Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Abstract: Existing reinforcement learning (RL) approaches treat LLMs as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the LLM policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks inside LLMs to understand how they make decisions, step by step, as they generate words. Instead of treating the whole model as one big “policy” (a rule for choosing the next word), the authors break that policy into smaller, hidden policies inside each layer and module of the model. Using what they find, they introduce a new training method called Bottom-up Policy Optimization (BuPO) that improves the model’s reasoning abilities by training the lower layers first.
What questions did the researchers ask?
The paper asks simple but important questions:
- Can we treat each layer (and each part of a layer) in a LLM as if it has its own mini policy for choosing the next word?
- How does a model’s “uncertainty” change from the bottom layers to the top layers when it’s reasoning?
- Do different model families (like Llama vs. Qwen) reason in different ways internally?
- If we optimize the lower-layer policies first, can we make the whole model reason better?
How did they study it? (Explained with everyday analogies)
Think of a Transformer (the type of model used in LLMs) as a team working on a writing task:
- The model has stacked “layers” (like levels in a building). Each layer has two main workers:
- Attention: the “looking” worker that scans the context to see what matters now.
- FFN (Feed-Forward Network): the “knowledge” worker that brings in stored facts and patterns.
- As the text is written, there’s a running notebook (called the residual stream) that carries notes from one layer to the next. Every layer adds to this notebook.
Key ideas they used:
- Internal policies: If you ask just one layer to make a guess about the next word, it can. The authors show that every layer’s notes can be turned into a probability distribution over the vocabulary—basically, “here’s how likely each next word is”—just like the final layer does. In math terms, they multiply a layer’s hidden state by an “unembedding” matrix (think of it as a decoder that turns thoughts into words) to get a usable prediction.
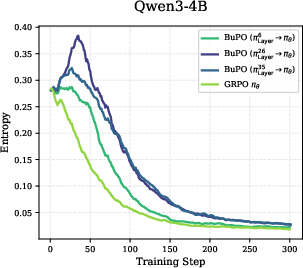
- Entropy: This is a measure of uncertainty. High entropy means the model is exploring many possibilities (it’s unsure and open-minded). Low entropy means it’s very confident (its guesses are focused). They track entropy at each layer and module to see how uncertainty changes.
- Entropy change: Instead of only looking at “how uncertain” a layer is, they also measure how uncertainty changes after the attention or FFN worker does its job. This tells whether a module increases exploration, integrates knowledge, or pushes toward a final answer.
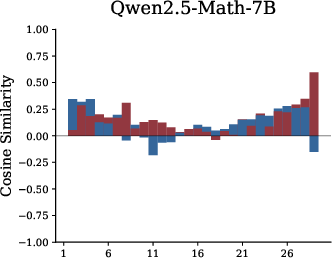
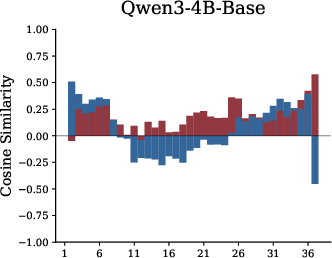
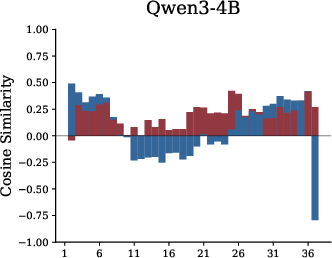
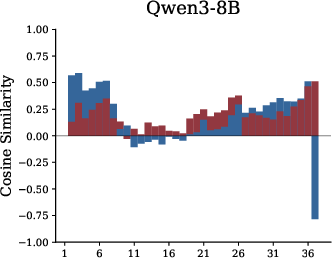
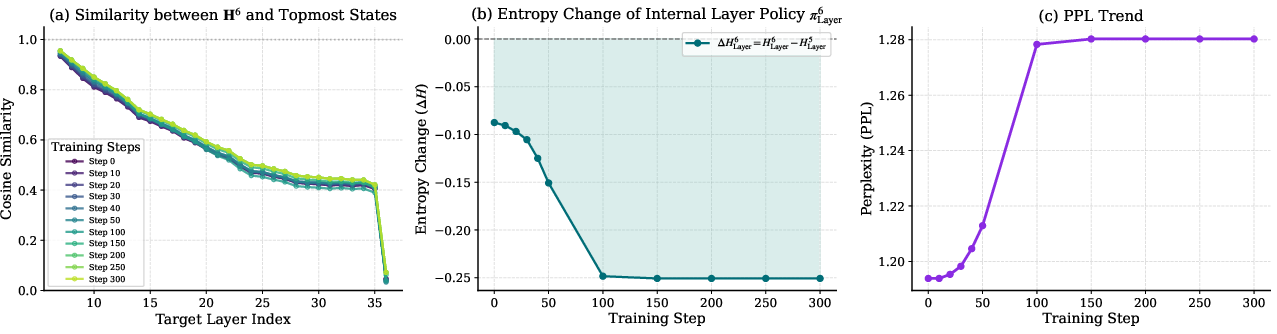
- Residual cosine similarity: This measures whether a module writes new ideas into the notebook (orthogonal/new), strengthens existing ideas (positive), or suppresses them (negative).
