GLM-OCR Technical Report
Abstract: GLM-OCR is an efficient 0.9B-parameter compact multimodal model designed for real-world document understanding. It combines a 0.4B-parameter CogViT visual encoder with a 0.5B-parameter GLM language decoder, achieving a strong balance between computational efficiency and recognition performance. To address the inefficiency of standard autoregressive decoding in deterministic OCR tasks, GLM-OCR introduces a Multi-Token Prediction (MTP) mechanism that predicts multiple tokens per step, significantly improving decoding throughput while keeping memory overhead low through shared parameters. At the system level, a two-stage pipeline is adopted: PP-DocLayout-V3 first performs layout analysis, followed by parallel region-level recognition. Extensive evaluations on public benchmarks and industrial scenarios show that GLM-OCR achieves competitive or state-of-the-art performance in document parsing, text and formula transcription, table structure recovery, and key information extraction. Its compact architecture and structured generation make it suitable for both resource-constrained edge deployment and large-scale production systems.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GLM-OCR, a small but powerful AI that can read and understand documents from images or PDFs. Think of it as a smart reader that not only recognizes words, but also understands tables, math formulas, stamps/seals, and how a page is laid out. It’s designed to be fast, accurate, and cheap to run in the real world.
What were the researchers trying to achieve?
The team had a few clear goals:
- Read complex documents (with tables, formulas, code, and stamps) accurately.
- Work fast and handle lots of pages at once without needing huge computers.
- Produce clean, structured results (like clean tables or JSON data) that software can use.
- Combine many tasks (OCR, layout understanding, and key-info extraction) in one unified system.
How did they build it?
They built a compact “two-part” model and a practical system around it.
- The model:
- A vision part (like eyes) that looks at the page image and turns it into visual features.
- A language part (like a brain) that turns those features into organized text, tables, or data.
- Altogether it’s “small” for this kind of AI (about 0.9 billion parameters), which makes it faster and cheaper than many giant models.
- Predicting multiple tokens at once:
- Normally, AI writes one tiny piece of text at a time (a “token,” like a short chunk of a word).
- GLM-OCR uses “Multi-Token Prediction,” which is like typing several characters at once instead of one-by-one. This speeds up reading without losing accuracy, especially for long, structured outputs like tables.
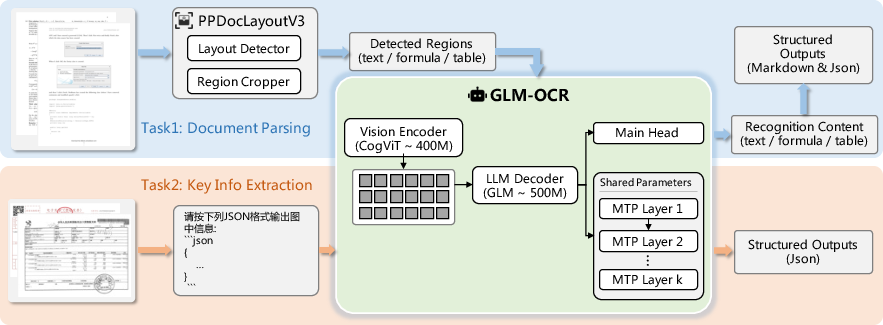
- Two-stage pipeline (how it processes a page): 1) Layout analysis: First, it divides the page into parts—paragraphs, tables, formulas—like cutting a pizza into slices so each piece is easier to handle. 2) Parallel recognition: Then it “reads” those parts at the same time and merges the results into a well-organized output.
- Structured outputs:
- It can produce Markdown (a simple way to format documents) and JSON (a tidy, labeled data format). Think of JSON as named boxes for information like “date,” “total,” or “address.”
- Training in steps (in simple terms):
- First it learns to see well (vision training).
- Then it learns to connect what it sees with language (vision–language pretraining).
- Next it practices on real OCR tasks—text, tables, formulas, and key info.
- Finally it uses reinforcement learning (learning from automatic checks and rewards) to reduce mistakes like broken table tags or bad JSON.
What did they find?
