Is One Layer Enough? Training A Single Transformer Layer Can Match Full-Parameter RL Training
Abstract: Reinforcement learning (RL) has become a central component of post-training LLMs, yet little is understood about how RL adaptation is distributed across transformer layers. Existing approaches typically update all model parameters uniformly, implicitly assuming that every layer contributes similarly to the gains obtained during RL post-training. In this work, we challenge this assumption through a systematic layer-wise study of RL training. Surprisingly, we find that training a single transformer layer can recover most of the gains achieved by full-parameter RL training, and in some cases even surpass it. To quantify this phenomenon, we introduce the quantity layer contribution, which measures the fraction of full RL improvement recovered by training a layer in isolation. Across seven models spanning two model families (Qwen3, Qwen2.5), three RL algorithms (GRPO, GiGPO, Dr. GRPO), and multiple task domains including mathematical reasoning, code generation, and agentic decision-making, we observe a remarkably stable pattern: RL gains are highly concentrated in a small subset of, and in many cases even a single, transformer layers. More strikingly, the same structural pattern consistently emerges: high-contribution layers concentrate in the middle of the transformer stack, while layers near the input and output ends contribute substantially less. The resulting layer rankings remain strongly correlated across datasets, tasks, model families, and RL algorithms.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple but surprising question: when you use reinforcement learning (RL) to improve a LLM, do you really need to update all of its parts? The authors show that, in many cases, training just one layer (one “floor” in the model’s stack) can recover most of the improvement you’d get from training the entire model—and sometimes even do better.
What the researchers wanted to find out
They focused on a few big questions:
- Do all layers of a transformer help equally when you train with RL, or are some layers much more important?
- Is it possible that training only one layer can match (or beat) training every layer at once?
- Are the “most important” layers the same across different models, tasks (like math, coding, or interactive decision-making), and training methods?
- Can we use this knowledge to train models faster, cheaper, or more effectively?
How they studied it (in everyday terms)
Think of a transformer model like a tall building with many floors (layers). Normally, RL post-training tries to renovate every floor at once. The authors did something different:
- They “froze” the entire building except for one floor (they locked all floors so they couldn’t change) and renovated just that single floor using RL. They repeated this for each floor, one at a time.
- After each single-floor renovation, they checked how much the whole building’s performance improved on tests (math problems, coding tasks, or agent tasks).
- They compared each single-floor improvement to the improvement you get when you renovate the whole building at once.
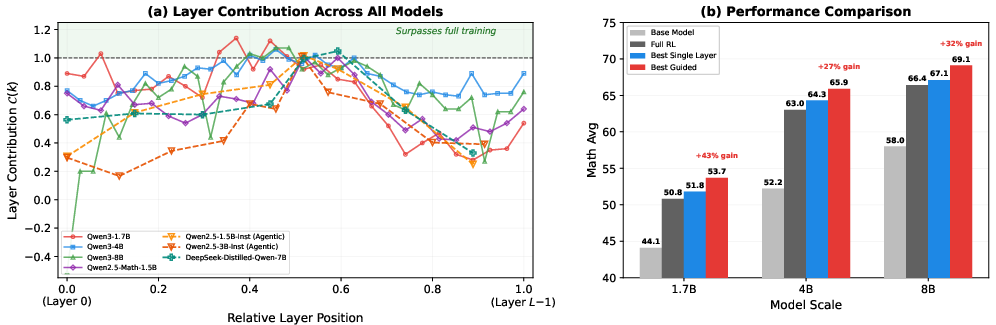
They created a simple score called “layer contribution.” It answers: “What fraction of the full improvement do we get by training only this one layer?” For example, if full training raises a score from 40 to 60 (+20), and training only Layer 12 raises it from 40 to 58 (+18), Layer 12’s contribution is 18/20 = 0.9 (90%).
They didn’t just try this on one model or one dataset. They ran this test across:
- Different model families and sizes (like Qwen3 and Qwen2.5, from ~1.5B to 8B parameters)
- Different RL methods (GRPO, GiGPO, Dr. GRPO)
- Different tasks (mathematical reasoning, code generation, and agentic decision-making in environments)
What they discovered and why it matters
The main findings are striking and very consistent:
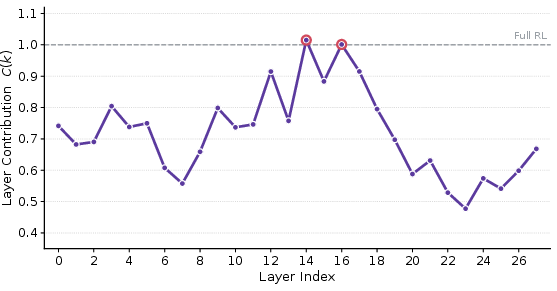
- Most of the RL improvement comes from a few layers, often just one. In many runs, training a single layer recovered most of the gains you’d get from training all layers—and sometimes even surpassed the full training result.
