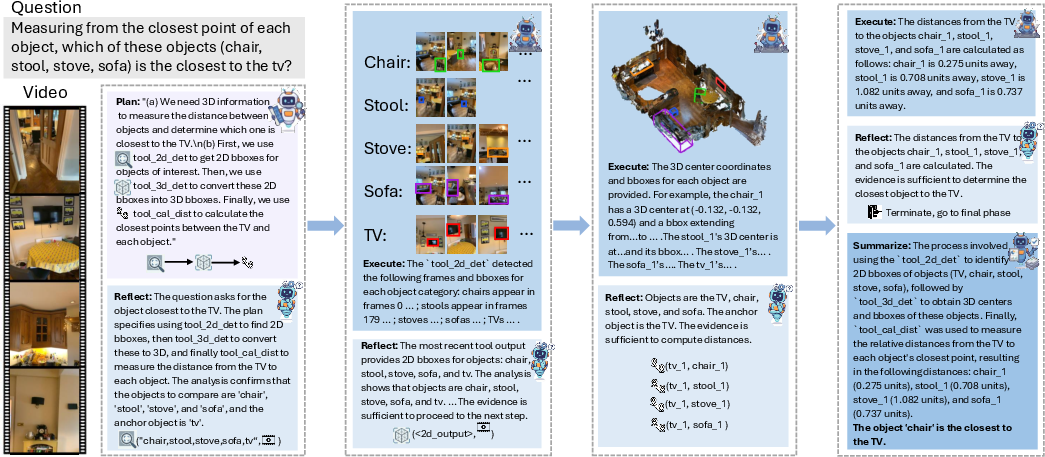
- The paper introduces ViSRA, a novel training-free, inference-time agent that leverages modular spatial tools to enhance 3D video reasoning in MLLMs.
- The paper demonstrates substantial accuracy improvements up to 15.6% on benchmarks and up to 28.9% on out-of-distribution tasks.
- The paper’s framework provides interpretable, evidence-grounded spatial reasoning through a multi-role agent architecture and modular tool orchestration.
ViSRA: An Inference-Time Framework for 3D Video-Based Spatial Reasoning in MLLMs
Motivation and Background
Despite significant progress in Multi-modal LLMs (MLLMs) for image and video understanding, the extension of genuine 3D spatial reasoning – such as comprehension of relative distances, directions, and object permanence in dynamic scenes – remains elusive. Most prior improvements in MLLMs' spatial intelligence have come from supervised post-training with large-scale, curated datasets, which introduces expensive computational overhead and fosters benchmark-specific overfitting, reducing transferability to out-of-distribution (OOD) situations or complex, real-world tasks.
The paper "ViSRA: A Video-based Spatial Reasoning Agent for Multi-modal LLMs" (2605.10106) presents ViSRA, a training-free, inference-time agentic architecture designed to augment spatial reasoning capabilities of MLLMs by orchestrating modular, domain-expert perception tools in a human-aligned manner. ViSRA obviates the need for further fine-tuning or dataset curation while enabling generalizable, flexible, and interpretable 3D spatial reasoning grounded in explicit intermediate outputs.

Figure 1: Comparison of three paradigms for 3D spatial reasoning. The left panel diagrams the paradigms, the middle panel provides qualitative examples showing ViSRA's advantage on both in-benchmark and novel questions, and the right panel presents ViSRA's superior accuracy across established and unseen tasks.
Limitations of Post-Training Approaches and the Need for Tool-Driven Inference
Current post-training strategies – including spatially grounded supervised fine-tuning, architectural adaptations, and spatial instruction tuning – have demonstrated accuracy gains on curated benchmarks. However, these improvements are largely non-transferable, as evidenced by sharp accuracy drops on OOD question types or novel task formulations. Notably, even with access to precise, ground-truth cognitive maps, state-of-the-art MLLMs cannot reliably infer straightforward spatial relations, indicating fundamental misalignment with human reasoning about space.
The core empirical findings leading to ViSRA are:
- Cognitive maps as auxiliary inputs do not confer reliable spatial reasoning capacity to MLLMs for a variety of spatial tasks.