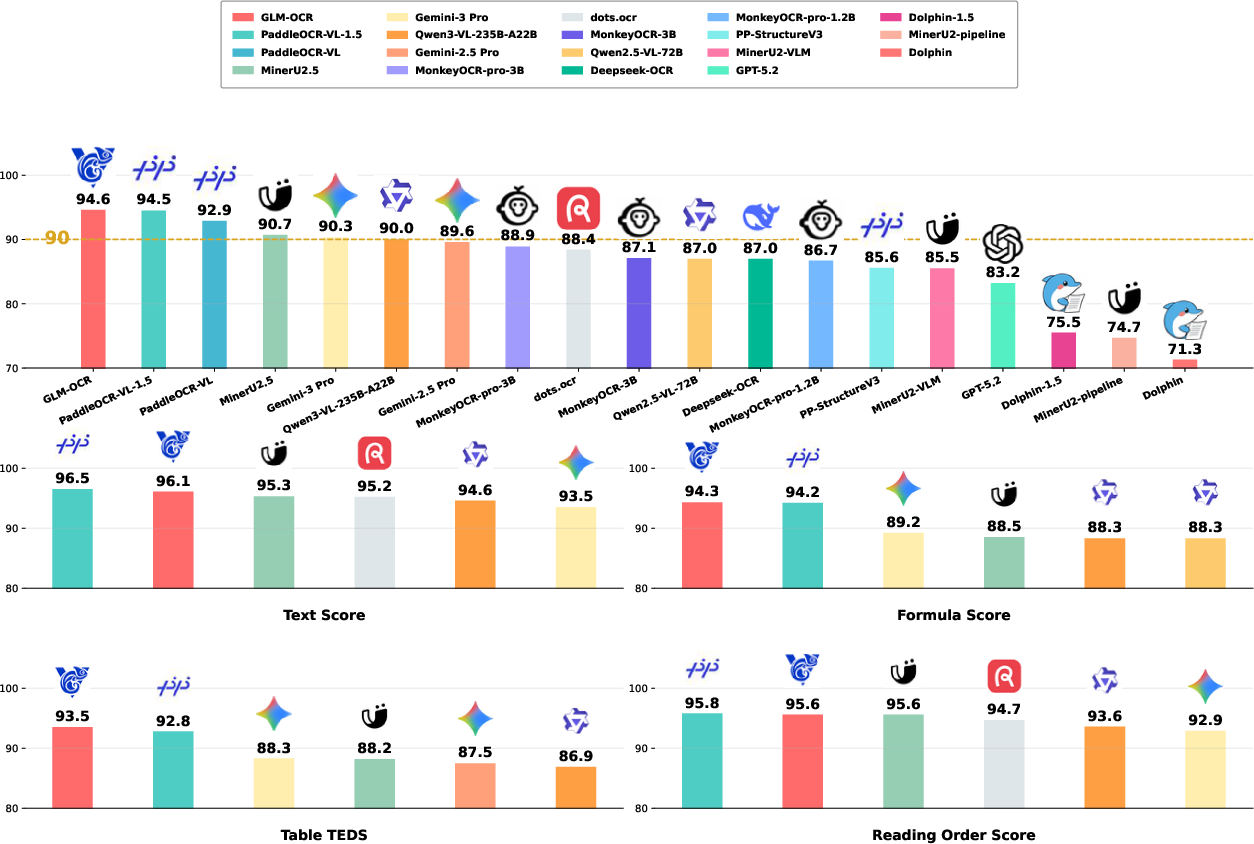
- Strong accuracy: On many standard tests for document understanding, GLM-OCR scores as well as, or better than, much bigger models. It handles:
- Text recognition
- Math formula transcription
- Table structure recovery
- Key information extraction (like pulling totals and dates from receipts)
- Real-world performance: On practical tasks (like reading receipts, recognizing official seals, handling handwriting, recognizing tables in the wild, and working in multiple languages), it performs consistently well.
- Speed and efficiency:
- Thanks to predicting multiple tokens at a time and processing page regions in parallel, it’s about 50% faster in decoding on average.
- It can run both in large server settings and on smaller, edge devices (like cheaper machines) because it’s compact.
