$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Abstract: Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $π0$, $π{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $π{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $π{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $π{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $π{\text{RL}}$ boosts few-shot SFT models $π0$ and $π{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $π{\text{RL}}$ in 320 parallel environments, improving $π_0$ from 41.6% to 85.7% and $π{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $π_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to train robot brains that understand pictures, language, and how to move (called Vision-Language-Action, or VLA models). The authors focus on a special kind of VLA that plans actions by gradually “refining” them (flow-based models, such as π0 and π0.5). These models are great at smooth, precise movements, but they’re hard to train with reinforcement learning (RL), which is how robots learn by trying things out and getting rewards.
The paper introduces π_RL, an open-source framework that makes RL work well with these flow-based models. It uses two ideas—Flow-Noise and Flow-SDE—to solve the main technical roadblocks and dramatically boost performance on tough robot benchmarks.
What questions were the researchers asking?
- How can we make flow-based VLA models learn from trial and error (RL), not just from human demonstrations?
- How do we handle the math needed for RL when the model’s action is produced through many tiny refinement steps?
- Can this approach scale to many tasks and still work fast and reliably?
- Will this make robots better at long, complicated tasks with less human training?
How did they do it?
Background in simple terms
- Vision-Language-Action (VLA) models: Think of a robot that looks at the world (vision), reads or hears instructions (language), and then decides how to move (action). VLAs connect these three.
- Flow-based models (like π0 and π0.5): Instead of picking one action at a time, they start with random noise and gradually “clean it up” over several steps to produce a smooth chunk of future actions (like planning several moves ahead). This is great for fine control, like picking up small objects.
Why RL is tricky here
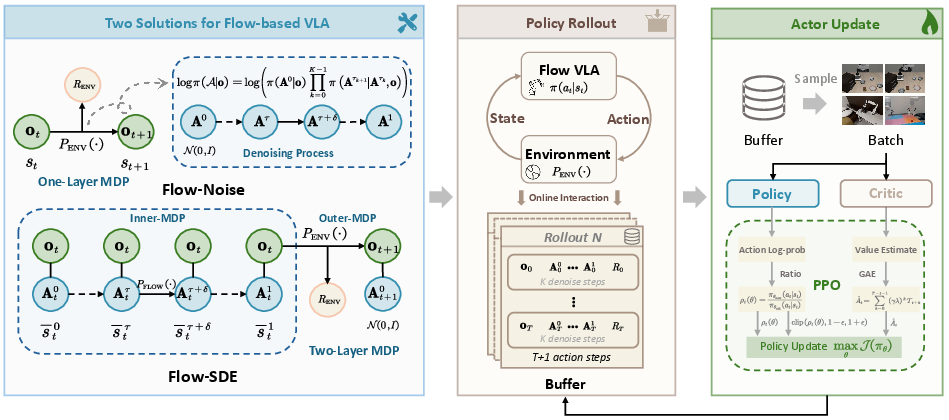
RL needs to know “how likely” a model was to choose an action, to adjust it when rewards come in. For flow-based models, one action comes from many small refinements. That makes the exact “likelihood” hard to compute, and the usual training tricks don’t work. Also, the standard refinement process is deterministic (no randomness), which is bad for exploration in RL.
The two key ideas
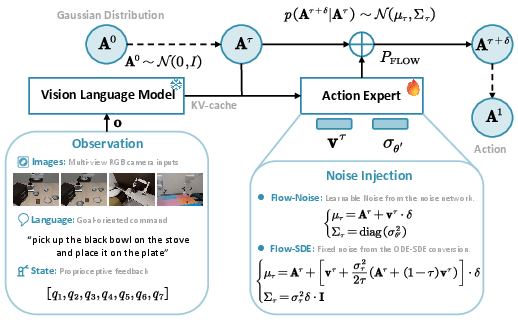
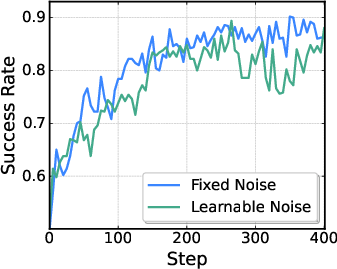
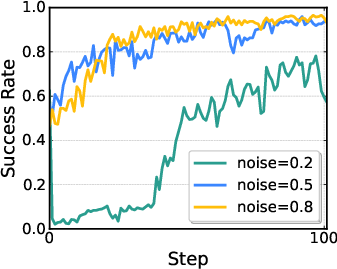
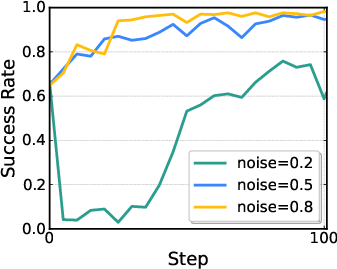
- Flow-Noise: Treat each small refinement step like a mini decision in a simple game. Add a tiny amount of learnable noise at each step (like gently shaking the action a bit), so the model’s choices have a clear probability you can compute exactly. During training, this makes RL work. At test time, the extra noise can be turned off, so the robot acts smoothly and confidently.
