- The paper presents a novel Test-Time Orchestration (TTO) mechanism that adaptively fuses heterogeneous VLM specialists for improved spatial reasoning.
- It decomposes spatial reasoning into query routing, specialist role assignment, and reliability-weighted synthesis for dynamic context adaptation.
- Empirical evaluations across multiple benchmarks show significant accuracy gains and robustness to out-of-distribution shifts, including a +14 point improvement in specific tasks.
SpatiO: Adaptive Test-Time Orchestration of Vision-Language Agents for Spatial Reasoning
Introduction and Motivation
Spatial reasoning in vision-language tasks demands more than mere object identification—it requires adaptive integration of situational spatial cues like 2D appearances, depth, and geometric priors. However, contemporary vision-LLMs (VLMs) generally internalize a monolithic spatial prior through single-pipeline architectures, undermining robustness to out-of-distribution (OOD) shifts and novel spatial configurations. Empirical analysis reveals that individual models excel in specific spatial categories, but systematically underperform in others, with failure modes that are largely uncorrelated. This strongly motivates architectures that leverage heterogeneous inductive biases for more context-adaptive spatial reasoning.
SpatiO addresses this limitation by framing spatial reasoning as a coordination and orchestration problem over a pool of heterogeneous VLM specialists. Each specialist is independently pretrained and exhibits expertise in distinct spatial reasoning categories, such as 2D visual cues, explicit 3D geometric reconstructions, and symbolic scene-graph relational reasoning. The central contribution is the Test-Time Orchestration (TTO) mechanism, which dynamically estimates and adapts agent reliability at inference based on real-time evidence accumulation, enabling robust, parameter-free adaptation to new contexts.
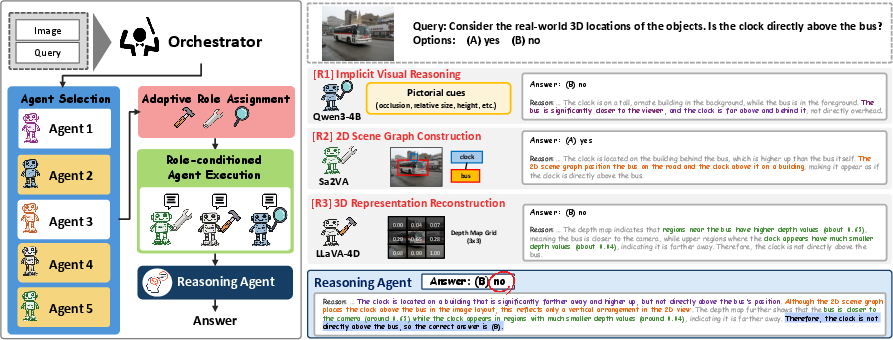
Figure 1: Overall framework illustration of SpatiO. Multiple heterogeneous vision-language agents operate as specialists under different roles, and their outputs are aggregated to produce the final spatial reasoning result.
System Architecture
SpatiO decomposes the spatial reasoning process into three sequential modules: query routing, role-based analysis by specialists, and reliability-weighted synthesis. The architecture leverages five complementary, pretrained VLMs as specialists, together with a head agent for category classification and an explicit final reasoner. Each specialist can dynamically assume roles among implicit visual reasoning (pure 2D), explicit 3D reconstruction (metric geometry, depth maps), and scene-graph construction (symbolic, relational structure), injected via structured prompting.
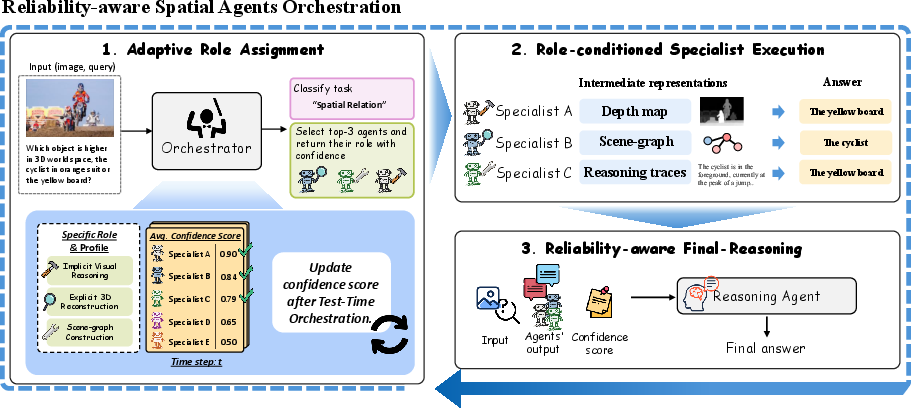
Figure 3: Overview of the SpatiO framework. (Left) The head agent classifies the query and selects the Top-3 agents with role assignments and trust weights. (Center) Each agent independently reasons under its designated role, optionally invoking open-source tools; outputs are stored in shared memory M.
