RLFR: Extending Reinforcement Learning for LLMs with Flow Environment
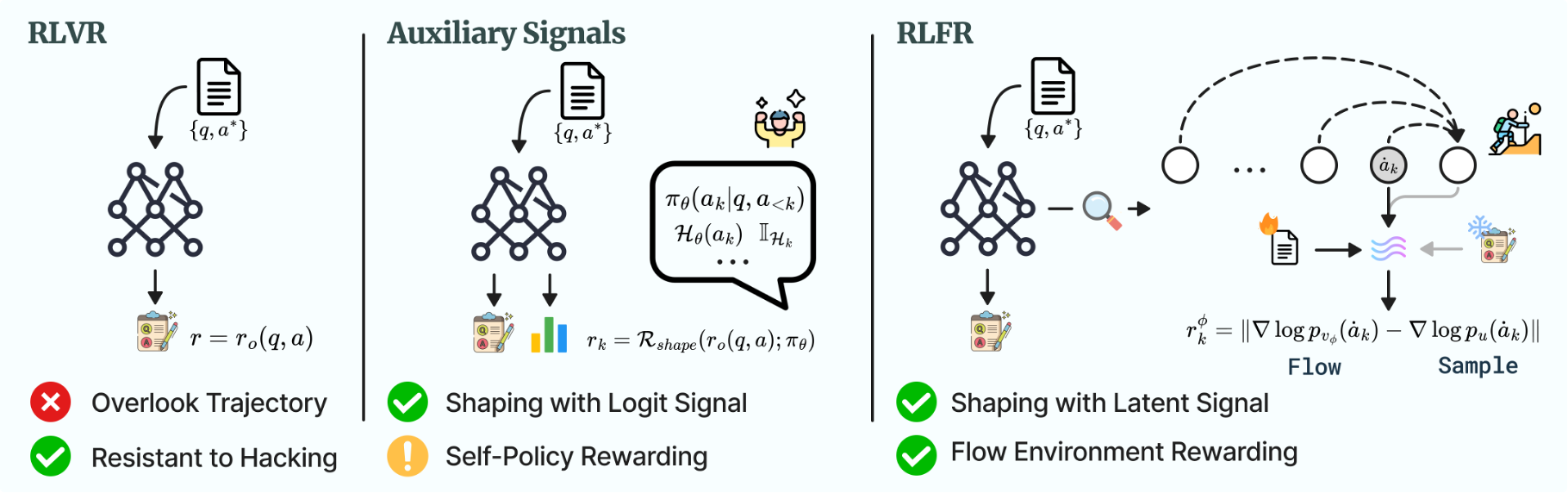
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a promising framework for improving reasoning abilities in LLMs. However, policy optimized with binary verification prone to overlook potential valuable exploration in reasoning trajectory. In view of heavy annotation cost of golden Process Reward Models (PRMs), recent works attempt using auxiliary signals for reward shaping of process tokens, involving entropy and likelihood collected from logit space. In this work, we offer a novel perspective on shaping RLVR with flow rewards derived from latent space, and propose RLFR, where the flow fields of model latents are constructed from either off-policy high-quality data and on-policy rejection sampling data, and the velocity deviations of policy latents within it are quantified to serve as a reward signal. RLFR first demonstrates that a well-established flow field can be a sound environment for reward signal collection, highlighting the expressive latent space is much underexplored. Moreover, RLFR is able to compress any off-policy expert data as reference for constituting reward signals, and we show that the efficient context dependence compressed within the hidden states are utilized, rather than individual token-level denotation for context comprehending. Experiments on both language and multimodal reasoning benchmarks demonstrate the reliability of flow rewards, and suggesting a promising paradigm for reward shaping with auxiliary signals.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to train LLMs to think and solve problems better. It builds on a technique called Reinforcement Learning with Verifiable Rewards (RLVR), where the model gets a reward only if its final answer is correct. The authors propose RLFR, which adds “flow rewards” from the model’s hidden activity (its internal “thinking”) to guide learning step by step, not just at the end.
What questions did the paper ask?
To make this easy to follow, here are the core questions the authors set out to answer:
- Can we give LLMs better training signals during their thinking process, instead of only rewarding the final right answer?
- Can we avoid expensive manual labeling of every step (which is needed by Process Reward Models), and risky methods that reward the model’s own confidence?
- Is the model’s hidden space (its internal “mind”) a good place to measure useful signals for rewards?
- If we use signals from the model’s hidden space, do models actually get better at reasoning on math and multimodal (text + images) tasks?
How did they do it? (Methods explained simply)
Here’s the big idea, using everyday language:
- Think of the model’s hidden space as a map of its internal thoughts as it reasons token by token (like words or symbols).
