S-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence
Abstract: Real-world spatial intelligence requires reasoning over a continuous and evolving 3D world, yet existing VLMs and tool-augmented agents largely remain tied to static, stateless inference from isolated visual observations. We introduce \textbf{\textsc{S-Agent}}, a spatial tool-use agentic paradigm for understanding and reasoning over continuous multi-view images and videos. By formulating spatial reasoning as spatio-temporal evidence accumulation rather than isolated frame-level prediction, \textsc{S-Agent} reshapes spatial perception into scene-centric understanding beyond frame-centric recognition. Specifically, \textsc{S-Agent} casts the VLM as a semantic planner that decides what evidence is needed, while a hierarchy of spatial tools and experts grounds objects in 2D, lifts them into 3D geometric evidence, and aggregates this evidence into high-level spatial knowledge (\textit{e.g.}, counting, measurement, orientation, and relative position). Additionally, a temporal memory mechanism, including Scene Memory for maintaining the evolving scene state and Agent Memory for accumulating reasoning context, enables evidence integration across frames and reasoning steps. Comprehensive experiments on multi-view and video spatial reasoning benchmarks show that \textsc{S-Agent} consistently improves both open-source and closed-source VLMs in a training-free manner. Beyond inference-time augmentation, supervised fine-tuning (SFT) on \textsc{S-Agent}-generated spatial trajectories \textsc{S-300K} yields \textsc{S-Agent-8B}, a compact spatial agent that significantly surpasses similar-scale baselines (e.g., Qwen3-VL-8B) and performs comparably to advanced closed-source models (e.g., GPT-5.4 and Gemini 3).


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
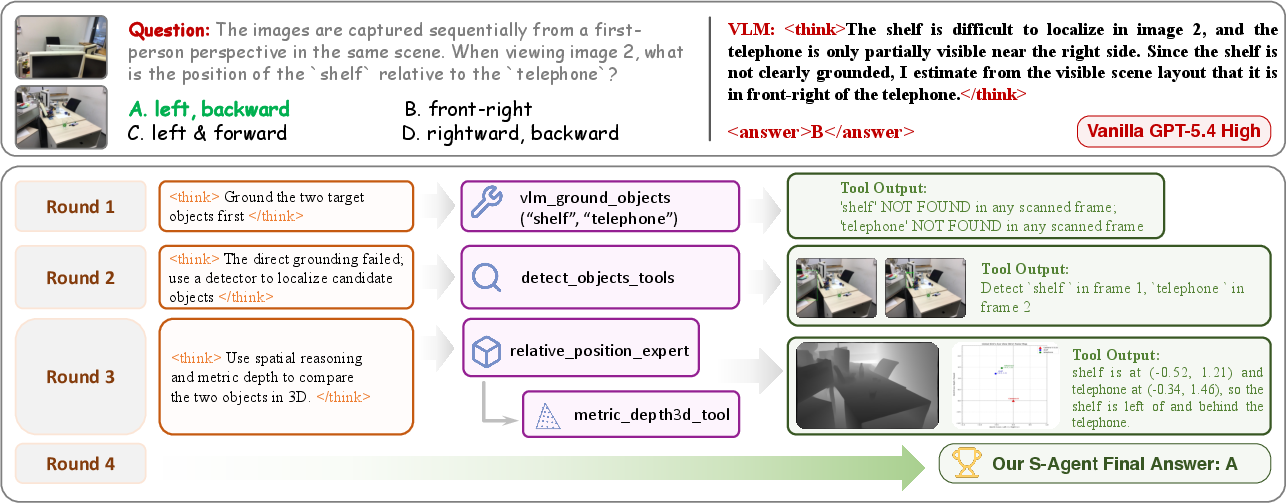
This paper introduces S-Agent, a new way for AI to understand space in the real world using photos and videos. Instead of guessing from a single picture, S-Agent acts like a careful detective: it looks at scenes from different angles and over time, collects clues, builds a 3D understanding, and then answers questions like “Where is the phone relative to the shelf?” or “How far apart are these objects?”
Goals and Key Questions
The researchers wanted to solve a common problem: many AIs are good at naming things in images, but they struggle with true “spatial intelligence” — understanding 3D positions, distances, directions, and how things move or change over time. They asked:
- How can an AI combine clues from multiple views and video frames to understand a 3D scene, not just flat pictures?
- Can an AI plan what evidence it needs (like a detective choosing which clue to gather next)?
- Will using special tools (for detecting objects, measuring depth, counting, etc.) and keeping memory of what it already saw help it reason better?
- Can we train a smaller, faster AI to copy these smart behaviors?