- Easy to deploy and adapt:
- It works with popular serving tools (so companies can run it at scale).
- It supports fine-tuning, so you can adapt it to your specific document type or industry.
Why does this matter?
- Faster, cheaper document processing: Businesses and apps can automatically read thousands of pages quickly—like invoices, contracts, research papers—saving time and cost.
- Better data quality: Because the output is structured (clean tables, valid JSON), it’s easier to plug into databases and software without lots of fixing.
- Practical at all sizes: A compact, well-designed model means more organizations can use powerful document AI without massive hardware.
- Versatile: One system handles many tasks—text, tables, formulas, and key fields—reducing the need for many separate tools.
In short, GLM-OCR shows that with smart design—splitting pages into parts, predicting several tokens at once, and training carefully—you can get top-tier document understanding that’s both fast and affordable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address.
- Data transparency: The paper omits detailed statistics and composition of pretraining and SFT datasets (domains, document types, language/script distribution, resolution ranges), making it hard to reproduce or assess coverage and bias.
- Licensing and provenance: No disclosure of data licensing, privacy handling, or potential contamination with evaluation sets; unclear compliance for “tens of billions” of image–text pairs and in-house datasets (e.g., seals, receipts).
- Multilingual coverage: Evaluation and training focus on eight languages; coverage and performance on right-to-left (e.g., Arabic, Hebrew), complex shaping (Indic scripts), vertical writing (e.g., Japanese), diacritics, and low-resource scripts are unreported.
- Tokenization choices: The effect of GLM’s tokenizer on OCR fidelity (e.g., CJK character granularity, whitespace, punctuation, math symbols) is not analyzed; no comparison with character-level or byte-level tokenization for OCR/formula tasks.
- MTP design trade-offs: No ablations varying MTP lookahead k, head sharing vs non-sharing, or speed–accuracy curves; unclear failure modes (e.g., compounding errors) when multiple tokens are predicted per step.
- Decoding strategy with MTP: The inference algorithm for reconciling disagreeing MTP heads (e.g., acceptance/reject criteria, fallback to autoregressive) is unspecified; no comparison to speculative decoding or blockwise parallel decoding baselines.
- Structural validity under MTP: While RL adds structural checks, there is no quantitative analysis of tag/JSON/LaTeX validity rates across k values or sequence lengths nor a breakdown by content type (tables vs formulas vs plain text).
- Constrained decoding: The system relies on learned structure; no experiments with grammar- or schema-constrained decoding (e.g., finite-state or trie-constrained decoding for Markdown/HTML/JSON/LaTeX) to further reduce malformed outputs.
- Error calibration and confidence: The model does not produce per-token or field-level confidence scores, hindering downstream QA, selective abstention, or human-in-the-loop workflows.
- Two-stage pipeline coupling: Layout and recognition are trained and evaluated separately; no joint-training or end-to-end fine-tuning study to mitigate error propagation from layout detection.
- Layout analysis robustness: No quantitative error analysis of PP-DocLayout-V3 on edge cases (overlapping regions, headers/footers, stamps overlapping text, multi-column with float elements), nor its impact on final structured outputs.
- Reading order reconstruction: The “Merge … Post Process” module is not described or evaluated; no ablation on reading-order heuristics, cross-page reading order, or multi-column irregularities.
- Runtime attribution: Throughput gains are reported, but component-wise latency (layout detection vs recognition vs post-processing), variance (p95/99), and CPU–GPU transfer overheads are not provided.
- Scalability under concurrency: Performance under high-concurrency, multi-tenant serving (e.g., batching effects, scheduler interactions with MTP, memory footprints) is unreported.
- Memory and energy: No detailed memory breakdown with/without MTP heads, nor energy/efficiency metrics (e.g., Joules/page), quantization effects, or CPU/edge-device performance beyond pages/sec.
- Input resolution and tiling: Maximum supported resolution, tiling/patching strategies for very large pages, and their effects on fidelity and speed are not specified.
- Long-document and multi-page handling: No evaluation of multi-page documents with cross-page references (e.g., figure/table references, continued tables), or mechanisms to maintain global context and consistent schema across pages.
