- The paper identifies model–task alignment (via pass@k accuracy) as the main determinant of reinforcement learning performance in LLM reasoning tasks.
- It demonstrates that high alignment can yield robust RL outcomes even with spurious, random, or negative-only reward signals, a benefit not observed in low-alignment settings.
- Empirical evaluations with Qwen2.5-7B and Llama-3.1-8B-Instruct reveal that one-shot and sample selection methods are effective only when the model’s pretrained capabilities align well with task requirements.
Model–Task Alignment as the Determinant of RL Outcomes in LLM Reasoning
Introduction and Motivation
The application of reinforcement learning (RL) to LLMs has produced a series of empirical phenomena that diverge from classical RL expectations. Notably, recent studies have reported that LLMs can achieve strong performance with minimal or even spurious reward signals, that one-shot RL can rival full-dataset training, and that negative-only reward signals can suffice for effective learning. However, these claims have been largely based on narrow experimental settings, often involving specific model-task pairs such as Qwen models on mathematical reasoning. The paper "Mirage or Method? How Model-Task Alignment Induces Divergent RL Conclusions" (2508.21188) systematically investigates the conditions under which these counterintuitive RL behaviors arise, positing that the degree of model–task alignment—quantified by pass@k accuracy—serves as the critical differentiator.
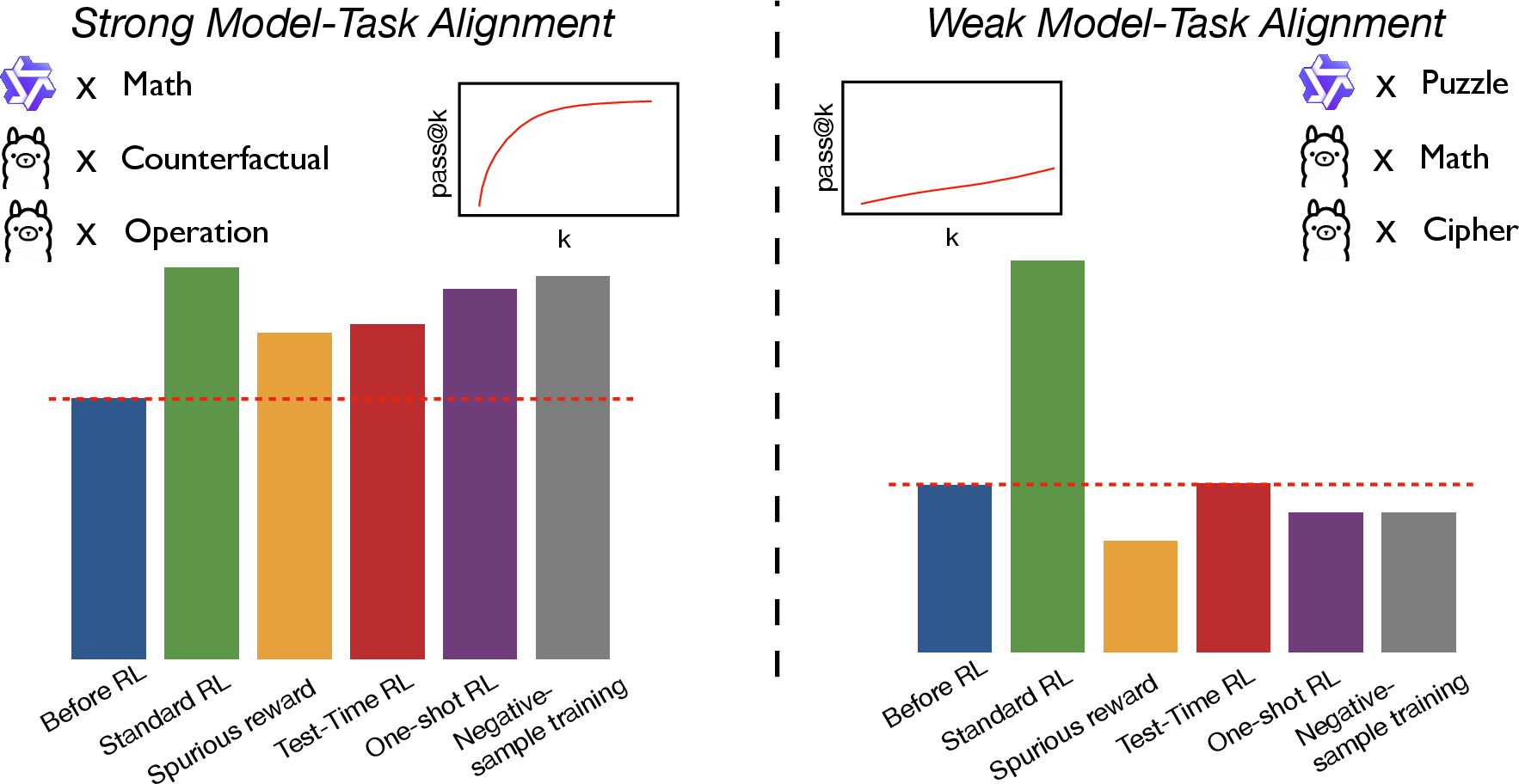
Figure 1: Model-task alignment, which is measured by pass@k accuracy on the evaluated task, drives distinct outcomes from the same series of RL approaches.
Model–Task Alignment: Definition and Measurement
The central hypothesis advanced is that the effectiveness of RL techniques in LLM reasoning is fundamentally contingent on the alignment between a model’s pretrained capabilities and the requirements of the target task. This alignment is operationalized via the pass@k metric, which measures the probability that at least one correct solution appears among k independent model samples for a given problem. High pass@k indicates strong inherent model proficiency on the task, while low pass@k signals misalignment.
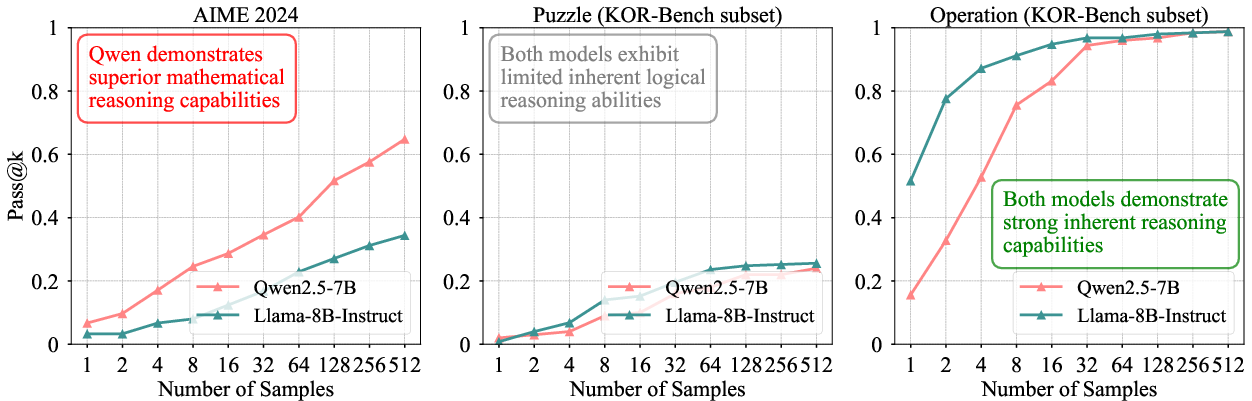
Figure 2: Pass@k for different tasks. Different LLMs have significantly different abilities on different tasks, which will affect how the RL techniques perform across model-task combinations.
