- The paper introduces RFM, a unified framework that trains both diffusion and flow policies by approximating unnormalized Boltzmann distributions in online RL.
- It leverages a reverse inferential perspective and Langevin Stein control variates to reduce estimator variance and stabilize policy optimization.
- Empirical studies show that RFM delivers superior performance and reduced variance across continuous control tasks compared to existing baselines.
Reverse Flow Matching: A Unified Approach for Training Diffusion and Flow Policies in Online Reinforcement Learning
Introduction and Motivation
Recent advances in generative modeling have underpinned the enhanced expressiveness of policy classes for sequential decision-making tasks, particularly through diffusion and flow models. While these approaches have achieved strong results in settings such as imitation learning and offline RL—where direct samples from the target action distribution are accessible—the online RL regime presents a fundamental challenge: the target policy distribution, typically a Boltzmann distribution over actions induced by the learned Q-function, is unnormalized and intractable to sample from directly. This distinction impedes the adoption of diffusion and flow policies in online RL, where existing training objectives either suffer from high variance/bias or are tightly coupled to specific parameterizations and fail to generalize to both diffusion and flow architectures.
This paper introduces a unified, statistically rigorous framework—Reverse Flow Matching (RFM)—for directly training both diffusion and flow models to approximate unnormalized Boltzmann action distributions in online RL. RFM views policy training through a reverse inferential lens, transforming the challenge of missing target samples into a tractable posterior mean estimation problem. Furthermore, it employs Langevin Stein operator-based control variates to reduce estimator variance, enabling stable and efficient policy optimization. The framework generalizes and unifies prior approaches, revealing noise-expectation and gradient-expectation methods as special cases and enabling, for the first time, principled minimum-variance estimators by combining Q-value and Q-gradient information.
Technical Framework
Online RL with Boltzmann-Induced Policies
Let Q(s,a) denote the soft state-action value function, and consider maximum entropy RL where the policy update step aims to match the Boltzmann distribution: πnew(a∣s)∝exp(λ1Q(s,a))
Because direct sampling from this distribution is infeasible, naively differentiating through diffuser/flow-based policy samplers accumulates significant computational overhead and instability.
RFM circumvents the direct sampling bottleneck by inverting the generative process: rather than constructing noisy samples from known source and target, it infers the unknown latent (source or target) given observations. Using linear interpolation between source and target (with schedule (αt,βt)), RFM formulates the posterior distribution over the latent as: q0∣t∗(x0∣xt)∝p0(x0)p1(αt1xt−αtβtx0)
Here, p1 is the unnormalized Boltzmann distribution. Policy training becomes regression of the velocity field toward the posterior mean of the endpoints, which is itself estimated via sampling from q0∣t∗. This reformulation generalizes to both flow (deterministic ODE) and diffusion (stochastic SDE) models.
Unified Objective and Prior Methods
The RFM objective encompasses both noise-expectation (average over noise, leveraging only Q) and gradient-expectation (average over Q gradients) training approaches as instances of a more general posterior mean estimator. Letting η∈[0,1] interpolate between the two, the minimum-variance estimator linearly combines Q- and ∇Q-based targets. Prior approaches correspond to fixed values of η: η=0 recovers noise-expectation [ma2025efficient, dong2025maximum], and η=1 recovers gradient-expectation methods [akhound2024iterated, jain2025sampling]. The optimal η (and general diagonal weighting Λ) can be computed to minimize estimator variance, substantially stabilizing policy optimization.
Variance Reduction via Langevin Stein Control Variates
Estimating the posterior means under q0∣t∗ is nontrivial due to the unnormalized nature of p1. RFM introduces Langevin Stein operators to construct zero-mean control variates over self-normalized importance sampling (SNIS), yielding a family of estimators of form: X0+Stein control variate
with the Stein operator leveraging both the gradient of the source and target densities. Optimal coefficients for the control variate are analytically derived to minimize estimator variance. This variance-reduction mechanism is theoretically justified and empirically shown to be crucial for stable high-performance training.
Practical Algorithm and Empirical Evaluation
Integration with Online RL and Flow Policies
RFM is instantiated with flow-matching velocity parameterizations and evaluated on continuous-control environments from the DeepMind Control Suite. Actions are sampled via ODE integration with the learned velocity field. The critic uses a double Q-network architecture; policy and Q-network updates proceed with standard off-policy RL sampling, and posterior means for RFM losses are computed with SNIS augmented by learned Stein control variates.
Empirical Results
RFM outperforms representative baselines—including SAC (mean-field Gaussian policy), Q-score matching (QSM, Langevin sampling from score models), Q-weighted noise estimation (QNE), and diffusion Q-sampling (DQS)—across all eight evaluation environments. It is the only approach to demonstrate both high average performance and low variance across all tested domains.
