- The paper shows that applying RL early in pre-training increases pass@1 from ~2% to ~18%, challenging the standard SFT→RL pipeline.
- It compares direct RL, SFT, and hybrid methods, demonstrating that curated data and a parallel averaging approach enhance both reasoning and general capabilities.
- The study introduces a diagnostic based on base model performance, revealing that RL can expand the solution distribution without sacrificing general skills.
Re-examining Policy Optimization in LLM Training: RL Excursions during Pre-Training
Introduction
This work rigorously scrutinizes the canonical LLM post-training paradigm—namely, the strict sequencing of next-token pre-training, followed by supervised fine-tuning (SFT), and concluded with reinforcement learning (RL). The central contribution is a systematic empirical reevaluation of when and how RL can be efficaciously incorporated into large-scale LLM training, including interventions applied at intermediate pre-training checkpoints. Rather than adhering to the default SFT→RL pipeline, this study interrogates direct RL, SFT variants, and hybrid approaches, discovering that RL can be effective much earlier than is conventional, with nontrivial implications for both model capability and generalization.
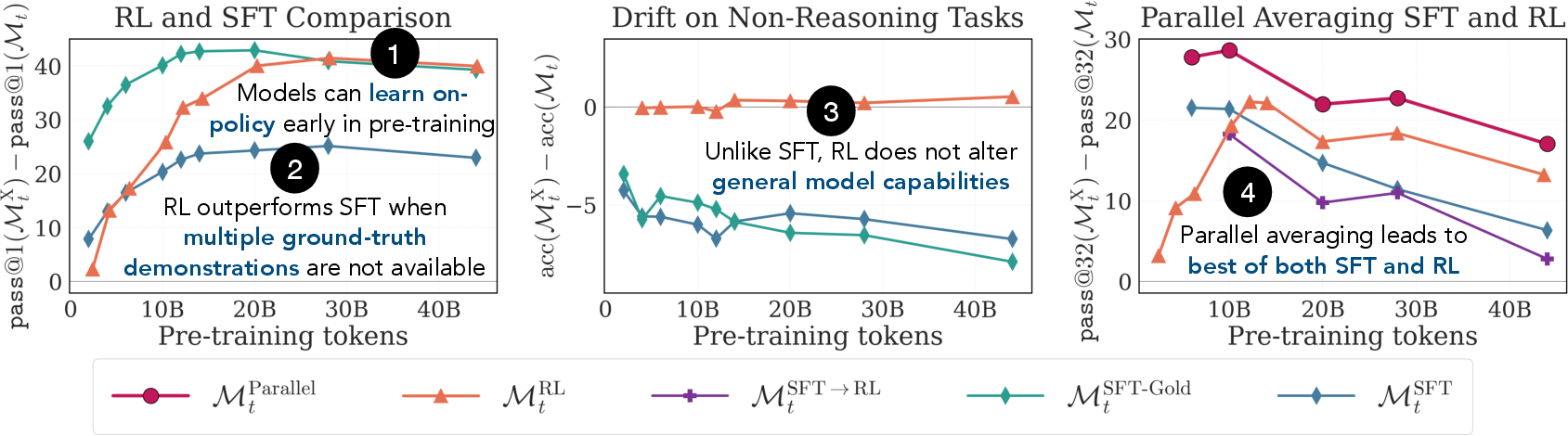
Figure 1: Comparative overview of post-training recipes at pre-training checkpoints, highlighting the early effectiveness of RL and the complementary effects of SFT and RL objectives.
Methodology
The primary experimental protocol leverages a 1B-parameter model custom-pre-trained on a well-curated reasoning-focused corpus (the DOLMino mix), with checkpoints recorded across the full pre-training trajectory (up to 50B tokens). Three key pipelines are compared at intermediate checkpoints:
- Direct RL: On-policy RL (specifically, GRPO for RLVR-style rewards) applied directly to the base checkpoint.
- SFT/SFT-Gold: SFT with one or multiple ground-truth solutions per prompt, respectively.
- SFT→RL: The standard sequential pipeline.
Training and evaluation are focused on the OpenMathInstruct dataset, which mixes GSM8K (grade-school) and MATH (competition-level) problems, supporting control over supervision diversity and problem difficulty.
Early Effectiveness and Competitiveness of RL
Direct RL training delivers substantial improvements over base models even at early pre-training—after as little as 4B tokens on GSM8K, RL increases pass@1 from ~2% to ~18%, with performance saturating or matching SFT→RL by 10B tokens.