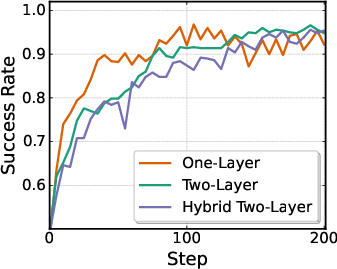
- Flow-SDE: Convert the usual deterministic refinement process (an ODE, which is like following a smooth, fixed path) into a slightly random version (an SDE, which is like walking the same path but with small, controlled wiggles). This gives the model natural exploration. They also build a two-layer “game” (MDP): the inner layer refines the action; the outer layer interacts with the world. To keep things fast, they mix one random step with mostly deterministic steps (hybrid ODE-SDE), so training doesn’t slow down too much.
How they trained the models
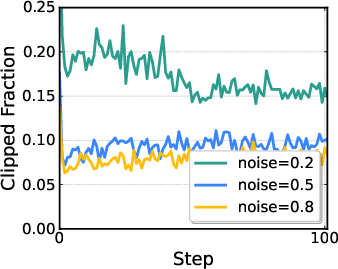
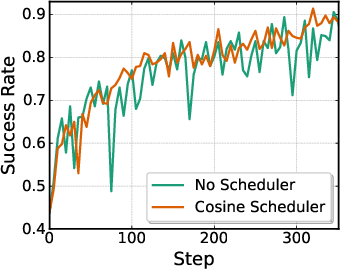
- They use PPO (a standard, reliable RL algorithm) to update the policy.
- The model predicts a chunk of several future moves at once (this gives smoother control and faster decisions).
- For efficiency, they freeze the big vision-language part and fine-tune the action module.
- They run many simulated tasks in parallel to speed up learning.
- Everything (code and model checkpoints) is open-sourced so others can use and reproduce the work.
What did they find?
Here are the main results from two major robot simulation benchmarks.
- LIBERO (many household-style tasks, including long, multi-step ones):
- π0 improved from 57.6% to 97.6% success after RL.
- π0.5 improved from 77.1% to 98.3% success after RL.
- On the hardest long-horizon set (LIBERO-Long), π0.5 went from 43.9% (with only one example demo) to 94.0% after RL—better than training on all demonstrations without RL.
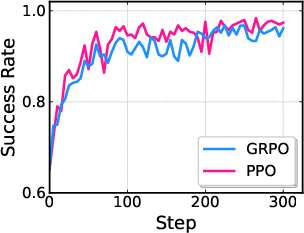
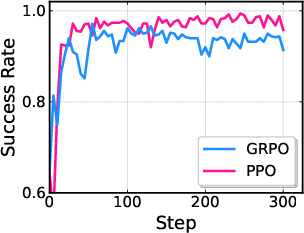
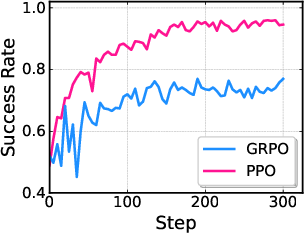
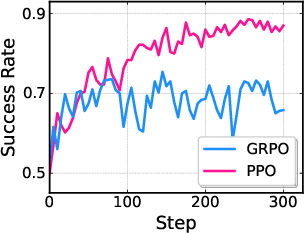
- PPO performed better than an alternative method (GRPO) in their tests.
- ManiSkill (a large, realistic 3D simulator with many tasks):
- MultiTask setup with 4,352 pick-and-place combinations:
- π0 improved from 41.6% to 85.7% success.
- π0.5 improved from 40.0% to 84.8% success.
- SIMPLER (a smaller set of 4 tasks):
- π0 improved from 67.2% to 86.7%.
- π0.5 improved from 59.2% to 79.1%.
Why this matters:
- The gains are big, especially for long, complex tasks.
- It works at scale (thousands of tasks, hundreds of parallel simulations).
- It shows that flow-based VLAs—known for smooth, precise control—can be fine-tuned effectively with RL.
