Think3D: Thinking with Space for Spatial Reasoning
Abstract: Understanding and reasoning about the physical world requires spatial intelligence: the ability to interpret geometry, perspective, and spatial relations beyond 2D perception. While recent vision large models (VLMs) excel at visual understanding, they remain fundamentally 2D perceivers and struggle with genuine 3D reasoning. We introduce Think3D, a framework that enables VLM agents to think with 3D space. By leveraging 3D reconstruction models that recover point clouds and camera poses from images or videos, Think3D allows the agent to actively manipulate space through camera-based operations and ego/global-view switching, transforming spatial reasoning into an interactive 3D chain-of-thought process. Without additional training, Think3D significantly improves the spatial reasoning performance of advanced models such as GPT-4.1 and Gemini 2.5 Pro, yielding average gains of +7.8% on BLINK Multi-view and MindCube, and +4.7% on VSI-Bench. We further show that smaller models, which struggle with spatial exploration, benefit significantly from a reinforcement learning policy that enables the model to select informative viewpoints and operations. With RL, the benefit from tool usage increases from +0.7% to +6.8%. Our findings demonstrate that training-free, tool-augmented spatial exploration is a viable path toward more flexible and human-like 3D reasoning in multimodal agents, establishing a new dimension of multimodal intelligence. Code and weights are released at https://github.com/zhangzaibin/spagent.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Think3D, a new way for AI models that look at pictures and videos (called vision-LLMs, or VLMs) to understand the real world in 3D. Instead of only “looking” at flat, 2D images, Think3D helps these models build and explore a 3D scene—like walking around a room in a video game—so they can reason better about space, distance, angles, and how things relate to each other.
The big questions the researchers asked
- Can we make AI models “think with space,” not just with images, so they understand 3D layouts like humans do?
- If a model can rebuild a 3D scene from photos or a short video, will exploring that scene from different viewpoints improve its answers to spatial questions?
- How can smaller, less powerful models learn to choose smart viewpoints during exploration?
How they did it
