Stable-Layers: Fine-Tuning Image Layer Decomposition Models with VLM-Scored Reinforcement Learning
Abstract: We present Stable-Layers, a reinforcement learning framework that eliminates the need for paired supervision by fine-tuning a pretrained layer decomposition model using only feedback from a vision-LLM (VLM). Starting from Qwen-Image-Layered, we apply Flow-GRPO with LoRA adaptation, sampling multiple candidate decompositions per image, scoring them with a VLM, and optimising the policy from group-relative advantages. The key challenge lies in designing a reliable reward signal: VLMs scoring samples in isolation tend to compress their judgements into a narrow band, leaving GRPO with little within-group variance to learn from. We address this with a two-stage evaluation pipeline that pairs structured per-sample scoring across five edit-centric criteria with a grid-based calibration step in which the VLM re-scores all candidates side-by-side. Stable-Layers produces decompositions with stronger layer separation, fewer blank or artifact-heavy layers, and lower per-layer reconstruction error on the Crello dataset compared to the base model.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Stable-Layers, a way to teach a computer program to split a single picture into several editable layers (like in Photoshop), even when there’s no “correct answer” for how to split it. Instead of training with lots of perfectly labeled examples (which are hard to get), the authors use an AI “judge” that looks at the results and gives feedback. The model learns from that feedback to make cleaner, more useful layers.
What questions the authors wanted to answer
- Can we improve image “layer decomposition” (turning one image into several clean, editable layers) without needing matched, hand-labeled training data?
- Can an AI judge that understands images and text (a vision–LLM, or VLM) score the quality of the layers well enough to guide learning?
- How do we design the judge’s scoring so the learning signal is strong and reliable?
- How can we keep training stable when the model outputs many layers at once?
How the method works (in simple steps)
Think of it like a talent show for pictures, where the model tries several ways to split an image into layers, and a judge rates each try. Then the model tweaks itself to do better next time.
Here’s the basic cycle:
- The model makes several different layer versions (candidates) for the same input picture.
- A VLM judge scores each candidate. The scoring happens in two stages to make the feedback clear and fair:
- Stage 1: Rubric scoring. The judge looks at each candidate separately and scores it on five simple criteria (0–5 each):
- Semantic separation: Are different objects on different layers?
- Clean edges (alpha masks): Are the cutout edges crisp with no jagged halos?
- Background fill (inpainting): Does the background layer plausibly fill in what was behind objects?
- Even content spread: Is content shared across layers instead of one layer doing everything?
- No junk layers: Avoid blank layers or layers full of artifacts/noise.
- Stage 2: Side-by-side comparison. The judge then sees all candidates together in a grid and re-scores them relatively. This widens small differences the judge might miss when looking at them one-by-one.
- Stage 1: Rubric scoring. The judge looks at each candidate separately and scores it on five simple criteria (0–5 each):
- The model learns from these scores using a reinforcement learning technique (a “learn from trial-and-error” method) called Flow-GRPO. In short: results that the judge liked get nudged to be more likely next time; results it didn’t like get nudged to be less likely.
- Only a small, efficient add-on (LoRA) is trained, so learning is faster and uses less memory, while the main model stays mostly fixed.
Two extra details the authors handled:
- No paired data: They train only on ordinary, unlabeled images (no ground-truth layers) by relying entirely on the judge’s feedback.
- Stable training: Because the model packs many layers into its internal representation, the authors slightly adjusted the math so the learning signals don’t get too small or unstable.
What they found and why it matters
The improved model (Stable-Layers), starting from an existing system called Qwen-Image-Layered, showed clear gains:
- Better separation: Objects are more cleanly split onto their own layers.
- Cleaner masks: Edges are crisper, with less “glow” or bleed into transparent areas.
- More useful backgrounds: The background layer fills in occluded (hidden) parts more realistically, so editors can move or delete objects without ugly holes.