- Tables beyond benchmarks: Limited insight into extremely irregular tables (unruled, rotated, nested, spanning pages), cell type inference (numeric vs text), and alignment errors beyond TEDS aggregates.
- Formula edge cases: The model’s behavior on very complex 2D layouts (piecewise, commutative diagrams, aligned multi-line equations, rare LaTeX macros) and ambiguity resolution is not analyzed; compilation success rates are not reported.
- Handwriting robustness: Mixed results for handwriting are noted, but there is no per-script or style breakdown (cursive, connected scripts), nor augmentation/denoising strategies tailored for handwriting.
- KIE generalization: Prompt-based KIE lacks analysis on schema drift, zero-shot or few-shot adaptation to unseen forms, field disambiguation, and handling of overlapping/implicit fields without explicit boxes.
- Schema discovery: The model assumes user-specified JSON schemas; no exploration of automatic schema induction or discovery from unlabeled form distributions.
- Security and prompt injection: No assessment of prompt-injection robustness in KIE settings (e.g., adversarial instructions embedded in documents), data exfiltration risks, or mitigations.
- Adversarial and degradation robustness: Effects of occlusion, watermarking, compression, heavy skew/blur, photographic lighting artifacts, or adversarial perturbations are not systematically evaluated.
- Fairness and bias: There is no analysis of differential performance across languages, regions, document sources, or protected attributes; no bias mitigation strategies are described.
- RL details and stability: GRPO hyperparameters, reward weightings, credit assignment for long structured sequences, and RL-induced regressions (e.g., over-optimization of structure at content cost) are not documented.
- Post-RL generalization: The impact of RL on out-of-domain generalization and on tasks not directly rewarded (e.g., code OCR) is unstudied.
- Comparative ablations: The contribution of each training stage (encoder pretrain, MTP pretrain, SFT with MTP, RL) is not disentangled through ablation studies.
- External layout detector dependency: Reliance on a third-party layout model (PP-DocLayout-V3) raises portability and licensing questions; no study of substituting detectors or training a compact in-house detector.
- Fine-tuning sample efficiency: While fine-tuning is supported, there are no experiments quantifying data requirements, overfitting risks, or catastrophic forgetting across tasks when adapting to a new domain.
- Evaluation reproducibility: Hardware, training compute budgets, seeds, and full hyperparameter settings for each stage are not provided; some benchmarks use in-house datasets without public release, hindering replication.
- Downstream integration: There is no discussion of canonicalization (e.g., normalization of whitespace, units, numeral formats), deduplication across pages, or entity linking for KIE outputs in production pipelines.
- Output determinism: The paper notes minor stochastic formatting variation, but does not quantify variance across repeated runs or propose deterministic decoding modes for strict reproducibility.
- Privacy-preserving deployment: No techniques (e.g., on-device differential privacy, redaction, secure enclaves) are explored for sensitive documents in regulated environments.
- Error taxonomy: Apart from headline scores, there is little qualitative error analysis (e.g., top failure categories per task) to guide targeted improvements.
Practical Applications
Practical Applications Derived from GLM-OCR
Below is a concise synthesis of practical, real-world applications traceable to the paper’s core findings and innovations: a compact 0.9B multimodal OCR model, a two-stage layout→region pipeline, Multi-Token Prediction (MTP) for high-throughput structured decoding, unified document parsing and KIE under a generative framework, structured RL rewards, efficient deployment (vLLM/SGLang/Ollama, MaaS), and turnkey fine-tuning.
Immediate Applications
The following use cases can be deployed now, leveraging the released model, SDK, and serving stack.