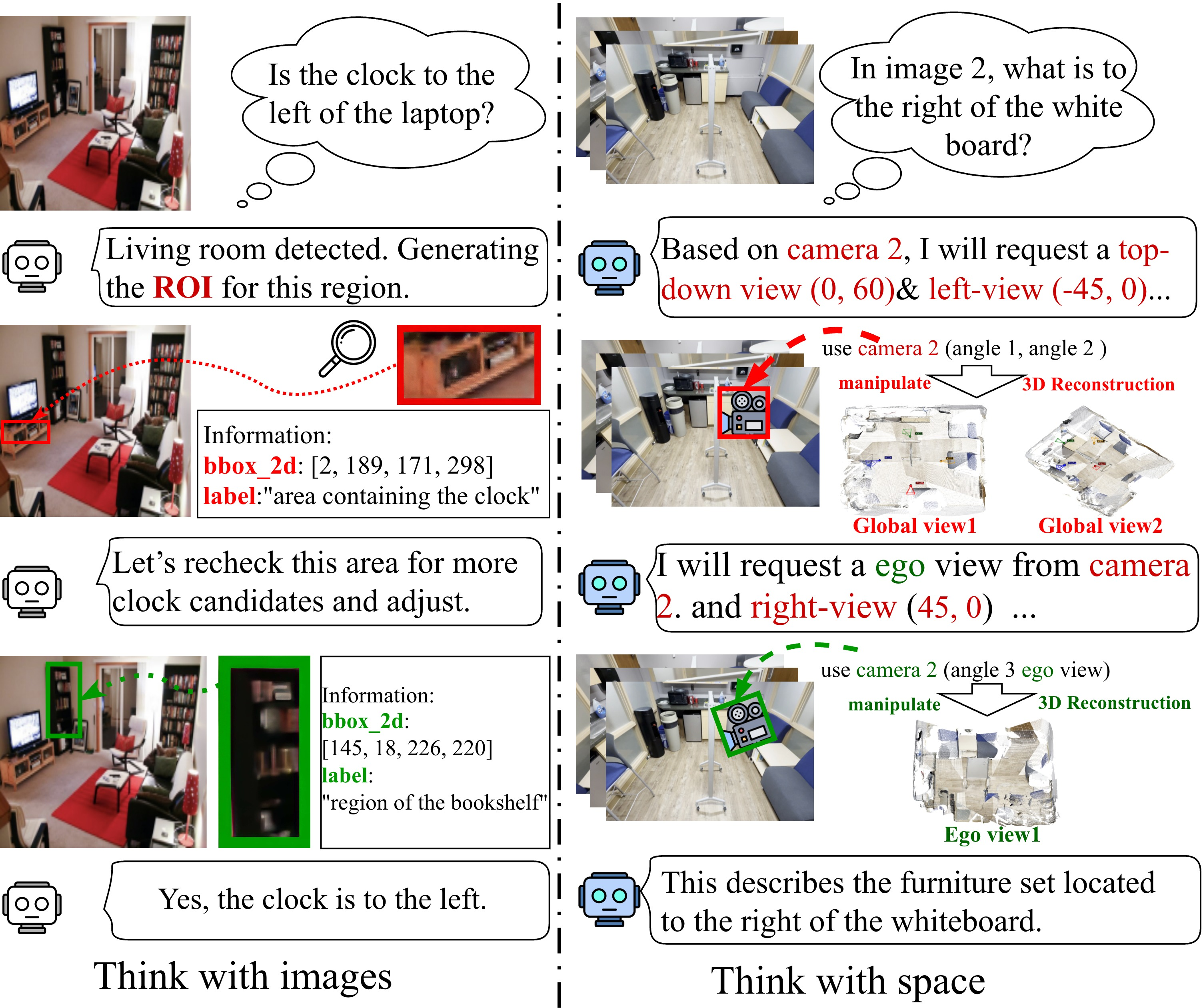
Think3D gives an AI model three main tools, then wraps them in a simple loop: observe → manipulate → reflect. Here’s what that means in everyday language.
Building a 3D world from 2D pictures
- The system takes several images or a short video and reconstructs a “point cloud”—a 3D scatter of colored dots that forms the shapes of objects in the scene.
- It also estimates each camera’s “pose,” which is just where the camera was and which direction it faced for each image.
Think of a point cloud like sprinkling confetti in space to outline your desk, chair, and walls. Camera pose is like the camera’s position plus its compass direction.
Moving the camera around smartly (using anchors)
- To keep movements consistent, the model picks one of the original camera views as an anchor (a stable reference).
- It then rotates a virtual camera around that anchor by horizontal and vertical angles (like turning your head left-right and up-down) to look at the scene from new viewpoints.
- The model can choose between:
- a “global” view (a wide, god’s-eye look at the whole room),
- or an “ego” view (a first-person look straight ahead).
Anchors are important because without a reference, rotations become confusing—like spinning in place with your eyes closed and losing track of which way is north.
Switching views and thinking step by step
- The model repeats a loop: 1) observe a view, 2) manipulate the camera to try a new angle, 3) reflect on what it learned, 4) decide the next move.
- Over several steps, it builds a 3D “chain of thought,” combining broad scene structure (global view) with close-up details (ego view).
Teaching smaller models to explore using trial-and-error
- Big models (like GPT-4.1 or Gemini 2.5 Pro) usually pick good viewpoints naturally.
- Smaller models struggle—they often choose angles that don’t help.
- To fix this, the authors use reinforcement learning (RL), which is like practicing with rewards:
- The model tries different exploration strategies over multiple steps.
- It only gets a reward at the end if its final answer is correct and well-formatted.
- Over time, it learns which viewpoints and action sequences lead to better answers.
During training, they simplify choices to a few “canonical” views (like top-down, left, right), so the model learns the habit of choosing helpful angles. At test time, it can use precise rotations.