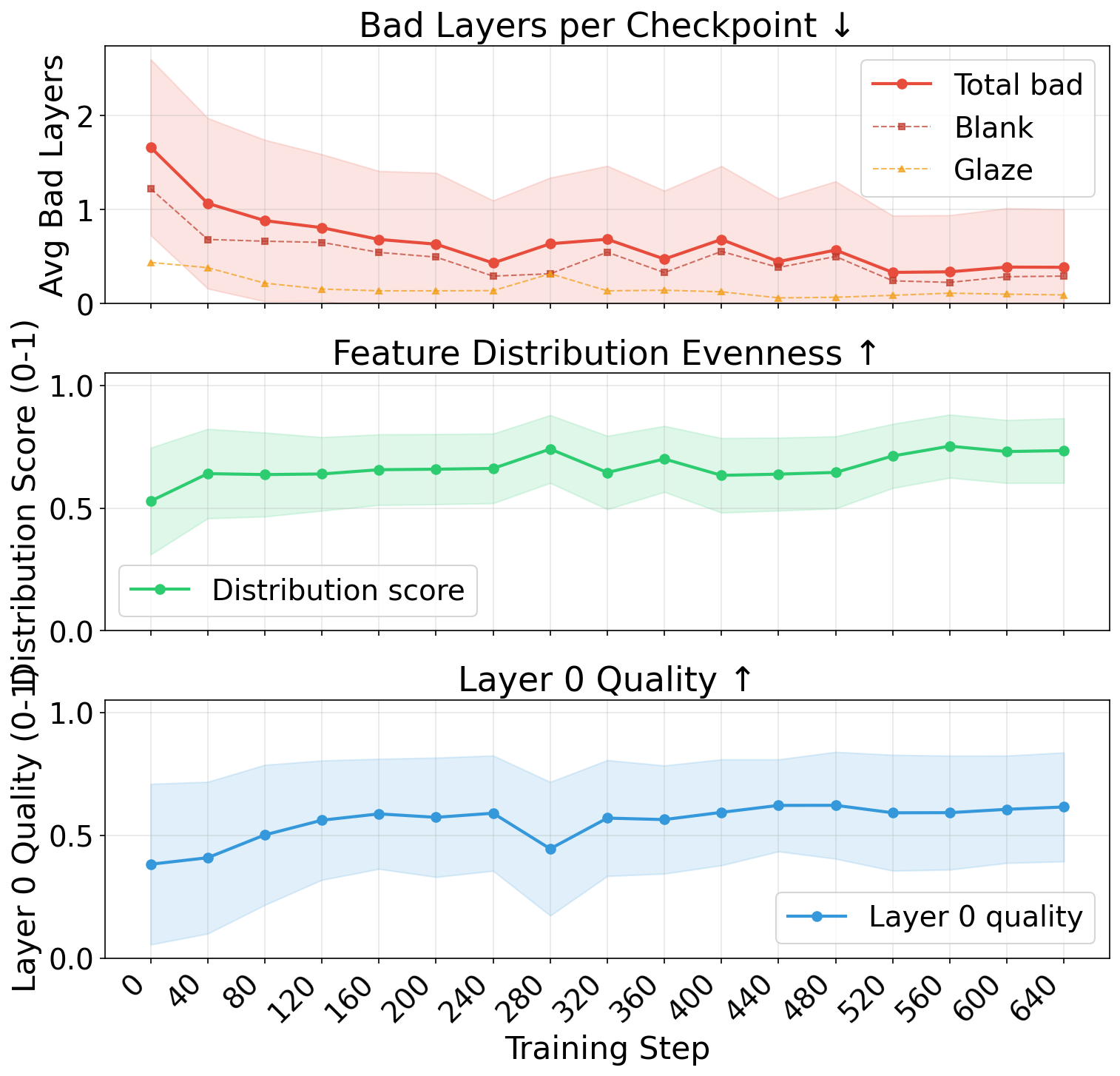
- Fewer bad layers: Fewer blank or artifact-heavy layers that waste space.
- Stronger accuracy on a public test set (Crello): The layers produced by Stable-Layers match ground-truth layers more closely (lower reconstruction error) than the base model.