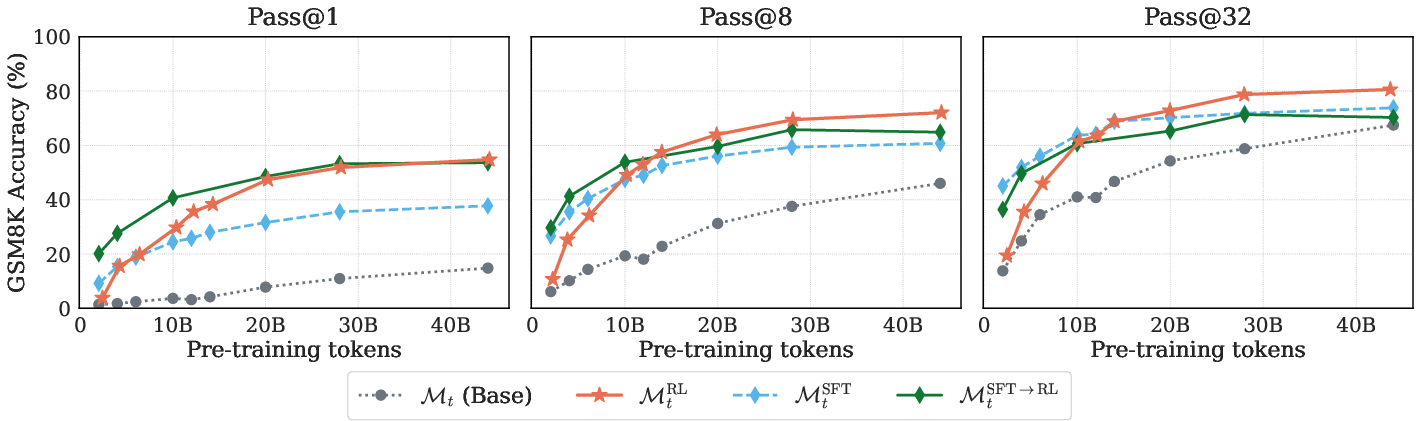
Figure 2: RL delivers robust gains on GSM8K at early pre-training, converging to or surpassing SFT→RL pipelines after only 10B tokens.
When the SFT regime is realistic (using only a single ground-truth demonstration per problem), RL on early checkpoints demonstrates clear superiority in extracting reasoning capability compared to SFT. However, when SFT-Gold is provided—using all ground-truth solutions per problem, which is rare outside synthetic or small datasets—SFT-based methods can outperform RL at high-k metrics (pass@8, pass@32), indicating that diversity in supervised solutions provides coverage not readily achievable by on-policy RL.
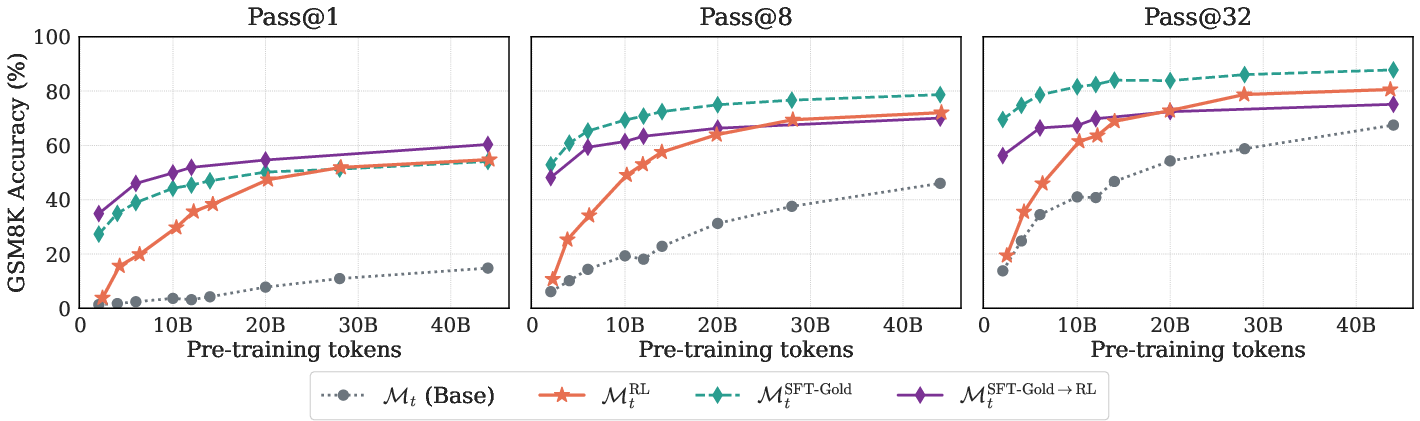
Figure 3: SFT-Gold benefits from diversity—access to many ground-truth solutions enables superior coverage at high-k, but only in the idealized multi-solution regime.
