FlowRL: Matching Reward Distributions for LLM Reasoning
Abstract: We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in LLM reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
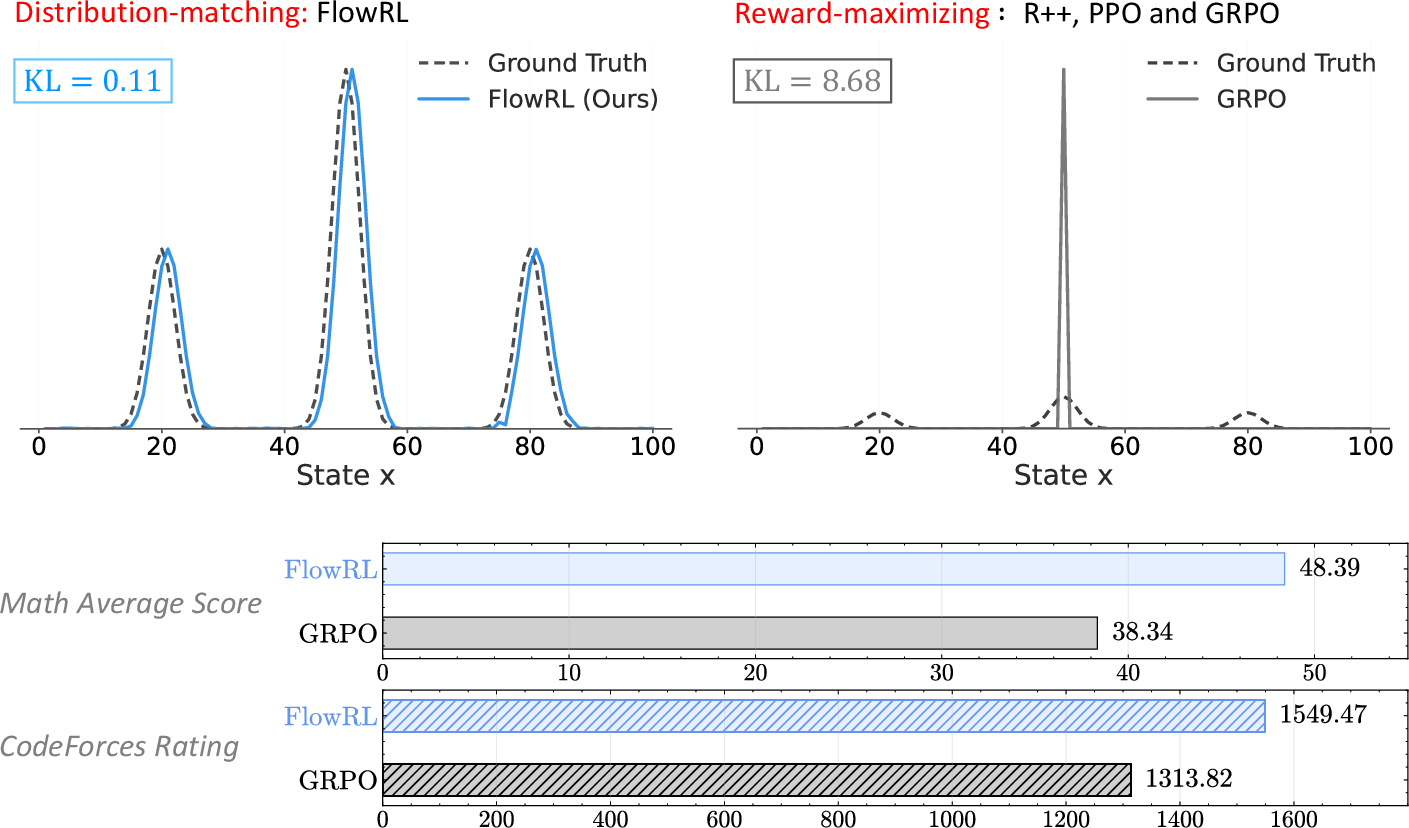
This paper introduces a new way to train LLMs to reason better, called FlowRL. Instead of always pushing the model to pick the single best answer (which can make it narrow and repetitive), FlowRL teaches the model to match a whole “reward distribution.” That means it learns to consider many good solution paths in proportion to how good they are. The goal is to keep the model’s reasoning diverse and flexible, so it can solve harder math and coding problems more reliably.