Training approach:
- Standard RL (Reinforcement Learning) methods train the whole model’s policy at once to get more correct answers, often using verifiable rewards (like math problem correctness).
- Their new approach, BuPO, first optimizes internal layer policies—especially in lower layers—for a short, early phase. Then it switches to training the overall policy as usual. This is “bottom-up.”
What did they find, and why is it important?
Here are the main findings, explained simply:
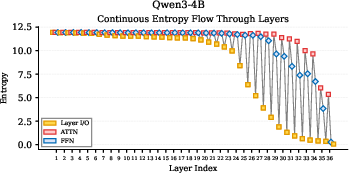
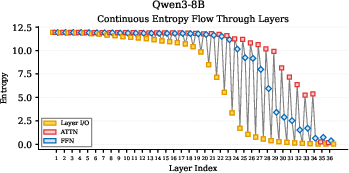
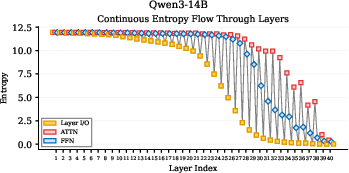
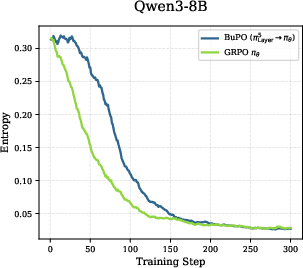
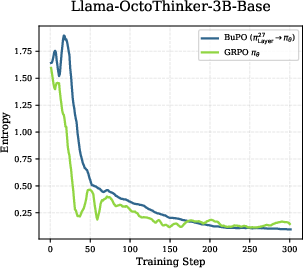
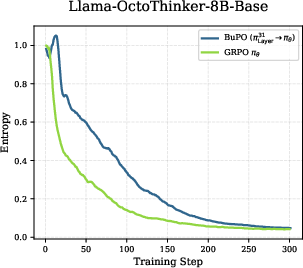
- Universal pattern across models: Early layers explore and have high entropy. Top layers converge and have low entropy, becoming very confident before outputting the final word. This suggests the model starts broad and narrows down as it goes up the stack.
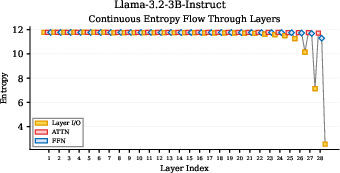
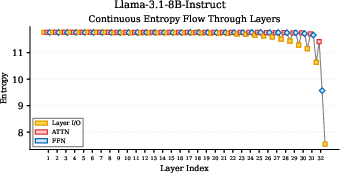
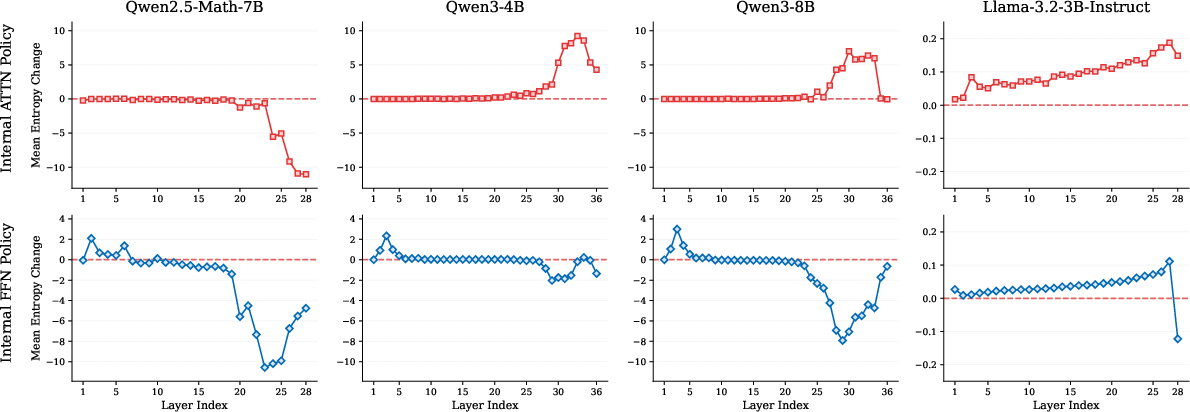
- Different model families reason differently:
- Llama models: They collapse (become very certain) mainly in the last few layers. That means most narrowing happens right at the end.