- The most helpful layers are usually in the middle of the model. Layers near the very beginning (close to the input) and the very end (close to the output) usually helped less. In some cases, training certain early layers even made things worse.
- This pattern holds across models, tasks, and RL methods. Whether the model was doing math, writing code, or making decisions in a simulated environment, the “middle layers matter most” pattern appeared again and again.
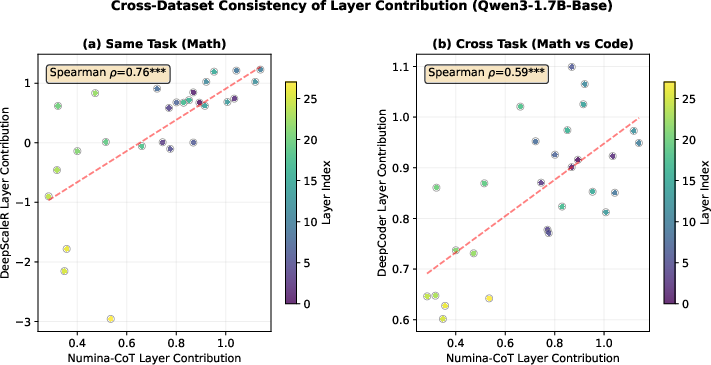
- Important layers stay important even when the dataset changes. The ranking of which layers help the most stayed similar across different datasets and tasks, showing this is a stable property of the model, not a fluke of one dataset.
- Single-layer training also boosted skills beyond the training target. For example, training on math didn’t just help with math—it often improved coding or general reasoning too. This suggests the changes weren’t just overfitting.
Why this is important:
- It challenges a common assumption that every layer contributes equally during RL post-training.
- It shows that smarter, layer-aware training can be more effective—and possibly cheaper—than training everything uniformly.
What this could change in practice
The authors turned these insights into simple training strategies:
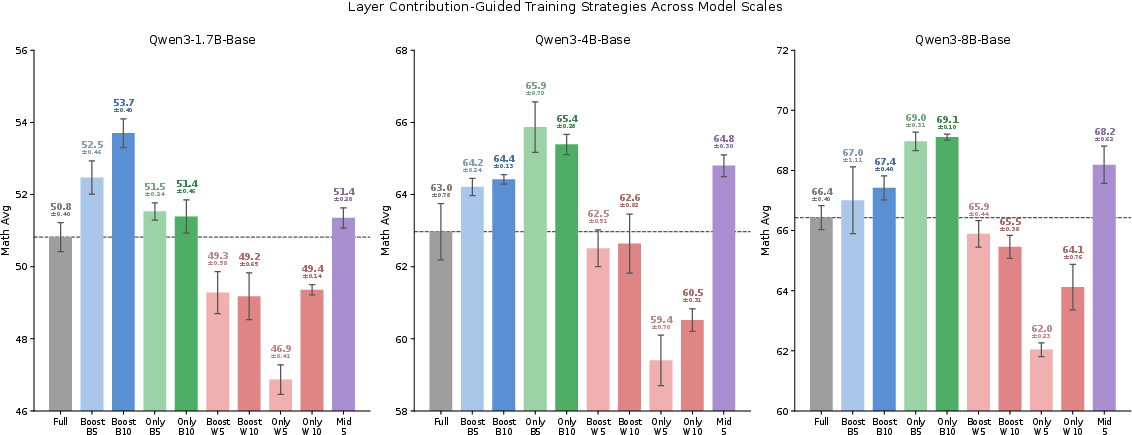
- Focus on the best layers. Give higher learning rates to the high-contribution layers or train only those layers. This consistently beat the standard approach of training every layer the same way.
- Use a quick heuristic: train the middle layers. Even without measuring contributions first, just training middle layers often matched or beat full-parameter training.