The system maintains per-(agent, role, category) confidence scores, initialized to $0.5$, updated via the TTO optimization as described below. For a given spatial query, the head agent routes to the top-3 most reliable specialists, who generate answers and intermediate structured outputs (e.g., depth maps, scene graphs). The final reasoning agent produces the output by re-integrating primary and intermediate representations, calibrated by TTO-derived reliability weights.
Test-Time Orchestration (TTO)
TTO is the core adaptation mechanism, enabling SpatiO to reweight specialists based on task- and context-dependent reliability signals extracted during inference. Each agent–role–category triple maintains a confidence score, incrementally updated using a beta-Bernoulli trust estimator that accumulates soft rewards according to the similarity of agent outputs to ground truth, and penalizes agents further whose answers diverge more from the final decision in cases of error. A dual exponential moving average (EMA) is applied to ensure rapid adaptation to distributional shifts while retaining long-term stability.

Figure 2: Framework for Test-time Orchestration (TTO) optimization.
Crucially, all adaptation occurs at the orchestration level; no agent parameters are updated during inference. This allows seamless deployment even for black-box or closed-source specialists. TTO incorporates explicit reward scaling to prevent overfitting in under-sampled categories and leverages per-category ramp factors for gradual trust calibration.
Empirical Analysis and Ablations
The authors present extensive quantitative evaluation across four major spatial reasoning benchmarks: 3DSRBench, STVQA-7k, CV-Bench, and Omni3D-Bench. SpatiO achieves superior accuracy in both vanilla and LoRA-finetuned settings and demonstrates robust transfer to OOD categories, particularly on categories requiring precise numerical estimation (e.g., depth, distance).
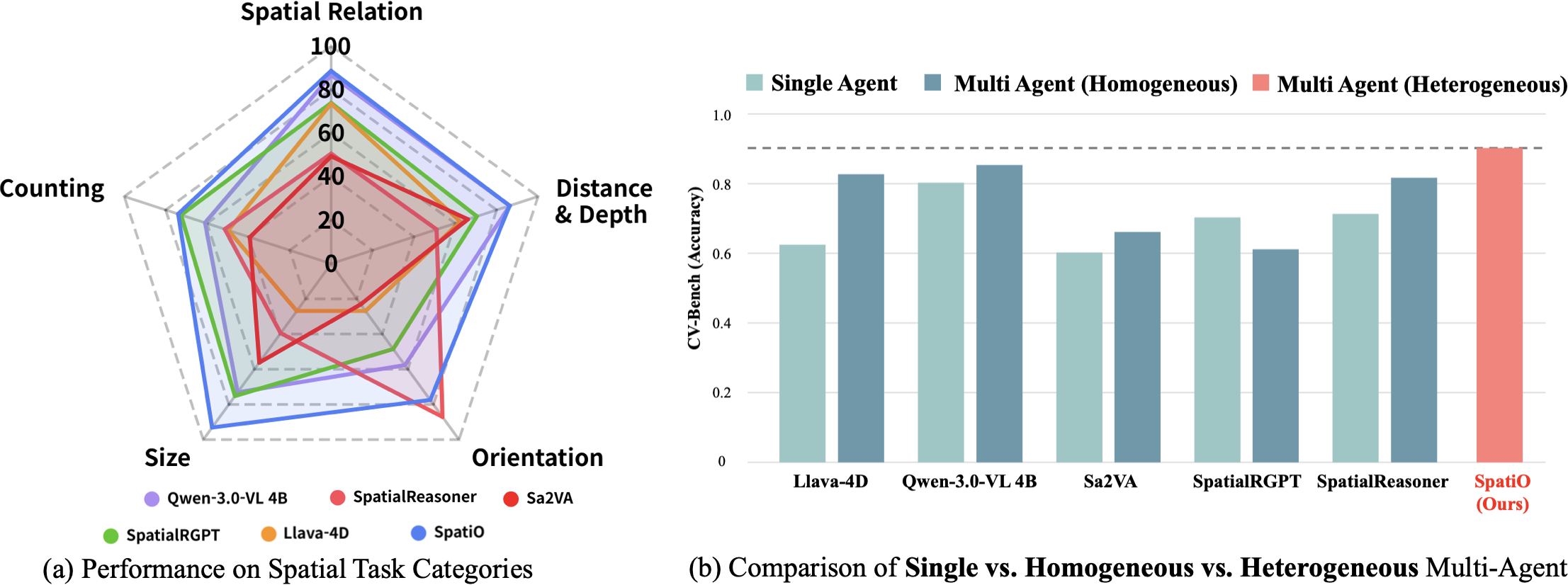