What they found
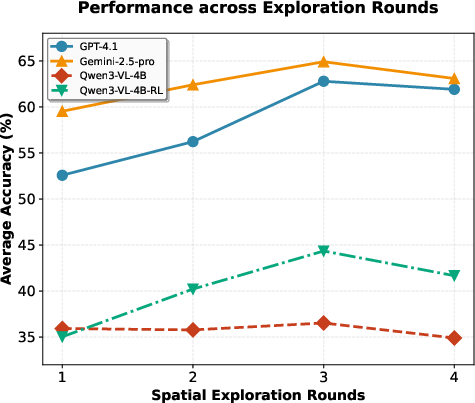
- Without extra training, Think3D improved big models’ performance on spatial tasks:
- On the BLINK Multi-view and MindCube benchmarks, average gains were about +7.8%.
- On the video-based VSI-Bench, gains were about +4.7%.
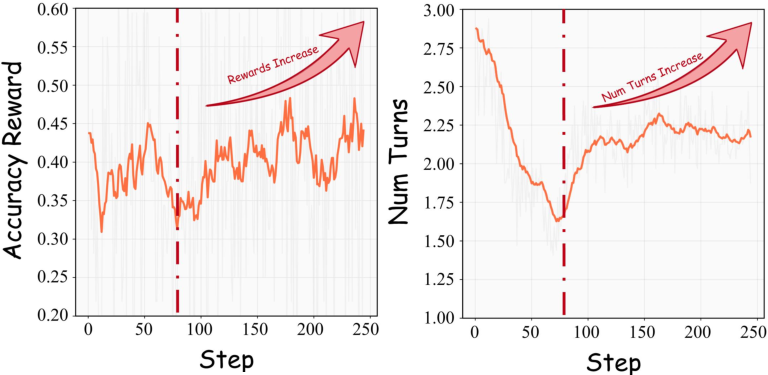
- For smaller models, exploration helped much more after RL:
- Before RL, tool-based exploration added only about +0.7%.
- After RL, it jumped to about +6.8%.
- The model learned task-specific habits:
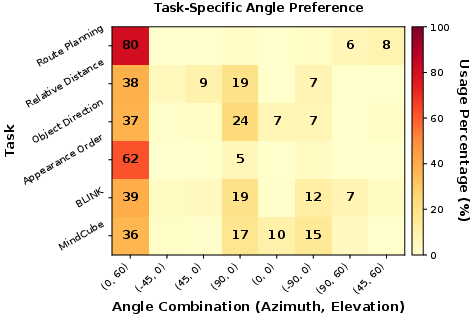
- For route planning and appearance order, top-down “global” views were most useful.
- For orientation tasks (like judging rotation), angled or rotating viewpoints were better.
- Using camera “anchors” mattered:
- Just throwing 3D data at the model didn’t help much.
- Letting it actively choose anchored viewpoints and switch to ego/global views made a big difference.
Why this matters
- Many real-world tasks (robot navigation, AR/VR, home assistance, mapping) require understanding space in 3D, not just recognizing objects in 2D images.
- Think3D shows a simple, powerful idea: give AI models tools to build and explore 3D scenes, and let them think step by step from different viewpoints.
- It works right away for advanced models and, with RL, teaches smaller models how to explore more like the big ones.
- This opens a practical path toward more human-like spatial intelligence in AI—without needing massive retraining datasets—by combining smart tools, interactive exploration, and trial-and-error learning.
The team also released their code and model weights, so others can try and build on this approach.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Sensitivity to reconstruction errors: Quantify how pose noise, depth noise, point sparsity/density, scale drift, and outlier points in the 3D reconstruction affect downstream reasoning accuracy; include controlled perturbation studies and robustness curves.
- Dynamic scenes and non-rigid objects: Evaluate Think3D when scenes contain moving objects, non-rigid motion, motion blur, or temporal inconsistencies that violate static-scene assumptions commonly used by reconstruction backends like Pi3.