They also tested generalization to “out-of-distribution” (OOD) situations (new visuals, new objects or instructions, and different starting positions). The RL improvements were strongest on in-distribution tasks; OOD gains were smaller. The authors suggest this is partly because they froze the vision-language part during RL, which limits how much the model can adapt to new visuals and meanings.
What could this change?
- Fewer expensive human demonstrations: Robots can start with a few examples and get much better by practicing through RL.
- Better long-horizon skills: The approach excels at complex, multi-step tasks.
- Scalable training: Works with many tasks in parallel, which is important for building general-purpose robots.
- Open-source tools: Others can reuse and build on this, speeding up progress.
Potential next steps:
- Unfreeze or adapt the vision-language module during RL to improve generalization in new environments.
- Move from simulation to real robots, using the same ideas.
- Explore even larger and more varied task sets.
In short, π_RL shows how to make RL work with flow-based VLA models—solving tough technical issues and delivering strong, scalable performance on complex robot tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and unresolved questions that future researchers could address.
- Real-world validation: The framework is only evaluated in simulators (LIBERO, ManiSkill). Assess sim-to-real transfer, safety, latency, and reliability on physical robots across diverse embodiments.
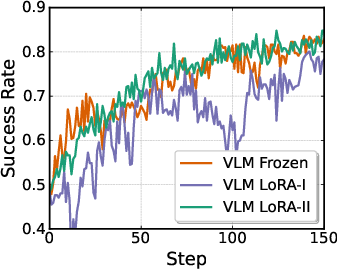
- OOD generalization bottlenecks: Gains are limited under visual, semantic, and execution OOD. Systematically test strategies such as unfreezing or adapting the VLM (e.g., LoRA/adapters), domain randomization, multi-view augmentation, and curriculum RL to improve OOD generalization.
- Freezing the VLM during RL: Quantify how freezing the VLM constrains visual and semantic adaptation. Evaluate partial fine-tuning schemes, parameter-efficient tuning, or joint actor–encoder updates under tight memory budgets.
- Train–test mismatch in Flow-Noise: The noise network is used during training but discarded at inference (deterministic policy). Measure the performance gap due to this mismatch and test alternatives (e.g., calibrated stochastic inference, temperature scaling, or retaining a lightweight stochastic head).
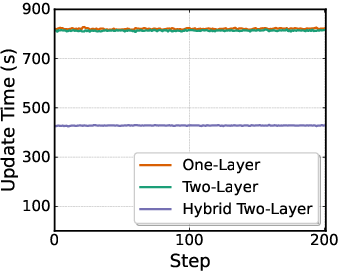
- Computational efficiency of Flow-Noise: Log-likelihood requires recomputing the entire denoising trajectory; update time scales with denoising steps K. Profile wall-clock and memory; study caching, truncated likelihoods, or learned surrogates to reduce compute while maintaining PPO stability.
- Horizon expansion in Flow-SDE’s two-layer MDP: The inner denoising loop multiplies the effective horizon, potentially increasing variance and complicating credit assignment. Investigate temporal abstraction, learned inner-loop termination, or advantage propagation across inner steps.
- Bias/variance of hybrid ODE–SDE rollouts: Only one stochastic SDE step is sampled per denoising sequence. Quantify the bias this introduces, compare multi-step stochastic injections, learn the τ selection policy, and study sensitivity to the noise schedule parameter a.
- Noise schedule sensitivity: The fixed schedule g(τ)=στ with parameter a is chosen heuristically. Conduct sensitivity analysis and design adaptive schedules (e.g., learned στ or state-conditioned exploration) for better exploration–exploitation trade-offs.
- Likelihood modeling assumptions: Transitions are modeled as isotropic Gaussians. Evaluate learned anisotropic/structured covariance, diagonal vs full covariance, and regularization to better match action distribution geometry and improve policy gradient accuracy.
- Equivalence guarantees: Provide formal bounds showing that Flow-Noise’s joint-denoising log-likelihood yields unbiased gradients relative to final-action likelihood in the robotics setting, and that Flow-SDE’s discretized sampler preserves marginals sufficiently under finite K.
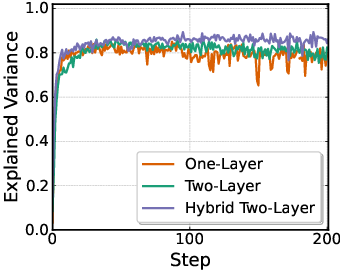
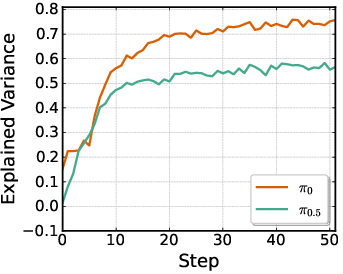
- Critic design for π0: The value function is approximated by averaging over τ (uniform) across the denoising trajectory. Quantify bias from this heuristic; compare τ-conditioned critics, per-τ critics with temporal bootstrapping, or critics that attend over inner-loop states.