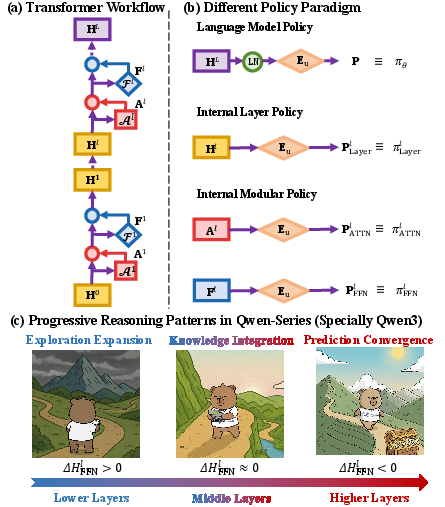
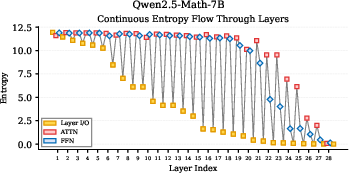
- Qwen models (especially Qwen3): They show a more gradual, human-like pattern. In their FFN modules, they go through three stages:
- 1. Exploration: lower layers expand uncertainty (open-minded).
- 2. Integration: middle layers hold uncertainty steady and combine knowledge.
- 3. Convergence: upper layers reduce uncertainty and push toward an answer.
- Attention vs. FFN behavior:
- In Qwen3, attention often increases exploration across layers (positive entropy change), helping the model consider more context.
- FFN acts like a knowledge library: lower FFN layers add new ideas, middle ones integrate stored knowledge, and upper ones help finalize predictions.
- Internal policy optimization effects:
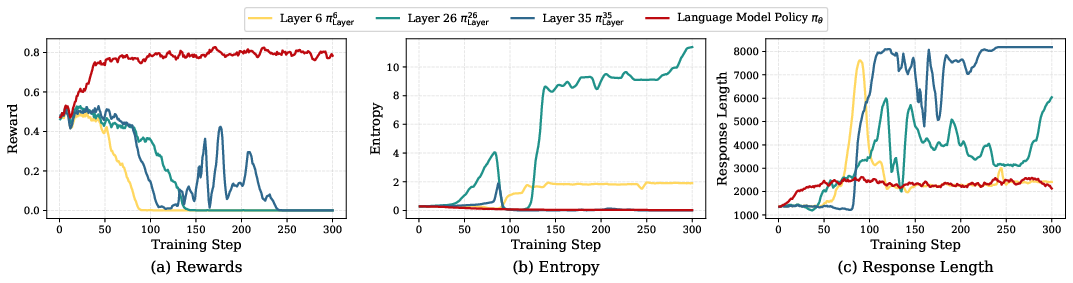
- If you train only internal policies too long, the model can “collapse” (overfit or become unstable).
- But brief, early training of lower layers causes “feature refinement”: lower layers start capturing high-level reasoning signals sooner. This gives upper layers a stronger foundation.
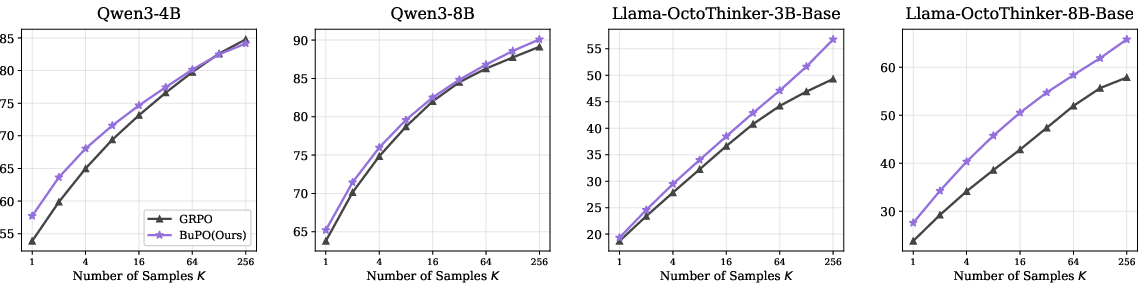
- BuPO works:
- After a short internal-policy phase, switching to normal training improves results on challenging math and reasoning benchmarks (AMC, MATH500, AIME24/25) across multiple models.