Key Questions
Here are the simple questions the paper tries to answer:
- How can we prevent LLMs from getting stuck using the same kind of solution over and over?
- Can we train models to explore multiple valid reasoning paths, not just the most common one?
- Will this “distribution-matching” approach beat popular methods like PPO and GRPO on math and code tasks?
How They Did It (Methods)
Think of problem-solving like navigating a huge maze. Traditional methods (like PPO or GRPO) push the model to sprint toward the single brightest path because it seems best. That can make the model ignore other good paths, reducing diversity. FlowRL changes the goal: don’t just chase the top path—learn the shape of all good paths.
To do this, the paper uses a few key ideas:
- Reward distribution instead of single reward:
- Normally, each answer gets a score (a “reward”). FlowRL turns these scores into a probability distribution—like “answers with higher rewards should be sampled more often, but don’t ignore the others.”
- It uses a learnable “partition function” (think of it like a smart scale) to make sure the probabilities add up to 1.
- Matching distributions:
- The model tries to make its output probabilities match this reward distribution.
- They measure how close the two distributions are using “reverse KL divergence,” a mathematical way to compare probability shapes that encourages covering multiple good options, not just one peak.
- GFlowNets and trajectory balance:
- To make this practical, they turn the math into a stable training objective called “trajectory balance,” inspired by GFlowNets.
- Picture probability flowing through states like water through pipes: FlowRL balances the “inflow” and “outflow” so good final answers get the right amount of probability mass.
- Fixing two real-world problems:
- Length normalization: Long chain-of-thought responses can create huge gradients (unstable training). They “normalize” by the length so long answers don’t overpower shorter ones—like grading an essay fairly whether it’s 1 page or 10.
- Importance sampling: Training often reuses answers from the “old” model. FlowRL carefully reweights these old samples to match the current model’s behavior, with safety limits (“clipping”) to avoid big swings—like giving older data a fair, controlled influence.
In everyday terms: FlowRL teaches the model to explore broadly, weighs many promising solutions appropriately, and uses careful training tricks so the learning stays stable and efficient.
Main Findings
The authors tested FlowRL on tough math and coding tasks with different model sizes.
Highlights:
- Math reasoning:
- FlowRL beat GRPO by about 10% and PPO by about 5% on average across six math benchmarks.
- It did especially well on challenging sets like MATH-500 and Olympiad problems.
- Code reasoning:
- FlowRL consistently outperformed other methods on LiveCodeBench, Codeforces (rating and percentile), and HumanEval+.
- Diversity matters:
- When they analyzed the variety of solution paths (using a judge model), FlowRL produced more diverse reasoning steps than other methods. This supports the idea that matching reward distributions helps the model avoid “mode collapse” (getting stuck in one pattern).
Why this is important: Better diversity leads to better generalization. The model is less likely to fail when problems require different strategies.
Why It Matters
FlowRL shows a promising shift in how we train reasoning models:
- From “maximize one reward” to “match the whole reward distribution,” which encourages exploring multiple valid solutions.
- This can make LLMs more adaptable and robust—useful for math, programming, and any task where different paths can lead to correct answers.
- The training tricks (length normalization and importance sampling) make the method practical for long chain-of-thought responses.
In short, this research suggests that teaching models to think broadly—not just chase the single best-looking answer—can make them smarter and more reliable. It could help future AI systems reason more like strong problem-solvers: open-minded, diverse in strategy, and effective across different kinds of tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete future work.
Theory and objective formulation
- Clarify and rigorously prove the conditions under which the proposed reverse-KL-based objective actually promotes mode coverage. Reverse KL is typically mode-seeking; the paper asserts diversity via trajectory balance, but provides no formal guarantee or diagnostic linking reverse-KL minimization to improved multi-modal coverage in the autoregressive, long-horizon setting.