Industry and Enterprise
- Accounts Payable (AP) automation and invoice/receipt processing
- Sectors: Finance, Retail, ERP/Accounting
- Tools/workflows: GLM-OCR SDK for PDF/image ingestion → layout analysis (PP-DocLayout-V3) → regional recognition → JSON export; KIE prompts for fields (seller, tax ID, totals); batch processing via MaaS API
- Rationale: SOTA/competitive KIE scores and 1.86 pages/s PDF throughput reduce cost and latency; structured output validation (JSON parse, missing/duplicate penalties) improves reliability
- Assumptions/dependencies: Clear schema prompts; acceptable scan quality; privacy/compliance for cloud use; domain fine-tuning improves vendor-specific templates
- Contract and policy document parsing to Markdown/JSON
- Sectors: Legal, Insurance, Compliance
- Tools/workflows: Layout-aware parsing → Markdown with reading order + tables → downstream clause extraction; integration with e-discovery and policy management tools
- Rationale: Robust layout parsing and table recovery (TEDS/OmniDocBench scores) enable machine-readable corpora
- Assumptions/dependencies: Complex multi-column or cross-page layouts may require human-in-the-loop validation (paper notes reading order limits)
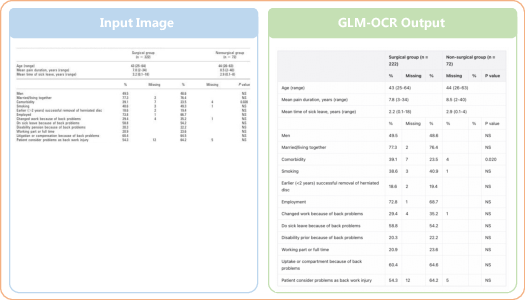
- Table-to-CSV/Spreadsheet microservice for enterprise ETL
- Sectors: BI/Analytics, Manufacturing, Pharma, Energy
- Tools/workflows: Table Recognition prompts → Markdown tables → CSV; automated QA via TEDS score thresholds
- Rationale: High TEDS/TEDS-S; MTP speeds long structured outputs (≈50% decoding throughput gain)
- Assumptions/dependencies: Dense/irregular tables may need guardrails (fallback pipelines, confidence thresholds)
- Code documentation and technical spec ingestion
- Sectors: Software, Hardware, Compliance
- Tools/workflows: SDK to parse code examples in PDFs; extract tables/figures; link code blocks to metadata
- Rationale: Strong in-house performance on code documents; structured parsing to Markdown accelerates content reuse
- Assumptions/dependencies: Consistent rendering of code blocks; discipline-specific fine-tuning improves accuracy
- Seal/stamp detection for business process verification
- Sectors: Government Services, B2B Trade, Compliance
- Tools/workflows: KIE prompts for presence/metadata of seals; routing rules for exception handling
- Rationale: Large margin on seal recognition in in-house tests; useful for authenticity checks and workflow gating
- Assumptions/dependencies: Not a forensic forgery detector; lighting/contrast affect reliability; combine with traditional CV checks for high-stakes decisions
- Customs, logistics, and trade form extraction
- Sectors: Logistics, Supply Chain, Trade Finance
- Tools/workflows: Schema-driven KIE on customs declarations; JSON export to TMS/ERP; field-level F1 reward aligns to schema fidelity
- Rationale: Unifies layout and KIE; multilingual support and strong structured validation
- Assumptions/dependencies: Template drift across jurisdictions; low-resource languages may need finetuning
Healthcare and Scientific Publishing
- Clinical report and lab result digitization
- Sectors: Healthcare, Diagnostics
- Tools/workflows: Table extraction to HL7/FHIR-compatible JSON; privacy-preserving local inference via Ollama/SGLang on hospital hardware
- Rationale: Strong table parsing; compact model suits on-prem deployment; structured RL improves output validity
- Assumptions/dependencies: PHI handling and regulatory compliance; domain-specific fine-tuning recommended
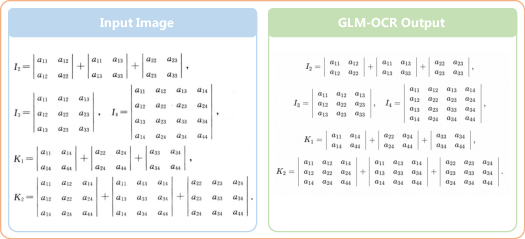
- Formula-to-LaTeX transcription and equation-aware search indexing
- Sectors: Academia, Publishing, EdTech
- Tools/workflows: Formula Recognition prompts; LaTeX export into search indexes and authoring tools
- Rationale: High UniMERNet/CDM performance; valid LaTeX reduces manual post-editing