- The gains are consistent and sometimes large, showing bottom-up training can guide the model to reason better.
What does this mean for the future?
- Better training strategies: Instead of only coaching the “final decision-maker” layers, BuPO shows that coaching the “junior” layers first can make the whole team better at reasoning.
- Model design insights: The staged reasoning pattern in Qwen3 looks more like human thinking (explore, integrate, converge). Future models might bake in or strengthen such structures.
- Interpretability helps training: By peeking into internal policies and watching entropy, we can design smarter RL algorithms that target the right parts of the model at the right time.
- Practical impact: Stronger reasoning means better performance on tasks like math, logic, and step-by-step problem solving—important for tutors, assistants, and scientific tools.
Overall, this paper suggests a shift in how we think about and train LLMs: treat layers as having their own internal “mini-policies,” understand how their uncertainty changes, and use that knowledge to train from the bottom up. This leads to clearer internal reasoning and better results.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- Theoretical validity of treating softmax(Hl E_uT) as a “policy”: quantify how layer normalization, scaling, and output temperature affect the interpretability and calibration of internal distributions across layers.
- Calibration of modular policies: assess whether softmax(Al E_uT) and softmax(Fl E_uT) meaningfully approximate token distributions given pre-LN architectures and residual scaling; compare against learned per-layer unembedding probes.
- Entropy as a proxy for exploration: disentangle effects of logit scale, temperature, and normalization on entropy/ΔH; evaluate alternative measures (e.g., effective support size, Renyi entropy, margin-based uncertainty).
- Token-position dependence: analyze internal entropy/ΔH across different token positions (early CoT vs final answer tokens) and prompt lengths to verify that patterns are not averaging artifacts.
- Causal tests of the EIC hypothesis: use activation patching/ablation to test whether disrupting FFN middle layers breaks Exploration–Integration–Convergence and degrades reasoning performance.
- Architectural determinants of model differences: isolate which design choices (activation functions, FFN width, attention head count, RoPE scaling, normalization) drive the Qwen vs Llama internal dynamics via controlled ablations on matched training data.
- Formal link between residual cosine similarity and entropy change: derive or empirically validate a quantitative relationship; identify confounders (e.g., residual norm changes due to LN).
- Off-policy InterGRPO correctness: provide convergence guarantees or unbiasedness analysis for using internal-policy importance ratios while sampling from the external policy πθ; characterize bias/variance trade-offs.
- Stability mechanisms for internal policy optimization: develop trust-region constraints, KL penalties to π_layer, or joint objectives to prevent the observed collapse when s_inter is large.
- Automatic layer selection: devise data-driven criteria (e.g., ΔH targets, curvature, gradient sensitivity) to pick which internal layers to optimize, rather than manual selection of “boundary” layers.
- Multi-stage BuPO curricula: explore sequential optimization of multiple layers (e.g., bottom → middle → penultimate), adaptive stopping criteria, and schedules tied to internal metrics (ΔH, similarity to final layer).
- Alternative internal objectives: test optimizing ATT N vs FFN policies, matching desired ΔH trajectories, mutual-information regularization with πθ, or consistency constraints between π_layer and πθ.
- Interaction with standard RLVR regularizers: evaluate BuPO with KL control (β>0), entropy bonuses, DAPO/DCPO/DoG, and length penalties to see if benefits are additive or redundant.
- Comparison to parameter-restriction baselines: benchmark BuPO against lower-layer-only RL finetuning, layer freezing, or LoRA confined to early layers to isolate the value of the bottom-up schedule vs parameter subset effects.
- Generalization beyond math RLVR: test on non-verifiable rewards, instruction following, coding, multi-step tool use, and multi-turn dialogue to assess scope and transferability.
- Model and scale coverage: extend experiments to larger models (≥14B), additional families (Mistral, Gemma), and “thinking-mode” variants; report compute, memory, and wall-clock overheads.
- Robustness to decoding settings: examine whether BuPO’s gains persist under different temperatures, top-p settings, and nucleus/top-k combinations at train and test time.
- Repetition/length pathologies: diagnose and mitigate the repetition and length inflation seen when optimizing penultimate layers (e.g., length normalization, anti-repetition penalties, stop-token shaping).
- Time aggregation choices: clarify how internal entropies are aggregated across sequence positions; compare per-token vs final-token analyses and their effect on conclusions.
- Unembedding tying and output scaling: study the impact of tied vs untied E/E_u and any output logit-scale/gating on internal policy interpretability and entropy comparability.
- Data dependence and OOD robustness: train on diverse datasets beyond DeepMath and evaluate OOD (GSM8K, SAT, Codeforces, multilingual reasoning) to probe robustness and transfer.