How S-Agent Works (in everyday terms)
Think of S-Agent as a team with a planner, a toolbox, and two notebooks.
- The planner (a Vision-LLM, or VLM) is like the team leader. It reads the question, looks at the images/video, and decides what clue to gather next.
- The toolbox holds different “spatial tools” that do specific jobs.
- The notebooks (memories) keep track of what the team has already learned and tried, so it doesn’t repeat itself or forget important clues.
The Toolbox: Three Levels of Tools
S-Agent uses tools in three stages, from simple to advanced. This is like starting with a magnifying glass, then building a 3D model, then doing measurements on that model.
- Level 1: 2D visual clues (basic spotting)
- What it does: picks useful frames, finds objects in images, and marks regions of interest.
- Analogy: circling items in a photo that matter to the question.
- Level 2: 3D lifting (turning flat clues into 3D)
- What it does: uses multiple views to estimate depth, camera angles, and positions, so 2D sightings become 3D points.
- Analogy: taking several photos of a room and using them to build a rough 3D map.
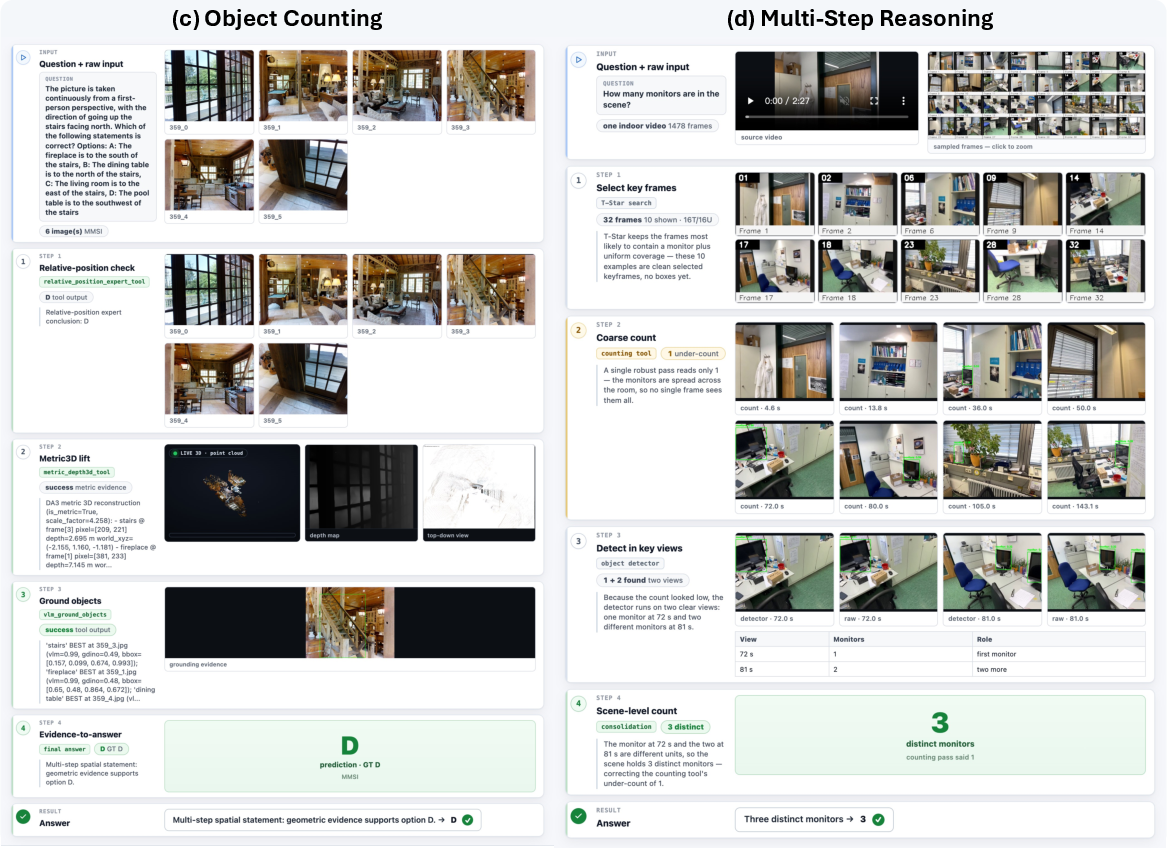
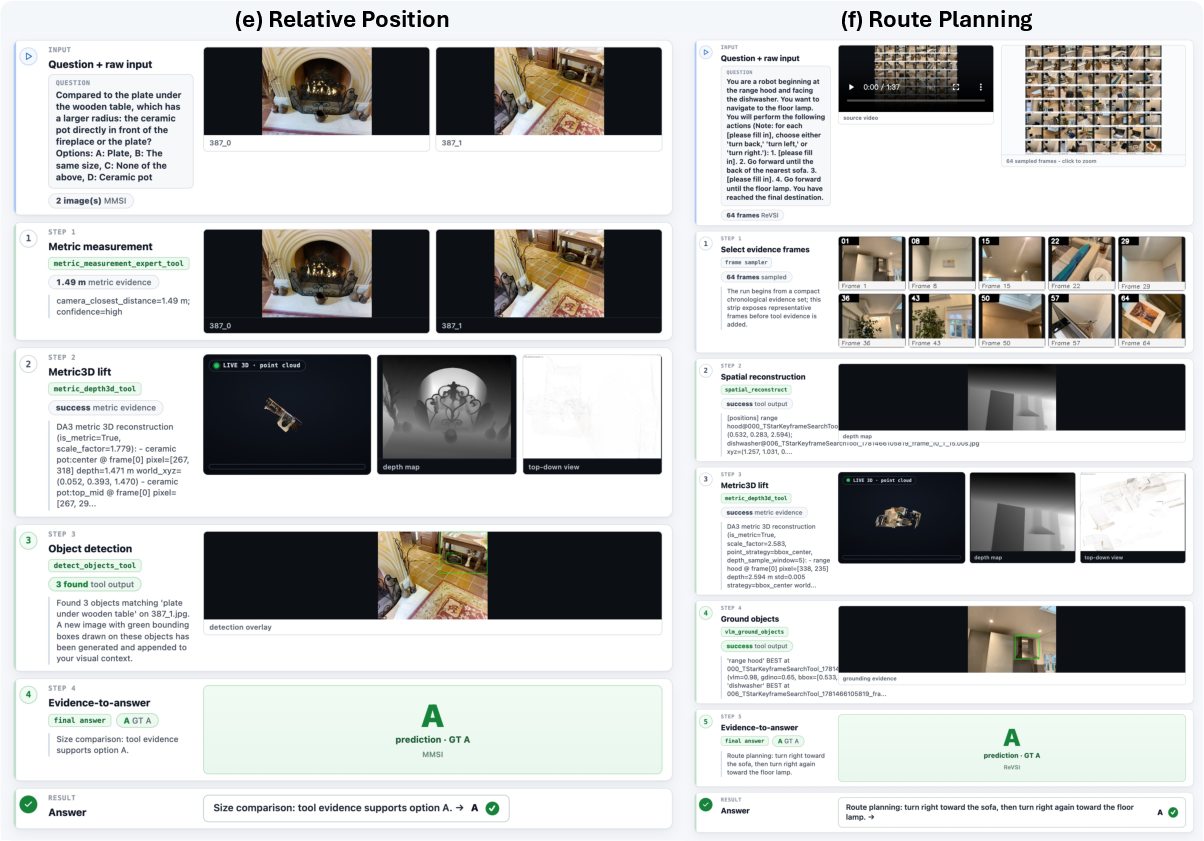
- Level 3: Spatial experts (answer-focused calculations)
- What it does: uses the 3D map to count objects, measure distances, find directions (left/right/behind), or compare sizes.
- Analogy: pulling out a tape measure, compass, or top-down map to get exact answers.
The Two Notebooks (Memories)
S-Agent keeps two kinds of memory so it can reason over time and across views:
- Scene Memory
