- The paper introduces CtrlFlow, a novel trajectory synthesis method that minimizes cumulative errors in online reinforcement learning.
- It leverages conditional flow matching with the Controllability Gramian Matrix and energy vector fields to guide high-return trajectory sampling.
- Experiments on MuJoCo benchmarks show improved sample efficiency and faster convergence compared to traditional model-based RL methods.
Controllable Flow Matching for Online Reinforcement Learning
Introduction
The paper "Controllable Flow Matching for Online Reinforcement Learning" (2511.06816) addresses critical challenges in Model-Based Reinforcement Learning (MBRL) associated with cumulative errors during long-horizon rollouts. These errors degrade policy quality by misaligning synthetic trajectories from real state-action distributions. The authors propose a novel trajectory-level synthesis method, CtrlFlow, which utilizes conditional flow matching (CFM) to model trajectory distributions directly, circumventing the inaccuracies of traditional environment-driven simulation. By leveraging the Controllability Gramian Matrix, CtrlFlow enhances data robustness and cross-task generalization, showing superior performance in MuJoCo benchmark tasks over baselines.
Methodology
The proposed CtrlFlow approach is grounded in several methodological advancements:
- Trajectory-Level Flow Matching Model: Instead of predicting step-by-step transitions, CtrlFlow generates entire trajectories at once, significantly reducing cumulative errors and providing a distributionally-consistent trajectory dataset. The model applies a conditional vector field to sample high-return trajectories systematically.
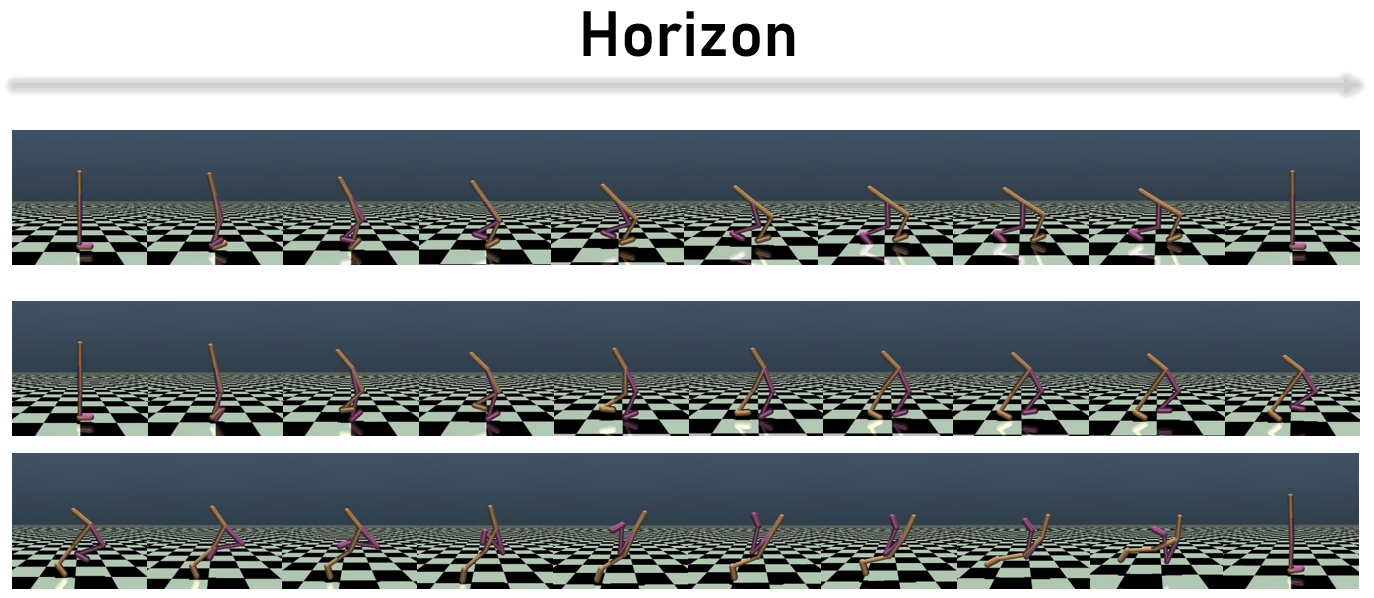
Figure 1: A validation episode in the Walker2d benchmark task of MuJoCo, demonstrating trajectory data generated by CtrlFlow.