- Post-trained models overfit to benchmark distributions and show negligible gains – or even performance degradation – on OOD spatial queries.
ViSRA consists of two principal components:
- A suite of interoperable, explicit spatial tools that encapsulate strong domain expert perception models for extracting 2D/3D object presence, tracking, scene geometry, and semantic priors.
- A multi-role agentic runtime which instantiates four specialized agent roles – Planner, Reflector, Executor, Summarizer – coordinating tool invocations to decompose and solve spatial reasoning tasks.
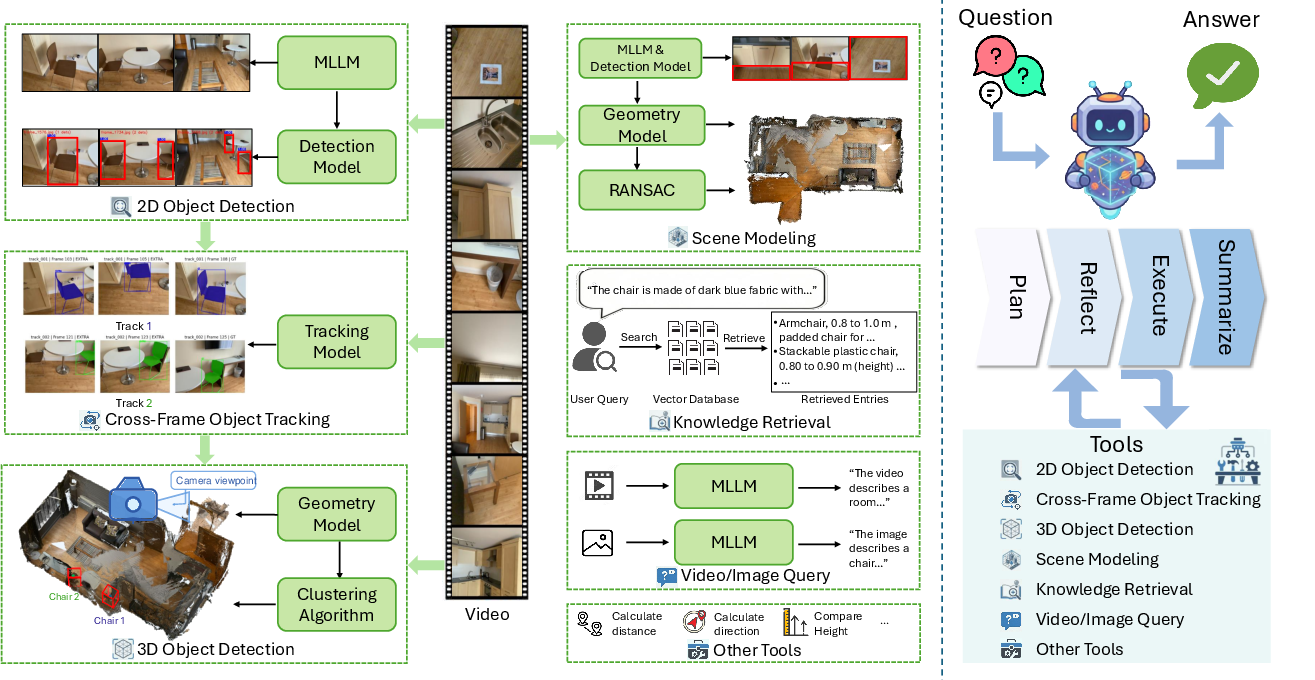
Figure 2: Overview of ViSRA, showing the spatial tools (left) and the multi-role agent architecture with planning, execution, reflection, and summarization (right).
- 2D Object Detection: Per-frame detection of query-relevant objects using advanced detectors, informed by MLLM-driven frame filtering.
- Cross-Frame Object Tracking: Propagation and association of detected objects across time for instance-level recognition.
- 3D Object Detection: Lifting of 2D detections to 3D via foundational geometric models (e.g., VGGT), with constrained clustering to prevent instance-mixing.