- State all assumptions and provide a complete proof for Proposition 1 (gradient equivalence to trajectory balance), and analyze how the equivalence is affected when practical modifications (importance sampling, length normalization, reference-model term, clipping) are introduced.
- Analyze the bias introduced by the modified trajectory-balance loss (sequence-length normalization and reference-model factor) relative to the original GFlowNet trajectory balance; characterize convergence properties and fixed points of FlowRL under function approximation.
- Provide a formal treatment of the effect of incorporating the reference model via the added term −(1/|y|) log π_ref(y|x) in the “energy” (Eq. 10–11). Is this equivalent to a specific KL-regularized target distribution? Under what conditions does it avoid over-regularization or excessive anchoring to π_ref?
- Characterize the role of the learnable partition function Z_φ(x) in identifiability and optimization: when can the model minimize loss primarily by adjusting Z_φ instead of improving πθ? What constraints or regularizers on Zφ ensure well-posed learning and avoid degenerate solutions?
- Provide stability and convergence analysis for off-policy, clipped, detached importance weighting at the trajectory level. What is the asymptotic bias/variance trade-off and how does it scale with trajectory length and policy drift?
- Examine sensitivity of the method to the reward temperature β theoretically (e.g., limits β→0 and β→∞) and whether learning or scheduling β improves stability/coverage; justify β=15 beyond empirical ablation.
Algorithmic design and ablations
- Ablate length normalization: compare 1/|y|, 1/√|y|, per-token normalization, or normalization by effective reasoning span; quantify effects on gradient norms, stability, and accuracy.
- Ablate the reference-model factor: remove it, vary its strength, or replace it with an explicit KL penalty to the reference; measure the diversity/accuracy trade-off and policy drift.
- Ablate Z_φ: fix Z_φ to a constant, freeze it after warm-up, vary architectures, or share parameters with the policy encoder; report impacts on stability and performance.
- Study group-size and group-normalization effects (G in GRPO-style batching): how do group statistics interact with distribution matching when groups are homogeneous (all-correct/all-incorrect) or highly imbalanced?
- Report sensitivity to importance-sampling clipping ε and the policy refresh cadence (age of “old” trajectories), and compare trajectory-level vs token-level importance ratios.
- Provide gradient-norm and loss-curvature diagnostics to substantiate the claim that length normalization mitigates exploding gradients; include training curves with instability events.
- Explore robust loss variants for trajectory balance (e.g., Huber, Tukey) to handle outlier rewards/lengths and compare with the squared loss used.
Reward design and supervision
- Test robustness to noisy, sparse, or partially incorrect outcome rewards (e.g., flaky code execution, spurious math matches). How resilient is FlowRL vs PPO/GRPO when the reward signal is imperfect?
- Evaluate compatibility with process/step-level rewards and hybrids (process + outcome). Does distribution matching at the trajectory level hinder fine-grained credit assignment compared to token-level advantage methods?
- Investigate preference-based rewards (human or model-assisted RLHF/RLAIF) where rewards are relative and noisy; adapt FlowRL to pairwise or listwise reward structures.
- Analyze how reward scaling and normalization (group normalization vs global/EMA baselines) interact with β and Z_φ to shape the induced target distribution.
Evaluation, metrics, and generalization
- Validate diversity gains with multiple, reproducible metrics beyond GPT-4o-mini judgment (e.g., self-BLEU, distinct-n, pairwise edit distance, AST-level/code-structure diversity, symbolic step diversity). Quantify semantic vs surface-form diversity and correlate with accuracy.
- Report variance across random seeds and provide statistical significance tests. Current tables lack confidence intervals/standard deviations, making robustness claims uncertain.
- Examine out-of-domain generalization and dataset shift (e.g., different math/coding distributions, unseen styles, adversarial prompts) to test whether “distribution matching” truly improves coverage beyond training regimes.
- Extend beyond math/code to other long-horizon reasoning domains (scientific QA, theorem proving, formal verification, planning) to assess breadth of applicability.
- Provide leakage checks for training/eval overlap (especially with DAPO-derived math data and dynamic benchmarks like LiveCodeBench/Codeforces) to rule out contamination and ensure fair comparisons.
