- The paper introduces a novel flow-based model that estimates full return distributions in reinforcement learning, enhancing exploration and safety.
- It employs a flow-matching objective with ODEs to transform noise into complex return paths while using uncertainty estimates for efficient learning.
- It demonstrates a 1.3x improvement in success rates over traditional methods in both offline and offline-to-online benchmarks, ensuring robust policy performance.
Detailed Summary of "Value Flows" (2510.07650)
Introduction and Motivation
The paper "Value Flows" introduces a novel approach to distributional reinforcement learning (RL) by leveraging flow-based models to estimate the entire distribution of future returns rather than a scalar value. This approach provides robust learning signals and facilitates applications in exploration and safe RL by capturing return distributions more comprehensively. Traditional methods model return distribution via discrete bins or quantiles, but these methods often fail to capture the intricate structure of return distribution and uncertainty in decision-making states. Instead, this paper proposes utilizing modern flow-based models to improve the granularity in return distribution estimation and utilize this for identifying high return variance states.


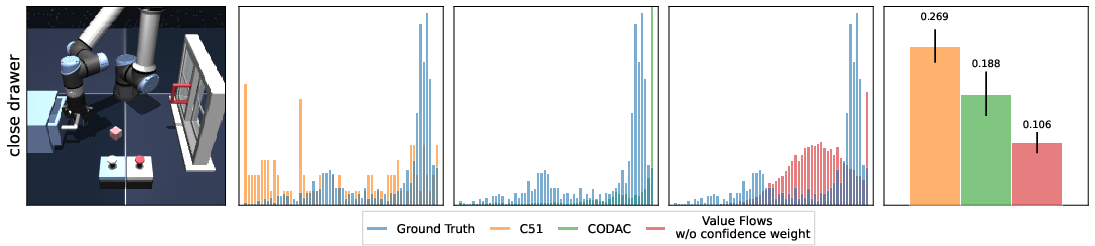
Figure 1: Visualizing the return distribution. (Column 1) The policy completes the task of closing the window and closing the drawer using the buttons to lock and unlock them. (Column 2) C51 predicts a noisy multi-modal distribution, and (Column 3) CODAC collapses to a single return mode. (Column 4) Value Flows.
Methodology
Flow-Matching Objective