- Assumptions/dependencies: Very complex 2D constructs may need QA; low-res scans degrade accuracy
- PDF-to-Markdown production workflows for journals and archives
- Sectors: Publishing, Libraries, Reproducibility
- Tools/workflows: SDK pipeline to produce Markdown/JSON; post-process to XML/TEI; batch MaaS processing for backfiles
- Rationale: Throughput/cost (0.2 RMB per million tokens) enables large-scale conversion
- Assumptions/dependencies: Cost estimates depend on tokens/page; reading order errors in atypical layouts
Government and Policy
- Digitization of public records and FOIA responses
- Sectors: Government, Public Records
- Tools/workflows: On-prem parsing to Markdown/JSON; searchable repositories; human validation lane for edge cases
- Rationale: Compact 0.9B model supports edge environments; scalable parallel region recognition
- Assumptions/dependencies: Records quality varies; multilingual forms may require incremental fine-tuning
- Regulatory reporting ingestion (financial, environmental, safety)
- Sectors: Finance, Energy, Transportation
- Tools/workflows: KIE prompts mapped to reporting schemas; validation via structural rewards; audit trail of edits
- Rationale: Structured extraction + schema validation reduces manual data entry and errors
- Assumptions/dependencies: Evolving schemas; need governance and traceability
Daily Life and SMBs
- Mobile scanning for receipts, invoices, and worksheets
- Sectors: Personal finance, SMB bookkeeping, Education
- Tools/workflows: On-device or lightweight server inference; automatic CSV export; math homework LaTeX capture
- Rationale: Edge-friendly size; strong KIE and formula transcription
- Assumptions/dependencies: Camera quality; privacy settings; multilingual text diversity
- Multilingual signage/menu transcription and translation pre-processing
- Sectors: Travel, Hospitality, Accessibility
- Tools/workflows: Text Recognition mode → text handed to MT systems; preserves line structure and currency symbols
- Rationale: In-house multilingual text strength; robust to moderate noise
- Assumptions/dependencies: Underrepresented languages may need targeted tuning; perspective distortions impact accuracy
Long-Term Applications
These opportunities are enabled by the paper’s methods but require further research, scaling, or integration work (e.g., harder layouts, cross-page semantics, forensic validation, broader language coverage).
Industry and Enterprise
- End-to-end “DocOps” agents that read, extract, validate, and act
- Sectors: Finance, Insurance, Manufacturing
- Tools/workflows: GLM-OCR + rule engines + LLM planners; auto-triage exceptions; integrate with RPA and knowledge graphs
- Dependencies: More robust cross-page reading order; confidence estimation; human-in-the-loop governance
- Semantic table understanding and analytics beyond structure
- Sectors: BI/Analytics, Pharma, Scientific R&D
- Tools/workflows: Table structure + semantic type inference; unit detection; metadata linking
- Dependencies: Additional supervision for semantics; domain ontologies
- Document provenance, seal authenticity, and anti-fraud
- Sectors: Compliance, Trade Finance, Government
- Tools/workflows: Seal detection fused with forensic CV, cryptographic provenance (e.g., C2PA); anomaly detection
- Dependencies: Ground-truth datasets for forgery; legal standards
Healthcare and Scientific Publishing
- Large-scale scientific knowledge graphs from PDFs (text + tables + formulas)
- Sectors: Academia, Pharma Discovery
- Tools/workflows: Unified parsing → entity/relation extraction → graph stores; formula-aware indexing and reasoning
- Dependencies: High-precision entity linking; cross-document deduplication; long-document and cross-page modeling
- Clinical decision support via structured OCR + LLM reasoning
- Sectors: Healthcare
- Tools/workflows: OCR → KIE → guideline-constrained reasoning; alerting/triage