The paper also ran comparisons and tests:
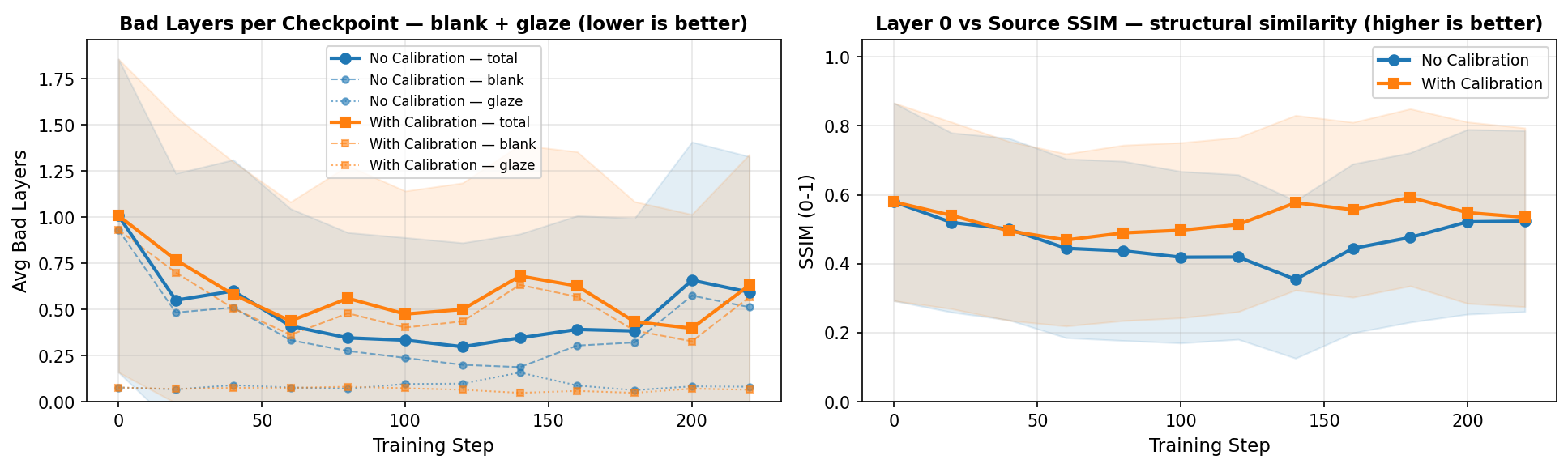
- Without the second “grid comparison” stage, the judge’s one-by-one scores were too similar, and the model didn’t learn fine details as well. Adding the side-by-side re-scoring made learning more precise.
- Compared with another approach (LayerD) that often returns fewer layers when uncertain, Stable-Layers consistently fills the requested number of layers with meaningful content—more useful for many editing tasks—even if the other method sometimes scored slightly higher on a narrow background-only metric.
Why this is useful (implications)
- Easier editing: Designers, artists, and everyday users can get cleaner, more editable layers from a single image—making tasks like swapping backgrounds, moving objects, or recoloring parts faster and simpler.
- Less dependence on labeled data: The training doesn’t need matched “correct” layers, which are expensive and subjective to create. This makes improving such tools much more practical.
- A general recipe: The same “AI judge + reinforcement learning” idea could help other image-editing or design tasks where there isn’t one right answer, but we can still judge quality (e.g., better masking, smarter object separation, or style adjustments).
- More reliable training: Their scoring setup and stability tweaks show how to make judge-based training work even when outputs are complex (like many layers at once).
In short, Stable-Layers shows that you can make image layer tools smarter and more useful by letting a capable AI judge guide the learning—no perfect labels required.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and could guide future research:
- Reward model dependence and bias
- Validate cross-judge robustness: does a policy trained with one VLM (e.g., Gemini) still score well with different VLMs and with human experts? Quantify judge-transfer performance and agreement (Kendall’s τ, Spearman’s ρ).
- Assess and mitigate judge bias and drift: how sensitive are rewards to VLM model versions, prompt tweaks, and rubric wording? Establish versioning, calibration, and robustness tests.
- Detect reward hacking: do learned policies exploit systematic VLM blind spots (e.g., over-smoothing edges) while degrading true editability? Design adversarial tests and countermeasures.
- Reward design and calibration
- Phase-2 grid calibration sensitivity: quantify how relative scores depend on grid resolution, layout, label format, and group size G; determine minimal settings that preserve variance and reliability.
- Absolute vs relative calibration: compare current two-phase approach to principled ranking models (Bradley–Terry, Thurstone, Elo) and to listwise ranking losses to improve consistency across groups.
- Alpha-channel presentation choice: test checkerboard, multiple background colors, and alpha-visualization overlays rather than white-only compositing to reduce presentation bias and better expose matte errors.