- Statistical rigor and reproducibility: report multiple seeds, confidence intervals, and significance tests; release full scripts and exact hyperparameters (including s_inter, η, batch/G) to quantify variance.
- Black-box applicability: explore variants of BuPO for API-only models (e.g., distilling internal-policy targets into adapters or using proxy probes without access to E_u/hidden states).
- Credit assignment with sparse rewards: investigate value functions or token-level credit assignment tailored to internal policies to reduce instability from sparse verifiable rewards.
- Safety, alignment, and calibration effects: measure impacts on toxicity, refusal, hallucination, and probability calibration to ensure internal optimization does not degrade safety or trustworthiness.
- Catastrophic forgetting and capability balance: assess whether early-layer alignment harms non-reasoning skills (e.g., translation, factual QA) and develop regularizers to prevent negative transfer.
- Hyperparameter sensitivity: systematically map performance vs s_inter, learning rate, rollout group size, and layer choice; derive practical guidelines for selecting these settings.
- Compute efficiency: profile the cost of computing internal distributions per token/layer; develop approximations (e.g., low-rank E_u, caching, top-k logits) that keep BuPO practical at scale.
- Mechanistic circuit identification: localize neurons/heads contributing to EIC; test targeted optimization of those components to see if it outperforms layer-wide objectives.
Practical Applications
Immediate Applications
The following applications can be deployed with current open-source LLMs, RLVR pipelines, and standard ML tooling.
- BuPO training schedule for RLVR (software/AI)
- What: Adopt Bottom-up Policy Optimization by optimizing an internal layer policy for a short early phase (e.g., s_inter ≈ 20–30 steps on Qwen3), then switch to standard RL (e.g., GRPO/PPO).
- Tools/Workflow: verl-based RL training; InterGRPO importance ratios on π_Layerl; select layer l with positive FFN ΔH; monitor entropy and PPL to avoid collapse; reward via verifiable tasks (math/code).
- Assumptions/Dependencies: Access to hidden states and unembedding matrix; open-weight models (e.g., Qwen, Llama); verifiable reward datasets; careful choice of s_inter to prevent instability.
- Internal Policy Lens for diagnostics and interpretability (software/AI safety, MLOps)
- What: Compute π_Layerl and π_Modulel, their entropy H and entropy change ΔH across layers/modules; visualize residual cosine similarity; identify Exploration–Integration–Convergence (EIC) regions.
- Tools/Workflow: PyTorch hooks for hidden states; “logit lens” with unembedding; dashboards integrated into training loops; alerts on entropy collapse or anomalous spikes.
- Assumptions/Dependencies: Need internal access to model layers; additional compute overhead during training/inference.
- Model selection and procurement by internal reasoning pattern (industry/ML platform teams)
- What: Choose base models whose internal entropy dynamics match task needs (e.g., Qwen3’s progressive EIC for math/coding vs. Llama’s late collapse).
- Tools/Workflow: Lightweight benchmark to profile H and ΔH on a sample of target tasks before committing to a base model.
- Assumptions/Dependencies: Patterns may vary by domain; validation on your task distribution recommended.
- Training monitoring, early stopping, and schedule control (MLOps)
- What: Use entropy trends and PPL spikes as early-warning signals for over-optimization (e.g., collapse after too many internal-policy steps); auto-adjust s_inter or stop training.
- Tools/Workflow: Callbacks that log H, ΔH, response-length distribution, and repetition metrics; automated schedule controllers.
- Assumptions/Dependencies: Correlation between entropy dynamics and downstream quality holds in your domain.
- Layer-targeted fine-tuning to reduce cost (software/AI)
- What: Apply LoRA/adapters primarily to EIC-critical FFN layers (e.g., lower-layer exploration and middle-layer integration), freeze others to save compute while preserving gains.
- Tools/Workflow: Per-layer adapter placement guided by ΔH patterns; small-batch RLVR or SFT refresh.
- Assumptions/Dependencies: Needs per-architecture mapping of EIC boundaries; some tasks may require broader updates.
- Dynamic inference with depth gating and early exit (inference infra, energy/cost)
- What: Stop forward passes once an internal layer’s policy entropy is near-zero; allocate more depth when ΔH indicates ongoing exploration.
- Tools/Workflow: Threshold-based gating integrated with vLLM or custom inference engines; per-token or per-step checks.
- Assumptions/Dependencies: Access to intermediate activations at inference; careful calibration to avoid quality loss.
- Data curriculum for RLVR by EIC stage (data engineering)
- What: Stage training data to encourage exploration (lower layers), knowledge integration (middle layers), and convergence (upper layers), aligned with BuPO’s early phase.