- What it stores: the “state” of the scene — which objects were found, where they are, how they were seen in different frames, and any computed facts (like “object A is behind object B”).
- Why it helps: it avoids double-counting and keeps object identities consistent, even when the camera moves.
- Agent Memory
- What it stores: the reasoning process — what tools were used, what worked or failed, and the planner’s intermediate thoughts.
- Why it helps: the planner learns from its own attempts, avoids repeating steps, and knows what evidence is still missing.
Putting it all together
For each question, the planner:
- Chooses which tool to call next (e.g., “find the shelf,” “get depth here,” “measure distance”).
- Updates the memories with the new clues.
- Repeats until it has enough evidence to answer confidently.
This turns “guessing from a single frame” into “collecting and combining evidence over time.”
Main Findings and Why They Matter
The team tested S-Agent on several benchmarks that check spatial reasoning across multiple images and videos:
- MMSI-Bench (multi-image scenes, directions, sizes, motion, multi-step reasoning)
- ViewSpatial-Bench (viewpoint-aware tasks like camera vs. person perspective directions)
- ReVSI (video-based spatial reasoning: counting, distances, directions, route planning)
Key results:
- Training-free boost: Just by adding S-Agent’s tool-use and memory (no extra training), existing AIs got consistently better at spatial questions. For example, S-Agent improved over a strong commercial model on MMSI-Bench by 4.5 percentage points and achieved 60.0% on ViewSpatial-Bench, a large jump over a strong baseline.