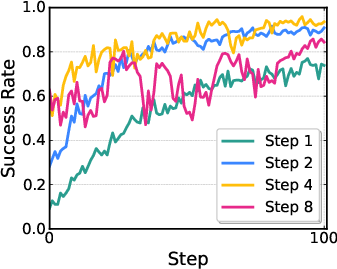
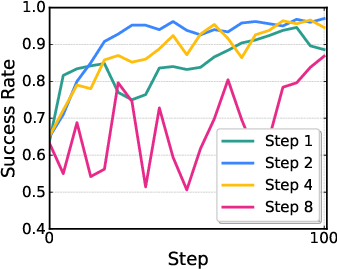
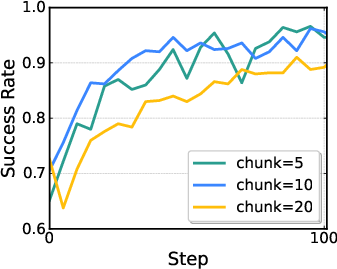
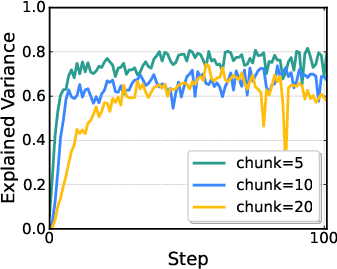
- Action chunking effects: The model outputs H-step action chunks and aggregates rewards. Study how chunk length H affects stability, credit assignment within chunks, latency, and performance; explore dynamic or task-conditioned chunk sizes.
- Reward design limitations: LIBERO uses binary success; ManiSkill uses simple shaping. Evaluate learned reward models, preference-based RL, sparse-reward techniques, and compositional task rewards to improve learning in long-horizon, sparse settings.
- Algorithmic breadth: Beyond PPO/GRPO, compare to off-policy and advantage-weighted methods (e.g., SAC, AWAC), FPO, PA-RL, DSRL, and critic-guided distillation to understand method robustness for flow-based VLAs.
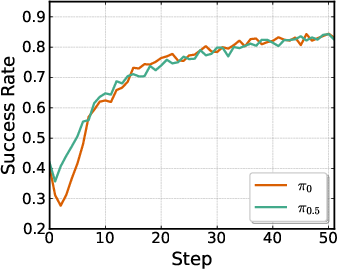
- Modality constraints and proprioception: π0.5 omits robot state on LIBERO/ManiSkill; π0 relies on it. Systematically study the role of state inputs in overfitting vs generalization and reconcile dataset modality mismatches (e.g., missing states in SFT).
- Sample efficiency and compute reporting: Report environment steps, GPU-hours, throughput, and scaling curves. Benchmark against SFT-only and autoregressive RL baselines under matched budgets; study performance on commodity GPUs.
- Task coverage: Most evaluations are pick-and-place/stacking. Test contact-rich, deformable, bimanual, and long-horizon tasks to validate claims of dexterity and high-frequency action generation.
- Safety and constraint handling: Incorporate and evaluate safety critics, constraints (e.g., energy, collision), and recovery policies to ensure safe exploration and execution, especially for real robots.
- Disturbance robustness: Execution OOD shows moderate improvements. Investigate closed-loop replanning, disturbance observers, and robust control augmentations under dynamic perturbations and varied initializations.
- Accuracy vs denoising steps K: The paper notes likelihood inaccuracy with few denoising steps in standard flow models. Provide empirical guidance on K for reliable likelihoods and RL performance; explore adaptive K or learned integrators.
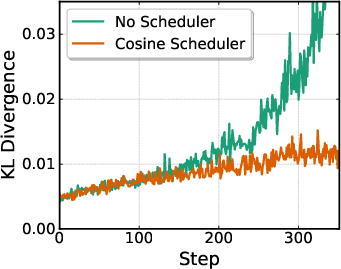
- Exploration strategy details: Flow-Noise mentions relative entropy bonuses without detailed analysis. Ablate entropy regularization types, KL penalties, population-based noise schedules, and their impact on stability and final performance.
- Visual representation adaptation: Quantify benefits of encoder-side RL fine-tuning vs domain randomization, and measure feature drift; study mechanisms to preserve language grounding while adapting vision.