The proposed method applies a flow-matching objective to create probability density paths that satisfy the distributional Bellman equation. This method uses ordinary differential equations (ODEs) to transform a noise distribution into a complex return distribution. This is achieved by learning a time-dependent vector field that generates a probability path for the returns and adjusting this path to match observations from dynamic environments.
Flow Derivative for Uncertainty Estimation
The uncertainty in return distributions is captured using a proposed flow-derivative ODE, allowing the system to comprehend transition variance better. This uncertainty information is then employed to focus learning on making more accurate predictions in transitions where this variance is high, optimizing learning efficiency.
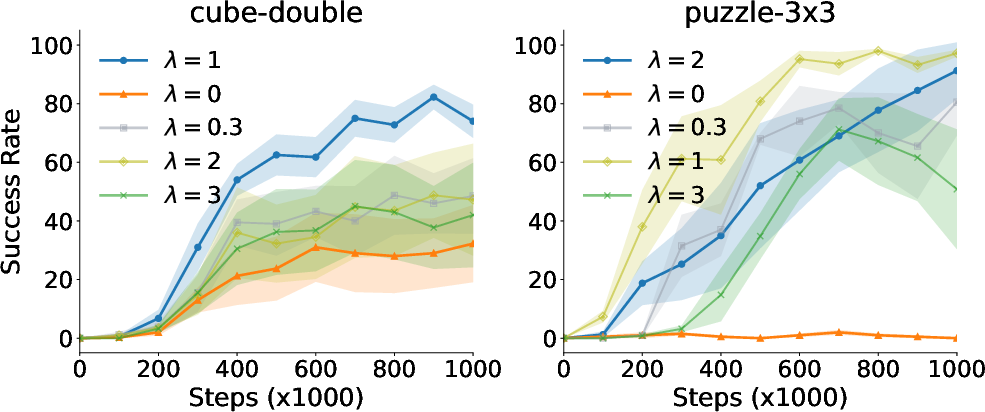
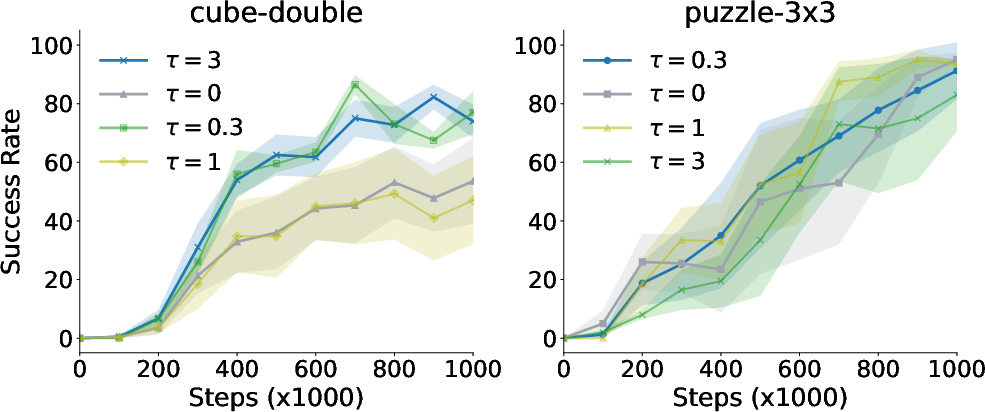
Figure 2: Regularizing the flow-matching loss is important. The regularization coefficient lambda needs to be tuned for better performance.
Algorithm Components
The complete algorithm, named Value Flows, involves:
- Learning the Vector Field: Using a flow-matching loss to fit the return distribution. The loss is weighted by the aleatoric uncertainty to prioritize fitting more ambiguous areas accurately.
- Policy Extraction: In offline settings, a behavioral cloning policy is employed with rejection sampling to find actions maximizing the Q-value estimation. In offline-to-online transitions, a one-step flow policy is trained to maximize Q-values while respecting behavioral constraints.
- Practical Constraints: The algorithm is efficient in estimating return variance and expectation, contributing to a stable learning framework.
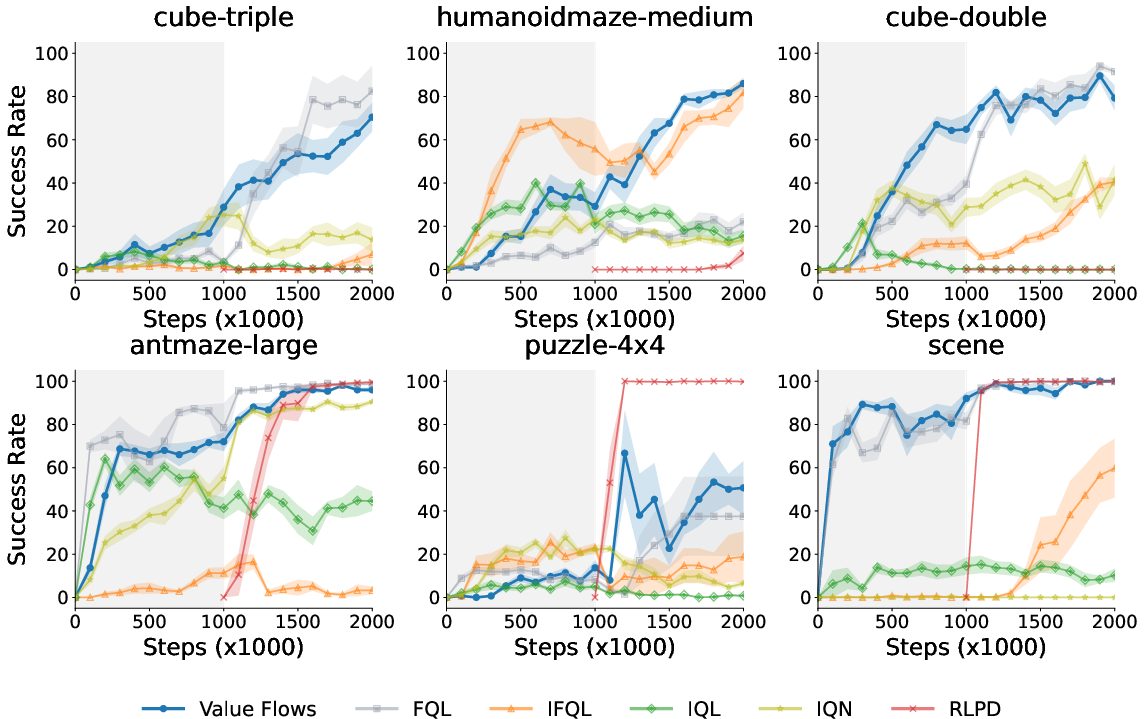
Figure 3: Value Flows continues outperforming prior methods with online interactions.