- The authors build a “flow field” in that hidden space. Imagine a river with currents that roughly point along the best-known reasoning paths from high-quality solutions (like expert examples). This “flow” encodes how good reasoning “moves” through the hidden space.
- As the model thinks through a problem, you can measure how its hidden state moves compared to the river’s currents:
- If it follows the currents (small deviation), that’s good: it gets a positive “flow reward.”
- If it drifts away (large deviation), that’s bad: it gets a negative “flow reward.”
- These flow rewards are added to the usual RLVR setup, so the model doesn’t just care about the final answer; it also gets guidance during the reasoning steps.
A few technical ideas in simple terms:
- Latent space: This is the model’s internal representation—its “mind space”—not the exact words, but the thoughts between them.
- Logits/entropy/confidence: These are signals from the model’s output layer about how sure it is about the next token. Prior methods used these signals to shape rewards, but that can sometimes reward the model for being confident rather than being correct.
- Flow Matching: A method that learns a “velocity field,” meaning the direction and speed that hidden states would move if they followed the expert distribution. Here, the authors use it to check whether the model’s current internal state is heading in a good direction.
- Velocity deviation: How far the model’s hidden “movement” is from the flow’s suggested movement. Smaller is better.
- Rejection sampling: After the model tries to solve problems, they keep the better attempts (based on correctness or other metrics) and use those to update the flow field over time.
What the training looks like:
- Start with a collection of high-quality solutions. Use them to build an initial flow field in the hidden space (the expert currents).
- Train the model with RLVR, but add token-level flow rewards that encourage steps aligned with the flow and discourage big drift.
- Keep updating the flow field with new good examples from the model’s own attempts (the reference “river” gets refined as learning progresses).
What did they find, and why does it matter?
Main results:
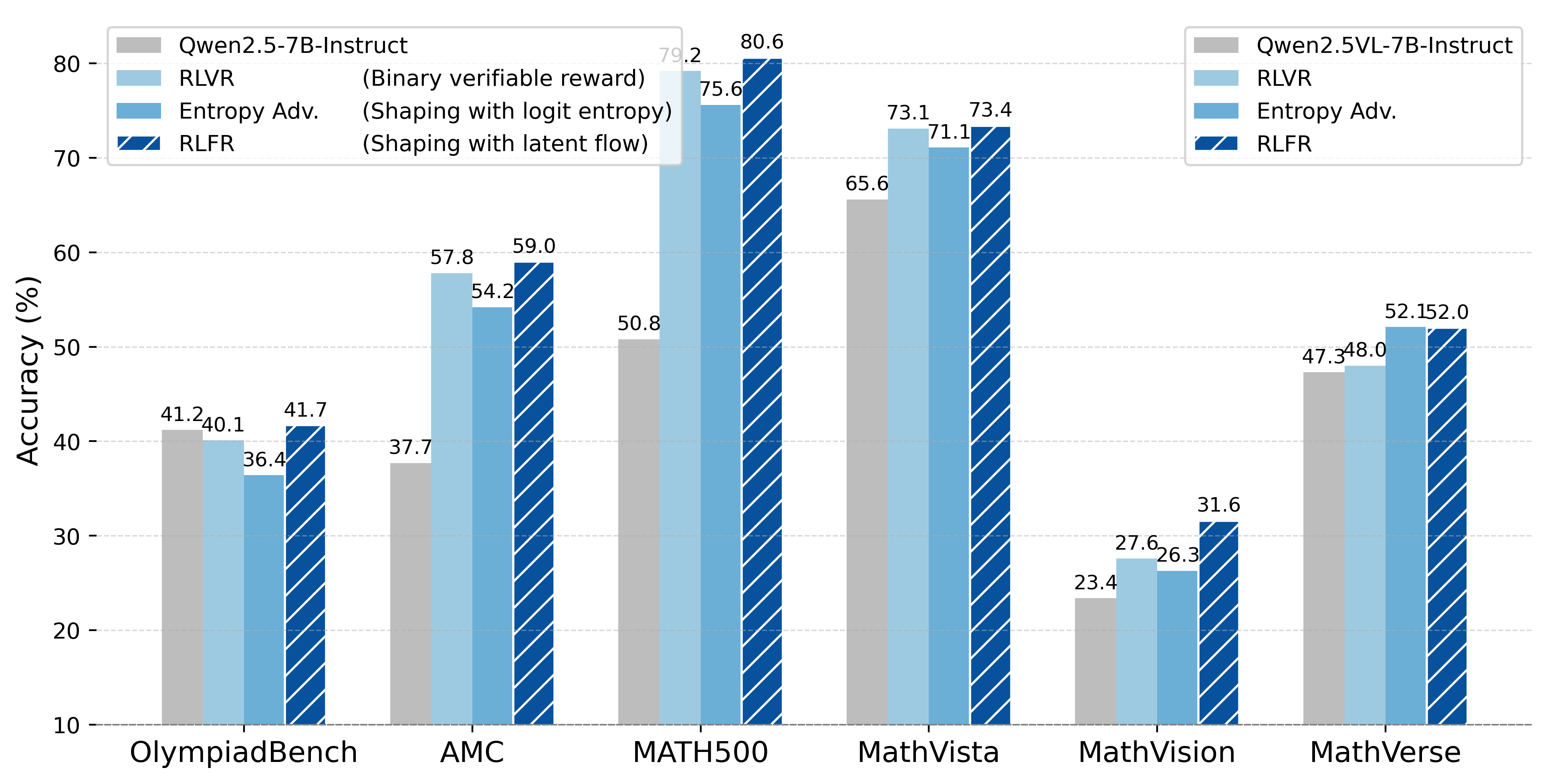
- Across multiple math benchmarks (like AIME, AMC, MATH500, OlympiadBench) and multimodal benchmarks (like MathVista, MathVerse), RLFR consistently beats standard RLVR (binary reward) and a strong baseline that uses entropy-based shaping from the model’s outputs.