- Strong at motion and perspective: S-Agent did especially well on tasks needing multi-step thinking, camera motion understanding, and perspective-dependent directions — places where a single image often misleads.
- Teaching a smaller model: The researchers recorded S-Agent’s step-by-step “trajectories” (the planner’s decisions, tool results, and final answers) to create a dataset called S-300K. Using this, they fine-tuned a compact 8-billion-parameter model, S-Agent-8B, which significantly outperformed a similar-sized baseline model and got close to advanced commercial systems on several benchmarks.
Why this matters:
- It shows that “collect evidence over time” beats “guess from one frame” for real-world spatial understanding.
- It proves that smaller, open models can learn these skills by imitating smart, tool-using reasoning.
Implications and Impact
- Better robots and AR/VR: Robots, self-driving cars, and AR/VR systems need reliable 3D understanding of the world. S-Agent’s approach — plan, gather evidence, remember, and measure — makes AI more trustworthy and accurate in these tasks.
- Smarter AI reasoning: Instead of cramming everything into a single prediction step, AIs can act like investigators: plan what to look for, use the right tools, and keep track of what they’ve learned.
- Scalable training: By recording its own “reasoning stories” (trajectories), S-Agent can teach smaller models to do complex spatial reasoning, making strong performance available without giant, expensive models.
In short, S-Agent turns spatial reasoning into a careful, step-by-step process of gathering and combining clues across views and time. This makes AI much better at understanding the 3D world — a key step toward AI that can safely and helpfully operate in our everyday environments.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions that remain unresolved in the paper.
- Missing runtime, latency, and cost analysis of tool-invocation and memory operations, making it unclear whether S-Agent can meet real-time constraints for robotics, AR/VR, or on-device deployment.
- No characterization of computational footprint (GPU/CPU usage, memory growth) as video length and number of views increase; scalability limits for long sequences and large scenes are unspecified.
- Unclear camera calibration assumptions and 3D lifting reliability: the paper does not detail how camera poses are estimated, validated, or how errors in depth/pose propagate to final answers.
- Lack of quantitative evaluation of geometric accuracy for recovered 3D evidence (e.g., error bounds for distances, orientations, positions) and its impact on downstream reasoning.
- Tool failure handling is under-specified: there is no formal strategy for detecting unreliable tool outputs, recovering from failures, or selectively distrusting noisy evidence.
- Entity identity resolution and data association in Scene Memory are not formalized (e.g., multi-object tracking, occlusion handling, re-identification), leaving ambiguity on how repeated detections are robustly linked across frames.
- Memory management policies (e.g., pruning, compression, forgetting, conflict resolution) are not described; it is unclear how S-Agent prevents memory bloat or resolves contradictory observations.
- Termination criteria for the evidence accumulation process are not formalized; no uncertainty or confidence thresholds are provided to decide when to stop requesting more evidence.
- No systematic method to quantify or propagate uncertainty from tools (depth, detectors, pose estimators) into the planner’s decisions or final answers.
- Tool-selection policy learning remains unexplored: the paper uses zero-shot planning or SFT, but does not compare reinforcement learning, cost-aware scheduling, or active planning strategies to optimize tool use.
- Level-2 3D evidence is reported to be noisy and of limited standalone usefulness, yet the paper does not investigate which 3D representations or denoising strategies make this evidence more consumable for planners.
- The design and internal algorithms of Level-3 spatial experts (e.g., counting, measurement, orientation, relative position) are not detailed; their failure modes, accuracy, and calibration are untested against ground-truth geometry.
- Conflict resolution across heterogeneous tools and views (e.g., inconsistent measurements, contradictory relations) is not specified, raising questions about robustness in multi-source evidence aggregation.
- S-300K distillation dataset construction may propagate teacher biases and errors; the paper lacks an analysis of error inheritance, diversity coverage, and potential overfitting to teacher-specific tool-use patterns.
- Limited robustness evaluation: there is no study on domain shifts (indoor → outdoor, low light, clutter), sensor variations (RGB-D, fisheye), or adversarial conditions (motion blur, occlusion, distractors).
- Generalization to embodied tasks is untested: the framework claims relevance for robotics and AR/VR, but there are no experiments with active control, spatial decision-making under actuation constraints, or interaction loops.
- Reproducibility risks due to dependence on closed-source planners (GPT-5.x, Gemini): sensitivity to API versions, prompt changes, and rate limits is not quantified.