- Controllability Gramian Matrix: This matrix aids in minimizing the control energy needed for trajectory generation, ensuring that the trajectories align through non-linear controllable dynamics. It quantifies the trajectory's flow, crucial for optimizing sampling conditions under varying distributions.
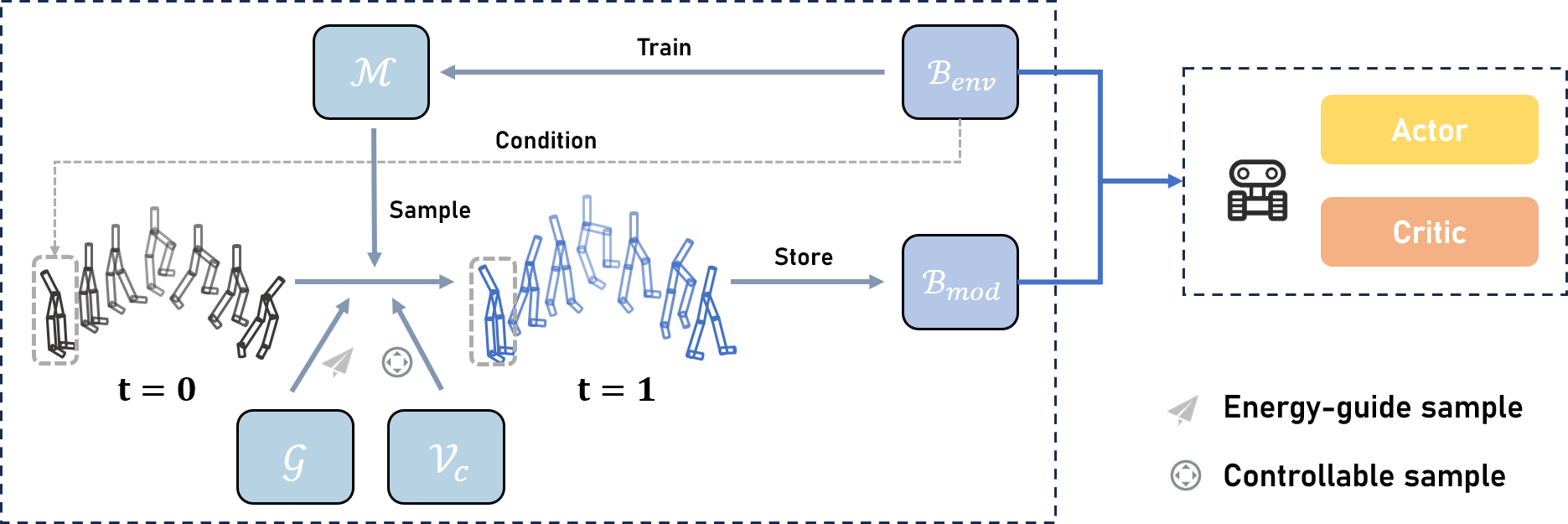
Figure 2: The overall architecture of CtrlFlow including the CFM model $\mathcal{M$.
- Value Guidance with Energy Vector Field: By transforming vector fields into energy-based vectors through an energy function, CtrlFlow can iteratively steer sampled trajectory data towards high-cumulative discounted returns. This process accelerates convergence more effectively than traditional MBRL methods.
Results
Experimental evaluations on MuJoCo tasks demonstrate CtrlFlow's prowess:
- Performance: Compared to both model-based and model-free RL methods, CtrlFlow exhibits superior sample efficiency and convergence rates. For example, it achieves 90% of peak performance in the Hopper task within 35k steps, outperforming MBRL baselines that require approximately double the steps for similar results.