- Tools/Workflow: Tag datasets by difficulty/structure; schedule samples to match layer-optimization phases.
- Assumptions/Dependencies: Requires metadata on task difficulty/structure; empirical validation for your domain.
- Mitigating repetition and length issues in RL (product QA)
- What: Detect and mitigate repetition/overlong outputs by monitoring penultimate-layer optimization effects and entropy overshoots; add length/repetition penalties and schedule constraints.
- Tools/Workflow: Response-length histograms; entropy-based guardrails; decoding-time repetition penalties.
- Assumptions/Dependencies: Penultimate-layer tuning risks known (paper observed repetition); combine with decoding controls.
- Knowledge distillation from internal policies (model compression)
- What: Distill π_Layerl distributions (not just final logits) into smaller or shallower models to transfer progressive reasoning features.
- Tools/Workflow: KD losses between internal policy logits; multi-layer teachers from EIC-localized layers.
- Assumptions/Dependencies: Student must expose analogous layers or auxiliary heads; compute overhead for internal-KD.
- Research benchmarks and academic analysis (academia)
- What: Create benchmarks and metrics (H, ΔH, residual cosine similarity) to evaluate progressive reasoning and track changes after RLHF/RLVR.
- Tools/Workflow: Public leaderboards reporting internal-policy metrics alongside Pass@K.
- Assumptions/Dependencies: Community buy-in and standardized measurement protocols.
- Post-RL quality regression checks (software QA)
- What: Use residual cosine similarity and ΔH signatures to detect module-function drift after RLHF/RLVR updates.
- Tools/Workflow: Baseline vs. post-training internal-policy diffs; alert on large deviations in EIC structure.
- Assumptions/Dependencies: Requires pre-training baselines and stable measurement pipelines.
Long-Term Applications
These applications likely require further research, integration with hardware/closed models, or broader ecosystem standards before widespread deployment.
- RLHF/RLVR with internal-policy constraints (AI safety)
- What: Add regularizers to keep entropy dynamics within safe/healthy envelopes (avoid collapse; preserve EIC shape) to reduce mode collapse and brittle reasoning.
- Tools/Workflow: Multi-objective RL with constraints on H/ΔH profiles; layer-wise penalties.
- Assumptions/Dependencies: Robust causal links between entropy profiles and quality/safety; tuning without harming performance.
- Standardized internal metrics for audits and governance (policy/compliance)
- What: Establish reporting standards for internal-policy diagnostics (entropy curves, ΔH by module) as part of capability and safety audits.
- Tools/Workflow: Third-party evaluation suites; regulatory templates.
- Assumptions/Dependencies: Regulatory consensus; vendors providing internal-access or verifiable surrogates.
- Cross-model transfer by internal-policy alignment (model development)
- What: Align EIC-phase policies between different architectures to transfer reasoning structure, enabling efficient post-training or model merging.
- Tools/Workflow: Multi-teacher distillation or CCA/Procrustes alignment across layers; shared internal-policy heads.
- Assumptions/Dependencies: Stable layer-wise correspondences; IP constraints across vendors.
- Adaptive compute and hardware co-design (hardware/energy)
- What: Hardware and runtimes that can read intermediate states cheaply to implement entropy-based depth gating and per-token compute scaling.
- Tools/Workflow: Accelerator primitives for mid-layer taps; compiler/runtime support.
- Assumptions/Dependencies: Vendor support; latency overheads must be minimal to justify savings.
- Continual learning with EIC preservation (AI maintenance)
- What: Use internal-policy profiles as invariants to prevent catastrophic forgetting during domain updates; enforce EIC shape.
- Tools/Workflow: Replay + EIC-profile regularization; selective layer updates guided by ΔH.
- Assumptions/Dependencies: Generalizes across domains; avoids over-constraining plasticity.
- Tool-using agents gated by internal entropy (agentic systems, software automation)
- What: Trigger tool calls (search, solver) when ΔH indicates stalled integration or persistent exploration; skip when confident convergence is detected.
- Tools/Workflow: Entropy-gated tool routers; chain-of-thought checkpointing tied to EIC phases.
- Assumptions/Dependencies: Reliable mapping between ΔH signals and tool utility; guard against adversarial prompts.
- Multimodal extension of internal-policy optimization (robotics, vision-language)
- What: Apply EIC-guided internal-policy training to VLMs/robotics transformers for better planning and grounded reasoning.
- Tools/Workflow: Multimodal unembedding heads; RL with verifiable simulators and sensors.
- Assumptions/Dependencies: Well-defined verifiable rewards; access to multimodal internals; safety validation.