- Multi-task interference and forgetting: Analyze cross-task interference across 4,352 combinations, track per-task learning curves, and evaluate continual RL/meta-RL strategies that mitigate forgetting.
- Reproducibility gaps: Provide complete details on the noise network architecture, SDE schedule, τ sampling distribution, and all ablation results (including critic placements, hyperparameters) with seed-wise variance to enable faithful replication.
- Deterministic vs stochastic inference: Evaluate whether deterministic policies at test time hinder performance on ambiguous tasks; compare stochastic sampling at inference and its impact on success vs consistency.
- Alternative likelihood estimators: Explore pathwise estimators or divergence-based methods (e.g., Hutchinson trace) for final-action likelihoods to avoid full trajectory recomputation while preserving gradient fidelity.
Practical Applications
Immediate Applications
The following applications can be deployed now, using the released code, checkpoints, and workflows described in the paper. They leverage few-shot supervised fine-tuning (SFT) followed by online RL with Flow-Noise or Flow-SDE to achieve strong gains in dexterous, language-conditioned manipulation.
- Few-shot training pipeline for multi-task robot manipulation
- Sector: robotics (manufacturing, logistics, service)
- What: Use the open-source pi_RL framework to fine-tune flow-based VLA models (pi_0, pi_0.5) with parallel simulation, starting from small demonstration sets and improving rapidly via online RL.
- Tools/workflows: RLinf/pi_RL GitHub, HuggingFace checkpoints; ManiSkill and LIBERO simulators; chunk-level PPO optimization; Flow-Noise for exact joint likelihood or Flow-SDE with hybrid ODE–SDE rollouts.
- Assumptions/dependencies: Access to GPU resources (multi-GPU recommended), simulators aligned with target tasks, minimal SFT dataset (~40–200 demos), reward design and task APIs, safety checks before real deployment.
- Rapid adaptation for pick-and-place cells and sorting stations
- Sector: manufacturing/logistics
- What: Quickly adapt existing robotic cells to new objects/receptacles via short SFT and online RL in sim, then deploy the improved controller for high-frequency, dexterous action chunks.
- Tools/workflows: pi_0/pi_0.5 models fine-tuned with Flow-Noise; use MultiTask-like scenario generation to match real object/receptacle combinations; integrate PPO with enterprise simulation stack.
- Assumptions/dependencies: Sim-to-real transfer procedures; calibration between sim models and real hardware; controlled environments where OOD shifts are limited.
- Robotics QA using structured OOD evaluation harness
- Sector: robotics quality assurance
- What: Adopt the paper’s OOD testing taxonomy (vision, semantics, execution) to systematically probe generalization limits and regressions in VLA policies.
- Tools/workflows: Test suites modeled after LIBERO/ManiSkill OOD splits; automated reporting of success rates; policy comparison under controlled OOD conditions.
- Assumptions/dependencies: Curated OOD scenarios; consistent metrics; time budget for evaluation; understanding that VLM freezing can cap OOD gains.
- Academia: reproducible benchmarking for RL on flow-based VLAs
- Sector: academia
- What: Use the pi_RL framework to replicate and extend studies on RL algorithms (PPO vs. GRPO), critic design variants, noise injection strategies, and multi-task scaling across LIBERO and ManiSkill.
- Tools/workflows: Open-source code and pre-trained checkpoints; ablation scripts; shared actor-critic architecture; co-located GPU scheduling strategy.
- Assumptions/dependencies: Access to compute; adherence to benchmark protocols; data licensing and simulator availability.
- Education: hands-on coursework and labs in multimodal robot RL
- Sector: education
- What: Create course modules where students implement few-shot SFT and online RL for flow-based policies, inspect denoising MDP formulations, and study hybrid ODE–SDE sampling.
- Tools/workflows: Teaching notebooks built on RLinf/pi_RL; small-scale simulation tasks; guided ablations on noise schedules and advantage estimators (GAE).
- Assumptions/dependencies: Modest GPU resources; simplified task suites; instructor familiarity with flow matching and PPO.
- Training-as-a-service for robotic controllers
- Sector: software/cloud robotics
- What: Offer cloud-based parallel simulation RL fine-tuning of clients’ VLA policies with co-located GPU pipelines, delivering improved controllers and evaluation reports.
- Tools/workflows: RLinf-driven orchestration; containerized simulators; CI/CD for checkpoints and metrics; dataset intake and reward configuration.
- Assumptions/dependencies: Client data sharing agreements; privacy/security controls; consistent simulation replicas of client tasks; cost of GPU compute.