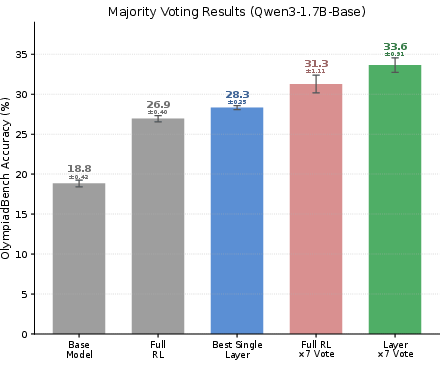
- Combine specialized models. Models trained on different single layers learned slightly different strengths, so combining their answers (like a vote) gave extra gains.
Big picture: This work suggests a new, more efficient way to post-train LLMs with RL. Instead of treating all layers the same, we can concentrate effort where it counts most—the middle layers—saving time and compute while getting equal or better results. It also gives researchers a clearer picture of “where the learning happens” inside these models, which could lead to better model designs and training methods in the future.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues that future work could address to deepen understanding and broaden the applicability of the paper’s findings.
- Scaling to larger and different architectures:
- Do the “single-layer suffices” and “middle-layer concentration” findings hold for larger models (e.g., 14B, 34B, 70B+), mixture-of-experts (MoE), encoder–decoder architectures, and alternative backbones (e.g., RWKV, Mamba, multimodal models)?
- Broader RL settings:
- Does the phenomenon persist under reward-model-based RLHF, off-policy RL, and algorithms with learned critics (e.g., PPO with value networks), or under alternative post-training objectives (DPO/KTO-style preference optimization rather than verifiable-reward RLVR)?
- Task generality beyond those studied:
- Are single-layer effects and middle-layer dominance robust for instruction-following, safety alignment, tool use, long-context reasoning, retrieval-augmented tasks, dialog, multilingual tasks, and multimodal RL?
- Mechanistic explanation:
- Why do middle layers dominate? Which subcomponents (self-attention vs MLP; specific heads; gating) within high-contribution layers actually absorb RL changes? Are there identifiable circuits or representational shifts that explain the concentration?
- Additivity and interaction among layers:
- Are layer contributions additive or do they exhibit interference/synergy when training multiple high-contribution layers jointly? How do gains scale as top-k layers are added, and are there diminishing returns or antagonistic interactions?
- Dynamics over training:
- How do layer-contribution profiles evolve during training (early vs late phases)? Do the “best layers” remain best as learning progresses, or do rankings shift over time?
- Post-adaptation stability of rankings:
- After training top layers, if the model is profiled again, do the same layers remain high-contribution (i.e., are rankings invariant to prior adaptation), or does credit assignment migrate?
- Robustness across seeds and hyperparameters:
- The paper provides limited seed averaging and mainly examines learning rate. How robust are contribution rankings to changes in batch size, KL coefficient, clip range, sampling temperature, group size, optimizer, and other RL hyperparameters?
- Sensitivity of the contribution metric:
- The layer contribution normalizes by (S_full − S_base). When full-parameter gains are small or negative, this metric can be unstable or misleading. How do conclusions change under alternative normalizations (e.g., absolute gains, bootstrapped confidence intervals, or per-benchmark normalization)?
- Computation and efficiency characterization:
- What are the actual wall-clock/compute/memory savings of single-layer and top-k-layer training vs full-parameter RL? Does single-layer training converge faster or slower to the same gains, and is sample efficiency improved?
- Generality of “position-only” heuristics:
- The paper shows a middle-layer heuristic can work, but how often does a position-only rule reliably approach the performance of a full layer scan across architectures, tasks, and scales?
- Predictors of high-contribution layers without scans:
- Can we develop scan-free proxies (e.g., per-layer gradient norms at initialization, Fisher information, logit/feature sensitivity, NTK diagnostics, probing/CCA similarity) to identify high-contribution layers prior to or during training?
- Sub-layer and parameter-efficient granularity:
- Could updating only specific submodules (e.g., attention vs MLP, specific heads, K/V projections) or applying LoRA/adapters within a single high-contribution layer match/surpass the full-layer update? What is the minimal parameter budget needed?
- Role of embeddings and LM head:
- The study freezes embeddings and the LM head. How much gain can be achieved by updating only the head or embeddings? Do conclusions about middle-layer dominance change if head/embedding are allowed to adapt?
- Boundary conditions and failure cases:
- For which datasets or tasks do early or late layers become dominant (if any)? Under what conditions do single-layer updates produce negative contributions (e.g., Layer 0 on Qwen3-8B), and why?