- Safety-critical decision support with progressive reasoning (healthcare, finance)
- What: Deploy models that exhibit and can report staged reasoning (exploration, integration, convergence) for traceability and oversight.
- Tools/Workflow: Layer-wise confidence reports; clinician/analyst UIs mapping stages to evidence.
- Assumptions/Dependencies: Rigorous clinical/compliance evaluation; explainability that is faithful and calibrated.
- Distribution-shift and robustness monitoring (MLOps)
- What: Use deviations in internal entropy profiles and residual write patterns as early indicators of domain shift or policy drift in production.
- Tools/Workflow: Canary jobs logging H/ΔH time series; drift detectors with alerts.
- Assumptions/Dependencies: Stable baselines; low false-positive rates.
- Federated or on-device internal-layer tuning (edge, mobile)
- What: Run short s_inter internal-policy updates on-device to adapt foundational reasoning locally with minimal compute/data movement.
- Tools/Workflow: Partial-layer adapters; privacy-preserving RLVR with small verifiable tasks.
- Assumptions/Dependencies: Sufficient on-device acceleration; careful safety constraints.
- AutoML for BuPO hyperparameters (AutoML)
- What: Automatically select layer l and s_inter via Bayesian optimization or bandit controllers using online H/ΔH/PPL signals.
- Tools/Workflow: Closed-loop schedulers; multi-objective optimization balancing reward and stability.
- Assumptions/Dependencies: Robust online metrics; safe exploration in production.
- Educational technology with metacognitive scaffolding (education)
- What: Tutors that mirror EIC stages to teach problem-solving: encourage exploration, prompt knowledge integration, and guide convergence.
- Tools/Workflow: Stage-aware feedback; visible “reasoning stage” indicators for learners.
- Assumptions/Dependencies: Validated pedagogical benefits; alignment between internal signals and student-facing explanations.
Notes on Assumptions and Dependencies (cross-cutting)
- Access to internals: Most applications require access to hidden states and unembedding matrices; closed APIs may not support this without vendor cooperation.
- Generality: Entropy dynamics shown for Qwen and Llama; validate on other architectures and domains before broad use.
- Stability vs. collapse: Internal-policy optimization is powerful but fragile—moderate early-stage steps are critical; monitor PPL, entropy, and output pathologies (repetition).
- Compute/latency: Internal probing adds overhead; ensure gains outweigh costs, especially at inference.
- Reward design: RLVR assumes verifiable rewards; porting to domains without clear verifiers will need proxies or human feedback.
- Safety and compliance: For regulated sectors, extensive validation is required; internal metrics should complement, not replace, outcome-based evaluations.
Glossary
- Advantage: In reinforcement learning, the advantage function quantifies how much better an action is compared to a baseline, guiding policy gradient updates. "estimates advantages as :"
- Bottom-up Policy Optimization (BuPO): A training paradigm that first optimizes internal layer policies and then the overall LLM policy to enhance reasoning. "we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training."
- Decoder-only Transformer: A Transformer architecture composed solely of decoder blocks for autoregressive generation. "A decoder-only Transformer consists of stacked layers, each containing a multi-head self-attention (MHSA) module and a feed-forward network (FFN) module."
- Entropy Change (): The difference in entropy between a module’s output and input distributions, measuring change in uncertainty. "we introduce Entropy Change, which measures the incremental information gain within a single internal policy and is defined as:"
- Entropy regularization: An RL technique that adds an entropy term to the objective to encourage exploration by preventing premature policy collapse. "entropy regularization~\cite{cui2025entropy, yu2025dapo, yang2025dcpo}."
- Exploration–Integration–Convergence (EIC): A staged reasoning pattern where lower layers explore, middle layers integrate knowledge, and upper layers converge to predictions. "This “Exploration–Integration–Convergence” (EIC) pattern is more consistently expressed in Qwen3 than in earlier Qwen2.5 variants"
- Feed-forward network (FFN): The per-layer MLP submodule in Transformers that transforms representations and often stores parametric knowledge. "the feed-forward network (FFN) module." / "the FFN module is widely regarded as the key-value memories of parametric knowledge in Transformers"
- GRPO (Group Relative Policy Optimization): A policy optimization algorithm that samples groups of responses and uses normalized advantages with clipping. "We adopt GRPO~\citep{shao2024deepseekmath}, which samples a group of responses per question and estimates advantages as ..."
- Importance ratio: The ratio between new and old policy probabilities for an action, used in off-policy corrections and clipping. "where $r_{i,t}=\frac{\pi_\theta(o_{i,t}|s_{i,t})}{\pi_{\theta_\text{old}(o_{i,t}|s_{i,t})}$ is the importance ratio."