- Alternative reward extraction: benchmark structured text scoring against logit-based probes, learned reward models, or multimodal critics for each criterion; measure variance, calibration, and sample efficiency.
- Multi-criteria weighting: the 5 criteria are summed uniformly; explore criterion weights (learned or task-specific) and analyze trade-offs (e.g., alpha cleanliness vs inpainting plausibility).
- Inter-group comparability: current GRPO only needs within-group variance; for broader evaluation, design globally calibrated scales so scores are comparable across images and time.
- Optimization stability and theory
- RatioNorm reformulation: provide theoretical analysis and broad ablations of the sum-and-rescale-by sqrt(D) modification across architectures, latent dimensionalities, and datasets; verify it is not model-specific.
- KL regularization: clarify whether the KL term is fully omitted and study its effect; examine stability–performance trade-offs with/without KL under high-dimensional packed latents.
- Group size and sampling strategy: systematically vary G and the number of samples per image to map compute–performance curves and identify the minimal group variance needed for effective GRPO updates.
- Model capacity and adaptation
- LoRA-only updates: quantify performance vs full/partial fine-tuning; probe whether LoRA capacity (rank, targeted layers) limits achievable decomposition quality or generalization.
- Layer-count generalization: training uses 2–5 layers, but inference claims extend to up to 20 layers; verify empirically how quality scales with requested layer count beyond the trained range and under occlusion depth.
- Text conditioning: beyond fixed prompt ablations, test content-aware prompts (e.g., image captions) and conditional rubrics; disentangle whether prompts steer the generator vs bias the judge.
- Data and generalization
- Dataset breadth: training on Fine-T2I (photos + artwork) may not cover product shots, UIs, technical diagrams, anime, medical, or document images; evaluate cross-domain generalization and failure modes.
- Style and content edge cases: systematically test transparent/reflective objects, shadows, motion blur, fine hair/fur, thin structures, text, and repetitive patterns where alpha mattes commonly fail.
- Resolution and aspect ratio: the pipeline fixes 640×640; assess behavior at higher resolutions, non-square aspect ratios, and tiling strategies for large images.
- Evaluation coverage and rigor
- Human-in-the-loop validation: conduct expert user studies measuring editability (time-to-edit, success rate for common edits, user preference) rather than relying solely on proxy metrics.
- Composite fidelity: report composite reconstruction error (and colorimetric metrics) to ensure RL doesn’t degrade overall fidelity while improving per-layer properties.
- Alpha/matte metrics: include matting-specific metrics (e.g., SAD, MSE, gradient error) against curated pseudo-GT or synthetic composites to quantify mask edge quality.
- Background inpainting metrics: current L0 metrics (Qual., Sharp., SSIM) may not reflect semantic plausibility; evaluate with semantic consistency, texture realism, and human preference on diverse scenes.
- Statistical power: Crello test comparisons are small (e.g., m=3 for L=2, m=29 for L=3); expand test sets, report confidence intervals, and run significance tests.
- Baseline breadth: compare against more decomposition approaches (e.g., LayerDiffuse, CLD, LASAGNA, segmentation-based pipelines) under matched settings; include recent supervised and unsupervised baselines.
- Practicality and efficiency
- Cost and latency: quantify end-to-end training cost (VLM calls per step, grid overhead), and propose efficiency strategies (cached judgments, preference-learning to replace the VLM online, active sampling).
- Inference-time performance: measure inference latency and memory for various layer counts and image sizes; profile any regressions induced by LoRA or algorithmic changes.
- Downstream workflows and assets
- Editing tasks: benchmark common operations (object recolor, replace, reorder, scale, relight) and evaluate error rates introduced by imperfect masks or bleed-through after edits are applied.
- Graphics effects: current outputs are RGBA-only; study handling of blend modes, shadows, glows, and vector elements common in PSD/illustration workflows.
- Layer semantics: assess whether layers align with semantically meaningful parts and remain stable under minor input perturbations (consistency for iterative edits).
- Safety, fairness, and ethics
- Fairness and bias: examine whether the VLM judge introduces demographic or content biases (e.g., treating people vs objects differently) that skew layer allocation.