- Safety and alignment side effects:
- Does concentrating updates in a single layer increase risks of reward hacking, degraded safety guardrails, or undesirable behaviors on adversarial prompts? Are safety and toxicity metrics affected differently across layers?
- Out-of-distribution and generalization breadth:
- While some OOD categories are reported, a deeper analysis is needed: how do single-layer updates affect robustness to distribution shifts, adversarial inputs, prompt styles, and multilingual/broad-domain generalization?
- Interaction with KL regularization and reference policies:
- How does the KL strength and choice of reference policy (base vs instruct-tuned) modulate which layers contribute most? Do different KL regimes shift the contribution profile?
- Ensemble analysis depth:
- The paper shows complementary behaviors qualitatively via majority voting. What is the measured diversity among layer-specialized models (e.g., error overlap, mutual information), and do more sophisticated ensembling methods (logit/score fusion, self-consistency) yield larger gains?
- Continual and multi-task RL:
- Can different layers be specialized to different tasks without catastrophic interference? How does sequentially training different layers for different tasks affect cross-task transfer and overall capability?
- Long-context and memory mechanisms:
- Do layer-contribution profiles change with very long contexts, memory-augmented setups, or during tasks that heavily rely on positional/rotary embeddings and long-range attention?
- Theoretical grounding:
- Can we formalize why middle layers dominate RL adaptation (e.g., via representational hierarchy, information bottlenecks, linearization/NTK analyses, or depth-wise capacity allocation theories)?
- Full-layer scans for partially profiled models:
- For models where only a subset of layers were scanned (e.g., agentic and distilled settings), do full scans affirm the same top-layer identities, or are we missing atypical high-contribution layers outside the sampled subset?
- Cross-lingual and cross-domain transfer:
- Are the same high-contribution layers stable across languages and domains (e.g., legal/medical/scientific text)? Does the ranking transfer across fundamentally different distributions?
- Reproducibility and variance reporting:
- More comprehensive reporting of run-to-run variance and statistical significance for per-layer results (not only guided strategies) is needed to quantify confidence in rankings and small differences that decide “top-k” layer selections.
Practical Applications
Overview
This paper shows that, during reinforcement learning (RL) post-training of LLMs, most gains concentrate in a small subset of transformer layers—often a single middle layer can match or surpass full-parameter RL. The authors introduce a “layer contribution” metric to rank layers, and demonstrate robust, cross-model, cross-task patterns. They also propose layer-aware strategies (e.g., per-layer learning rates, training only high-contribution layers, ensembles of layer-specialized models) that consistently outperform standard full-parameter RL.
Below are actionable applications grouped by deployment horizon, with sector links, possible tools/workflows, and key assumptions/dependencies.
Immediate Applications
These are deployable now with current open-source stacks (e.g., PyTorch, Hugging Face, TRL), modest engineering, and available compute.
- Layer-aware RL post-training to cut cost and time
- Sectors: software/AI platforms, cloud, startups, academia
- What: Train only the highest-contribution (middle) layers or assign them higher learning rates; freeze others. Expect comparable or better performance than full-parameter RL with lower compute and memory.
- Tools/workflows:
- Add per-layer LR schedules and trainable masks in TRL/PEFT pipelines.
- Provide a “middle-layer-only RL” switch and a “top-k layer” selector.
- Assumptions/dependencies:
- Findings are shown on Qwen2.5/Qwen3 and DeepSeek-distilled models (1.5B–8B); generalization to all model families/sizes should be validated per case.
- Works best with RLVR-style verifiable rewards and GRPO-family algorithms.
- Rapid A/B testing via single-layer RL trials
- Sectors: applied research, MLOps, product teams
- What: Run quick experiments by training one middle layer to gauge potential RL gains before committing to full runs; iterate hyperparameters faster.
- Tools/workflows:
- Automated script to scan 3–5 mid layers on a small dataset; pick the best layer(s) for full training.
- Assumptions/dependencies:
- Layer rankings transfer across datasets/tasks but still benefit from a small in-house scan.
- Parameter-efficient customer fine-tunes for multi-tenant SaaS
- Sectors: enterprise software, AI platforms
- What: Provide per-customer RL “layer packs” (diffs for a few layers) instead of whole-model forks. Reduces storage, deployment complexity, and update friction.