Figure 4: Per-spatial task accuracy of five spatial reasoning specialists (single-agent) and SpatiO (Ours) on reorganized task groups. Each agent occupies a distinct region of the performance space, motivating heterogeneous orchestration over single-backbone selection.
The radar plot demonstrates that each single-agent method achieves peak performance in a distinctive spatial category, exposing the limitations of monolithic models and motivating the multi-agent orchestration mechanism. The test-time orchestration leads to a new Pareto frontier in accuracy vs. robustness, with categorical average gains of +14 points in counting on CV-Bench and significant improvement in cross-benchmark settings.
Ablation analyses confirm the necessity and additive effect of each TTO component (reward scaling, Bayesian trust estimation, dual EMAs), and show diminishing accuracy returns beyond 150 optimization samples—the minimal size for robust per-category trust estimation.
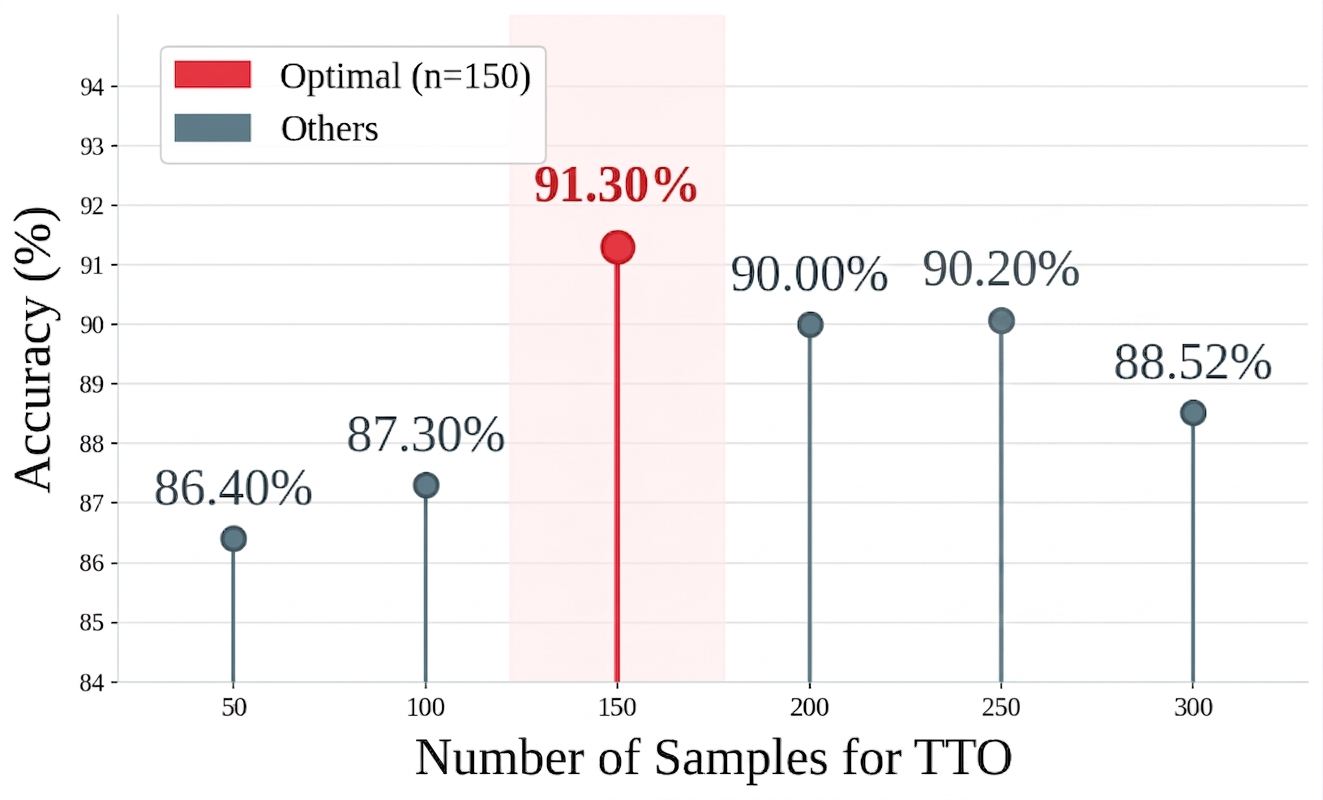
Figure 5: Overall Performance on CV-Bench according to TTO sample size.
Generalization and Cross-Domain Robustness
SpatiO’s reliability-aware orchestration generalizes across spatial reasoning benchmarks and is effective for zero-shot transfer to datasets—including MMSI-Bench and Omni3D-Bench—not seen during TTO optimization. The core spatial taxonomy used for TTO proves structurally aligned with spatial query categories in unseen benchmarks, yielding up to +29% accuracy improvements for multi-step spatial reasoning chains. Additionally, trust scores learned using more complex 3D datasets steadily transfer to 2D-dominant or simpler benchmarks, underscoring SpatiO’s efficacy as a test-time adaptive mixture-of-experts system.


Figure 6: SpatiO pipeline output on 3DSRBench during TTO. 3D representations and scene graphs are post-hoc visualizations provided for interpretability only.
Latency and Practical Considerations