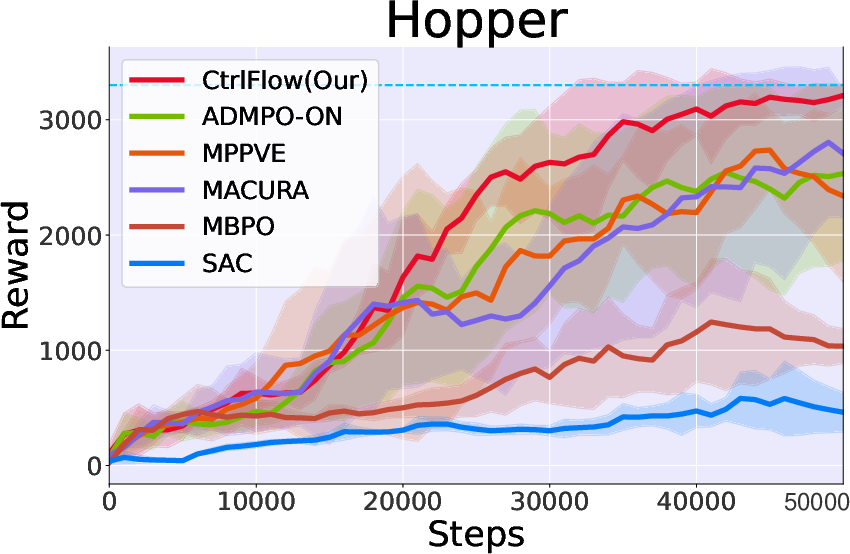
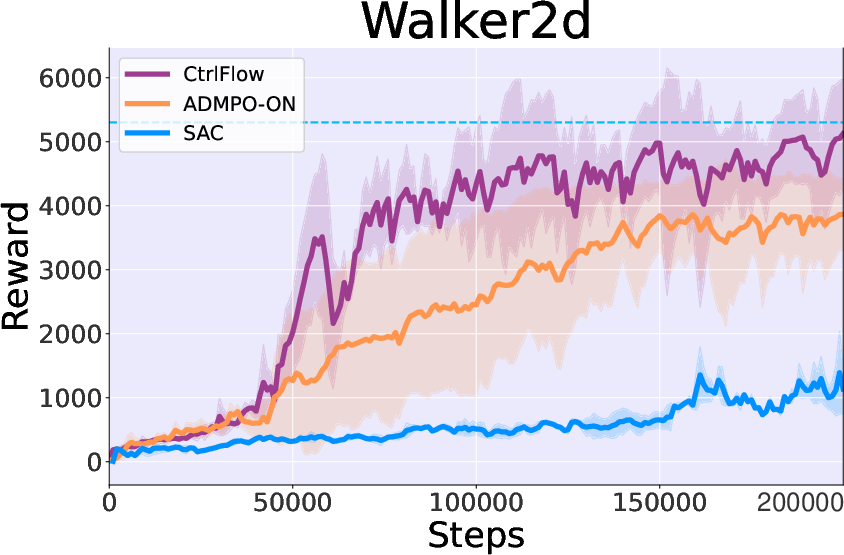
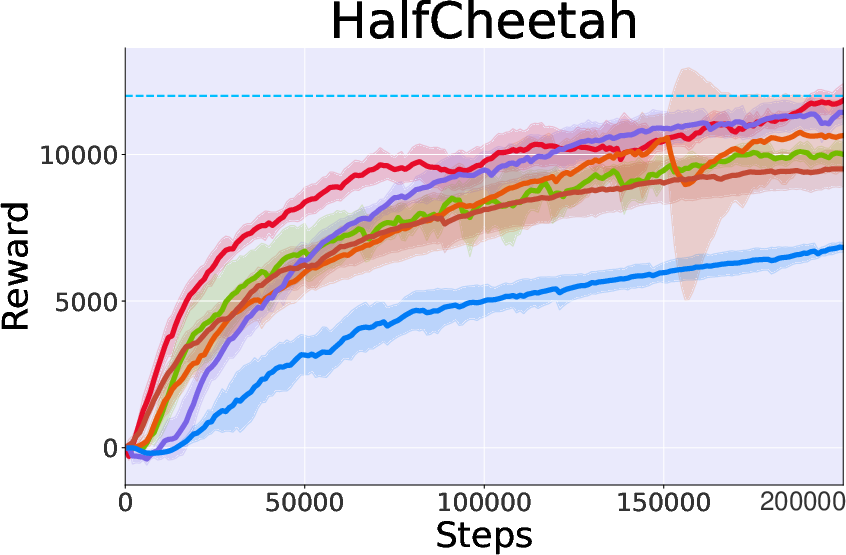
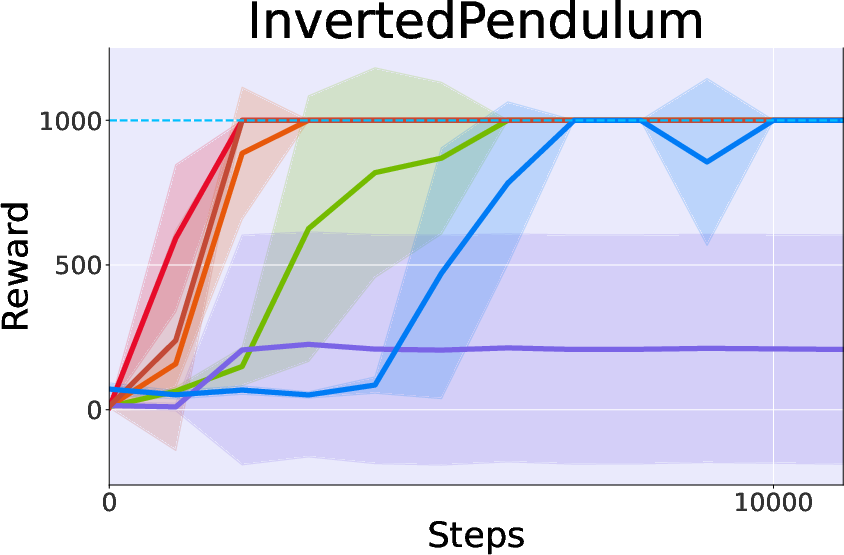
Figure 3: Performance on MuJoCo Benchmark illustrating CtrlFlow's superiority over several baselines.
- Generated Length Study: Longer trajectory generation (up to 10 steps) enriches transition information and yields better