Scaling Laws: Data vs. Model Size
For more challenging tasks (MATH), model capability bottlenecks become pronounced. RL performance gains relative to SFT are highly contingent on pre-training data composition rather than parameter count. Even large (4B) models pretrained on generic data are unable to close the gap to SFT→RL. Instead, augmenting the corpus with targeted, task-relevant math data (scaling the data, not just parameters) robustly boosts RL's impact on MATH, suggesting pre-training data curation is the binding constraint on RL's effectiveness in early and intermediate regimes.
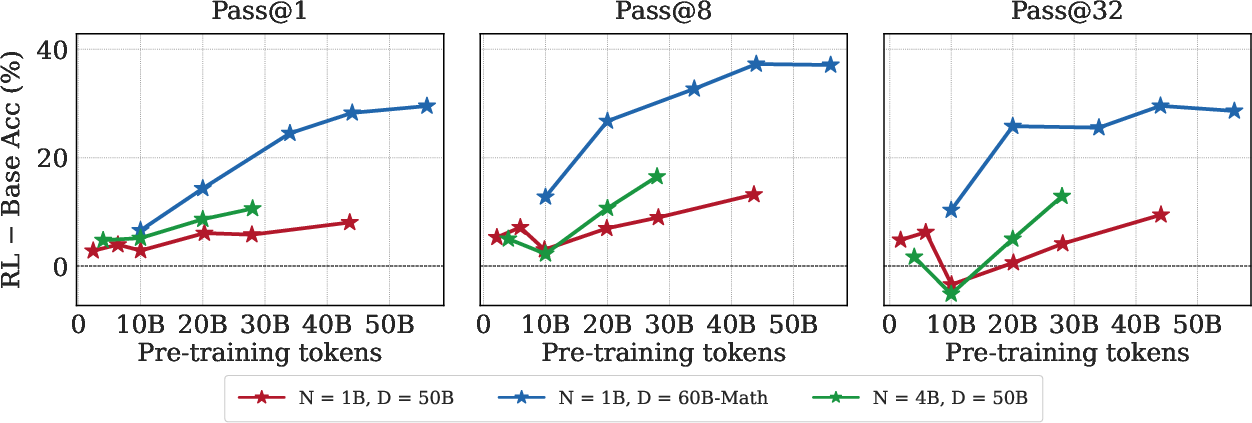
Figure 4: The amount and relevance of pre-training data (not model scalar size) determines RL’s effectiveness on harder mathematical reasoning benchmarks.
Predictive Diagnostics for RL Effectiveness
The base model’s pass@k performance on evaluation data is strongly predictive of attainable RL improvements. This provides a lightweight diagnostic for prioritizing checkpoints most amenable to effective RL post-training.
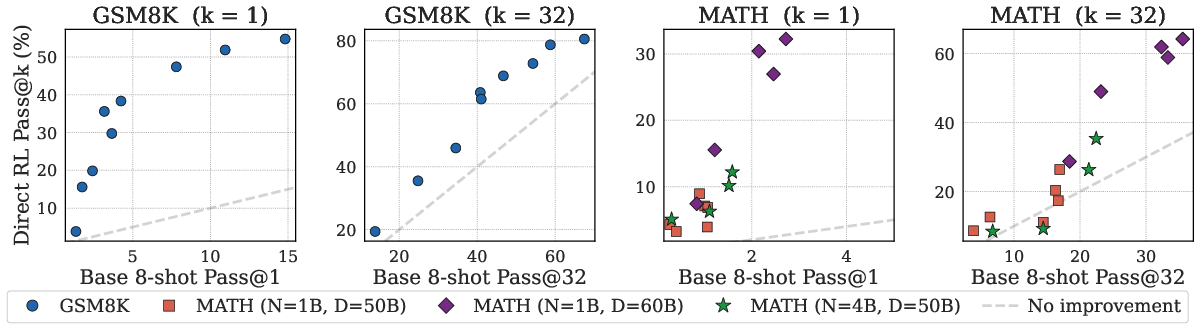
Figure 5: Base model test accuracy is a monotonic predictor of RL gains, enabling checkpoint triage for RL resource allocation.