- The improvements hold for different model sizes and families (Qwen and Llama, language and vision-LLMs).
- The hidden space is more informative than the output confidence for this kind of reward shaping. In other words, looking at the model’s internal “thinking” gives better signals than just asking, “how confident are you about the next word?”
Why this matters:
- Step-by-step guidance without labeling every step: RLFR gives useful signals during reasoning without needing expensive human annotations for every intermediate step.
- Safer than self-confidence rewards: It avoids the risk of rewarding the model just for being confident (which can become a shortcut or “reward hacking”).
- Uses expert traces efficiently: The flow field compresses good reasoning patterns from expert data and reuses them to guide learning.
Extra observations:
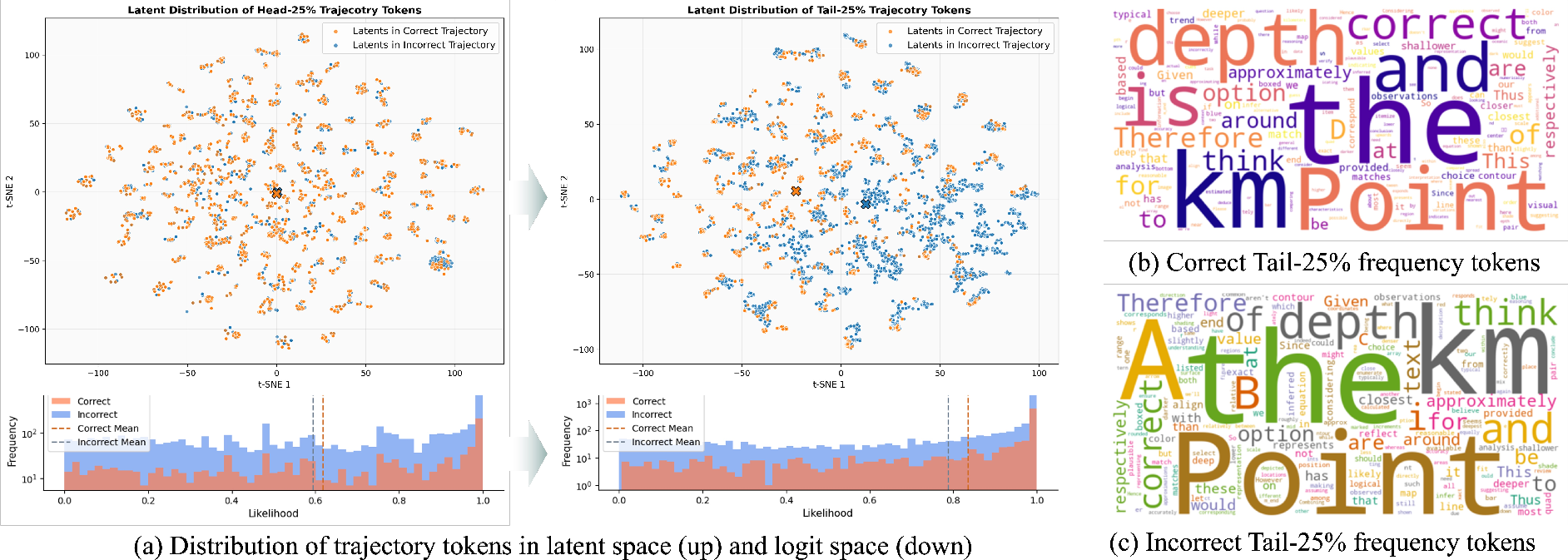
- Flow rewards tend to encourage content-rich, math-relevant tokens (like “sqrt,” “angle,” “frac”), not just filler words (like “to,” “determine,” “given”). That suggests the method really pushes the model to do the math rather than just stitch sentences together.