policy optimization, although extremely long horizons (like 30 or 50 steps) face heightened complexity and diminished performance.
- Control Importance: The inclusion of control theory elements significantly enhances stability and convergence speed, evidenced by greater reward consistency and alignment accuracy in trajectory transitions.
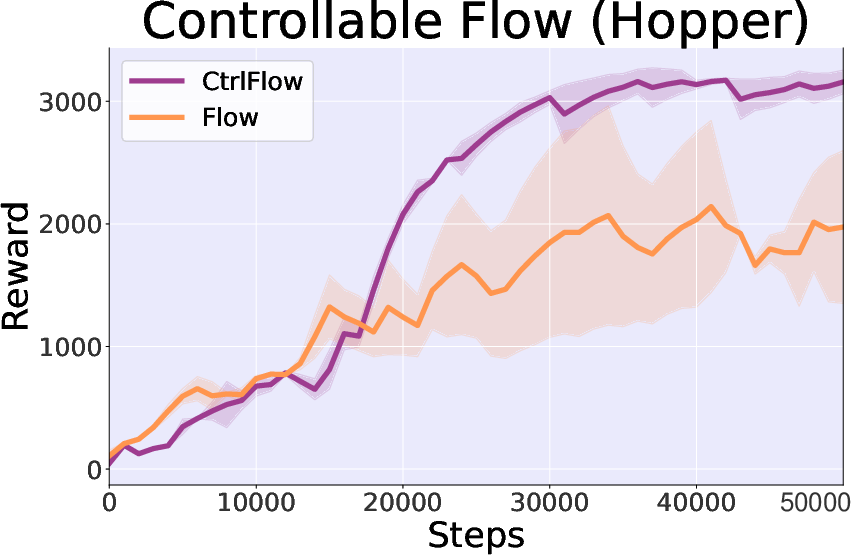