- The ablation studies are restricted to one benchmark (ViewSpatial) and one planner (GPT-5.4); cross-benchmark, cross-planner ablations and per-tool/expert component analyses are missing.
- Lack of interpretability of intermediate representations: the schema for memory entries, evidence provenance, and reasoning trace inspection is not standardized for debugging or auditing.
- No human evaluation or statistical significance testing of benchmark improvements; the paper does not report variance, confidence intervals, or robustness across multiple random seeds/rollouts.
- Evaluation coverage gaps: benchmarks emphasize specific spatial tasks but omit physically calibrated measurements with ground-truth units, large outdoor scenes, and multi-agent scenarios.
- Limited discussion of ethical and resource considerations (compute cost, energy use, API expenses), which are important for practical deployment.
- Open question: can end-to-end differentiable integration of 3D modules (depth/pose/BEV) with the planner reduce reliance on brittle tool interfaces and improve learning from raw geometry?
- Open question: how to incorporate explicit uncertainty-aware planning (e.g., Bayesian evidence accumulation, POMDP formulations) to decide when and what evidence to acquire next?
- Open question: can S-Agent learn active viewpoint selection or camera control policies to acquire missing evidence rather than passively consuming provided views?
Practical Applications
Below is an overview of practical applications enabled by the paper’s findings and innovations. Each item links the S-Agent paradigm (VLM planner + hierarchical spatial tools + scene/agent memories + trajectory distillation into S-Agent-8B) to concrete use cases, suggested products/workflows, sectors, and feasibility notes.
Immediate Applications
- Robotics (warehousing, service robots, inspection)
- What: Deploy S-Agent as a perception-and-reasoning “copilot” to improve object grounding, counting, simple measurements, and perspective-aware instructions from multi-camera or video feeds.
- Example workflows/products:
- “S-Agent for ROS2”: a microservice that ingests robot video streams, calls 2D grounding (e.g., open-vocabulary detection), depth/pose tools, and Level-3 experts (counting, relative direction), stores evidence in Scene Memory, and returns metrics/bounding boxes in robot/world frame for downstream planning (MoveIt/Nav2).
- QA copilot for mobile inspection robots that accumulates evidence across frames to verify “Are all bolts present?” or “Is the valve left of the pipe junction?”
- Dependencies/assumptions: Requires reliable camera calibration or on-the-fly pose/depth estimation, GPU for real-time tool calls, stable open-vocab detectors/segmentation, and integration with robot control stacks. Use in non-safety-critical “advise/assist” roles is advisable in the near term.
- Retail and Manufacturing QA
- What: Shelf/stock compliance checks, assembly verification, and parts counting across multi-view cameras with reduced double-counting via Scene Memory.
- Example workflows/products:
- “PlanogramCheck” service: aggregates multi-view evidence to count SKUs, detect missing items, and check spatial placement rules (e.g., “is brand A on the top-left of bay 3?”).
- Assembly-cell auditor: from multi-camera footage, measure clearances, count fasteners, and verify parts’ relative orientation.
- Dependencies/assumptions: Camera synchronization or timestamping; periodic re-calibration; tolerance for approximate measurements; privacy/compliance for human-in-view scenes.
- AEC/Construction/Real Estate and Insurance
- What: Video-based measurements and spatial QA for rooms, fixtures, or damage assessment using Level-3 experts for measurement and relative location.
- Example workflows/products:
- Drone/site inspection assistant: stitches multi-view imagery (Level-2 lifting) and returns counts and metric distances (e.g., “How many rebar bundles on level 2?”, “Distance from beam A to column C”).
- Claims adjuster toolkit: from walk-through videos, estimate room sizes, locate damage relative to reference points, and output annotated evidence trail for audit.
- Dependencies/assumptions: Accuracy depends on pose/depth quality; best with known camera intrinsics or smartphone AR frameworks (ARKit/ARCore) for metric scale; regulated settings may require human validation.
- AR/VR and Mobile Measurement
- What: Perspective-aware guidance and measurement overlays for consumer or enterprise tasks (e.g., furniture placement, interior layout).
- Example workflows/products:
- “Measure-Assist” app: uses phone video + AR depth to answer “distance from couch to TV” or “is the lamp to the left of the bookshelf?” while maintaining stable anchors over multiple views via Scene Memory.
- Dependencies/assumptions: Access to device depth/pose (ARKit/ARCore) improves reliability; inference can run on-device (with S-Agent-8B) or on edge/cloud.
- Video Analytics (sports, traffic, operations centers)
- What: Evidence-accumulating QA across cameras for counting, relative orientations, route/path analysis (leveraging strong gains in relative direction and route planning tasks).