- Tools/products:
- Registry for “RL layer packs” with versioning and dependency metadata.
- Runtime for swapping layer weights per tenant.
- Assumptions/dependencies:
- Serving stack must support dynamic loading of specific layer weights.
- Careful isolation to avoid cross-tenant leakage.
- On-device and low-resource RL adaptation
- Sectors: edge AI, mobile, embedded
- What: Adapt models by updating only one or a few layers to fit memory/compute budgets of consumer GPUs or edge devices.
- Tools/workflows:
- Freeze-all-but-k-layers training templates; optimizer state limited to selected layers.
- Assumptions/dependencies:
- Backprop still traverses the full model; memory savings come from reduced gradient/optimizer state, not elimination of forward compute.
- Ensemble of layer-specialized models for robust performance
- Sectors: software/AI products, safety-critical applications
- What: Train multiple models with different high-contribution layers; combine via majority voting or logit averaging to capture complementary behavior and surpass full-parameter baselines.
- Tools/workflows:
- Inference-time ensembling service with lightweight aggregation; caching to control latency.
- Assumptions/dependencies:
- Higher inference cost; may need routing (use ensemble only for hard queries).
- Safer/steadier RL updates by restricting adaptation scope
- Sectors: safety, governance, regulated industries (healthcare, finance, public sector)
- What: Reduce catastrophic forgetting or unintended shifts by constraining RL updates to mid layers known to carry most adaptation.
- Tools/workflows:
- Guardrails that cap trainable parameters to selected layers; capability regression checks focused on early/late layers.
- Assumptions/dependencies:
- Not a substitute for full safety auditing; risk still exists and must be evaluated.
- Task-specific modularity and hot-swapping for agents
- Sectors: robotics, agentic systems, operations automation
- What: Maintain a library of mid-layer modules specialized via RL for different tasks/domains; swap modules at runtime for context-appropriate behavior.
- Tools/products:
- “Skill-layer” repository; routing logic that loads task-appropriate layer modules.
- Assumptions/dependencies:
- Empirically validated transfer across tasks (math, code, ALFWorld) is promising; domain shifts still require checks.
- Monitoring and quality assurance focused on high-contribution layers
- Sectors: MLOps, compliance
- What: Track parameter norm changes and gradients primarily on mid layers that drive RL gains; detect drift early.
- Tools/workflows:
- Layer-focused telemetry; alarms on abnormal dynamics in dominant layers.
- Assumptions/dependencies:
- Complement with output-level evaluation for full assurance.
- Energy/carbon reduction for RL post-training
- Sectors: cloud/compute, sustainability reporting
- What: Reduce compute and optimizer state for RL by training only top-k layers; report lower energy/carbon KPIs.
- Tools/workflows:
- Job profiles that toggle “layer-limited RL mode”; automated carbon accounting integrated with scheduling.
- Assumptions/dependencies:
- Actual savings depend on framework’s ability to avoid storing grads/optimizer state for frozen layers and to optimize backward graphs.
- Education and academic curricula focusing on layer-wise analysis
- Sectors: education, research labs
- What: Teach and standardize the “layer contribution” metric and middle-layer heuristics in coursework and lab practices.
- Tools/workflows:
- Public labs that reproduce single-layer RL runs on small models/datasets; benchmarking kits.
- Assumptions/dependencies:
- Requires datasets with verifiable rewards (e.g., math/coding problems) for quick iteration.
- Vendor/Cloud “RL Efficiency Mode”
- Sectors: cloud providers, ML platforms
- What: Managed training setting that automatically trains only mid/high-contribution layers; exposes cost/speed/quality trade-offs to users.
- Tools/products:
- API flag (e.g., rl_mode="layer-efficient"); built-in profiling or default mid-layer heuristic.
- Assumptions/dependencies:
- Default layer choices may need periodic refresh per model family.
- Open-source checkpoints as “Layer Contribution Maps”
- Sectors: OSS community, research
- What: Release maps ranking layer contributions for popular base models to guide others’ RL runs.
- Tools/workflows:
- Lightweight repos documenting top-k layers and suggested LRs for each model family.
- Assumptions/dependencies:
- Community maintenance required as models/datasets evolve.
Long-Term Applications
These require further research, scaling experiments (e.g., >8B models), or engineering for broader generality and safety.
- AutoProfiler for RL layer selection and adaptive scheduling
- Sectors: AutoML, cloud, enterprise ML
- What: A system that runs minimal pilot RL on a small dataset, infers high-contribution layers, then schedules production RL with per-layer LRs and selective training.