- Scene Modeling: Estimation of canonical scene geometry (e.g., ground plane) for metric spatial tasks and the construction of real-world-aligned coordinates.
- Knowledge Retrieval: Contextual access to a structured knowledge base of object/room priors for semantically ambiguous tasks.
- Video/Image Query: Direct delegation of questions to the MLLM for unstructured or hard-to-specify tasks.
- Utility Functions: Downstream operations (e.g., distance, direction, height, obstruction computation) leveraging extracted representations.
Multi-Role Agent
Experimental Evaluation
ViSRA is evaluated as a drop-in agentic enhancement across multiple open-source MLLMs (e.g., Qwen2.5-VL, InternVL3, LLaVA-OneVision) of varying sizes and compared with state-of-the-art proprietary and post-trained models. Evaluations span:
- VSI-Bench: Established benchmark for spatial intelligence in egocentric videos.
- VSI-Bench-Extra: OOD benchmarks with new spatial question types to assess generalization.
- Other suites: Cross-viewpoint, online spatio-temporal, and comprehensive video-based spatial intelligence benchmarks (ViewSpatial-Bench, OST-Bench, MMSI-Video-Bench).
Quantitative Results and Highlights
- On VSI-Bench, ViSRA-augmented models realize absolute accuracy improvements up to 15.6% over their base counterparts, yielding performance competitive with much larger, post-trained or proprietary systems.
- On VSI-Bench-Extra, ViSRA outperforms post-trained baselines by up to 28.9% on OOD spatial queries, demonstrating superior generalization beyond training distributions.
- Substantial accuracy gains are observed in spatial categories highly dependent on explicit 3D reasoning (relative direction, planning, appearance order).
- Ablation studies show tool choice and execution protocol (frame sampling, detector/tracker selection, clustering algorithm) significantly affect final accuracy, with transferability to improved perception models.

Figure 4: Correct object-counting results generated by ViSRA, invoking both detection and tracking tools.

Figure 5: Accurate appearance-order reasoning achieved by ViSRA leveraging tool-driven evidence aggregation.

Figure 6: Successful relative-direction reasoning by ViSRA, using spatial tools to extract human-aligned spatial cues.

Figure 7: A failure case from ViSRA due to upstream perception errors (e.g., category confusion in detection).
Interpretability and Modularity
A critical strength of ViSRA is its modular architecture and explicit evidence trail. Each decision step, intermediate output, and final answer is interpretable, facilitating fault diagnosis and extension. Improvements in vision models (e.g., better detectors/trackers or geometric solvers) are inherited without retraining, making ViSRA both upgradable and generalizable.
Ambiguities inherent to annotation (referent ambiguity, visual occlusion) are visualized and accounted for in the qualitative analysis, illustrating both progress and residual source of error in spatial QA.
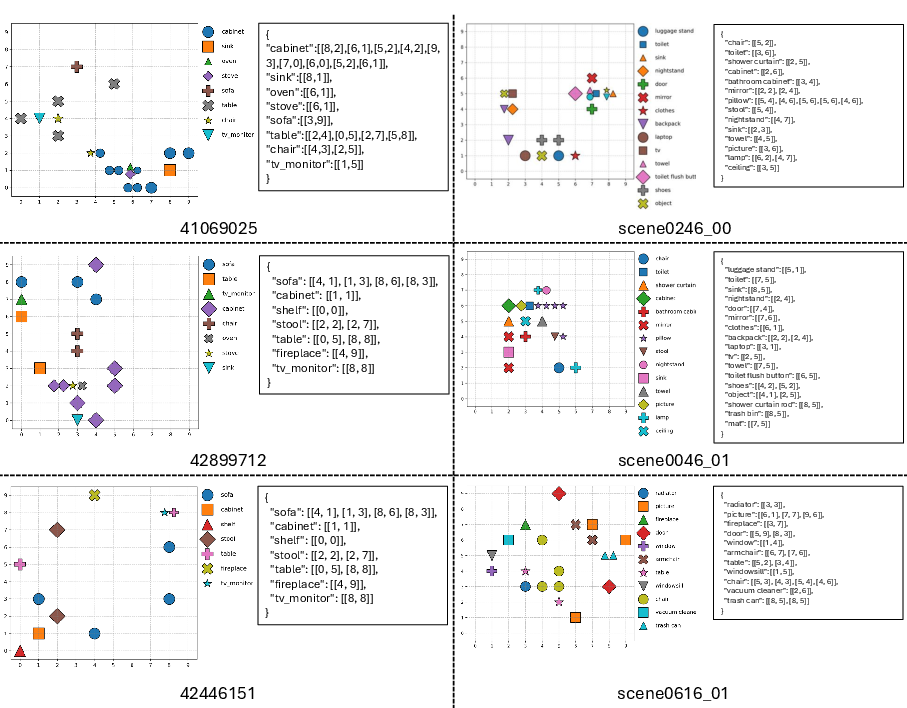
Figure 8: Cognitive map visualizations utilized for evaluation, drawn from 3D ground truth annotations.