- Reconstruction backend dependence: Compare multiple 3D backends (e.g., DUSt3R, MASt3R, VGGT, MapAnything) to assess portability and performance variance; identify which geometric attributes (pose quality, metric scale, track consistency) most influence reasoning.
- Limited viewpoint control (2-DoF rotations only): Relax the restriction that virtual cameras rotate around fixed input camera centers (no translation, no roll); test full 6-DoF control and study whether translational moves produce more informative observations.
- Anchor choice and reference frames: Explore alternatives to using input camera poses as anchors (e.g., gravity-aligned world frames, learned canonical frames) and analyze how anchor selection impacts consistency, interpretability, and exploration efficiency.
- Rendering fidelity and visibility modeling: Analyze point-based rendering limitations (occlusion ordering, hole-filling, aliasing, visibility uncertainty); compare with differentiable splatting or mesh/neural rendering to see if higher-fidelity views improve reasoning.
- Uncertainty-aware reasoning: Incorporate per-point confidence/depth variance from the reconstruction into rendering, view selection, and the VLM’s decision policy (e.g., uncertainty-weighted evidence aggregation); quantify gains.
- Missing geometric measuring tools: Expose explicit 3D geometry queries (e.g., distances, angles, relative poses, visibility checks, ray casting) rather than relying solely on rendered images; test whether direct geometric computations boost accuracy and sample efficiency.
- Semantic grounding in 3D: Integrate 3D instance/semantic segmentation, object tracking, and scene graphs to combine geometric exploration with semantic reasoning; measure effects on tasks like relational queries or route planning.
- Policy gating for tool use: Develop confidence- or cost-aware policies that decide when 3D reconstruction is beneficial; address observed regressions where Think3D hurts performance on certain tasks and minimize unnecessary tool invocations.
- Budget- and latency-aware evaluation: Report and optimize end-to-end latency, GPU memory, FLOPs, and dollar cost (including API calls) for reconstruction and multi-step exploration; benchmark real-time feasibility for online agents.
- Exploration step scheduling and stopping: Learn adaptive stopping criteria and step budgeting (e.g., via reward shaping or early-stopping heuristics) rather than fixing the number of iterations (2–3); evaluate trade-offs between steps and accuracy.
- RL reward design and credit assignment: Go beyond trajectory-only correctness rewards; compare step-wise rewards, exploration bonuses, value-function baselines, and auxiliary objectives (e.g., view novelty, coverage, uncertainty reduction) for better credit assignment.
- Discretized-to-continuous mismatch: The RL policy is trained on discretized canonical views but evaluated with continuous controls; quantify sim-to-real gaps and test finer training grids or continuous-action RL.
- Data scale and overfitting risks: RL is trained on only 977 MindCube samples; examine cross-benchmark generalization, sensitivity to dataset composition, and overfitting (e.g., angle distributions that key on dataset biases).
- Stability and reproducibility of RL: Report variance across seeds, runs, and hardware; clarify differences between Qwen3-VL-4BGRPO and Qwen3-VL-4BRL setups; provide ablations on rollout count, KL constraints, and group sizing in GRPO.
- Side effects on non-spatial capabilities: Evaluate whether RL fine-tuning for spatial exploration degrades general reasoning or vision tasks; propose regularization or multi-task training to prevent catastrophic forgetting.
- Benchmark coverage and statistical rigor: Move beyond small subsets (e.g., 120 MindCube questions, VSI-Bench-tiny) to full benchmarks; report confidence intervals, significance testing, and per-category breakdowns to support claims.
- Harder and more diverse scenarios: Test cluttered, texture-poor, reflective/transparent objects, outdoor/indoor mixes, long-horizon videos, and extreme viewpoints to stress both reconstruction and policy; include single-view inputs to assess failure modes.
- Embodied, real-robot evaluation: Validate Think3D in closed-loop navigation/manipulation settings (e.g., real robots, simulators with physics) to test whether viewpoint policies and 3D CoT translate to action success.