Distributional Effects: RL Expands, SFT Sharpens
Contrary to prevalent claims that RL simply "sharpens" models (i.e., increases pass@1 but not pass@k for larger k), the results show a nuanced duality. When applied directly to a checkpoint, RL expands the candidate distribution, improving both pass@1 and pass@32. Distribution sharpening (where pass@k stagnates or decreases for larger k) emerges sharply only when RL follows SFT—attributable not to RL, but to the prior SFT regime constraining exploration.
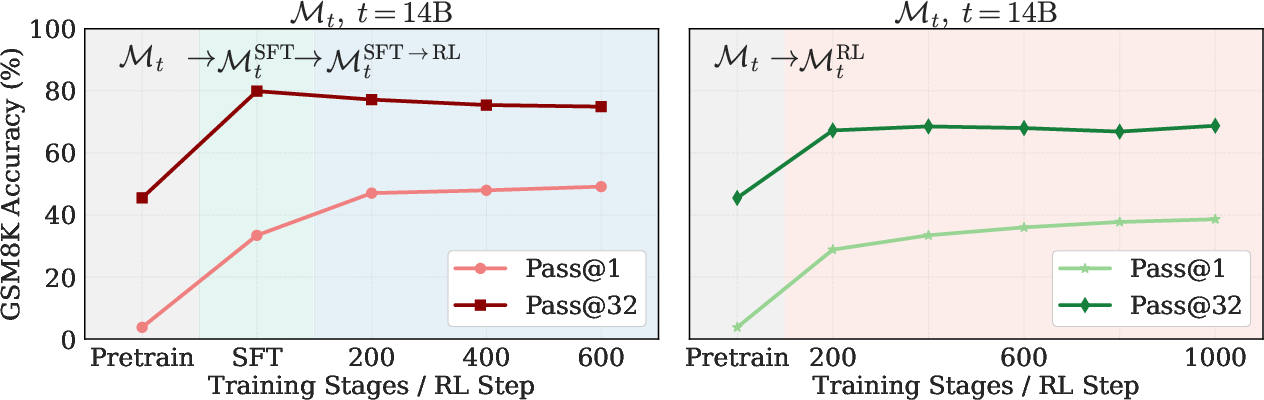
Figure 6: RL directly on the base model expands the solution distribution; SFT before RL induces sharpening, reducing coverage at high-→0.
Preservation of General Capabilities
RL post-training is remarkably neutral with respect to non-math, general capabilities; direct SFT, by contrast, consistently reduces these abilities by 4–8 points across diverse benchmarks, even when using SFT-Gold. This finding is robust across check-pointing and data splits, supporting the thesis that the standard SFT→1RL pipeline over-attributes regression to RL rather than SFT.
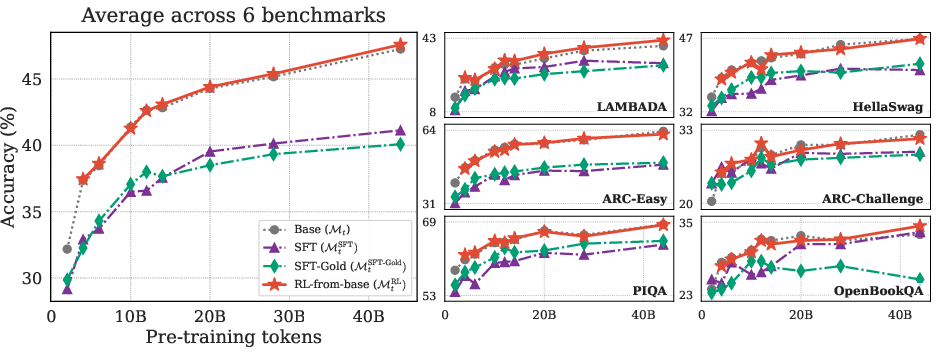
Figure 7: RL preserves broad generalization, while SFT degrades general-purpose capabilities; preserving generality is a unique strength of RL objectives.
RL + SFT: Parallel Averaging for Enhanced Training
A parallel-averaging algorithm is proposed, maintaining independent optimizer states and simultaneously applying SFT and RL gradients at each step via averaging. This approach consistently outperforms all other evaluated recipes (including SFT→2RL) on pass@32 in single-solution settings, while also fully preserving general capabilities.