- Dependencies/assumptions:
- Automates cross-dataset transfer while managing exploration cost.
- Needs robust generalization across architectures (e.g., Llama, Mistral, Mixtral, multimodal).
- PEFT–RL hybrids focused on middle layers
- Sectors: software/AI platforms
- What: Combine LoRA/adapters with layer-aware RL to maximize efficiency and modularity (e.g., LoRA only on high-contribution layers).
- Dependencies/assumptions:
- Requires empirical tuning to balance LoRA rank, layer choice, and RL objectives.
- Regulatory/compliance frameworks incentivizing efficient post-training
- Sectors: policy, public sector, sustainability
- What: Standards or best-practice guidelines that prioritize energy-efficient training (e.g., selective-layer RL) in public funding or procurement.
- Dependencies/assumptions:
- Must be technology-agnostic and validated across models to avoid bias.
- Model architecture co-design to emphasize mid-layer adaptability
- Sectors: foundational model R&D
- What: Architectures that intentionally allocate capacity for RL adaptation in mid layers (e.g., larger FFN or attention blocks mid-stack).
- Dependencies/assumptions:
- Requires scaling studies on 30B–70B+ models and cross-modal architectures.
- Skill marketplace for “RL layer modules”
- Sectors: AI marketplaces, enterprise solutions
- What: Exchange for validated, plug-and-play mid-layer RL modules (e.g., math, coding, agenting) with licensing and provenance.
- Dependencies/assumptions:
- Standardization of interfaces, versioning, and IP enforcement; compatibility across base model variants.
- Task-aware router that selects layer-specialized models at inference
- Sectors: production AI, agents
- What: A router that detects query type (math/code/agentic) and picks the best layer-specialized model; uses ensembles selectively for uncertain cases.
- Dependencies/assumptions:
- Low-latency routing and calibration; confidence estimation pipelines.
- Continual and federated learning with limited-layer updates
- Sectors: healthcare, finance, privacy-sensitive domains
- What: Federated RL that updates only specific layers to reduce data leakage risk and model drift; easier aggregation and auditing.
- Dependencies/assumptions:
- Secure aggregation for layer diffs; validation that privacy gains do not harm performance.
- Interpretability and safety interventions targeted at high-contribution layers
- Sectors: AI safety research, regulated industries
- What: Focus mechanistic analyses, red-teaming, and policy interventions on layers that drive RL changes; targeted patching/regularization.
- Dependencies/assumptions:
- Techniques to attribute behavior changes causally to layer updates; scalable interpretability tools.
- Cross-modal and non-text extensions (vision, speech, multimodal agents)
- Sectors: robotics, autonomous systems, media AI
- What: Evaluate whether the same mid-layer concentration holds in multimodal transformers and apply layer-aware RL to reduce training cost.
- Dependencies/assumptions:
- Requires new reward designs and benchmarks with verifiable outcomes.
- Knowledge distillation pipelines that transfer “RL gains” via mid layers
- Sectors: model compression, deployment
- What: Distill only the adapted mid-layer behaviors into smaller students to retain post-training benefits with smaller footprint.
- Dependencies/assumptions:
- Methods to isolate and transfer mid-layer representations without losing upstream/downstream compatibility.
- Risk management for democratized RL fine-tuning
- Sectors: policy, platform governance
- What: As layer-limited RL lowers barriers, governance frameworks to mitigate misuse (e.g., harmful specialization) while enabling beneficial customization.
- Dependencies/assumptions:
- Monitoring, watermarking of layer modules, and use policies.
Notes on Assumptions and Dependencies
- Generalization: Evidence spans Qwen2.5/Qwen3 families and a DeepSeek-distilled model (1.5B–8B), tasks in math, code, and ALFWorld, and GRPO-family algorithms. Validation is still needed for larger models (≥30B), other families (Llama, Mistral, Gemini-like), and non-verifiable preference-optimization settings.
- Compute/Memory: Freezing layers removes optimizer state and gradients for those layers, reducing memory; forward compute remains full. Realized savings depend on framework optimizations and activation checkpointing.
- Layer identification: Full scans are expensive; however, the middle-layer heuristic and small-dataset scans transfer well in reported experiments.
- Performance trade-offs: Ensembling improves quality but increases inference cost; routing or selective ensembling alleviates this.