- Larger timesteps (later stages in the flow process) are more reliable for measuring the velocity deviation; the authors show a debiasing method that improves results by favoring these.
- Using the next token’s hidden state as extra context helps make better reward signals than using only the current token or the previous token.
What’s the potential impact?
- Better reasoning models: RLFR can train LLMs to think more carefully through math and science problems, not just guess the final answer.
- Lower cost: It reduces dependence on costly, step-by-step labels needed by traditional Process Reward Models.
- Generalizable idea: The approach of using hidden-space “flow rewards” could be applied to other domains where reasoning quality matters, like programming, logic puzzles, and multimodal tasks.
- A new “environment” for RL: Instead of only rewarding the end result, RLFR turns the model’s own hidden space into a kind of environment where rewards are collected from how well the internal “moves” follow expert-like currents. This opens up a new path for designing reward signals beyond the usual output-layer tricks.
In short, RLFR shows that the model’s internal thoughts can guide training in a safe, scalable, and effective way—helping LLMs learn better reasoning strategies step by step.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that remain unresolved and could guide future research:
- Generalization beyond math-centric reasoning: The method is evaluated almost exclusively on math and logic (language and multimodal). It is unknown whether flow rewards from latent space transfer to open-domain QA, coding, dialogue planning, scientific reasoning, or long-horizon tasks without deterministic verifiers.
- Robustness to imperfect verifiers: RLFR builds on RLVR’s binary verification. How does performance degrade when verifiers are noisy, probabilistic, or unavailable (e.g., subjective tasks)? Can RLFR handle soft or learned verifiers and still provide stable training?
- Architecture and model-family dependence: Results are limited to Qwen and Llama (≤8B). It is unclear whether latent flow rewards behave similarly for larger (≥70B) or different architectures (e.g., Mistral, Mixtral, Phi, DeepSeek, multilingual LLMs), or for retrieval-augmented and tool-augmented models.
- Scalability and compute/memory overhead: The paper does not quantify wall-clock and memory costs of extracting multi-layer latents, running the flow model per token, injecting noise at chosen timesteps, and online flow retraining. Profiling and scaling laws (w.r.t. sequence length, model size, number of layers, and timestep samples) are missing.
- Deployment-time cost and footprint: While flow rewards are used in training only, the paper does not clarify the extra storage and I/O needed (e.g., latent buffers), or whether the method can be made streaming/online to avoid storing full-sequence latents.
- Data efficiency and quality sensitivity: RLFR requires “high-quality” off-policy trajectories to pretrain the flow. How much data is needed, how sensitive is performance to dataset noise/bias, and what are the trade-offs when only small or partially-correct corpora are available?
- Online rejection sampling design: The method primarily filters by correctness; entropy as an alternative underperforms. Open questions include which metrics (e.g., verifier confidence, self-consistency, path diversity, step-level PRM scores) produce the best flow reference, and how often the flow should be refreshed to avoid staleness.
- Exploration vs. conformity: Training the flow on expert-like data risks penalizing novel but useful strategies that deviate from the reference manifold. How to balance exploration and adherence to the reference flow to avoid early convergence or mode collapse?
- Stability over long training horizons: The paper claims no degeneration but does not present long-run curves or failure analyses. Do flow updates chase a moving target and destabilize credit assignment over millions of steps or with curriculum changes?
- Hyperparameter sensitivity: Critical choices (eta threshold, gamma=1, beta=0.01, timestep set {0.8}, layer percentiles {0.25, 0.5, 0.75}, buffer size kappa, min–max normalization per sequence) lack systematic sensitivity studies. Which settings are robust across tasks/models?