Empirical evaluation across Qwen2.5-7B and Llama-3.1-8B-Instruct on mathematical and logical reasoning benchmarks reveals substantial variance in pass@k, with Qwen2.5-7B exhibiting strong alignment on math tasks and both models showing strong alignment on certain KOR-Bench subtasks (Operation, Counterfactual), but weak alignment on more complex logical reasoning tasks.
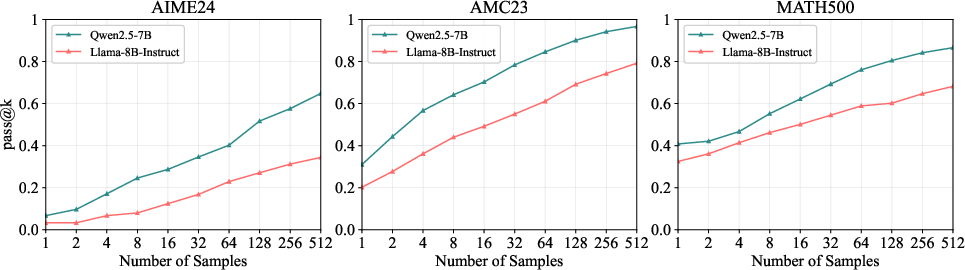
Figure 3: Pass@k for math tasks. Qwen demonstrates strong capabilities across all three mathematical evaluation datasets.
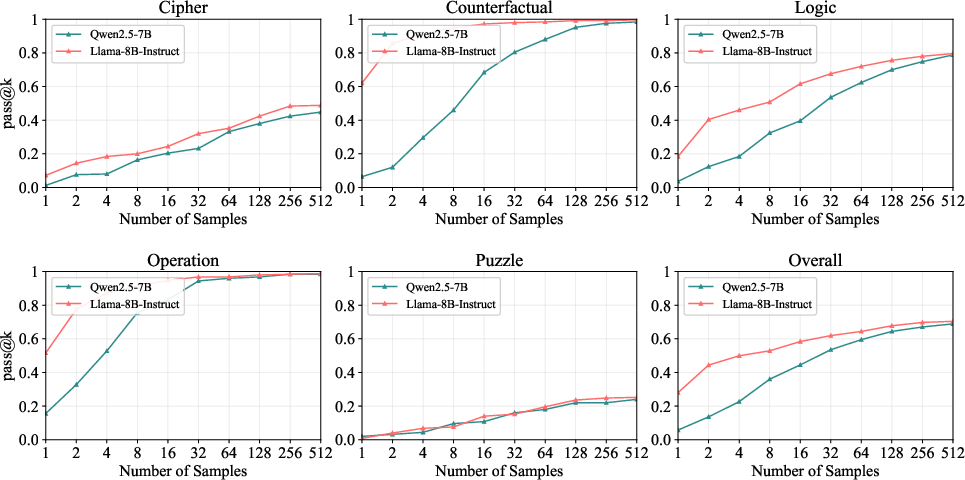
Figure 4: Pass@k for KOR-Bench. Both models demonstrate strong inherent reasoning capabilities in Operation and Counterfactual subtasks, but exhibit limited inherent logical reasoning abilities in Cipher, Puzzle and Logic.
Disentangling Contamination from Alignment
A competing hypothesis attributes the observed RL phenomena to data contamination (i.e., test set leakage during pretraining). The authors conduct prompt truncation and completion experiments to assess contamination, finding that strong RL effects persist even in settings with no evidence of contamination, provided model–task alignment is high. Conversely, in low-alignment settings, neither contamination nor RL idiosyncrasies are observed. This decouples contamination from the core mechanism and reinforces alignment as the primary explanatory variable.
Reward Signal Robustness and RL Effectiveness
The study systematically evaluates RL performance under various reward signal regimes: ground-truth, random, incorrect, and self-rewarded (e.g., majority voting, entropy minimization). The results demonstrate:
- Ground-truth rewards consistently yield the highest performance across all settings.