- Memory representation of 3D CoT: Replace the sequence of rendered images with persistent 3D memory (e.g., object-level scene graphs, neural maps) and test whether structured memory yields better long-horizon reasoning and sample efficiency.
- Mode selection analysis (ego vs global): Provide a principled criterion or learned policy for ego/global switching; ablate FOV, clipping thresholds, and multi-scale zoom to understand when each mode is most beneficial.
- Camera intrinsics and FOV handling: Study sensitivity to inaccurate intrinsics/FOV and mixed intrinsics across views; test intrinsics refinement or self-calibration to reduce projection artifacts.
- Cross-backend tool robustness and fallbacks: Define automatic fallbacks when reconstruction fails (e.g., revert to 2D toolchain); detect tool failures online and quantify their impact on decision quality.
- Interpretability of learned policies: Beyond angle histograms, develop tools to attribute answer correctness to specific view choices, identify redundant/contradictory views, and visualize policy rationales for debugging and auditing.
Practical Applications
Immediate Applications
Below are applications that can be deployed now using Think3D’s training-free tool augmentation and, where helpful, the RL viewpoint policy for smaller models. Each item includes sector alignment, potential tools/products/workflows, and feasibility notes.
- Spatial QA copilot for robotics operations
- Sectors: robotics, warehousing, manufacturing
- Tools/products/workflows: a Think3D agent plugged into existing VLMs (e.g., GPT-4.1, Gemini 2.5 Pro) to reconstruct point clouds from multi-view cameras or short videos; iterative observe→manipulate→reflect loop to select informative global or ego views; route-planning, object orientation, and appearance-order checks mirroring VSI-Bench tasks
- Assumptions/dependencies: adequate multi-view coverage; reliable camera pose estimation; moderate GPU for Pi3/VGGT inference; static scenes or limited motion during capture
- AEC site inspection assistant (as-built vs. as-planned checks)
- Sectors: architecture, engineering, construction
- Tools/products/workflows: phone or drone capture → Pi3 reconstruction → agent selects top-down/global views to check clearances, distances, and layout conformance; automatic generation of annotated novel views for RFIs/issue logs
- Assumptions/dependencies: sufficient image overlap and scene texture; calibrated intrinsics or estimable camera parameters; adherence to project privacy/security policies
- E-commerce product visualization QA and viewpoint planning
- Sectors: retail/e-commerce, product photography
- Tools/products/workflows: convert turntable or multi-view product images to a point cloud; Think3D agent proposes canonical angles and ego/global views to expose dimensions, features, and occlusions; automate “shop-the-look” scene setups
- Assumptions/dependencies: consistent lighting/background; high-quality multi-view captures; basic renderer suffices for view synthesis
- Industrial equipment inspection and maintenance guidance
- Sectors: industrial automation, energy, utilities
- Tools/products/workflows: technician-recorded short videos → 3D reconstruction → agent selects viewpoints to reveal occluded components, label relative positions, and suggest approach angles; generates step-by-step spatial CoT annotated frames
- Assumptions/dependencies: acceptable reconstruction of reflective/low-texture surfaces; controlled motion during capture; on-device or edge GPU
- Surveillance and multi-camera incident review
- Sectors: security, public safety
- Tools/products/workflows: fuse multi-camera footage of an event → Think3D agent reconstructs scene and uses global views to answer spatial queries (who moved where, relative distances, routes); produces evidence-ready novel views
- Assumptions/dependencies: time-synced cameras, sufficient overlap; data governance and chain-of-custody compliance
- AR home layout and organization assistant
- Sectors: consumer software, interior design
- Tools/products/workflows: users record a room with a phone → Think3D reconstructs → agent generates top-down views, measures distances, and suggests furniture placement or cable routing; integrates with mobile AR overlays
- Assumptions/dependencies: consistent scanning paths; device-grade intrinsics; latency tolerable on mobile/edge
- Educational tutor for spatial reasoning and geometry
- Sectors: education, edtech
- Tools/products/workflows: interactive exercises (mental rotation, camera-motion understanding) using Think3D’s ego/global switching; dynamic 3D CoT explanations; auto-generated multi-view problems inspired by MindCube and BLINK
- Assumptions/dependencies: curated learning content; reliable rendering on school devices; simplified UI for learners