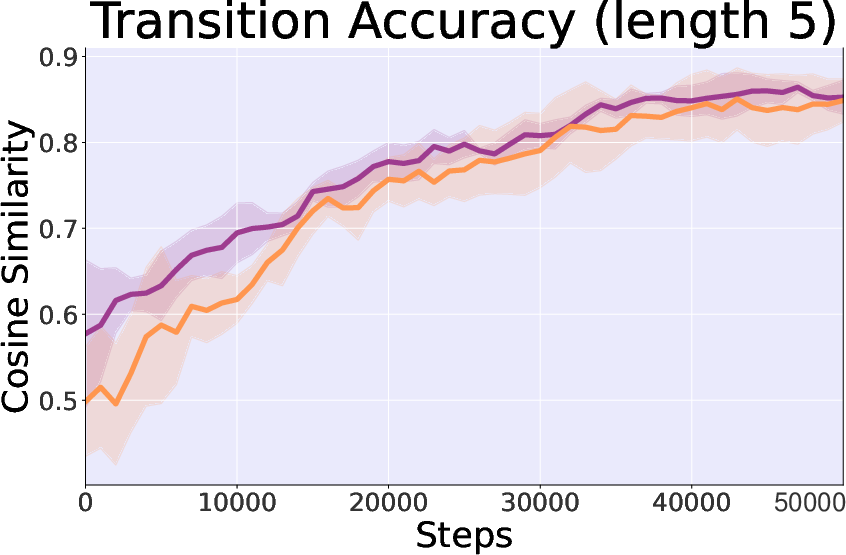
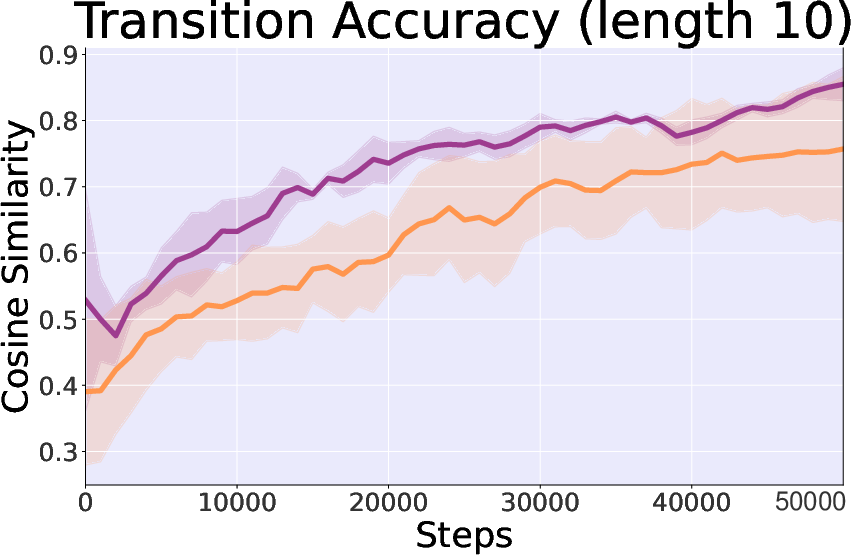
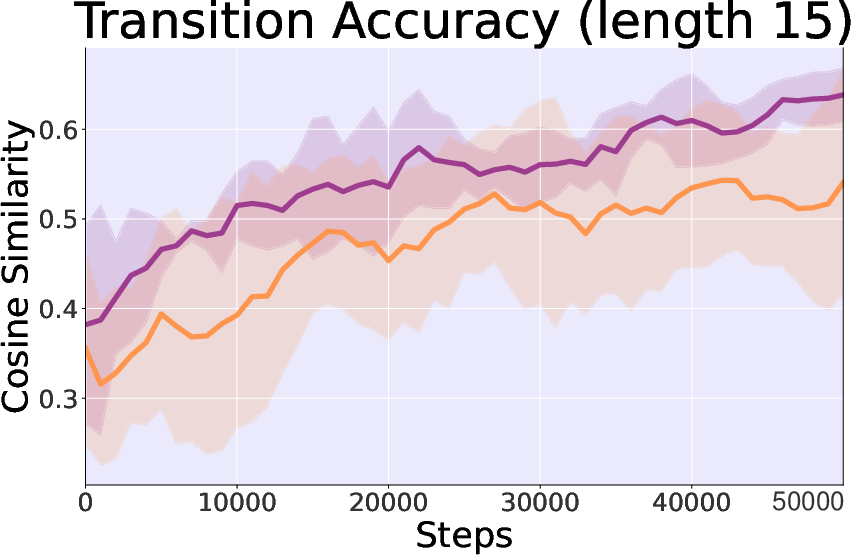
Figure 4: Study on control theory in Hopper-v3 task, comparing controllable and cosine similarity in generated state accuracy.
- Value Guidance Impact: Energy-guided trajectory generation demonstrates accelerated convergence in Hopper-v3 by enabling more directed learning.