- Accelerator plugins for flow-based policies
- Sector: software
- What: Integrate hybrid ODE–SDE rollout and exact joint likelihood computation into existing robotics ML stacks to stabilize and speed training with diffusion/flow models.
- Tools/workflows: Flow-SDE conversion; Flow-Noise learnable noise networks; PPO with chunk-level rewards; actor-critic sharing.
- Assumptions/dependencies: Compatibility with internal policy architectures; validation against production tasks; maintenance of noise schedules and sampling fidelity.
Long-Term Applications
These applications require further research and engineering (e.g., robust sim-to-real transfer, safety certification, OOD generalization, VLM adaptation during RL, scaling to fleets or heterogeneous embodiments).
- Household generalist robots with language-conditioned dexterity
- Sector: consumer robotics
- What: Train a single VLA policy that handles diverse home tasks (organizing, placing, tidying) with few-shot SFT and continuous online RL, responding to natural language.
- Dependencies: Robust sim-to-real transfer (domain randomization, sensor fidelity), safety monitors and fail-safes, VLM fine-tuning during RL for better OOD performance, long-horizon curricula and reward models.
- Hospital logistics and assistive care robots
- Sector: healthcare
- What: Deploy generalist manipulation policies to handle diverse medical objects and trays, adapting to changing contexts via online RL while maintaining stringent safety.
- Dependencies: Regulatory approval and clinical validation, sterile environment constraints, comprehensive OOD testing, preference/safety reward models, human oversight.
- Fleet-level training over heterogeneous embodiments
- Sector: manufacturing/logistics/service robotics
- What: Train a shared multi-robot VLA policy in heterogeneous, parallel simulation (akin to 4,352-task MultiTask), then adapt per site with minimal local data.
- Dependencies: Standardized hardware interfaces, digital twins for each site, scalable RL infrastructure and telemetry, policy distillation/transfer between embodiments.
- On-robot online RL adaptation
- Sector: robotics
- What: Enable safe, real-time RL fine-tuning in deployment to accommodate drift, new tools, or novel environments, using Flow-SDE for exploration and conservative updates (PPO trust regions).
- Dependencies: On-device accelerators, constrained exploration and risk mitigation, continuous safety validation, periodic human-in-the-loop checks and rollbacks.
- Certification and policy frameworks for VLA-RL controllers
- Sector: policy/regulation
- What: Establish standards for OOD robustness, failure modes, online learning safeguards, and reproducible evaluation for language-conditioned robot policies.
- Dependencies: Reference benchmarks and audit protocols, third-party testing bodies, logging and traceability of updates, alignment with workplace safety rules.
- Autonomy-as-a-service productization of the pi_RL stack
- Sector: software/robotics
- What: Package data collection, few-shot SFT, online RL, OOD evaluation, and deployment into a turnkey product for enterprises adopting generalist robot control.
- Dependencies: Integration with clients’ hardware and MES/WMS systems, MLOps for model lifecycle, SLAs on performance and safety, sustained support and updates.
- Cross-domain adoption of Flow-Noise/Flow-SDE in continuous-control and generative policies
- Sector: autonomous systems (drones, mobile robots), software (generative control)
- What: Extend the two-layer MDP and likelihood computation tools to other flow/diffusion-based controllers (e.g., locomotion, drone manipulation, generative motion planners).
- Dependencies: Domain-specific reward design, safety-critical constraints (airspace, traffic), large-scale sim and hardware-in-the-loop testing, real-world certification.
- Energy-efficient large-scale RL training
- Sector: energy/compute optimization
- What: Build “green RL” pipelines using hybrid ODE–SDE sampling, co-located GPU scheduling, and trust-region updates to reduce training energy and cost for large policies.
- Dependencies: Instrumentation for energy metrics, scheduler integration with clusters, algorithmic tuning for minimal steps without quality loss, cross-vendor GPU support.
- Workforce and data policy planning
- Sector: policy/workforce development
- What: Plan for reduced manual demonstration needs and changing skill demands (robot ops, simulation engineering), with reskilling programs and data-sharing guidelines.
- Dependencies: Industry consortia, training curricula, privacy and IP frameworks for shared simulations and datasets, public incentives for upskilling.
Notes on feasibility and assumptions across applications:
- Strong reported gains (up to ~98% success) are in simulation; real-world performance depends on sim-to-real transfer quality, sensor calibration, and OOD robustness.
- Freezing the VLM during RL (for efficiency) can limit visual generalization; unfreezing or co-training VLMs may be needed for OOD-heavy deployments.
- Flow-Noise provides finer control but higher compute per update (recomputes denoising trajectory); Flow-SDE is more scalable with hybrid rollouts but requires careful noise schedule management.