- Previsualization and cinematography viewpoint planner
- Sectors: media, film, game development
- Tools/products/workflows: ingest location scout videos → reconstruct → agent proposes informative oblique/top-down angles and blocking suggestions; exports shot lists and storyboard frames
- Assumptions/dependencies: adequate scene coverage; creative workflows accept tool-generated viewpoints; integration with DCC tools
- Assembly and customer support guidance
- Sectors: consumer electronics, furniture
- Tools/products/workflows: user captures partial assembly → agent reconstructs and selects ego/global views to show part orientation, order of operations, and alignment; produces annotated, stepwise visuals
- Assumptions/dependencies: training-free deployment with strong VLMs; consistent packaging of multi-view captures
- Research instrumentation for spatial cognition and tool-use policies
- Sectors: academia, AI research
- Tools/products/workflows: use Think3D pipeline to study 3D CoT, benchmark spatial reasoning, and evaluate RL viewpoint policies; generate reproducible multi-turn trajectories for analysis
- Assumptions/dependencies: access to datasets (BLINK/MindCube/VSI), GPU resources, standardized prompts and logging
- Insurance and property claims triage (damage assessment)
- Sectors: finance/insurance, real estate
- Tools/products/workflows: claimant uploads short video → Think3D reconstructs property/asset; agent produces top-down and ego views to quantify affected areas and distances; supports adjuster decisions
- Assumptions/dependencies: privacy-preserving processing; regulatory compliance; minimal user capture guidance requirements
Long-Term Applications
These applications require further research, scaling, safety validation, or real-time integration. They build on Think3D’s 3D CoT and RL-driven viewpoint selection.
- Real-time embodied robot copilot for manipulation and navigation
- Sectors: robotics, logistics, home assistance
- Tools/products/workflows: on-robot 3D CoT fused with control stacks; RL-trained viewpoint policies to decide where to look and when; closed-loop planning from ego/global views
- Assumptions/dependencies: low-latency 3D reconstruction on embedded hardware; robust in dynamic, cluttered environments; safety certification
- Autonomous driving spatial reasoning layer
- Sectors: automotive
- Tools/products/workflows: integrate Think3D-style reasoning over multi-sensor imagery to disambiguate relative direction/distance and route options; use canonical viewpoints to validate perception outputs
- Assumptions/dependencies: real-time constraints, sensor calibration, rigorous validation, regulatory approvals
- Surgical and endoscopic 3D orientation assistance
- Sectors: healthcare
- Tools/products/workflows: reconstruct anatomy from endoscopic multi-view sequences; agent selects vantage angles to orient surgeons and annotate spatial relationships in situ
- Assumptions/dependencies: medical-grade accuracy/latency; domain-specific reconstruction for specular/low-texture tissues; clinical trials and regulatory compliance
- XR co-pilot for complex tasks (maintenance, construction, training)
- Sectors: enterprise XR, education, industrial
- Tools/products/workflows: headset capture → on-device/edge reconstruction → Think3D agent guides tasks with adaptive ego/global viewpoints; integrates with digital twins
- Assumptions/dependencies: efficient on-headset compute; ergonomic UX; robust tracking and occlusion handling
- Disaster response mapping and path planning
- Sectors: public safety, NGOs
- Tools/products/workflows: drone/ground-camera sweeps → rapid 3D reconstruction → agent produces safe routes, object-relative positions, and top-down situational maps
- Assumptions/dependencies: adverse conditions (smoke, debris) degrade reconstruction; policy and liability frameworks for AI recommendations
- Smart city analytics and crowd flow management
- Sectors: urban planning, policy
- Tools/products/workflows: multi-camera fusion across public spaces → agent performs route planning and relative direction analyses; informs event logistics and evacuation planning
- Assumptions/dependencies: privacy, governance, and data-sharing agreements; bias and fairness audits; scalability to city-wide deployments
- Assistive navigation for the visually impaired
- Sectors: healthcare, accessibility
- Tools/products/workflows: phone or wearable capture → 3D reasoning for indoor routing and obstacle orientation; spoken guidance informed by ego/global view switching
- Assumptions/dependencies: robust dynamic-scene handling, low latency, high reliability; safety standards and user trials
- 3D search and spatial QA over scanned environments
- Sectors: software, real estate, facilities management
