Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Tuna-2 challenges a fundamental assumption in multimodal AI by removing all pretrained vision encoders and operating directly in pixel space. Through masking-based feature learning and pixel-space flow matching, this encoder-free architecture achieves state-of-the-art performance on both understanding and generation tasks at the 7B scale, demonstrating that unified transformer models can learn robust visual representations end-to-end without the traditional modular frontend that has dominated multimodal systems.Script
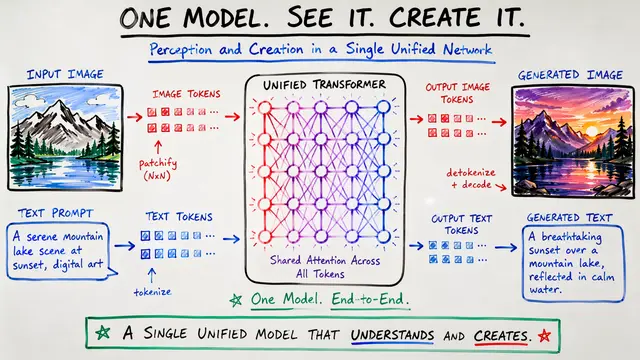
Most multimodal AI systems rely on pretrained vision encoders as gatekeepers between images and language models. Tuna-2 throws out that entire pipeline and learns directly from raw pixels, matching or beating the best encoder-based models on both understanding and generation.
The architecture is radically simple: raw image patches are embedded with learnable layers and fed straight into a single transformer backbone that handles both vision and language. No VAE bottleneck, no representation encoder, just end-to-end learning from pixels to semantics.
To force robust pixel-space representations, the authors randomly mask image patches during training. The model must answer questions about partially hidden images and simultaneously reconstruct the missing pixels, creating strong regularization that benefits both understanding and generation.
On fine-grained visual reasoning benchmarks like V-star, CountBench, and VisuLogic, Tuna-2 achieves the highest accuracy among all 7 billion parameter models. The encoder-free design actually outperforms systems with pretrained vision frontends, challenging decades of assumptions about how visual AI should be built.
Training dynamics reveal a fascinating pattern. The encoder-based Tuna-R learns faster early on, but Tuna-2 overtakes it as data scale increases, demonstrating superior long-term scalability when the model learns pixel representations from scratch.
Tuna-2 proves that pretrained vision encoders are no longer necessary for state-of-the-art multimodal AI. To explore more research like this and create your own video summaries, visit EmergentMind.com.