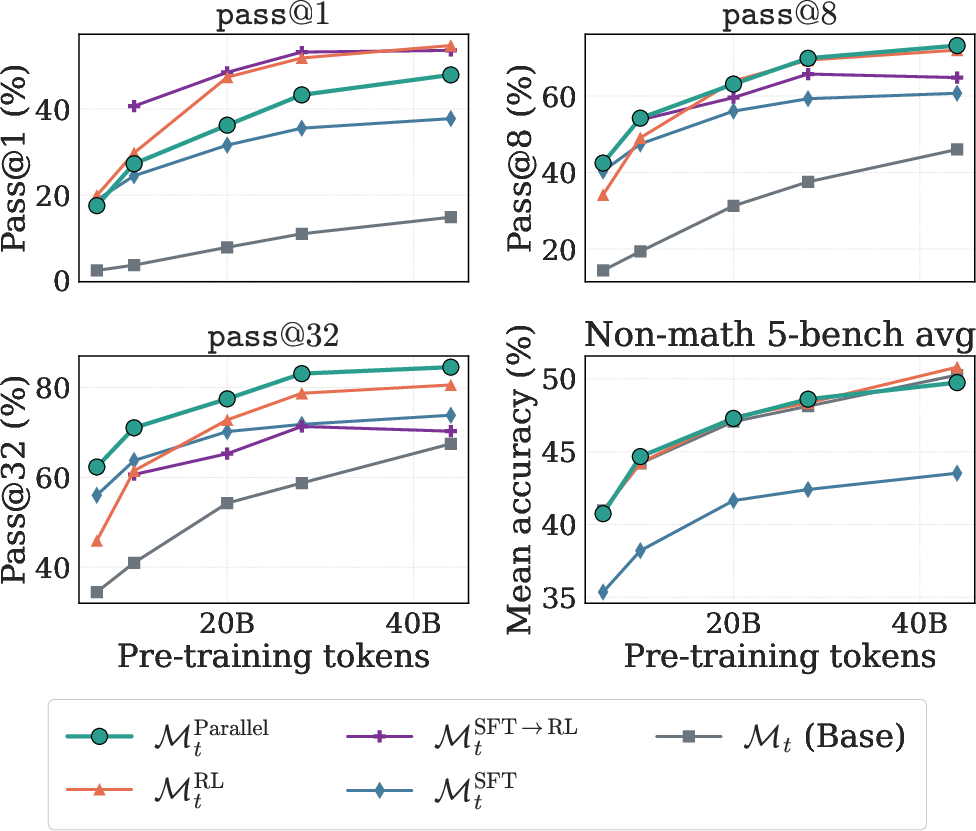
Figure 8: Parallel averaging update algorithm simultaneously applies SFT and RL gradients from the same parameter snapshot.
(Figure 1, right panel)
Figure 1 (revisited): Across all intermediate checkpoints, the parallel approach yields superior pass@32, synergizing the generalization of RL with the structured reasoning induced by SFT.
Theoretical and Practical Implications
These results challenge entrenched assumptions in LLM training:
- RL is not strictly a late-stage or post-training procedure; it is effective early and does not require a fully capable foundation model.
- Pretraining data curation trumps model size in enabling RL to unlock new capabilities, especially on complex tasks.
- Distribution-sharpening and general capability regression are not intrinsic to RL, but are consequences of SFT-induced collapse/exploration constraints in the standard pipeline.
- Hybrid, parallel approaches to combining RL and SFT can break the trade-off between reasoning skill and generalization, laying groundwork for more nuanced, adaptive objective mixing during LLM training.
Several open avenues are identified, including adaptive weighting/scheduling of RL and SFT losses, further studies at larger scale, and adaptive rollout allocation strategies depending on checkpoint readiness.
Conclusion
This comprehensive empirical analysis reconfigures foundational understandings of RL in LLM post-training. RL may be profitably introduced much earlier in training, especially with curated pre-training data, to simultaneously boost out-of-distribution reasoning and maintain general-purpose language competence. The efficacy and neutrality of RL (contrasted with SFT-induced regression), as well as the promise of hybrid training objectives such as parallel averaging, indicate substantial room for innovation in LLM training pipelines. Future work at larger scales and with broader tasks is required to confirm these findings at the frontier, but the analysis presented here offers a compelling blueprint for RL-centric, capability-promoting LLM development.
Reference:
"RL Excursions during Pre-Training: Re-examining Policy Optimization for LLM training" (2606.04272)