Efficiency, scaling, and practicality
- Quantify sample efficiency and wall-clock efficiency vs PPO/GRPO: report tokens seen, updates-to-convergence, throughput, and compute/memory overhead (including long sequence log-prob computations and Z_φ forward passes).
- Assess numerical stability and implementation details for trajectory-level probability ratios over 8k tokens (e.g., log-space accumulation, precision issues).
- Explore scalability to longer contexts (e.g., 16k–32k tokens) and larger models (>32B); report any degradation in stability or performance.
- Study inference-time trade-offs: how does FlowRL interact with decoding strategies (temperature, top-p, self-consistency, best-of-N selection)? Does the matched distribution reduce or increase the need for test-time sampling budgets?
- Investigate parameter-efficient finetuning (e.g., LoRA, adapters) for FlowRL to reduce compute and memory while retaining gains.
Comparisons and baselines
- Compare against strong diversity- and entropy-focused methods beyond PPO/GRPO (e.g., SAC-style maximum-entropy RL for LLMs, AWR/AWAC-style advantage-weighted regression, DAPO variants, explicit high-entropy token upweighting) under identical compute.
- Evaluate against other distributional/energy-based or GFlowNet-inspired alignment methods on text (e.g., amortized GFlowNets, reward-weighted flow matching variants), to isolate the contribution of trajectory balance vs alternative distribution matching techniques.
- Test combined objectives (e.g., FlowRL + PPO/entropy bonus) more broadly than the single adapted baseline cited, including careful tuning to rule out under-optimized hybrids.
Safety, calibration, and behavior
- Measure safety/factuality/harms alongside reasoning accuracy to ensure distribution matching does not amplify unsafe or spurious-but-rewarded behaviors.
- Assess probability calibration and uncertainty estimation: does matching a reward-induced distribution improve calibration of success likelihoods or epistemic uncertainty?
- Probe reward hacking and mode-exploitation risks (e.g., gaming unit tests in code or exploiting brittle math checkers), and whether FlowRL exacerbates or mitigates them relative to reward-maximizing baselines.
Open implementation questions
- Specify training dynamics for Z_φ (learning rates, initialization, constraints) and its interaction with π_θ updates (e.g., alternating vs joint steps); provide guidance to avoid collapse or oscillation.
- Detail rollout/update scheduling (replay window size, on-policy freshness), and examine the trade-off between data reuse and policy drift under trajectory-level importance sampling.
- Release comprehensive reproducibility artifacts (seeds, logs, curve summaries, code to compute sequence-level ratios safely) to facilitate independent verification of results.
Glossary
- Advantage: A measure in RL estimating how much better an action is compared to a baseline at a state. "Here, denotes the advantage, computed by normalizing the group reward values"
- Advantage normalization: Normalizing advantages (e.g., within a group) to stabilize training. "without advantage normalization, clipping, or KL regularization."
- Chain-of-thought (CoT): A prompting and training paradigm that elicits step-by-step reasoning in LLMs. "To address the challenges of long CoT training"
- Clip ratio: A hyperparameter controlling how far importance ratios are allowed to deviate in PPO-style objectives. "adjust the clip ratio"
- Clipping (PPO-style clipping): Bounding importance ratios to stabilize off-policy updates. "we incorporate PPO-style clipping to bound the importance weights"
- Conditional flow matching: A training objective for learning vector fields to match conditional distributions. "advantage-weighted ratios from conditional flow matching loss"
- Conditional generation: Modeling outputs conditioned on inputs, e.g., answering a question given its text. "We formulate reasoning as a conditional generation problem"
- Critic model: A value estimator in actor-critic methods used to compute advantages. "PPO uses a critic model to estimate the advantage"
- Energy-based modeling: A framework that defines probabilities via unnormalized energies and a partition function. "Inspired by energy-based modeling"
- Entropy regularization: Adding an entropy term to the objective to encourage exploration and diversity. "Entropy regularization is a classical technique for mitigating mode collapse"
- Flow matching: Learning vector fields that transport samples from a prior to a target distribution. "inspired by flow matching"
- Flow-balanced optimization: An approach that enforces balance between incoming and outgoing probability flows during training. "flow-balanced optimization method"
- GFlowNets (Generative Flow Networks): A framework that learns policies to sample objects in proportion to reward via flow balance. "GFlowNets~\citep{JMLR:v24:22-0364} are a probabilistic framework"
- Gradient explosion: Unstable training due to rapidly increasing gradient norms, often in long sequences. "gradient explosion issues"
- Group normalization (of rewards): Normalizing rewards within a sampled group to stabilize updates. "apply group normalization to "
- GRPO: Group Relative Policy Optimization, a PPO-like method using group comparisons instead of value functions. "GRPO neglects other meaningful modes."