- Robustness to adversarial/ambiguous inputs: test for catastrophic decompositions under adversarial patterns or highly cluttered scenes; design guardrails in reward and training.
- Reproducibility and openness
- Precise reward prompts and VLM details: release full prompts, judge model/version, and calibration settings; evaluate with open-source VLMs to improve reproducibility.
- Code and model release: provide training code, checkpoints, and evaluation scripts to enable independent verification and ablation of each component.
- Longer-term research directions
- Learned multi-criteria critics: train small, open VLMs or multimodal reward models distilled from expensive judges to reduce cost and stabilize scoring.
- Curriculum over layer count and difficulty: progressively increase requested layer counts and scene complexity to build capability without destabilizing training.
- Joint training with weak supervision: combine VLM-judged RL with small amounts of synthetic or pseudo-labeled data to anchor absolute fidelity while optimizing editability.
Practical Applications
Practical Applications of “Stable-Layers: Fine-Tuning Image Layer Decomposition Models with VLM-Scored Reinforcement Learning”
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Items are grouped by deployment horizon and note sector tags, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
- One-click layerized PSD exports for creatives — sector: software/creative tools
- Automate decomposing any image into clean RGBA layers suitable for direct editing (alpha cleanliness, semantic separation, plausible background inpainting).
- Tools/workflows: Photoshop/Photopea/Figma plugin or a web API that returns a layered PSD; batch converters for studios.
- Assumptions/dependencies: Base model (e.g., Qwen-Image-Layered) fine-tuned with Stable-Layers LoRA; acceptable inference latency; license-compliant VAE/transformer weights.
- E-commerce product imagery cleanup and variation — sector: retail/e-commerce, marketing
- Isolate product vs. background; generate background variants; remove artifacts; recombine layers for region-specific localization (e.g., labels).
- Tools/workflows: “CleanBack & Variants” pipeline; DAM-integrated bulk processor; Shopify/BigCommerce app.
- Assumptions/dependencies: Domain adaptation may be needed for specific product categories; guardrails for text/logo layers.
- VFX pre-rotoscoping and matte assistance — sector: film/VFX, media
- Provide initial layered separations and inpainted backgrounds to reduce manual rotoscoping and matte painting.
- Tools/workflows: Nuke/After Effects plugin; ingest RGBA layers for manual refinement; timeline batch processor for keyframes.
- Assumptions/dependencies: Still-image performance is strong; for video, start with keyframes and interpolate (manual QC required).
- Rapid compositing for ad creatives and DCO (dynamic creative optimization) — sector: marketing/advertising
- Separate compositional elements for fast swapping (e.g., backgrounds/props), supporting A/B tests and personalization.
- Tools/workflows: Creative Ops UI that shows layer stack with toggles/swaps; automatic rendering for campaign variants.
- Assumptions/dependencies: Brand/color fidelity QC; performance monitoring to avoid VLM-judged bias creeping into creative decisions.
- Photography and smartphone apps: interactive edits — sector: consumer software/daily life
- One-tap background replacement, object removal, or per-object adjustments via layer toggles.
- Tools/workflows: Mobile SDK integrated into camera/gallery apps; on-device caching of layers for responsive edits.
- Assumptions/dependencies: On-device optimization or server-side inference; consistent performance across photo styles.
- Design localization and multi-language assets — sector: software/design ops, localization
- Decompose graphics to isolate text and graphic elements for language swaps and layout adjustments.
- Tools/workflows: “Auto-layer” before localization pipeline; export to PSD/Sketch/Figma layers.
- Assumptions/dependencies: Robustness to typographic content varies; may require domain-specific fine-tuning on text-heavy assets.
- Object-level DAM indexing and retrieval — sector: enterprise software, media libraries
- Index images by layer content (objects/regions) for finer-grained search and asset reuse.
- Tools/workflows: DAM plugin to extract per-layer tags via a VLM/Vision encoder; search UI with layer previews.
- Assumptions/dependencies: Reliable semantic separation across domains; privacy and IP considerations for derived metadata.
- Print and packaging prepress assist (raster workflows) — sector: print/manufacturing
- Pre-separate major elements to streamline color correction, spot edits, and dieline fit checks in raster workflows.
- Tools/workflows: Prepress automation scripts that import layered outputs; operator-in-the-loop adjustments.