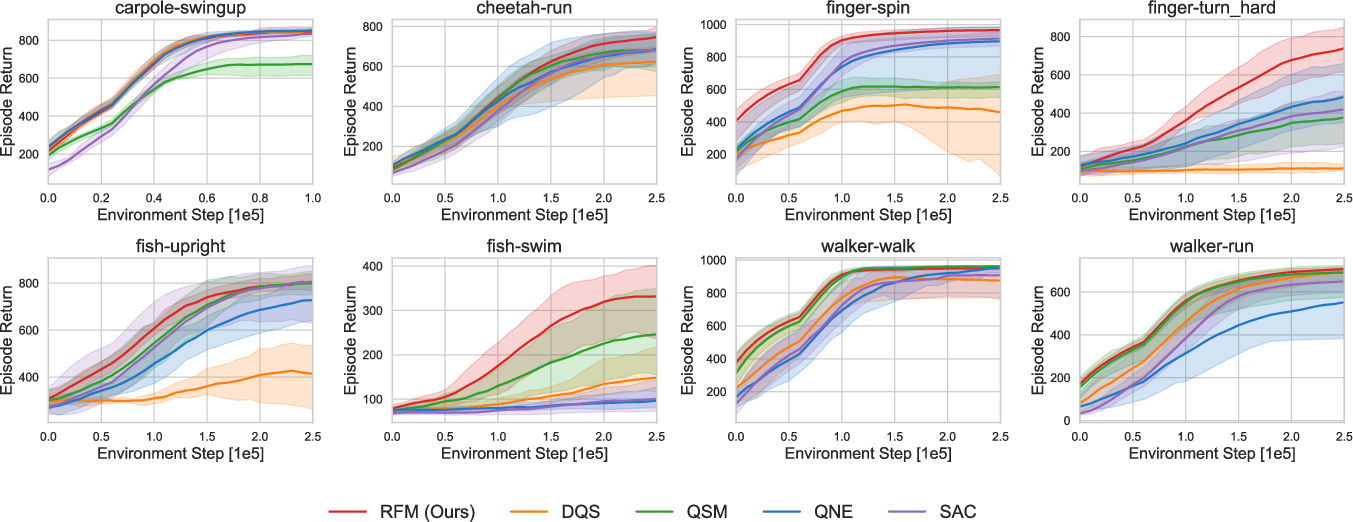
Figure 1: Training curves on eight environments demonstrate RFM's consistent superiority in mean episodic return and training stability compared to all baselines.
Strong numerical results show that RFM's improved posterior mean estimation directly yields quantifiable gains in both task performance and learning stability, particularly in complex or multi-modal continuous control scenarios.
Theoretical Implications and Generalizations
RFM provides a principled unification of previously disparate methods by showing they are all instantiations of its general posterior mean estimation principle. Its construction allows, for the first time, the extension of Boltzmann-targeted training to both diffusion and flow policies, as well as the principled inclusion of both Q-value and Q-gradient information with variance-optimal combination.
Moreover, the control variate formalism based on Langevin Stein operators has broader implications: it is not only crucial for variance reduction in RL but may also be employed in general generative modeling, semi-supervised learning, and Bayesian inference settings where target distributions are unnormalized or otherwise intractable. Notably, this framework is flexible enough to accommodate further amortized or learned control variates beyond the diagonal or isotropic forms discussed in the paper.
Limitations and Future Developments
While RFM significantly advances training methodology for expressive policies in RL, practical scalability to ultra-high-dimensional action spaces or environments with complex temporal structure may introduce additional computational considerations (e.g., per-iteration cost of posterior estimation, integration with model-based or hierarchical decomposition in RL).
The reverse-inference perspective and control variate construction also naturally suggest future extensions:
- Learned or amortized control variates to further reduce estimation variance across state, time, and environment;
- Extensions to offline RL and imitation settings leveraging the RFM posterior mean formulation for general unnormalized targets;
- Generalization to other structured generative models for policy learning or structured output tasks, including more sophisticated source distributions or hybrid latent structures.
Conclusion
Reverse Flow Matching formalizes and extends policy training for expressive generative models in online RL. By transforming the intractable sampling challenge of Boltzmann action distributions into a posterior mean estimation problem, and by employing rigorously constructed variance-reduced estimators, RFM establishes a unified objective encompassing and improving upon all prior methods. Empirically, it achieves uniformly strong performance and stability across standard RL benchmarks. Theoretically, RFM's foundations in statistical estimation and control variates open further avenues for robust generative policy learning and scalable approximate inference in AI systems.