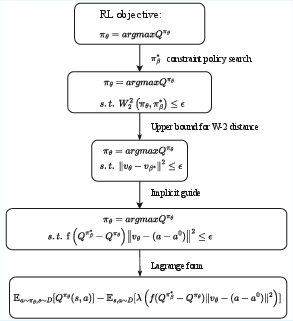
Figure 4: Theoretical sketch of FlowRL.
Future developments could focus on integrating adaptive exploration mechanisms to further enhance policy learning efficiency. Overall, FlowRL contributes significantly to the domain of reinforcement learning by demonstrating the efficacy of flow models in capturing complex action distributions.