- Safety-critical deployments must incorporate constrained exploration, reward shaping aligned with safety, and third-party validation before online learning on hardware.
Glossary
- Action chunking: A policy design that outputs sequences (chunks) of future actions at each step to enable smooth, high-frequency control. "introduce an action chunking architecture based on flow matching."
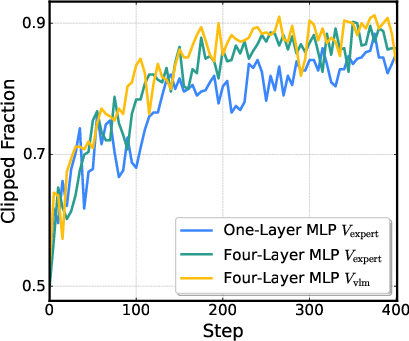
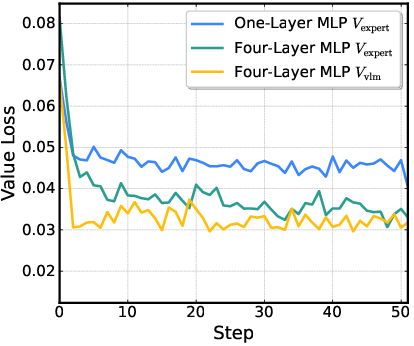
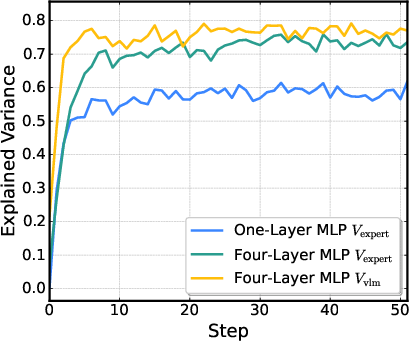
- Actor-critic architecture: A reinforcement learning framework where an actor (policy) and critic (value estimator) are trained jointly, often sharing parameters. "we employ a shared actor-critic architecture for memory-efficient value prediction"
- Advantage function: In RL, the measure of how much better an action is than the average action at a state, defined as A(s,a)=Q(s,a)−V(s). "The advantage function, "
- Advantage-weighted ratio: An RL optimization objective that reweights losses by estimated advantages to emphasize beneficial actions. "maximizing the advantage-weighted ratio of the conditional flow matching loss."
- Autoregressive: A generation paradigm where outputs are produced sequentially, each conditioned on previously generated outputs. "generate output in an autoregressive or parallel fashion."
- Conditional Flow Matching (CFM) loss: A training objective for flow models that aligns a learned vector field with a target conditional vector field to map noise to data. "minimizing the Conditional Flow Matching (CFM) loss"
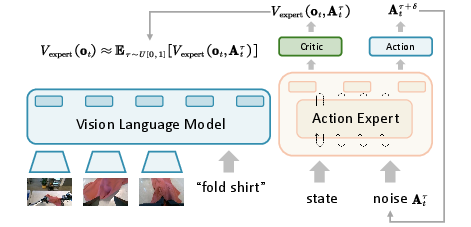
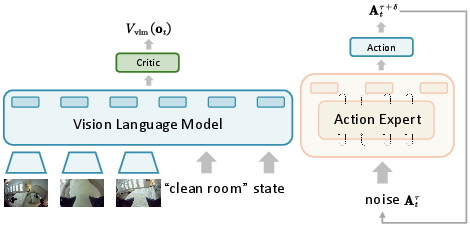
- Critic network: The value-function estimator in actor-critic RL that predicts future returns to guide policy updates. "we attach the critic network directly to the VLM output"
- Direct Preference Optimization (DPO): An RL-from-preference method that optimizes models directly from pairwise or preference data without explicit reward models. "direct preference optimization (DPO)"
- Diffusion term: The stochastic component in an SDE that injects noise, enabling exploration and randomness in trajectories. "a diffusion term that introduces noise"
- Discrete-time MDP: A Markov Decision Process where state transitions occur at discrete time steps. "models the denoising process as a discrete-time MDP"
- Drift term: The deterministic component in an SDE that governs the direction and rate of change of the process. "a drift term that corrects the original velocity"
- Flow matching: A generative modeling approach that learns a vector field to transform noise into data via continuous-time dynamics. "generate actions through iterative refinement in flow matching"
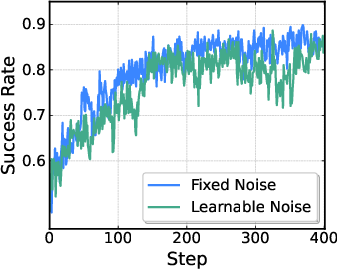
- Flow-Noise: An RL method proposed in the paper that injects learnable noise into flow matching to enable exact likelihoods and exploration. "Flow-Noise adds learnable noise in a one-layer MDP"
- Flow-SDE: An RL method proposed in the paper that converts flow ODEs to SDEs and formulates a two-layer MDP for exploration and tractable likelihoods. "Flow-SDE builds a two-layer MDP with ODE-to-SDE conversion"
- Forward Euler method: A numerical integration scheme for ODEs used to discretize continuous-time dynamics step by step. "based on the forward Euler method"
- Generalized Advantage Estimation (GAE): A technique to compute low-variance, biased advantage estimates for stable policy gradient updates. "PPO employs Generalized Advantage Estimation (GAE) to compute a low-variance estimate of the advantage"
- Group Relative Policy Optimization (GRPO): A policy-gradient algorithm variant that uses group-relative baselines or normalization to improve learning stability. "group relative policy optimization (GRPO)"
- Heterogeneous parallel simulation: Running many diverse simulated tasks/environments concurrently to scale RL training. "heterogeneous parallel simulation, which includes a total of 4,352 task combinations."