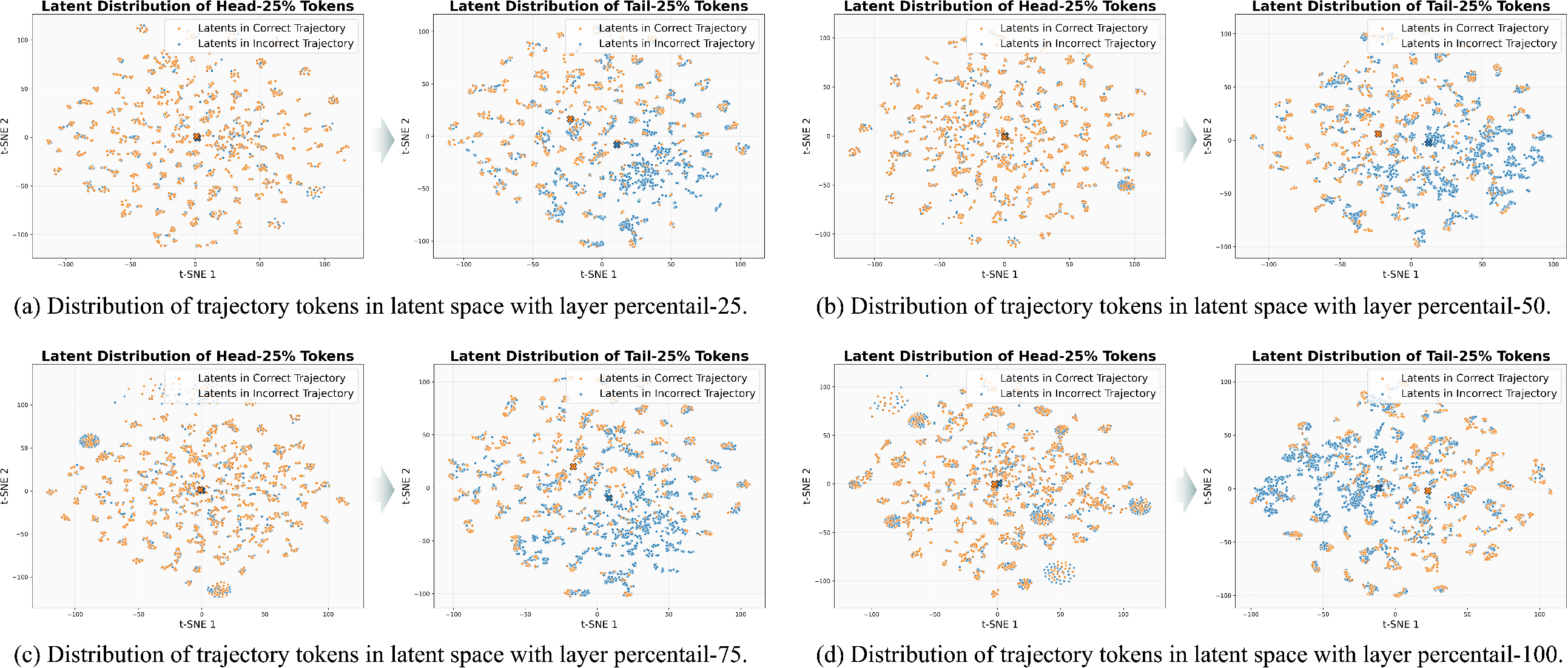
- Choice of layers and representations: Latents are sampled from three intermediate layers with a layer-position embedding. The optimal layers, inclusion of early/late layers, and the benefit of mixing attention vs. MLP outputs remain untested. Are there sweet spots per model/task?
- Timestep policy and debiasing validity: Preference for large timesteps (e.g., 0.8) and weighting by t/(1−t) is motivated theoretically; however, empirical verification across tasks and models is limited. Are multiple timesteps (with or without debiasing) ever superior?
- Theoretical guarantees and assumptions: The ELBO-style link between velocity deviation and likelihood relies on assumptions (e.g., linear interpolation, Gaussian noise) and unspecified constants. Under what conditions does reducing velocity deviation provably improve task reward, not just likelihood under the reference?
- Reward hacking in latent space: Although the approach aims to reduce “self-rewarding” risks of logit-based shaping, there is no adversarial/safety evaluation showing the policy cannot manipulate hidden states to minimize deviation without improving reasoning.
- Comparison breadth and strength: Baselines exclude strong process-level methods (e.g., PRMs, DeepCritic, value-model credit assignment, pass@k RL variants, or other hidden-state shaping methods). It remains unclear how RLFR stacks up against state-of-the-art process supervision at similar compute.
- Interaction with standard RL losses: KL and entropy regularization are disabled; only GRPO is tested. How does RLFR interact with PPO+value baselines, VAPO, or curricula that use KL/entropy? Can value models leverage flow rewards for better credit assignment?
- Token-level advantage shaping side effects: Per-token shaping adds flow returns to a shared outcome advantage. The impact on gradient variance, credit assignment accuracy, sequence-length bias, and interference across tokens is not analyzed.
- Normalization scheme risks: Min–max normalization per sequence may distort cross-sequence comparability and amplify outliers. Are z-score or robust norms preferable? What happens if reward magnitudes vary across tasks or lengths?
- Latent conditions for the flow: Using the post-token latent as a condition performs best in the reported setting; however, the dependence on lookahead is underexplored. Is this practical under different decoding regimes (e.g., nucleus sampling), and does it introduce bias?
- Prompt vs. response latents: Flow training focuses on response tokens. It is unknown whether incorporating prompt latents (or prompt-response interactions) would improve reward fidelity or credit assignment for long-context reasoning.