- Dependencies: Clinical validation, safety; on-prem deployment; bias controls
Government and Policy
- National-scale digitization platforms with standardized machine-readable submissions
- Sectors: Public Sector, Standards Bodies
- Tools/workflows: Mandate Markdown/JSON deliverables; validation pipelines using structural RL objectives
- Dependencies: Policy adoption; accessibility and multilingual equity; vendor ecosystem support
- Automated compliance auditing across heterogenous filings
- Sectors: Finance, Energy, Transportation
- Tools/workflows: OCR→KIE→rule-based/ML auditing; report generation
- Dependencies: High recall on edge-case layouts; evolving regulations; explainability requirements
Daily Life and Edge/Embedded
- Real-time AR assistance: read, structure, and summarize documents in-view
- Sectors: Accessibility, Field Service, Education
- Tools/workflows: On-device GLM-OCR variants optimized for NPUs; streaming MTP decoding
- Dependencies: Further model compression/distillation; low-latency camera pipelines
- Privacy-preserving on-device personal document vaults
- Sectors: Consumer, SMB
- Tools/workflows: Secure local parsing to structured formats; offline search; client-side fine-tuning for personal templates
- Dependencies: Robust CPU/NPU performance; incremental learning without data leakage
- Robotics and warehouse operations: label, checklist, and manifest reading
- Sectors: Robotics, Logistics
- Tools/workflows: OCR + KIE on industrial labels and forms; exception routing
- Dependencies: Extreme lighting/angle robustness; domain adaptation for symbologies and low-res prints
Cross-Cutting Enablers and Caveats
- Enablers drawn from the paper
- Multi-Token Prediction (MTP): Improves throughput and structural coherence; especially valuable for long tables and JSON
- Two-stage layout→region pipeline: Reduces hallucinations, supports parallelism, and improves robustness
- Structured RL rewards: JSON validity, TEDS/CDM alignment minimize malformed outputs
- Deployment stack: vLLM/SGLang/Ollama for local/edge; MaaS API with ultra-low token pricing; LLaMA-Factory fine-tuning
- Key assumptions/dependencies impacting feasibility
- Input quality: Very low resolution, harsh distortions, and rare scripts degrade accuracy
- Layout limits: Cross-page dependencies and complex reading orders can cause errors; consider human review lanes
- Schema clarity: KIE relies on explicit, unambiguous JSON schemas and high-quality prompts
- Language/domain coverage: Underrepresented languages and niche forms benefit from fine-tuning and curated datasets
- Privacy and compliance: Sensitive documents may require on-prem/edge deployment and auditability
- Cost/throughput claims: Token-based pricing depends on tokens/page; performance varies by hardware and concurrency
- Forensic needs: Seal recognition ≠ anti-forgery; combine with dedicated verification for high-stakes use
This mapping reflects what can be deployed today with GLM-OCR’s released artifacts and where its methods naturally extend to longer-horizon, higher-integration solutions.
Glossary
- Autoregressive decoding: A decoding strategy that generates one token at a time conditioned on previous tokens, which can be accurate but slow for long sequences. "To address the inefficiency of standard autoregressive decoding in deterministic OCR tasks"
- Auxiliary heads: Additional prediction heads attached to a model to forecast multiple future tokens or objectives in parallel. "we attach shared-parameter auxiliary heads that simultaneously predict the next tokens."
- CDM score: A metric for evaluating mathematical formula recognition accuracy. "CDM score"
- CLIP: Contrastive Language-Image Pretraining, a method that aligns images and text via contrastive objectives. "The training incorporates a dual objective of MIM and CLIP tasks."