- Example workflows/products:
- “Spatial QA Console”: operators ask natural language questions (“Which player moved behind defender X?”), system returns BEV overlays and intermediate evidence from Agent Memory.
- Dependencies/assumptions: Multi-camera synchronization; privacy compliance; acceptable latency for operator-in-the-loop use.
- Software/AI Development Tools
- What: Provide S-Agent as a training-free augmentation layer for existing VLMs or as an open-weight distilled model (S-Agent-8B) for on-prem deployments.
- Example workflows/products:
- “Spatial Toolchain SDK”: LangChain-/Ray- compatible wrappers for Level-1/2/3 tools, Scene/Agent Memory stores, and serialization of tool-use trajectories for debugging and audits.
- “Agent Trace Explorer”: visualize stored Scene Memory entities and Agent Memory steps for explainability and iteration.
- Dependencies/assumptions: Stable tool APIs (depth, pose, detection); reproducible memory serialization; governance for logging sensitive visual data.
- Education and Research
- What: Use S-Agent trajectories and S-300K to teach spatial reasoning, tool-use planning, and explainable, evidence-grounded analysis.
- Example workflows/products:
- “Spatial Reasoning Tutor”: step-by-step examples and exercises that show queries → tool calls → accumulated evidence → answer.
- Academic baselines: re-usable pipeline for stateful multi-view/video spatial benchmarks, and fine-tuning templates for smaller campus-friendly models.
- Dependencies/assumptions: Licensing/availability of training corpora; compute for SFT; clear separation of training/evaluation datasets for fair benchmarking.
- Media and Game Production
- What: Camera continuity and scene consistency checks across shots, including actor/object placement and relative directions.
- Example workflows/products:
- “ContinuityCheck”: accumulate scene entities and spatial facts to flag continuity errors (e.g., prop orientation flips across cuts).
- Dependencies/assumptions: High-quality multi-view inputs; tool tuning for specific cinematography conventions.
Long-Term Applications
- Closed-loop Autonomous Systems (autonomous driving, household robotics)
- What: Integrate S-Agent’s stateful spatial reasoning into perception–planning–control loops for robust, long-horizon tasks (e.g., navigation under occlusions, complex manipulation).
- Potential products/workflows:
- “Semantic-SLAM++”: fuse Scene Memory with SLAM to maintain lifelong, task-conditioned 3D knowledge; use Level-3 experts for task-relevant metrics feeding planners.
- Dependencies/assumptions: Stronger real-time guarantees; tight integration with control safety; rigorous validation; regulatory approval for safety-critical domains.
- Surgical and Clinical Assistance (healthcare)
- What: Intra-operative video reasoning to track instruments, measure distances to anatomy, or check left/right orientation and approach angles.
- Potential products/workflows:
- “OR Spatial Copilot”: tool-grounded annotations and measurements across laparoscopic/endoscopic video to assist surgical navigation and training.
- Dependencies/assumptions: Domain-specific detectors/segmentation; strict latency and reliability requirements; clinical trials and regulatory clearance; robust sterilized hardware integration.
- City-Scale Multi-Camera Reasoning (public safety, traffic management)
- What: Cross-camera event understanding with persistent identities and spatial relations (e.g., vehicle path reconstruction across intersections).
- Potential products/workflows:
- “Urban Spatial Twin”: aggregate multi-source feeds into a dynamic, queryable scene memory (privacy-preserving and audit-ready).
- Dependencies/assumptions: Privacy-by-design, anonymization; scalable storage/compute; governance and legal frameworks for surveillance data.
- AR Glasses and On-Device Spatial Assistants
- What: Persistent, on-device S-Agent variants for real-time, hands-free guidance (maintenance, assembly, navigation).
- Potential products/workflows:
- “Heads-up Spatial Guide”: continuous evidence accumulation across sessions, 3D-anchored instructions, and memory of previously found parts/steps.
- Dependencies/assumptions: Further model compression beyond 8B; on-chip acceleration; energy constraints; reliable egocentric pose.
- Digital Twins and BIM Compliance Automation
- What: Automatically reconcile as-built conditions to BIM models over time using accumulated scene facts (counts, measurements, orientations).
- Potential products/workflows:
- “BIM Compliance Agent”: Level-2 lifting + experts to produce structured deltas (e.g., misalignments, missing elements) with traceable evidence.
- Dependencies/assumptions: Accurate metric scale and registration to BIM coordinate frames; standardized data exchange; tolerance bands agreed with stakeholders.
- Regulated AI with Evidence-Grounded Explainability
- What: Policy/audit frameworks that require tool-grounded, memory-backed decisions for spatial claims; Agent Memory provides traceable “why/how” logs.