- Safety: Constraining updates can reduce unintended shifts but does not replace comprehensive safety evaluations.
Glossary
- Agentic tasks: Interactive tasks requiring multi-step decision-making by an autonomous agent. "agentic tasks"
- ALFWorld: A benchmark of household-like, text-based tasks for evaluating embodied/agentic decision-making. "ALFWorld"
- Backpropagation: The gradient-based procedure for computing parameter updates by propagating errors through the network. "computed via backpropagation through the full network"
- Clipped surrogate objective: A PPO-style policy objective that limits the change in policy by clipping the importance ratio to stabilize training. "clipped surrogate objective:"
- DeepCoder: A dataset focused on code generation tasks used to evaluate or train models. "DeepCoder"
- DeepScaleR: A mathematics-focused training dataset for reasoning tasks. "DeepScaleR"
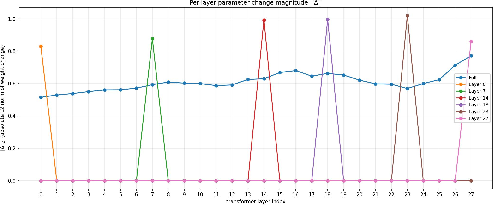
- Depth-normalized relative layer position: A normalized index of a layer’s position in the stack, scaled from 0 (first layer) to 1 (last layer). "depth-normalized relative layer position"
- Dr.~GRPO: A variant of GRPO (Group Relative Policy Optimization) used for RL training of LLMs. "Dr.~GRPO"
- Frozen layers: Model layers whose parameters are held fixed (not updated) during training. "all remaining layers are frozen"
- GiGPO: An RL optimization algorithm for LLMs based on grouped sampling and policy updates. "GiGPO"
- GPQA-Diamond: A challenging science/QA benchmark used for out-of-distribution evaluation. "GPQA-Diamond"
- GRPO: Group Relative Policy Optimization; an RL algorithm that estimates advantages from grouped samples without a value network. "GRPO"
- GSM8K: A benchmark of grade-school math word problems for evaluating math reasoning. "GSM8K"
- Group-normalized advantage: An advantage estimate computed by normalizing rewards within a sampled group of responses. "group-normalized advantage"
- HumanEval+: An evaluation suite for code generation that extends the original HumanEval. "HumanEval+"
- Importance sampling ratio: The ratio between current and reference policies for a sampled action, used to correct off-policy updates. "importance sampling ratio"
- KL coefficient: The weighting factor on a KL-divergence penalty that constrains policy updates during RL. "KL coefficient"
- LLM head: The final projection layer mapping hidden states to token logits in a LLM. "LLM head"
- Layer contribution: The fraction of full RL improvement recovered when only a single layer is trained. "layer contribution"
- Layer-wise heterogeneity: The phenomenon that different transformer layers play different roles or contribute unequally to performance. "layer-wise heterogeneity"
- Learning rate ablation study: An experiment that varies learning rates to assess sensitivity and robustness of observed effects. "learning rate ablation study"
- Majority voting: An ensemble method where multiple models’ outputs are combined by selecting the most common answer. "majority voting"
- MATH500: A subset of math problems used to evaluate mathematical reasoning ability. "MATH500"
- MBPP: Mostly Basic Python Problems; a benchmark for evaluating code synthesis capabilities. "MBPP"
- MMLU-Pro: A more challenging version of the MMLU benchmark for advanced multi-task language understanding. "MMLU-Pro"
- NuminaMath-CoT: A chain-of-thought mathematics training dataset used for RL post-training. "NuminaMath-CoT"
- OlympiadBench: A benchmark of competition-level math problems targeting advanced reasoning. "OlympiadBench"
- Parameter subspace: A subset of the full parameter space (e.g., one layer) within which learning can occur. "parameter subspace of a single layer"
- RLVR (Reinforcement Learning with Verifiable Rewards): An RL setup where rewards are given based on verifiable correctness of model outputs. "Reinforcement Learning with Verifiable Rewards (RLVR)"
- Single-layer training: A procedure where only one transformer layer is updated while others are frozen to isolate its effect. "single-layer training"
- Skywork: An open mathematics reasoning dataset used for training or evaluation. "Skywork"
- Spearman rank correlation coefficient: A nonparametric measure of rank-order correlation used to compare layer rankings across datasets/tasks. "Spearman "
Collections
Sign up for free to add this paper to one or more collections.