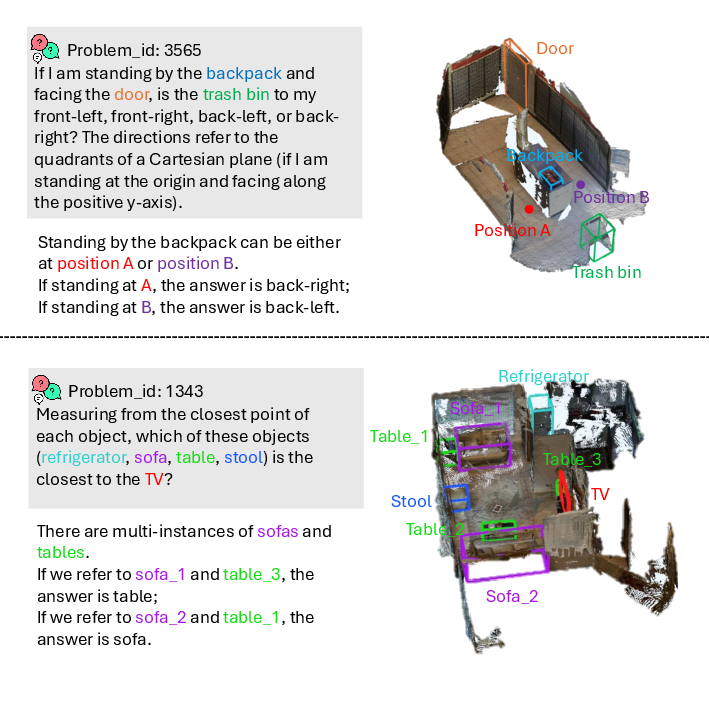
Figure 9: Examples from VSI-Bench indicating ambiguity in human reference expressions and limitations of benchmark answer quality.
Implications and Directions for Future Research
ViSRA demonstrates that domain-structured, inference-time orchestration of expert models within an agentic MLLM framework is a robust alternative to dataset-centric post-training approaches. The approach is plug-and-play, supporting seamless integration of future advances in low-level visual perception or spatial modeling tools.
Practically, ViSRA's tool-based methodology encourages robust, evidence-grounded spatial reasoning applicable to mobile, real-world deployments, robotics, or low-resource devices. Theoretically, it offers a path towards more human-like 3D spatial intelligence in multimodal AI, shifting the research focus from optimizing for narrow benchmarks to optimizing agentic reasoning strategies and tool augmentation.
Future investigations may focus on expanding the toolset (including more sophisticated geometry, affordance, or physics reasoning), optimizing agentic decision latency, and formalizing agent self-improvement protocols as new tools become available.
Conclusion
ViSRA advances the study of 3D video-based spatial reasoning in MLLMs by proposing a modular, extensible agentic framework that operates entirely at inference time, leveraging explicit spatial tools without additional training. Empirical evaluation demonstrates that ViSRA systematically enhances both established and OOD spatial reasoning tasks, offering a clear path to generalizable and upgradeable MLLM spatial intelligence, and establishing a strong incentive to further explore training-free, tool-augmented paradigms in multimodal video reasoning.