- Potential products/workflows:
- “Spatial Audit Ledger”: standardized serialization of tool calls, observations, and intermediate conclusions for compliance in inspections, insurance, and infrastructure.
- Dependencies/assumptions: Interoperable audit formats; clear standards; storage/retention policies; human review in the loop.
- Edge Deployment and Streaming Inference at Scale
- What: Low-latency S-Agent variants for drones, wearables, and embedded cameras; streaming tools for continuous reasoning.
- Potential products/workflows:
- “S-Agent Lite”: pruned/distilled versions with hardware-aware depth/pose models and compact memory representations.
- Dependencies/assumptions: Hardware acceleration; model quantization; robust operation under bandwidth constraints.
- Foundation Training with Spatial Trajectories
- What: Use S-Agent-style trajectories (like S-300K) to pretrain multi-modal models on evidence-seeking behaviors, not just answers, improving general spatial reasoning.
- Potential products/workflows:
- “Spatial RLHF/SFT Suite”: combine trajectory SFT with reinforcement learning on tool-use outcomes to refine planning policies and tool selection.
- Dependencies/assumptions: Scalable, diverse trajectory generation; careful dataset curation to avoid overfitting; compute budgets.
- Multi-Agent Collaboration and Human–AI Teaming
- What: Agents that coordinate spatial subtasks (e.g., one agent grounds entities, another handles 3D lifting, a third aggregates knowledge), with human supervisors.
- Potential products/workflows:
- “Spatial Agent Team”: modular experts exchanging scene-memory entries and adjudicating conflicting evidence.
- Dependencies/assumptions: Robust orchestration and conflict resolution; communication protocols; usability tooling for operators.
Notes on feasibility across applications:
- Accuracy and reliability depend strongly on tool quality (open-vocabulary detection, depth, camera pose), view coverage, and calibration. Level-3 experts mitigate noisy 3D, but persistent errors can propagate.
- Real-time constraints may limit immediate use in fast, safety-critical loops; operator-in-the-loop deployments are more viable in the near term.
- Privacy, security, and regulatory requirements are non-trivial for multi-camera/video applications; the built-in memory and trajectory logs facilitate explainability but require governance.
- S-Agent-8B lowers the barrier for on-prem or edge experimentation, but further compression and optimization are needed for wearables and microcontrollers.
Glossary
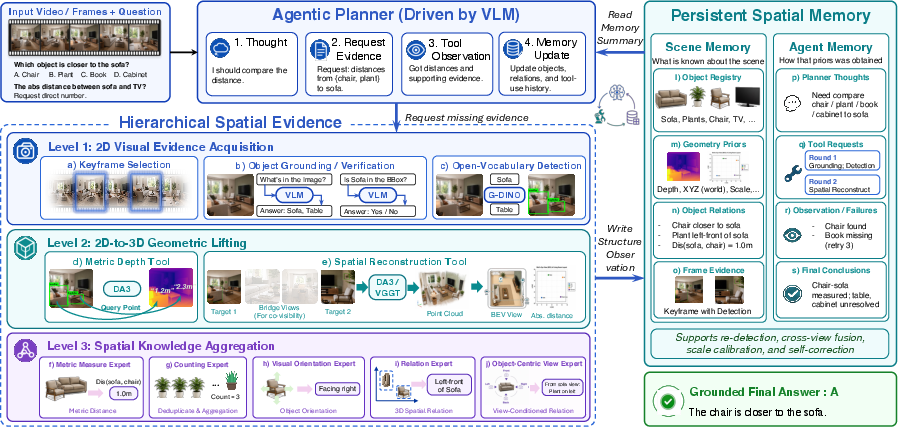
- 2D-to-3D geometric lifting: The process of converting 2D visual cues into an explicit 3D-aware scene representation for reasoning. "2D-to-3D Geometric Lifting (Figure~\ref{fig:framework}(d-e))."
- 3D geometric evidence: Explicit geometric signals (e.g., depth, coordinates) derived from images that support spatial reasoning. "grounds objects in 2D, lifts them into 3D geometric evidence"
- AGI (Artificial General Intelligence): A long-term goal of AI aiming for human-like general reasoning and decision-making across domains. "artificial general intelligence (AGI)"
- Agent Memory: A procedural memory that records tool calls, observations, and intermediate decisions to guide subsequent steps. "Agent Memory preserves the reasoning process that leads to the evolving scene understanding."
- Agentic paradigm: A framework where a model actively plans, calls tools, and iteratively gathers evidence rather than passively predicting. "spatial tool-use agentic paradigm"
- Bird’s-eye-view: A top-down view of the scene used to disambiguate spatial relations beyond the image plane. "bird's-eye-view or novel-view evidence"
- Camera poses: The extrinsic parameters (position and orientation) of the camera used to align observations across views. "such as depth structure, metric coordinates, camera poses, and bird's-eye-view or novel-view evidence."