- Tools/products/workflows: index point clouds of homes/offices; answer queries like “Where is the nearest fire extinguisher?” with viewpoint-annotated responses; integrate with facility BIM
- Assumptions/dependencies: large-scale storage/indexing; standardized spatial metadata; user privacy and access controls
- Autonomous inspection for energy infrastructure
- Sectors: energy, utilities
- Tools/products/workflows: drone/robot capture → Think3D agent selects optimal viewpoints for anomaly detection and clearance checks; generates actionable 3D CoT reports
- Assumptions/dependencies: domain adaptation for extreme environments; integration with maintenance workflows; regulatory approvals for autonomous ops
- Policy toolkits and procurement standards for 3D reasoning AI
- Sectors: government, standards bodies
- Tools/products/workflows: adopt benchmarks (e.g., VSI-Bench, MindCube) and 3D CoT auditing protocols; require documented tool-calling policies and viewpoint-selection rationale in public-sector AI procurement
- Assumptions/dependencies: consensus on metrics; stakeholder engagement; compliance and auditing infrastructure
Cross-cutting assumptions and dependencies
- Data quality and capture: multi-view overlap, camera pose estimability, scene texture, and limited motion during reconstruction strongly influence performance.
- Compute and latency: Pi3/VGGT-like 3D reconstruction and rendering require GPU/edge resources; real-time applications need optimization or specialized hardware.
- Model choice: training-free gains are strongest with capable VLMs (e.g., GPT-4.1, Gemini 2.5 Pro); smaller models benefit after RL viewpoint policy training.
- Safety and reliability: safety-critical deployments (healthcare, AV, disaster response) need rigorous validation, monitoring, and fail-safe design.
- Privacy and governance: multi-camera fusion and spatial analytics require data protection, consent, and compliance frameworks.
- Generalization: dynamic scenes, reflective/low-texture materials, and adverse conditions may degrade reconstruction; domain-specific adaptation may be needed.
Glossary
- 2.5D operations: Tool-based image manipulations that infer partial 3D cues (e.g., relative depth) without full 3D geometry. "these 2.5D operations can only capture shallow spatial cues"
- Agentic reasoning: A model-led, multi-step decision and action process to solve a task. "We represent an agentic reasoning episode as the following trajectory:"
- Azimuth: The horizontal rotation angle around the vertical axis in 3D. "specifying horizontal (azimuth) and vertical (elevation) rotations"
- Canonical viewpoints: A discrete set of predefined camera poses used to simplify exploration during training. "we discretize the space of camera poses into a set of canonical viewpoints"
- Camera pose: The position and orientation of a camera in 3D space. "3D reconstruction models that recover point clouds and camera poses from images or videos"
- Chain-of-thought (3D): Step-by-step reasoning explicitly carried out within reconstructed 3D space. "transforming spatial reasoning into an interactive 3D chain-of-thought process"
- Cosine learning rate schedule: A training schedule where the learning rate follows a cosine curve over time. "using a cosine learning rate schedule with 5% warmup"
- Ego-centric view: A first-person perspective aligned with a chosen camera’s forward direction. "specifies the view mode (global overview vs.\ ego-centric);"
- Ego/global-view switching: Alternating between local first-person and global overview perspectives during reasoning. "camera-based operations and ego/global-view switching"
- Egocentric videos: Videos captured from a first-person viewpoint that reflect the observer’s perspective. "VSI-Bench assesses visual–spatial intelligence in dynamic egocentric videos"
- Elevation: The vertical rotation angle, reflecting up/down tilt in 3D. "specifying horizontal (azimuth) and vertical (elevation) rotations"
- Field-of-view cone: The region of space visible to a camera defined by its viewing angles. "a wide field-of-view cone aligned with the forward direction of "
- God’s-eye view: A global, top-down overview of the entire 3D scene. "In the global (god's-eye) mode, all 3D points in are projected"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm that normalizes advantages within groups for stability. "trained with Group Relative Policy Optimization (GRPO)"
- Group-normalized advantages: Advantage estimates normalized across a group to stabilize RL updates. "which provides stable, group-normalized advantages for multi-turn reasoning"
- Intrinsic matrix: A camera matrix encoding focal length and principal point that maps 3D rays to image coordinates. "where denotes the intrinsic matrix"
- Metric-scale reconstructions: 3D reconstructions with correct real-world scale (units). "to produce metric-scale reconstructions."