- Assumptions/dependencies: CMYK-specific color management still required; full vectorization remains out of scope.
- Usability-driven model tuning without labels — sector: ML engineering/research
- Adopt the two-phase VLM reward (structured rubric + grid calibration) to fine-tune existing edit-oriented generators when paired targets don’t exist.
- Tools/workflows: “JudgeRL” training loop template; LoRA adapters per domain; experiment trackers logging Phase-1/Phase-2 scores.
- Assumptions/dependencies: Access to a capable VLM judge; budget for VLM scoring; reproducibility of rubric prompts.
- Training stability upgrade for flow-matching RL — sector: ML tooling
- Apply the sum-and-rescale RatioNorm variant for packed latents (multi-layer, multi-frame, or high-dimensional tokens) to preserve O(1) importance ratios.
- Tools/workflows: Open-source patch to GRPO-Guard/Flow-GRPO pipelines; ablation scripts for ratio scaling across latent sizes.
- Assumptions/dependencies: Compatibility with existing GRPO-Guard implementations; empirical calibration for each model’s latent geometry.
- Quality assurance for layered outputs with a VLM judge — sector: software quality/ops
- Use the rubric and grid-calibration as a standalone automated QA step for third-party decomposition tools (flag duplicates, blank/glazed layers, poor inpainting).
- Tools/workflows: Scoring microservice; dashboards tracking “bad layers per decomposition,” inpainting quality, and feature distribution evenness.
- Assumptions/dependencies: VLM generalizes to target asset styles; cost-effective at scale.
- Dataset bootstrapping for compositional research — sector: academia/ML research
- Generate pseudo-labeled layered datasets from unlabelled images to study compositionality, matting, and object-centric learning.
- Tools/workflows: Batch generation with confidence filtering by VLM scores; release of curated subsets for benchmarking.
- Assumptions/dependencies: Clear licensing for derived datasets; transparent reporting of VLM-judge bias and scoring thresholds.
Long-Term Applications
- Real-time video layer decomposition for editing and AR occlusion — sector: media, AR/VR
- Extend to temporally consistent video layers for live or near-live compositing, including plausible inpainting behind moving objects.
- Tools/workflows: Temporal consistency modules; streaming inference on edge servers; AR SDK integration.
- Assumptions/dependencies: Temporal models and efficient inference; additional training on video data; robust latency budgets.
- Domain-specialized decompositions (fashion, furniture, automotive) — sector: retail/e-commerce, manufacturing
- Tailor decomposition to category-specific semantics (e.g., sleeves vs. collars; upholstery vs. frame; rims vs. body).
- Tools/workflows: Domain LoRAs + judge prompts with domain-specific rubrics; product onboarding pipelines.
- Assumptions/dependencies: Curated unlabeled image corpora per domain; reliable VLM recognition of domain concepts.
- Medical imaging layerization (anatomical/lesion separation) — sector: healthcare
- Decompose images into clinically meaningful layers (tissue types, pathologies) for planning/education.
- Tools/workflows: PACS-integrated review tools; expert-in-the-loop judge rubrics; regulatory-grade evaluation.
- Assumptions/dependencies: Domain VLMs trained on medical imagery; rigorous validation, privacy and regulatory compliance.
- Robotics and embodied AI scene factoring — sector: robotics
- Use layered decompositions with plausible occlusion inpainting to support object permanence, affordance reasoning, and manipulation planning.
- Tools/workflows: Perception pipeline modules that feed layered representations to planners; judge-as-reward for perception alignment.
- Assumptions/dependencies: Bridging from photographic layers to actionable 3D cues; task-specific reward design.
- 3D/NeRF bootstrapping from layered 2D — sector: 3D graphics/games
- Use separated layers and inpainted backgrounds as priors for single-view 3D reconstruction or texture recovery.
- Tools/workflows: Layer-aware 3D reconstruction pipelines; texture inpainting from per-layer content.
- Assumptions/dependencies: Methodological advances to fuse 2D layers into geometry; additional supervision or priors.
- Low-bandwidth creative streaming and personalized rendering — sector: media delivery/ads
- Transmit base scene plus small layered deltas for on-device recomposition, enabling personalized creatives with less bandwidth.
- Tools/workflows: Client-side composer; CDN logic for layer bundling; privacy-preserving personalization.