- Robustness to noisy or spurious rewards is observed only in high-alignment settings. For example, Qwen2.5-7B on math tasks maintains strong performance even with random or incorrect rewards, while Llama-3.1-8B-Instruct on the same tasks does not benefit from such signals.
- Self-rewarded methods underperform compared to external reward-based RL, especially in low-alignment domains.
These findings indicate that the apparent fault tolerance of RL in LLMs is not a universal property, but rather a consequence of latent model proficiency on the task.
One-Shot RL and Sample Selection
The claim that one-shot RL can match full-dataset training is scrutinized by comparing performance when training on a single example (randomly chosen or selected by reward variance) versus the full dataset. The results show:
- One-shot RL is effective only when model–task alignment is strong. In these cases, both random and selected examples yield substantial improvements, approaching full-dataset performance.
- In low-alignment settings, one-shot RL fails to drive meaningful learning, regardless of sample selection strategy.
- Sophisticated sample selection algorithms do not consistently outperform random selection in high-alignment regimes.
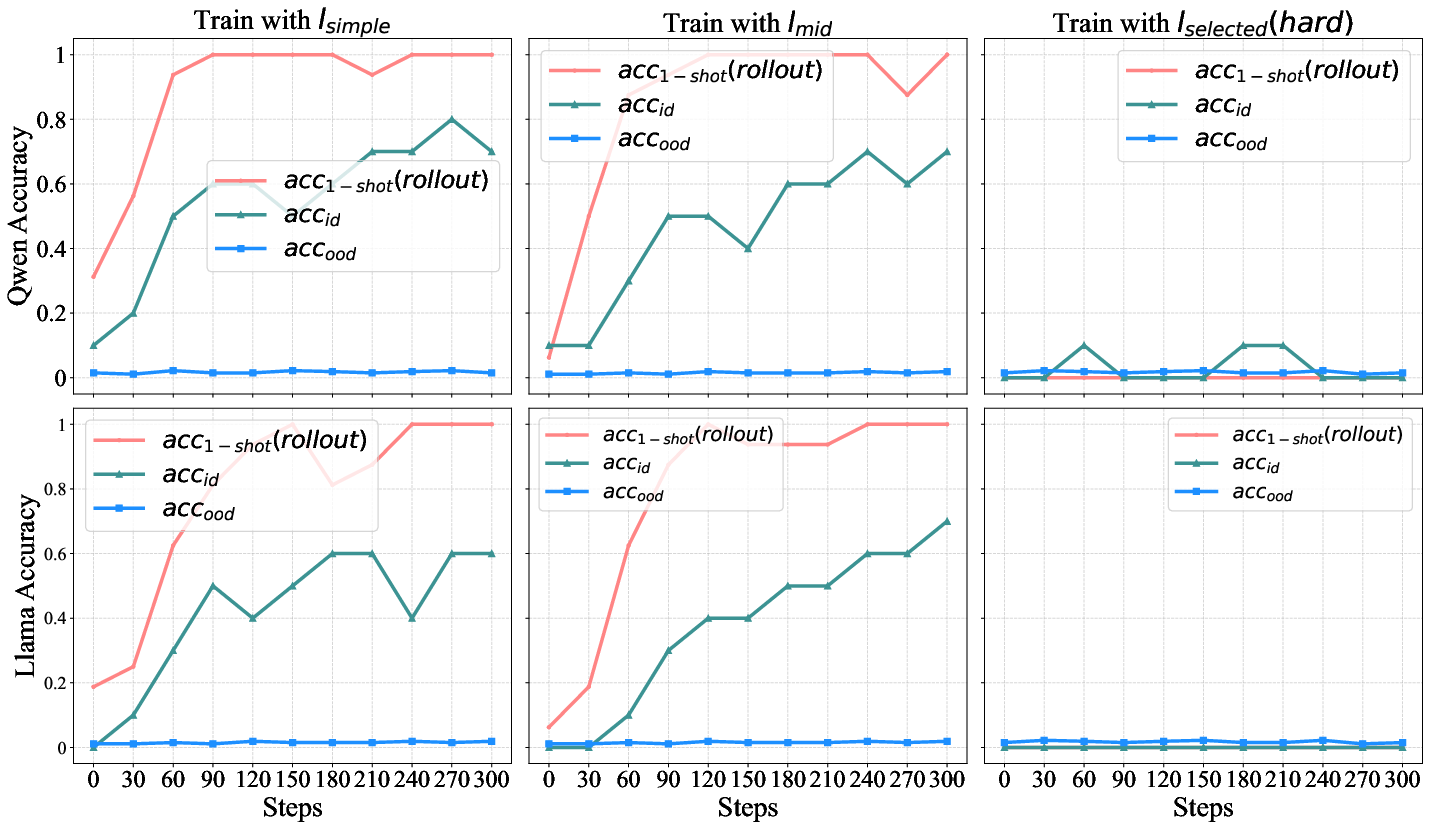
Figure 5: The changes in two models' accuracy during the training. If the initial rollout accuracy is non-zero, both models rapidly fit the employed samples (lsimple, lmid) and exhibit generalization within the same subtask; however, no generalization to puzzles of other types is observed.
Negative-Only and Positive-Only RL Signals
The paper further examines the effectiveness of negative-only (NSR) and positive-only (PSR) RL signals. The key findings are:
- In high-alignment settings, both NSR and PSR can recover most of the performance gains of full-signal RL.
- In low-alignment settings, PSR outperforms NSR, and NSR often fails to improve over baseline.