- Importance ratio: The ratio between current-policy and behavior-policy probabilities used for off-policy correction. "importance ratio $w = \pi_\theta(\mathbf{y}\mid\mathbf{x})/\pi_{\text{old}(\mathbf{y}\mid\mathbf{x})$"
- Importance sampling: Reweighting off-policy samples to correct distribution mismatch in policy updates. "we employ importance sampling inspired by PPO to stabilize policy updates with off-policy data."
- KL regularization: Penalizing divergence from a reference policy to constrain updates. "without advantage normalization, clipping, or KL regularization."
- Markov Decision Process (MDP): A formal framework for sequential decision-making with states, actions, and transitions. "a modified Markov Decision Process (MDP)"
- Maximum entropy reinforcement learning: RL that maximizes expected return plus an entropy bonus for exploration. "a maximum entropy reinforcement learning problem"
- Micro-batch updates: Performing parameter updates using smaller subsets of data to improve throughput or memory usage. "perform micro-batch updates"
- Mode collapse: Concentration of probability mass on few modes, reducing diversity. "leading to mode collapse and higher KL divergence."
- Mode coverage: Ensuring the policy captures multiple high-reward modes rather than collapsing. "encouraging mode coverage."
- Off-policy data: Experience generated by a different policy than the one currently being optimized. "off-policy data."
- On-policy sampling: Collecting data from the current policy being optimized. "fully on-policy sampling"
- Outcome reward: The final scalar reward assigned to a completed trajectory. "denotes the outcome reward commonly used in reinforcement learning"
- Partition function: The normalizing constant that converts unnormalized scores (e.g., exponentiated rewards) into a probability distribution. "learnable partition function "
- Policy drift: Large changes in the policy across updates that can destabilize learning. "prevent excessive policy drift"
- Policy gradient: A family of methods that directly compute gradients of expected return with respect to policy parameters. "REINFORCE applies the policy gradient directly"
- Proximal Policy Optimization (PPO): A policy gradient method that stabilizes updates via clipped objectives and a critic. "PPO improves upon REINFORCE with better stability and efficiency in complex settings"
- Reference model: A fixed pretrained policy used as a prior or constraint during training. "reference model as a prior constraint on the reward distribution"
- Reward distribution matching: Training the policy to match a target distribution induced by reward values, not just maximize expected reward. "reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning"
- Reward shaping: Modifying the reward signal to stabilize or guide learning without changing the optimal policy. "Reward shaping via length normalization"
- Reverse KL divergence: The divergence D_KL(p || q) used here to match the policy to a reward-induced target distribution. "minimize the reverse KL divergence between the policy and the target distribution"
- Rollout: A sampled trajectory or generated response from the policy. "more rollouts per update"
- Sampling mismatch: A discrepancy between the data-generating policy and the current policy used for training. "Sampling mismatch."
- Surrogate loss: An objective used to optimize policies indirectly, often involving importance weights and constraints. "serves as a coefficient in the surrogate loss"
- Trajectory balance: A GFlowNet objective enforcing consistency between cumulative log-probability, partition function, and reward along a trajectory. "trajectory balance loss used in GFlowNet"
- Value function: An estimator of expected return from a state (or state-action) used in actor-critic methods. "eliminating value functions"
Collections
Sign up for free to add this paper to one or more collections.