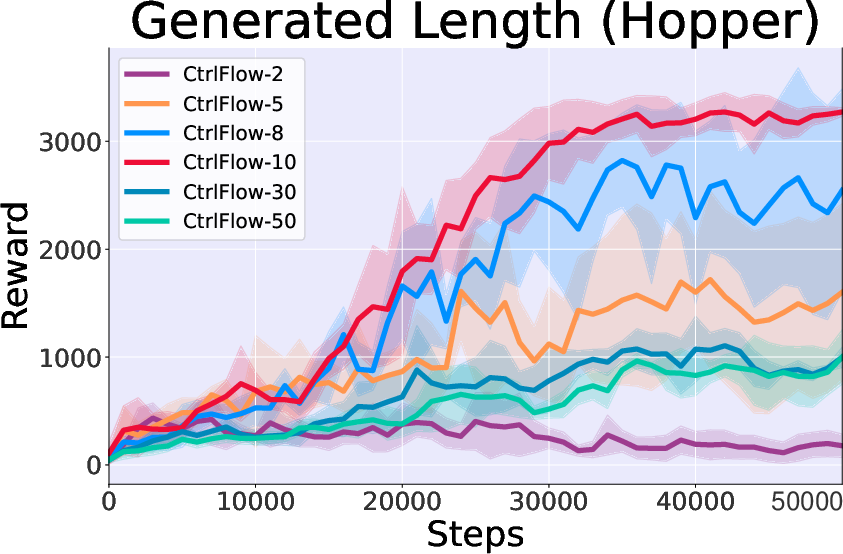
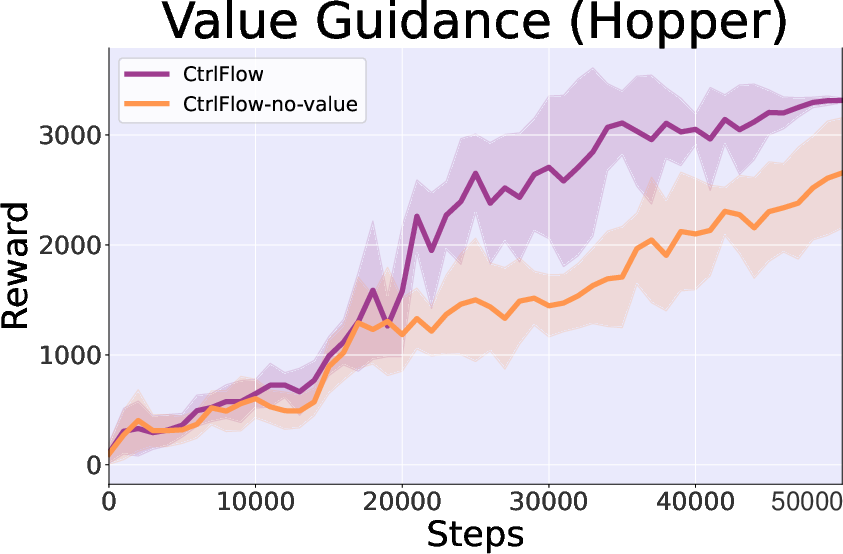
Figure 5: Generated length study showing improved performance with the inclusion of value guidance.
Discussion and Implications
CtrlFlow represents a substantial step forward in reinforcement learning, particularly in its approach to dynamic distribution adaptation and trajectory sampling. The integration of flow matching with controllability principles offers not just enhanced stability but also predictive accuracy in policy learning. While currently limited in certain partially observable scenarios, CtrlFlow's trajectory-centric data synthesis holds promise for applications in complex real-world environments requiring robust decision-making capabilities. Future research might extend its adaptability to partially observable settings, improving efficacy in broader applications.
Conclusion
The introduction of CtrlFlow in this study highlights a pivotal shift in reinforcement learning from traditional step-wise predictive models to sophisticated trajectory-based sampling frameworks. By mitigating cumulative errors and fostering dynamically controlled returns through flow matching and energy-based vector fields, CtrlFlow sets a new benchmark for efficiency and accuracy in RL applications. These advances underscore both theoretical and practical strides in the quest to enable more efficient and scalable reinforcement learning systems.