- Multimodal grounding specifics: The method operates on LLM hidden states after multimodal fusion. The contribution of visual-token latents, different vision encoders, and tasks beyond math diagrams (e.g., charts, medical images, open-world VQA) remain unexplored.
- Applicability without ground-truth answers: Many real-world tasks lack exact answers. How can RLFR be used when only weak or preference feedback is available? Can a learned verifier or ensemble approximations suffice without degrading stability?
- Diversity and solution-path coverage: The effect of flow rewards on solution diversity, self-consistency, and avoidance of spurious shortcuts is not measured. Do latent flows bias toward common patterns at the expense of rare but correct strategies?
- Failure-case characterization: Some benchmarks show small regressions (e.g., certain logic tasks). The paper does not analyze when and why RLFR underperforms RLVR or entropy shaping, nor propose mitigation strategies.
- Sampling and variance in flow rewards: Velocity deviation uses stochastic noise and potentially few timestep samples per token. The variance of this estimator and strategies for variance reduction (e.g., more samples, control variates) are not studied.
- Sample efficiency of “expert compression”: The claim that RLFR “compresses expert trajectories” into a flow field is not quantitatively evaluated (e.g., effect of training-set size, retention of rare skills, catastrophic forgetting under online updates).
- Interventions and causal validation: Beyond token frequency tables, there is no causal testing (e.g., hidden-state perturbations/steering) to verify that minimizing velocity deviation improves the intended reasoning steps rather than superficial token patterns.
- Safety, bias, and fairness: Training flows on expert datasets may encode societal or domain biases into rewards. No analysis is provided on whether RLFR amplifies or mitigates these biases or impacts safety filters.
- Reproducibility details: Important implementation choices (e.g., number of noise samples per token, batching strategy for latents, precision/memory budgets, flow-LLM synchronization schedule) are not fully specified; standardized configs and ablations would aid replication.
Glossary
- Advantage shaping: Modifying per-token advantages using auxiliary reward signals to guide policy updates. Example: "we shape advantage term for each token with flow returns"
- Binary verifier: A deterministic evaluator that assigns a binary outcome reward to a generated response. Example: "A binary verifier then assigns a scaler reward "
- Evidence lower bound (ELBO): A lower bound on the log-likelihood used in variational inference; here shown to be inversely related to velocity deviation under the flow reference. Example: "the evidence lower bound of log-likelihood is constituted by negative velocity deviation"
- Flow field: A learned velocity field over latent representations that transports a prior distribution to a target data distribution. Example: "the flow fields of model latents are constructed from either off-policy high-quality data and on-policy rejection sampling data"
- Flow Matching (FM): A generative modeling technique that learns a continuous-time velocity field to map samples from a simple prior to the data distribution. Example: "Flow Matching (FM) defines a generative process that learns a continuous-time velocity field"
- Flow reward: A reward signal derived from how much the predicted latent velocity deviates from the reference flow field. Example: "yielding flow reward from velocity deviations"
- Group Relative Policy Optimization (GRPO): An RL algorithm that simplifies PPO by using group-relative advantages without a value baseline. Example: "Group Relative Policy Optimization (GRPO) as a widely used reinforcement learning algorithm that simplfies the Proximal Policy Optimization (PPO)"
- Importance sampling ratio: The likelihood ratio between the current and old policy used to reweight updates in on-policy RL. Example: "is the importance sampling ratio between the current and old policy models"
- KL divergence: A measure of divergence between probability distributions often used as a regularizer in RL fine-tuning. Example: "we exclude both KL divergence loss and entropy loss"
- Latent space: The internal hidden-state representation space of an LLM, used here to construct rewards via flow-based signals. Example: "the latent space is much underexplored yet highly expressive"
- Likelihood (log-likelihood): The probability of observed data under a model; used to connect flow-based deviations with distributional fit. Example: "is the log-likelihood under distribution parameterized by "
- Logit space: The space of pre-softmax token scores; source of confidence signals like entropy and likelihood. Example: "token entropy and likelihood collected from logit space"
- Off-policy: Data or trajectories not generated by the current policy, used to pretrain or reference the flow field. Example: "off-policy high-quality data"
- On-policy: Data generated by the current policy, used for online updates and rejection sampling. Example: "on-policy rejection sampling data"
- Pass@k: An evaluation metric measuring the fraction of problems solved within k sampled attempts. Example: "We report Pass@1 metric with rollout temperature of 0 and Pass@32 with temperature of 0.7 for decoding"
- Proximal Policy Optimization (PPO): A policy-gradient method using clipped objectives and importance sampling to stabilize updates. Example: "Proximal Policy Optimization (PPO)"
- Process Reward Models (PRMs): Models that provide step-wise rewards for intermediate reasoning steps rather than only final outcomes. Example: "Process Reward Models (PRMs)"
