Beyond Language Modeling: An Exploration of Multimodal Pretraining
This presentation examines groundbreaking research that challenges the conventional wisdom of multimodal AI development. By conducting systematic from-scratch pretraining experiments, the authors demonstrate that vision and language can be unified within a single model without mutual degradation. The work reveals surprising findings about visual representations, data synergies, emergent world modeling capabilities, and the critical role of sparse architectures in harmonizing the asymmetric scaling demands of different modalities.Script
Most AI systems treat vision and language as incompatible partners, requiring separate architectures and careful isolation. But what if that entire premise is wrong?
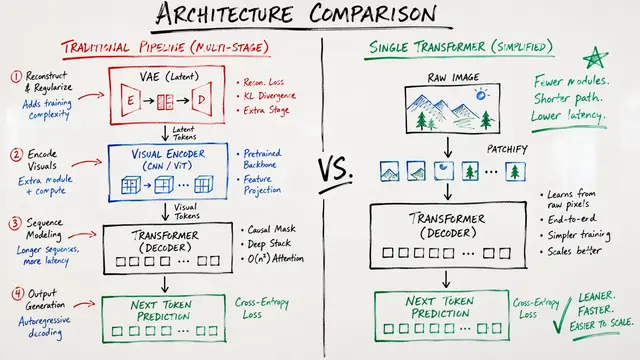
The researchers rejected the standard approach of adapting language models for vision. Instead, they built unified models from the ground up, systematically testing every assumption about how modalities should interact.
Their first discovery upends a core belief about visual AI.
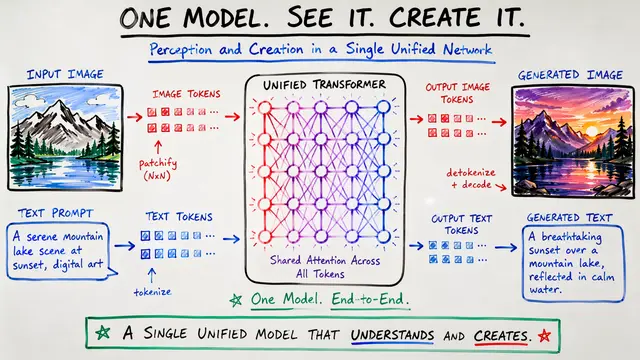
For years, the field assumed visual understanding and generation required separate representations—semantic encoders for one, VAE latents for the other. The data tells a different story. Representation autoencoders like SigLIP 2 excel at both generation quality on DPGBench and GenEval, and visual question answering accuracy, all while preserving text perplexity. The architectural split was never necessary.
The experiments reveal profound synergy, not competition. Adding video to language training maintains text quality while enabling visual capabilities. More striking: general multimodal pretraining transfers so effectively that world modeling for navigation requires only 1% specialized trajectory data. The model even achieves zero-shot controllability, generating navigation sequences from natural language commands without architectural modifications.
Sparse architectures solve the fundamental asymmetry problem: vision demands far more data than language at scale. Mixture of Experts models decouple total parameters from active compute, letting each modality scale according to its own laws. Remarkably, the experts themselves blur task boundaries—generation and understanding activate nearly identical expert sets, further evidence that architectural separation is a vestige, not a necessity.
This work proves that unified multimodal models aren't just possible—they're superior. The path to AI that truly understands and generates across modalities doesn't require isolation; it requires the right representations, data synergies, and adaptive architectures. Visit EmergentMind.com to explore this research further and create your own videos.