- Multi-view: Using multiple distinct images of a scene to improve 3D understanding. "Given multi-view images "
- Novel view rendering: Synthesizing images from new camera poses of a reconstructed 3D scene. "Novel View Rendering: In the global (god's-eye) mode"
- Permutation-equivariant: A property where outputs do not change under permutations of inputs (e.g., image/view order). "permutation-equivariant visual geometry"
- Point-based renderer: A renderer that synthesizes images by projecting colored 3D points. "A lightweight, point-based renderer then produces the synthesized image"
- Point cloud: A set of 3D points (often with color) representing a scene’s geometry. "a 3D point cloud and the corresponding camera poses can be estimated"
- Point tracks: Correspondences of points across multiple views that track their 2D projections over time. "including camera parameters, depth maps, and point tracks"
- Reinforcement learning policy: The learned strategy dictating which actions to take to maximize rewards. "benefit significantly from a reinforcement learning policy"
- Rotation matrix: A matrix representing 3D rotational orientation of a camera or object. "where denotes the rotation matrix"
- SO(3): The mathematical group of all 3D rotations (special orthogonal group in 3D). "where denotes the rotation matrix"
- Spatial grounding: Linking language or tasks to precise 3D locations or objects. "embodied interaction and precise 3D spatial grounding"
- Spatial prompting: Prompting strategies that explicitly encode spatial cues to guide model reasoning. "via spatial prompting"
- Token-wise mask: A training mask that controls which generated tokens contribute to gradient updates. "we apply a token-wise mask to exclude observation tokens"
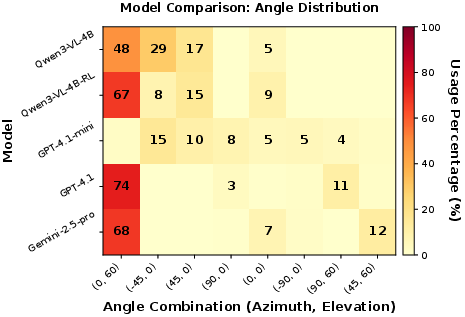
- Top-down viewpoint: A camera perspective looking downward from above to capture global layout. "GPT-4.1 predominantly uses top-down viewpoints to capture global spatial structure"
- Trajectory-level reward: A reward assigned after completing an entire sequence of actions/observations. "Trajectory-level reward."
- Virtual camera: A synthetically defined camera pose used to render novel views from 3D reconstructions. "we construct a virtual camera defined as"
- Vision LLM (VLM): A multimodal model that processes visual inputs and text jointly. "Recent advances in Vision LLMs (VLMs)"
- Viewpoint-manipulation actions: Agent-issued commands that adjust camera pose or rendering to explore the scene. "issuing viewpoint-manipulation actions that control camera pose and rendering parameters."
- Observe–manipulate–reflect loop: An iterative cycle of viewing, acting, and reasoning to refine understanding. "via a multi-turn observe â manipulate â reflect loop"
Collections
Sign up for free to add this paper to one or more collections.