- Rejection sampling: Filtering generated samples using metrics (e.g., correctness) to update the flow reference distribution. Example: "rejection sampling data filtered by desired metrics"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL framework where outputs can be deterministically verified to provide robust rewards. Example: "Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a promising framework"
- RLFR: A method that shapes RLVR using flow rewards derived from LLM latent space. Example: "we propose RLFR"
- Reward hacking: Exploiting reward signals to achieve high scores without genuine improvement in reasoning or capability. Example: "far less susceptible to reward hacking"
- Reward shaping: Transforming or augmenting environment rewards (e.g., with auxiliary signals) to stabilize and accelerate RL training. Example: "reward shaping transforms explicit environment-based rewards into a proxy reward function"
- Score function: The gradient of the log-density that guides local drift toward higher probability regions. Example: "the score function provides more accurate drift direction from local distributional gradients"
- Token entropy: The uncertainty of the token distribution (over logits), used as an auxiliary signal for shaping. Example: "token entropy and likelihood collected from logit space"
- Value model: A function approximator that estimates expected returns to aid credit assignment in RL (e.g., in PPO). Example: "the value model in PPO framework offers a promising strategy"
- Velocity deviation: The discrepancy between predicted and target latent velocities under a flow field, used as a reward measure. Example: "the velocity deviations of policy latents within it are quantified to serve as a reward signal"
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging RLFR’s latent-space flow rewards to shape reinforcement learning with verifiable outcomes. Each item notes sectors, likely tools/workflows, and assumptions or dependencies.
- Domain-specific reasoning model training with RLVR+RLFR
- Sectors: software, education, finance
- Tools/Workflows: integrate RLFR’s token-level advantage shaping into existing GRPO/PPO-based RLVR pipelines; pretrain flow fields on off-policy expert traces; update with on-policy rejection sampling; deploy improved math/code/logic models
- Assumptions/Dependencies: availability of deterministic verifiers (unit tests, math solvers, schema validators); access to model latents during training; curated high-quality off-policy data; compute budget for joint policy+flow training
- Code generation with unit-test-driven RL
- Sectors: software
- Tools/Workflows: plug RLFR into code RL pipelines (e.g.,
trlx/custom GRPO) to reward latent trajectories that align with expert solutions; maintain a rejection-sampling buffer based on test pass rates; produce models with higher Pass@k - Assumptions/Dependencies: robust test harnesses; repository of expert solutions; model architectures that expose hidden states; CI integration for automated rejection sampling
- Mathematical reasoning tutors and graders
- Sectors: education
- Tools/Workflows: RLFR-trained LLMs for step-by-step math assistance; automatic grading with verifiers; token-level reward shaping reduces overconfidence and improves chain-of-thought accuracy
- Assumptions/Dependencies: reliable solution checkers (symbolic math, numeric validation); appropriate datasets (e.g., OpenR1/MATH); alignment of reference flow to grade-level content
- Multimodal diagram and table reasoning in technical documentation
- Sectors: manufacturing, engineering, compliance
- Tools/Workflows: train MLLMs with RLFR using math/diagram datasets (e.g., MathVista/MathVerse); verify numeric constraints and consistency; embed into document-processing pipelines for QA of specs and BOMs
- Assumptions/Dependencies: image parsing verifiers (OCR, table consistency checks); curated multimodal datasets; robust latent extraction from vision-LLMs
- Data quality checks and reconciliation assistants
- Sectors: finance, operations, data engineering
- Tools/Workflows: verifiable reward tasks (sum checks, constraint satisfaction, reconciliation of ledgers); RLFR makes reward shaping tolerant to partial-but-valuable reasoning trajectories; deploy as internal copilots
- Assumptions/Dependencies: deterministic validators (constraints, balance checks); representative expert traces; domain-specific flow fields
- Compliance and policy QA for rule-based tasks
- Sectors: legal/compliance
- Tools/Workflows: enforce verifiable policy constraints (e.g., format, threshold rules); train RLFR models to prefer latent trajectories aligned with compliant outputs; use rejection sampling on compliance passes
- Assumptions/Dependencies: high-quality rule validators; clear, verifiable compliance criteria; off-policy examples of compliant outputs
- RLFR training module as an SDK/plugin
- Sectors: software tooling
- Tools/Workflows: package a “Flow Reward Environment” module (latent extractor, flow model trainer, velocity-deviation reward calculator, rejection-sampling buffer manager) for integration into RLHF/RLVR stacks
- Assumptions/Dependencies: standardized hooks into model latents; compatibility with training frameworks (PyTorch, JAX); support for common LLM backbones
- Research instrumentation: latent-space analytics
- Sectors: academia, ML engineering
- Tools/Workflows: dashboards to monitor velocity deviations per token/time-step; ablation interfaces (timestep debiasing, layer selection); analyze exploration vs exploitation in reasoning trajectories
- Assumptions/Dependencies: storage/telemetry for hidden states; reliable visualization and logging; repeatable evaluation harnesses
Long-Term Applications
These applications require further scaling, research, or ecosystem development (e.g., robust verifiers, broader domain generalization, or standardization).