- Cosine learning-rate decay: A training schedule where the learning rate follows a cosine curve over time, often with warmup. "cosine learning-rate decay with 3\% warmup"
- Entity-centric memory: A memory structure organized around persistent scene entities to accumulate their attributes over time. "an evolving, entity-centric memory"
- Geometric cues: Visual signals that carry geometric information necessary for 3D reasoning (e.g., depth, coordinates). "geometric cues (e.g., depth, 3D coordinates, and camera poses)"
- Geometric recovery: The computational process of reconstructing geometric structure (e.g., depth, pose) from images. "visual localization, geometric recovery, and metric or relational computation"
- Grounded entities: Objects or regions that have been explicitly localized in images and linked to textual references. "stores grounded entities and their accumulated spatial attributes."
- Metric 3D representation: A 3D scene description in real-valued physical units enabling quantitative measurements. "lifts the selected boxes into a metric 3D representation via the depth tool"
- Metric coordinates: 3D coordinates expressed in a consistent physical scale, enabling accurate measurement and comparison. "such as depth structure, metric coordinates, camera poses"
- Multi-granularity training signals: Supervision provided at multiple levels (final answer, turn-level, tool/expert) to teach nuanced behaviors. "multi-granularity training signals"
- Multi-view geometric tools: Tools that exploit multiple viewpoints to recover depth, pose, and other 3D scene properties. "invokes multi-view geometric tools to recover scene-level 3D information"
- Multi-view image set: A collection of images of the same scene from different viewpoints used to integrate spatial evidence. "or a multi-view image set (e.g., different images capture the same scene from different viewpoints)."
- Novel-view evidence: Information obtained by rendering or reasoning from viewpoints different from the original camera views. "bird's-eye-view or novel-view evidence"
- Open-vocabulary detectors: Detectors that can localize objects from arbitrary text categories without fixed label sets. "localizing candidate regions with open-vocabulary detectors."
- Perspective-aware localization: The task of localizing objects or positions while accounting for viewpoint changes and perspective effects. "focuses more specifically on perspective-aware localization"
- Relative-position expert: A specialized module that estimates relative spatial relationships (e.g., left/right/behind) between objects. "The relative-position expert then lifts the selected boxes into a metric 3D representation via the depth tool"
- Scene Memory: A memory that consolidates reusable 2D/3D evidence into a persistent scene state for later reasoning. "Scene Memory turns 2D/3D cues into a persistent, scene-level understanding."
- Semantic planner: The VLM component that decides what evidence to request and which tools to invoke next. "casts the VLM as a semantic planner"
- Spatial experts: Specialized modules that convert geometric signals into high-level spatial facts (e.g., counts, distances). "specialized spatial experts"
- Spatial Knowledge Aggregation: The process of transforming 2D/3D cues into explicit high-level spatial facts for decision-making. "Level 3: Spatial Knowledge Aggregation (Figure~\ref{fig:framework}(f-j))."
- Spatio-temporal evidence accumulation: Integrating spatial evidence over both space and time to build a coherent 3D understanding. "spatio-temporal evidence accumulation rather than isolated frame-level prediction"
- Stateful reasoning: Reasoning that maintains and updates internal state across frames and steps. "temporal memory for stateful reasoning"
- Stateless inference: Reasoning independently per input without retaining context or state across steps. "static, stateless inference"
- Supervised fine-tuning (SFT): Adapting a model to a task using labeled examples under a supervised objective. "Beyond inference-time augmentation, supervised fine-tuning (SFT) on S-Agent-generated spatial trajectories S-300K yields S-Agent-8B"
- Temporal memory: A mechanism that maintains information across time to support reasoning over sequences. "a temporal memory mechanism"
- Tool-augmented agents: Agents that improve their capabilities by invoking external tools during reasoning. "tool-augmented agents largely remain tied to static, stateless inference"
- Tool-calling VLM planner: A VLM that issues structured tool requests conditioned on the question and memory state. "A tool-calling VLM planner maps the question , input observations , and current memory states (, ) to an evidence request "
- Trajectory distillation: Training a smaller model by learning from full reasoning trajectories generated by a stronger teacher. "Trajectory Distillation from S-Agent"
- Vision-LLM (VLM): A multimodal model that processes both visual inputs and natural language. "vision-LLMs (VLMs)"
- Zero-shot: Evaluating or applying a model to new tasks without task-specific training or fine-tuning. "Zero-shot setting."
Collections
Sign up for free to add this paper to one or more collections.