- Assumptions/dependencies: Standardized layer formats; device GPU capabilities; content integrity checks.
- Interactive educational content and explorable diagrams — sector: education/edtech
- Automatically produce layered diagrams/illustrations where elements can be revealed step-by-step or highlighted for pedagogy.
- Tools/workflows: LMS plugins; authoring tools that import/decompose images into lesson steps.
- Assumptions/dependencies: Strong performance on stylized/diagrammatic content; didactic rubrics for judge prompts.
- Forensics and provenance analytics — sector: trust & safety, policy
- Analyze layered decompositions to detect compositing artifacts and inconsistencies as signals of manipulation.
- Tools/workflows: Forensic dashboards using judge metrics; provenance scoring alongside content credentials.
- Assumptions/dependencies: Research demonstrating discriminative power for forensics; careful handling of false positives.
- Standardization and auditing of VLM-as-judge pipelines — sector: policy/governance, ML ops
- Establish benchmarks and audit procedures for rubric-based and relative calibration scoring to mitigate bias, drift, and cost.
- Tools/workflows: Public test suites; reporting standards for prompts, model versions, and calibration artifacts; cost-capped evaluation designs.
- Assumptions/dependencies: Multi-stakeholder coordination; transparency from VLM providers.
- Generalized judge-driven RL for other edit tasks — sector: ML research, software
- Apply the two-phase reward design to matting, relighting, deblurring, upscaling, and layout synthesis where paired supervision is scarce.
- Tools/workflows: Task-specific rubrics + calibration templates; modular reward extractors; LoRA-based fine-tuning kits.
- Assumptions/dependencies: Task-relevant VLM perception; rubric engineering and reliable within-group variance.
- Vector/print-ready layer pipelines — sector: design/print
- Bridge from RGBA layers to vector-like separations (e.g., posterization + edge-aware vectorization) for scalable print workflows.
- Tools/workflows: Hybrid raster-to-vector pipeline seeded by Stable-Layers outputs; operator-in-the-loop refinement.
- Assumptions/dependencies: Advances in vectorization with preservation of semantics and matte quality.
- Compliance-aware content editing at scale — sector: legal/policy, enterprise ops
- Enforce rules (e.g., remove sensitive objects/logos) via layer separation and automated toggling, with judge-scored evidence trails.
- Tools/workflows: Policy engines tied to specific layer types; audit logs of decisions and VLM scores.
- Assumptions/dependencies: Reliable detection and separation of regulated content; human oversight for edge cases.
Notes on feasibility and risks across applications:
- VLM dependency: Quality and calibration of the judge are pivotal; access, cost, and potential bias of proprietary VLMs affect viability.
- Domain shift: Models trained on general images may underperform on specialized domains (medical, CAD, technical diagrams) without targeted adaptation.
- Latency/throughput: Production use may require model distillation, quantization, or server batching; RL training is offline but VLM scoring during training is cost-sensitive.
- IP and privacy: Deriving layers and inpainting occluded content can raise IP/consent concerns; ensure compliant data sources and disclosures.
- Evaluation: Internal QA should monitor metrics highlighted in the paper (bad layers per decomposition, feature distribution evenness, background inpainting quality) to guard against regressions.
Glossary
- Alpha matte: A per-pixel transparency mask that cleanly delineates foreground from background for compositing and editing. "including semantic separation, clean alpha mattes, minimal redundancy, and faithful handling of occluded content"
- Background inpainting: Filling in plausible background content where foreground elements are removed or made transparent. "background inpainting (layer~0 is a plausible scene completion)"
- Best-match assignment: Matching predicted layers to ground-truth layers by minimizing error irrespective of their index positions. "with one modification: best-match assignment in place of fixed-index comparison"
- Clipped surrogate: A PPO-style objective that clips importance ratios to stabilize policy updates. "GRPO optimises a clipped surrogate"
- Crello dataset: A layered graphic design dataset used to evaluate per-layer reconstruction quality. "lower per-layer reconstruction error on the Crello dataset compared to the base model."