Experiments and Results
Benchmarks Evaluated
The method was evaluated across both offline and offline-to-online RL tasks, using state-based and image-based benchmarks from OGBench and D4RL datasets.
Smart Prediction and Superior Performance
- The proposed Value Flows framework improves the estimation of multimodal return distributions and shows a significant gain (1.3x on average) in success rates across various settings. It outperforms both traditional distributional methods (e.g., C51, IQN) and other policy-based RL methods.
- For offline-to-online fine-tuning, Value Flows demonstrates strong sample efficiency by effectively using online data to adjust previously learned models.
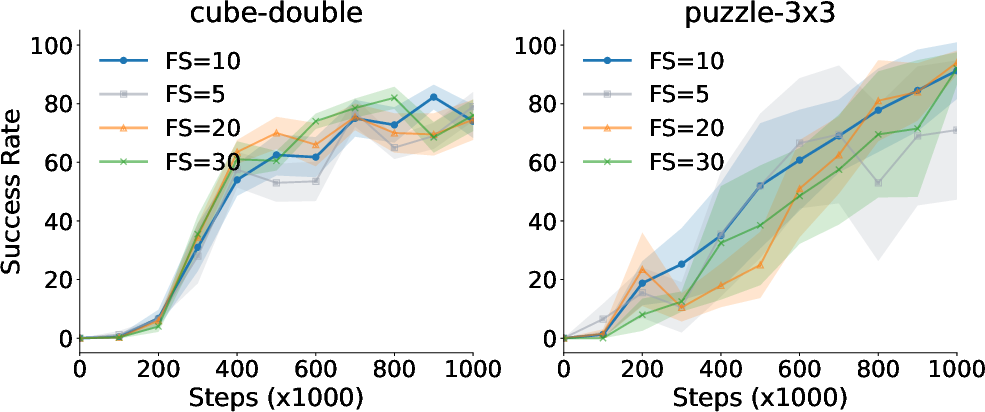
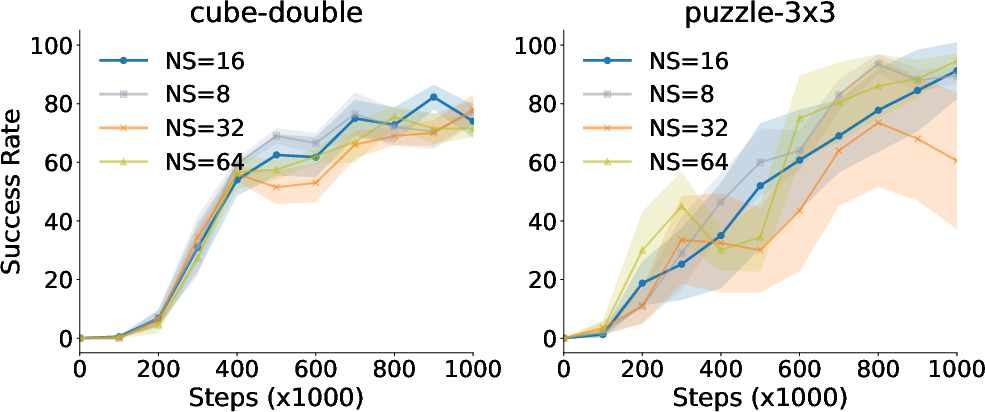
Figure 4: Value Flows visualization showing the efficiency in learning complex return distributions.
Conclusion and Future Work
Value Flows presents an advanced methodology for reinforcement learning that can leverage the nuanced return distributions to make informed policy decisions. While it exhibits strong performance, future work could explore disentangling epistemic from aleatoric uncertainty to further refine decision-making and ultimately enhance the robustness of the policy extraction mechanisms.
Further experimental work could present opportunities for integrating more sophisticated policy structures within the distributional RL framework to exploit these modeling advancements fully. Potential limitations are mentioned in estimating uncertainties fully and adapting policies in highly dynamic environments without further constraints.
Such explorations and improvements could continue refining this innovative approach, bridging theoretical developments with impactful real-world applications.