- Internal Layer Policy: A policy derived by mapping hidden states at a specific layer to token probabilities via the unembedding matrix. "Internal Layer Policy refers to utilize hidden states from each layer to combine with "
- Internal Modular Policy: A policy formed by mapping module outputs (attention or FFN) at a layer to token probabilities via the unembedding matrix. "Internal Modular Policy integrates with hidden states from specific module:"
- Internal Policy Entropy: The entropy of an internal policy’s token distribution, used to characterize exploration vs. convergence. "We define Internal Policy Entropy as:"
- Knowledge neurons: Neurons in FFN layers hypothesized to store factual or parametric knowledge. "encoded in knowledge neurons~\citep{dai2022knowledge}."
- Kullback–Leibler divergence (KL divergence): A measure of difference between two probability distributions, commonly used to regularize RL policies against a reference. "$- \beta \mathbb{D}_{KL}[\pi_\theta(\cdot|\mathbf{q})) || \pi_{\text{ref}(\cdot|\mathbf{q})]\right]$"
- Layer normalization (LN): A normalization technique applied within layers to stabilize training and representations. "where denotes layer normalization"
- Logit lens: An interpretability technique that decodes intermediate hidden states into vocabulary logits using the unembedding matrix. "The logit lens~\citep{nostalgebraist2020logitlens} framework offers initial insights by employing the unembedding matrix to decode intermediate layer representations into the token space."
- Markov Decision Process (MDP): A formal framework for sequential decision making comprising states, actions, transitions, and rewards. "LLM generation can be formulated as a token-level Markov Decision Process (MDP)."
- MHSA (Multi-head self-attention): A Transformer mechanism that computes attention over multiple heads to integrate contextual information. "a multi-head self-attention (MHSA) module"
- Parametric knowledge: Knowledge encoded directly in the model’s parameters rather than in-context. "FFN module is widely regarded as the key-value memories of parametric knowledge in Transformers"
- Pass@K: An evaluation metric estimating the probability that at least one of K sampled completions is correct. "We report Avg@ (Pass@1 averaged over outputs)."
- Perplexity (PPL): A language modeling metric reflecting the model’s uncertainty or fit to the data; lower is better. "the PPL trajectory in Figure~\ref{fig:analysis_combined}(c) reveals a clear trade-off"
- Proximal Policy Optimization (PPO): A widely used RL algorithm that performs clipped policy updates for stable training. "including GRPO, PPO~\citep{sutton1998reinforcement}, Reinforce++~\citep{hu2025reinforce++} and RLOO~\citep{ahmadian2024back}."
- Residual connections: Additive skip connections that accumulate outputs across layers, enabling gradient flow and compositional representations. "Due to residual connections in Transformer layers, the input to any sub-module (attention or FFN) equals the sum of all preceding outputs plus the original embedding."
- Residual cosine similarity: A measure of alignment between module outputs and the residual stream to characterize write-in behavior. "we analyze residual cosine similarity, which quantifies how each module writes to the residual pathway"
- Residual stream: The running sum of representations passed through residual connections across Transformer layers. "(a): The residual stream within Transformer which moves from previous layer hidden states into self-attention and feed-forward network (FFN) sequentially."
- Reinforce++: A reinforcement learning baseline algorithm used for LLM training and comparison. "including GRPO, PPO~\citep{sutton1998reinforcement}, Reinforce++~\citep{hu2025reinforce++} and RLOO~\citep{ahmadian2024back}."
- Reinforcement Learning from Human Feedback (RLHF): An RL paradigm that aligns model behavior with human preferences via feedback-driven rewards. "Reinforcement Learning from Human Feedback (RLHF)"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm that provides rule-based, verifiable signals to improve reasoning in LLMs. "reinforcement learning with verifiable rewards (RLVR)"
- RLOO: A reinforcement learning baseline using a leave-one-out estimator for variance reduction in policy gradients. "including GRPO, PPO~\citep{sutton1998reinforcement}, Reinforce++~\citep{hu2025reinforce++} and RLOO~\citep{ahmadian2024back}."
- Softmax: A normalization function converting logits into a probability distribution over the vocabulary. "$\mathbf{P} = \text{softmax}(LN(\mathbf{H}^{(2L)})\mathbf{E}_{\text{u}^\text{T})$"
- Unembedding matrix: The linear mapping from hidden representations to vocabulary logits, used to decode internal states. "the unembedding matrix "
- vLLM: A high-throughput inference engine for LLMs enabling efficient evaluation. "We use vLLM~\citep{kwon2023efficient} with temperature 1.0 and top_p 1.0."
Collections
Sign up for free to add this paper to one or more collections.