Owing to its parallel multi-agent execution paradigm, SpatiO incurs increased end-to-end inference latency (averaging ~28 seconds per query), dominated by the slowest specialist. However, this overhead is tightly coupled with query complexity, as only specialists relevant to the routed category are executed. The latency-accuracy tradeoff is especially favorable in spatial categories where single-model baselines have the largest performance deficits. The framework is robust to the choice of the head agent and specialist pool and is compatible with additional engineering optimizations such as asynchronous execution and KV-cache sharing.
Implications and Future Directions
SpatiO advances spatial reasoning in VLMs by reframing the challenge as adaptive orchestration of heterogeneous specialists, circumventing the narrow inductive biases of monolithic models. The parameter-free TTO mechanism enables context-adaptivity without modifying pretrained models, promoting practical deployment in scenarios where retraining or fine-tuning is infeasible or cost-prohibitive.
Theoretical implications include the viability of orchestrated mixtures of experts for robust, context-driven reasoning, and the utility of structured, per-category reliability estimation under distributional shift. Practically, the architecture provides a blueprint for systems in embodied AI, robotics, augmented reality, or any domain requiring resilient spatial reasoning under varying environmental or sensory characteristics.
Further research directions are clear: extending the spatial taxonomy to finer-grained categories and complex spatial predicates, scaling the agent pool, engineering latency-aware orchestration (early exiting/pruning), and adapting the framework to dynamic video or embodied settings. Improved trust modeling using richer confidence metrics and episodic memory could further enhance robustness.
Conclusion
SpatiO represents a technically rigorous, empirically validated approach for adaptive, specialist-driven spatial reasoning in vision-LLMs. By formalizing spatial reasoning as test-time orchestration of decorrelated expert agents and implementing reliability-aware aggregation, it achieves substantial gains in accuracy, robustness, and generalization, setting a new standard for spatial intelligence in multimodal AI systems (2604.21190).