- Hybrid ODE-SDE sampling: A rollout strategy that mixes deterministic ODE steps with occasional stochastic SDE steps to accelerate training while maintaining exploration. "hybrid ODE-SDE sampling technique for training acceleration."
- Isotropic Gaussian distribution: A Gaussian with identical variance in all dimensions, often used for noise or transition modeling. "modeled as an isotropic Gaussian distribution"
- Log-likelihood: The logarithm of the probability density of observed actions under a policy; used for policy gradient objectives. "intractable action log-likelihoods from iterative denoising."
- Noise schedule: A function controlling the magnitude of injected noise over time during sampling or training. "We parameterize the noise schedule with a neural network"
- ODE-to-SDE conversion: Transforming a deterministic ODE into an equivalent SDE that shares marginal distributions, enabling stochastic exploration. "employs ODE-to-SDE conversion for efficient RL exploration."
- Ordinary differential equation (ODE): A deterministic equation governing continuous-time dynamics used to map noise to actions in flow models. "converts the ordinary differential equation (ODE) denoising process into a stochastic differential equation (SDE)"
- Out-of-distribution (OOD): Data or environments that differ from those seen during training, used to test generalization. "OOD Tests. Following RL4VLA, we further evaluate the model's generalization across three challenging OOD scenarios"
- Probability flow ODE: The ODE corresponding to a stochastic process that yields the same marginal distributions, linking diffusion models and deterministic flows. "the connection between the probability flow ODE and SDE"
- Proprioception: A robot’s internal sensing of its joint states and body configuration used as input to policies. "robot proprioception"
- Proximal Policy Optimization (PPO): A popular policy-gradient RL algorithm that stabilizes updates via a clipped objective. "proximal policy optimization (PPO) algorithm."
- Rectified Flow: A specific flow-matching formulation that simplifies training and sampling by straightening paths. "especially the Rectified Flow"
- REINFORCE leave-one-out (RLOO): A REINFORCE variant that reduces variance by leaving one sample out when computing baselines. "REINFORCE leave-one-out (RLOO) algorithm"
- Score function: The gradient of the log-density of a distribution with respect to its input, used in score-based generative modeling. "is the score function of the marginal distribution "
- Stochastic differential equation (SDE): A differential equation including random noise, modeling stochastic dynamics over time. "convert the deterministic ODE into an equivalent SDE"
- Stochasticity injection: Introducing randomness into a process (e.g., sampling) to enable exploration and tractable likelihoods. "Stochasticity Injection"
- TD-error: The temporal-difference error used to compute advantage estimates and train value functions. "the TD-error is "
- Trust region: A constraint on policy updates to prevent large, destabilizing changes during optimization. "PPO constrains policy updates to a small trust region"
- Two-layer MDP: A hierarchical MDP formulation combining inner (denoising) and outer (environment) loops for flow-based RL. "formulating a two-layer MDP that couples the denoising process with policy-environment interaction"
- Vision-Language-Action (VLA): Models that map visual and language inputs to robotic actions for task execution. "Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input."
- Vision-LLM (VLM): A model that fuses visual and textual inputs to produce multimodal representations used by the policy. "Building on the pretrained Vision-LLM (VLM)"
- Wiener process: A continuous-time stochastic process (Brownian motion) used as the driving noise in SDEs. "denotes a Wiener process."
Collections
Sign up for free to add this paper to one or more collections.