- CogViT: A vision transformer-based visual encoder used to extract high-level representations from document images. "a 0.4B-parameter CogViT visual encoder"
- Cross-modal connector: A projection module that maps visual features into the language embedding space for joint processing. "a lightweight cross-modal connector"
- Draft models: Auxiliary predictor modules used in multi-token prediction to propose several future tokens while sharing parameters. "a parameter-sharing scheme across the draft models"
- Edge deployment: Running models on resource-limited edge devices rather than cloud/datacenter environments. "resource-constrained edge deployment"
- Field-level F1 score: An accuracy metric computing precision/recall per field in information extraction tasks. "Field-level F1 score"
- Grounding: Linking textual concepts to specific regions or elements within an image. "Image-text pairs, Grounding / Retrieval data"
- GRPO: A reinforcement learning algorithm that optimizes generation using graded or relative rewards. "The final stage applies GRPO~\cite{shao2024deepseekmath}"
- Hallucinations: Model outputs that invent content not supported by the input, a common generative failure mode. "susceptible to hallucinations and repetitive generation"
- JSON parse validation: A structural check ensuring generated JSON is syntactically valid and machine-parsable. "JSON parse validation"
- Key Information Extraction (KIE): Extracting predefined structured fields from documents based on visual inputs and prompts. "Key Information Extraction (KIE)"
- Knowledge distillation: Training a smaller model to imitate a larger teacher model’s behavior to improve performance. "we employ knowledge distillation from an in-house ViT"
- Layout analysis: Detecting and segmenting structural regions (e.g., paragraphs, tables) in a document prior to recognition. "PP-DocLayout-V3 first performs layout analysis"
- Layout cropping: Cropping a document image into detected regions for targeted recognition. "this task does not rely on explicit layout cropping"
- LLM Decoder: The autoregressive language modeling component that generates text conditioned on visual embeddings and prompts. "LLM Decoder (GLM, 500M parameters)"
- MaaS (Model-as-a-Service): A hosted API paradigm that provides model inference as a cloud service. "Model-as-a-Service (MaaS) API"
- Masked Image Modeling (MIM): A self-supervised objective where masked image patches are predicted to learn visual representations. "a dual objective of MIM and CLIP tasks"
- Multimodal LLMs (MLLMs): Models that jointly process and reason over images and text in a unified framework. "Recent multimodal LLMs (MLLMs)"
- Multi-Token Prediction (MTP): A mechanism that predicts multiple future tokens per decoding step to improve efficiency and planning. "Multi-Token Prediction (MTP)"
- Normalized Edit Distance: A sequence similarity metric normalized by length, commonly used to score OCR transcription accuracy. "Normalized Edit Distance"
- Ollama: A deployment framework for running and serving LLMs efficiently on local machines. "Ollama"
- OmniDocBench: A benchmark suite for evaluating document parsing across diverse PDF documents and metrics. "OmniDocBench v1.5"
- Parameter sharing: Reusing the same weights across multiple components to reduce memory overhead and improve efficiency. "a parameter-sharing scheme"
- PP-DocLayout-V3: A layout detection module that identifies structured regions to enable parallel recognition. "PP-DocLayout-V3 first performs layout analysis"
- Prefix tokens: Tokens prepended to the decoder input that condition generation on auxiliary signals like visual embeddings. "fed into the decoder as prefix tokens"
- Reading order: The logical sequence in which document content should be read, used as an evaluation dimension. "Reading Order"
- Reinforcement Learning (RL): An optimization paradigm where models learn by maximizing rewards derived from feedback signals. "Stage 4: Reinforcement Learning (RL)."
- Reward function: The task-aware function that provides scalar feedback signals to guide RL optimization. "The reward function is task-aware"
- SDK: A software development kit offering APIs and tools to integrate end-to-end document parsing workflows. "a comprehensive SDK is provided"
- SGLang: An inference serving framework optimized for efficient LLM/VLM deployment. "SGLang"
- Structured generation: Constrained text generation that must adhere to formats or schemas (e.g., JSON, Markdown). "structured generation"
- Table structure recovery: Reconstructing a table’s rows, columns, and headers from images. "table structure recovery"
- Tag closure verification: A validation step ensuring all markup tags in generated outputs are properly opened and closed. "Tag closure verification"
- TEDS score: Table Tree Edit Distance-based Similarity, a metric for evaluating the fidelity of reconstructed table structures. "TEDS score"
- Throughput: The amount of work (e.g., tokens or pages) processed per unit time during inference. "improving decoding throughput"
- vLLM: A high-throughput inference engine for serving LLMs efficiently. "vLLM"
- Vision Transformer (ViT): A transformer architecture for images that uses patch embeddings and self-attention. "Vision Transformer (ViT)"
- Visual Question Answering (VQA): A task where models answer natural-language questions about images. "VQA"
- Visual-text alignment: Learning correspondences between visual features and textual tokens or concepts. "(i) robust visual-text alignment"
Collections
Sign up for free to add this paper to one or more collections.