- Safety-critical decision support (clinical coding, medication checks)
- Sectors: healthcare
- Tools/Workflows: RLFR-shaped models for tasks with deterministic checks (drug–drug interaction flags, ICD mapping); latent reward design that avoids self-confidence exploitation
- Assumptions/Dependencies: certified medical verifiers; strict governance; domain-specific expert corpora; clinical validation trials
- Robust cross-domain flow environments and standardization
- Sectors: software, policy, academia
- Tools/Workflows: standardized APIs for latent exposure; shared “reference flow fields” per domain; benchmarks for auxiliary reward stability
- Assumptions/Dependencies: consensus on latent formats; reproducible evaluation protocols; licensing that allows latent access
- Program synthesis and formal verification
- Sectors: software, research
- Tools/Workflows: combine RLFR with theorem provers and symbolic verifiers; reward latent trajectories that approach provable correctness; extend to DSLs and constrained synthesis
- Assumptions/Dependencies: scalable formal verifiers; curated expert proofs/programs; flow fields that generalize across languages and tools
- Optimization under constraints (energy scheduling, logistics)
- Sectors: energy, supply chain
- Tools/Workflows: RLVR tasks with constraint verifiers (capacity, timing, costs); RLFR encourages exploration toward feasible optima by penalizing large latent deviations from expert flows
- Assumptions/Dependencies: accurate simulators/verifiers; representative expert solutions; mapping from latent reward signals to operational objectives
- Robotics planning with verifiable simulators
- Sectors: robotics
- Tools/Workflows: use physics simulators as outcome verifiers; shape policy latents via flow rewards to reduce unsafe exploration; blend with model-based planning
- Assumptions/Dependencies: high-fidelity simulators; latent access for robot policies; domain-specific flow training with expert demos
- Privacy-preserving RLFR and federated training
- Sectors: software, policy
- Tools/Workflows: on-device latent flow calculation; federated rejection sampling; privacy accounting for hidden-state telemetry
- Assumptions/Dependencies: privacy-preserving latent pipelines; secure aggregation; standardized privacy guarantees
- Test-time scaling via latent signals
- Sectors: software, research
- Tools/Workflows: use flow-derived signals at inference to adapt decoding (e.g., detect drifting tokens and trigger self-correction or tool calls); dynamic context augmentation based on velocity deviation
- Assumptions/Dependencies: low-latency latent inference hooks; validated heuristics linking deviations to correction strategies; acceptable runtime overhead
- Governance and procurement guidelines for auxiliary rewards
- Sectors: policy, compliance
- Tools/Workflows: standards defining acceptable auxiliary reward sources beyond logits; auditing practices for reward hacking risks; documentation for dataset curation and rejection sampling criteria
- Assumptions/Dependencies: multi-stakeholder agreement; regulatory alignment; third-party auditing capacity
- General-purpose “Flow Rewards Studio” product
- Sectors: AI tooling
- Tools/Workflows: end-to-end platform for building flow fields from expert data, running online rejection sampling, visualizing velocity deviations, and exporting trained models; connectors to RL frameworks
- Assumptions/Dependencies: demand for auxiliary reward tooling; integration with major model providers; sustained maintenance and support
- Cross-lingual and multi-domain latent reward shaping
- Sectors: global enterprises, education
- Tools/Workflows: train multilingual flow fields; domain-conditional latent rewards (law, finance, STEM); unified rejection-sampling policies for heterogeneous tasks
- Assumptions/Dependencies: multilingual expert traces; verifiers spanning languages and formats; adaptive flow architectures that handle diverse tokens/modalities
- Hybrid PRM-lite approaches using RLFR
- Sectors: academia, software
- Tools/Workflows: replace costly step annotations with latent flow rewards; combine sparse human feedback with velocity-deviation shaping; evaluate trade-offs vs full PRMs
- Assumptions/Dependencies: evidence that RLFR can substitute dense PRMs at scale; careful calibration of thresholds and debiasing; robust generalization across tasks and models
- Model-agnostic latent interfaces and hardware acceleration
- Sectors: chip design, model platforms
- Tools/Workflows: standardized latent extraction APIs; accelerator kernels for flow matching and deviation computation; low-overhead training/inference integration
- Assumptions/Dependencies: hardware/software co-design; vendor cooperation; benchmarking on diverse architectures (transformers, hybrid models)
Collections
Sign up for free to add this paper to one or more collections.