- Negative-only RL maintains higher entropy and exploration, but this does not translate to improved accuracy in challenging domains.
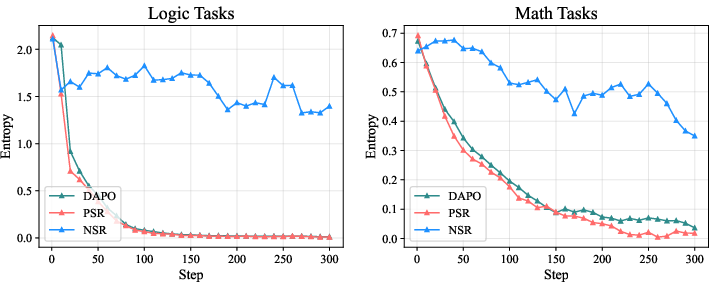
Figure 6: Entropy Dynamics of Qwen2.5-7B during Training. NSR can maintain the exploration space of reinforcement learning, but a larger exploration space is not always favorable, as in logical tasks.
Implications and Theoretical Significance
The results collectively indicate that many of the celebrated RL phenomena in LLMs—robustness to reward noise, one-shot learning, and negative-only signal sufficiency—are not general properties of RL, but rather artifacts of strong model–task alignment. In these cases, RL serves primarily as a mechanism for capability elicitation rather than genuine skill acquisition. For unfamiliar or misaligned tasks, standard RL with accurate rewards and sufficient data remains necessary.
This has several implications:
- Evaluation of RL methods in LLMs must control for model–task alignment to avoid overgeneralizing from high-alignment cases.
- Resource allocation strategies should consider whether to invest in pretraining/mid-training for domain-specific capabilities or in RL with high-quality rewards and data.
- Future research should focus on developing RL techniques that are effective in low-alignment regimes, where true generalization and reasoning skill acquisition are required.
Conclusion
This work establishes model–task alignment, as measured by pass@k, as the principal determinant of when counterintuitive RL phenomena manifest in LLM reasoning. The findings challenge the universality of recent RL claims and provide a rigorous framework for interpreting RL outcomes in LLMs. Theoretical and practical advances in RL for LLMs will require explicit consideration of alignment, with future work needed to develop methods that can drive learning in genuinely novel domains.