GLM-OCR: High-Fidelity Document Understanding at 0.9 Billion Parameters
This presentation examines GLM-OCR, a compact multimodal framework that challenges the assumption that document intelligence requires massive model scale. By coupling a 0.4B visual encoder with a 0.5B language decoder and introducing Multi-Token Prediction for efficient decoding, GLM-OCR achieves state-of-the-art performance on document parsing and key information extraction while remaining deployable in resource-constrained production environments. The talk explores the architectural choices, task-specific capabilities, and deployment trade-offs that enable competitive accuracy and throughput at a fraction of typical model sizes.Script
Can a model with fewer than 1 billion parameters match or exceed the document understanding capabilities of systems 10 times its size? GLM-OCR demonstrates that intelligent architectural design and efficient decoding can challenge the prevailing assumption that document intelligence scales primarily with parameter count.
The researchers couple a 0.4 billion parameter vision encoder with a half-billion parameter language decoder, yet achieve 94.6 on OmniDocBench—beating every comparable model. Throughput reaches nearly 2 pages per second, making this a production-ready system despite its compact footprint.
The performance advantage stems from a deliberate architectural choice that reimagines how documents should be decoded.
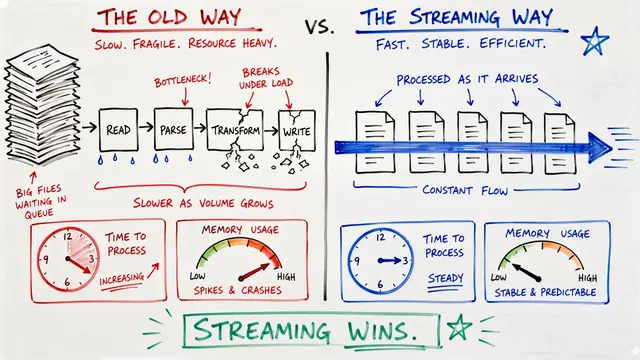
Standard autoregressive decoding generates one token at a time, creating a bottleneck for structured outputs like tables. Multi-Token Prediction generates 10 tokens per forward pass, exploiting the predictable sequential structure of OCR outputs and slashing inference overhead without sacrificing accuracy.
The system orchestrates a two-stage workflow. Layout analysis first segments complex documents into coherent regions, which are then processed in parallel by the core model. This decomposition prevents hallucination, handles variable layouts gracefully, and enables throughput scaling through concurrent region recognition—critical for production environments where documents rarely follow a single template.
Beyond raw OCR, the model handles tables with nested headers, mathematical formulas with precise spatial relationships, and key information extraction from invoices and forms. It achieves 96.5 on formula recognition and 85.2 on complex table benchmarks, demonstrating that unified generative architectures can master structurally diverse tasks without specialized modules for each.
GLM-OCR proves that document intelligence need not be the exclusive domain of billion-parameter giants. Strategic decoding innovations and modular workflows deliver competitive accuracy at a tenth the size, redefining what's deployable in cost-sensitive and latency-critical environments. Explore more research breakdowns and create your own video presentations at EmergentMind.com.