- DanceGRPO: A GRPO variant/study validating group-relative policy updates at scale. "DanceGRPO validates group-relative updates at scale"
- DDPO: A reinforcement learning approach casting diffusion sampling as an MDP and applying policy gradients to non-differentiable rewards. "DDPO and DPOK first cast diffusion sampling as a multi-step MDP and applied policy gradients to optimise non-differentiable rewards"
- Diffusion-DPO: A preference-based objective for diffusion models that avoids online rollouts. "Diffusion-DPO sidesteps online rollouts by optimising a preference-based objective on static comparison data."
- Flow matching: A generative modeling framework that learns a velocity field to transform noise into data along a continuous trajectory. "flow matching as the generative framework"
- Flow-GRPO: An SDE-augmented flow matching method that enables tractable log-probabilities for GRPO-style optimization. "Flow-GRPO augments the deterministic ODE with a stochastic differential equation that preserves the learned marginals"
- Generate-then-disassemble pipelines: Layered image generation approaches that first synthesize a composite image and then separate it into layers. "generate-then-disassemble pipelines."
- GRPO (Group Relative Policy Optimization): A policy optimization algorithm that computes and normalizes advantages within groups of samples from the same condition. "GRPO computes within-group advantage"
- GRPO-Guard: A stabilization scheme for GRPO that normalizes importance ratios and reweights gradients. "GRPO-Guard stabilises the importance ratio via normalisation and gradient reweighting."
- Grid calibration: A relative scoring step that presents candidates side-by-side to improve score spread and calibration. "with a grid-based calibration step in which the VLM re-scores all candidates side-by-side."
- Harmonized decoding: A decoding strategy coordinating multi-layer outputs to maintain consistency in layered generation. "harmonized decoding"
- Image layer decomposition: Separating an image into editable RGBA layers whose recomposition reconstructs the original. "Image layer decomposition—separating an image into a small set of editable RGBA layers whose composition reconstructs the original"
- Importance ratio: The ratio of new to old policy probabilities used to weight policy gradient updates. "stabilises the importance ratio via normalisation and gradient reweighting."
- Inter-layer attention: Attention mechanisms enabling information exchange across layers in multi-layer generation models. "inter-layer attention"
- LAION-Aesthetics: A subset of the LAION dataset filtered for aesthetic quality, used for evaluation. "480 LAION-Aesthetics images"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method injecting low-rank updates into weight matrices. "We apply Low-Rank Adaptation with rank r{=}16 and α{=}16 to all attention projection layers and feed-forward layers"
- MMDiT: A diffusion-transformer architecture variant used for variable-layer decomposition. "a Variable Layers Decomposition MMDiT"
- Patch-packed latents: Latent representations formed by packing small spatial patches into tokens for transformer processing. "operating on 2×2 patch-packed latents (yielding token dimension 16 × 4 = 64)"
- RatioNorm: A normalization of log-importance ratios per step to center and stabilize their distribution. "GRPO-Guard's RatioNorm uses a spatial mean of per-element log-probabilities"
- Rectified flow: A flow matching variant that linearly interpolates between noise and data while learning a velocity field. "Rectified flow interpolates"
- RGB L1: The mean absolute error between RGB images, used to measure reconstruction accuracy. "Per-layer RGB L1 vs Crello ground-truth test set layers"
- RGBA-VAE: A variational autoencoder specialized for four-channel (RGBA) images. "an RGBA-VAE"
- Sequence-packed latents: Latent sequences that pack multiple elements (e.g., multiple layers) into a single sequence for modeling. "flow-matching RL settings with sequence-packed latents."
- SSIM: Structural Similarity Index, an image quality metric assessing perceptual similarity. "Qual., Sharp., and SSIM are Layer~0 quality metrics."
- Stochastic differential equation (SDE): A stochastic dynamic used to define sampling transitions with tractable log-probabilities. "Flow-GRPO augments the deterministic ODE with a stochastic differential equation"
- Trajectory replay: Reusing stored sampling trajectories to compute policy updates after scoring. "We follow Flow-GRPO's trajectory replay procedure"
- Variational Autoencoder (VAE): A latent-variable generative model with an encoder-decoder architecture trained via variational inference. "The architecture comprises a 3D variational autoencoder (VAE) that encodes 4-channel RGBA frames"
- Vision-LLM (VLM): A multimodal model that jointly understands images and text, used here as an automatic judge. "using only feedback from a vision-LLM (VLM)."
Collections
Sign up for free to add this paper to one or more collections.

