- The paper introduces a code-as-action interface using a persistent Python kernel for iterative spatial reasoning.
- It demonstrates a significant improvement (+11.2 accuracy points) over traditional spatial agents on 20 diverse benchmarks.
- The method leverages compositional code execution and iterative feedback to enable adaptive, multi-step geometric analysis.
SpatialClaw: Code as the Action Interface for Agentic Spatial Reasoning
Motivation and Problem Definition
Spatial reasoning—locating, relating, and tracking objects in 3D and 4D environments—poses a persistent challenge for multimodal VLMs, as existing architectures inadequately support compositional geometric analysis and iterative refinement. Prior tool-augmented agents employ either single-pass code execution or structured tool-call interfaces, both constraining flexible multi-step reasoning. The paper "SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning" (2606.13673) investigates the consequences of action interface design, proposing that code, efficiently orchestrated via an agentic loop, should serve as the central interface for spatial analysis.
Action Interface Characterization
Spatial agents traditionally operate through one of two modalities: (1) single-pass code, requiring the agent to commit to an entire computational strategy upfront, limiting observation-dependent adaptation; (2) structured tool-calls, exposing perception operations via APIs (e.g., JSON/XML) that restrict composition and specialized computation. Both modalities fail to enable open-ended 3D/4D reasoning, especially when task-specific geometric aggregation or iterative inspection of tool output is critical. SpatialClaw introduces persistent kernel-based code execution, transforming code into a medium for iterative spatial composition, diagnosis, and revision.

Figure 1: Three action interfaces—single-pass code, structured tool-call, and SpatialClaw's persistent Python—with increasing flexibility for spatial reasoning.
Framework Architecture
SpatialClaw consists of a persistent Python kernel loaded with input frames, perception tools (e.g., depth, segmentation), and scientific libraries (NumPy, SciPy, Matplotlib). Each agentic step emits a Python code cell executed in context, with all intermediate variables retained for later compositional access. Feedback—including printed values, variable summaries, and rendered visual evidence—is appended to the context, enabling subsequent steps to adapt to present observations. Stages in the agentic loop comprise planning (via a separate LLM session), iterative code generation and execution, feedback assembly, and answer commitment.
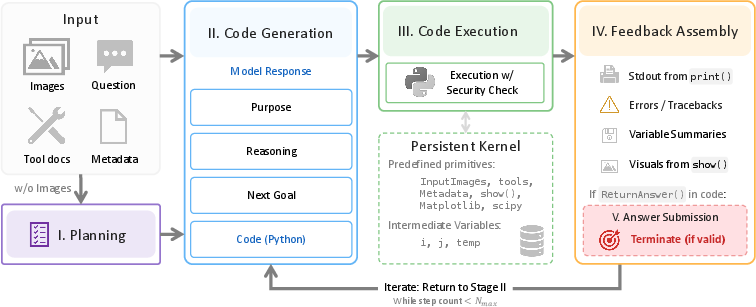
Figure 2: The SpatialClaw agentic loop coordinates iterative planning, code execution, and feedback integration in a persistent kernel.
System prompts encode spatial reasoning principles favoring metric computation, cross-validation, and intermediate inspection, eschewing task-specific customization. The planner, isolated from visual input, generates stepwise analysis plans grounded in available tools; the main agent generates actions conditioned on plan, context, and feedback.
Benchmarking and Results
SpatialClaw is evaluated on 20 diverse spatial reasoning benchmarks (single-image, multi-view, video-based 4D, general spatial, and general video), employing six open-source VLM backbones from Qwen and Gemma4 families, spanning 26B–397B parameters. Average accuracy across all tasks is 59.9%, a +11.2 point improvement over the strongest recent spatial agent baseline (SpaceTools), with consistent superiority across backbone variants and task categories. Gains are most pronounced in dynamic 4D video and multi-view settings, validating the advantage of the code action interface for multi-step geometric computation.
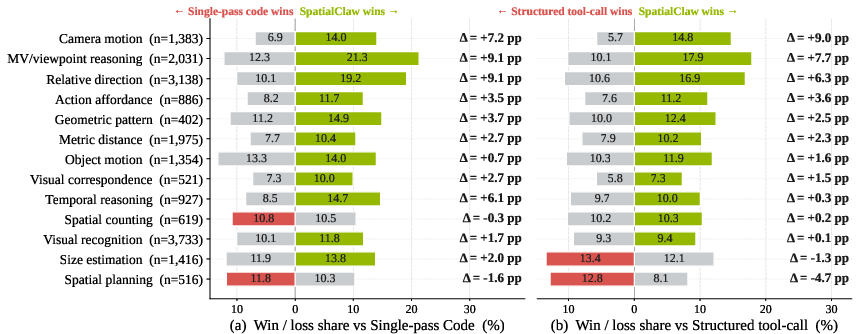
Figure 3: Pairwise win/loss margin: SpatialClaw outperforms prior interfaces in 11/13 meta-categories, concentrated in compositional geometric tasks.
Interface comparison demonstrates that neither single-pass code nor structured tool-call achieves comparable generalization or performance, even when the tool set and prompt are held fixed. Ablation studies further show that the persistent kernel's compositional flexibility persists absent predefined utility functions, confirming that the core improvements derive from code-based iterative reasoning with scientific primitives.
Analysis: Task-Adaptive Composition and Failure Modes
Analysis of kernel action traces reveals spontaneous adaptation: agents select primitives (e.g., KD-tree for proximity, dot product for direction) aligned with question semantics, without category-specific prompt engineering. LLM-judge attribution indicates that over 50% of wins against baseline methods stem from code composition, with another 19.5% attributable to iterative control flow; interface-neutral gains are limited to perceptual tasks.
Figure 3: SpatialClaw's largest gains are in multi-step spatial reasoning tasks demanding compositional computation.
Failure mode categorization identifies geometric reasoning errors as the dominant bottleneck, while perception limitations (e.g., hallucinations, tool failures) are the principal secondary cause. The remaining cases originate from misinterpretations, recovery deficiencies, or ambiguous annotations.
Practical and Theoretical Implications
SpatialClaw demonstrates the criticality of the action interface for spatial reasoning agents, showing that code-as-action with persistent kernel state enables task-adaptive, multi-step composition previously unattainable with structured APIs. The framework's training-free design facilitates out-of-the-box extension for deployed VLMs, enhancing spatial reasoning without further fine-tuning or engineering.
Theoretically, the results suggest that compositional expressiveness and iterative feedback integration are necessary conditions for agentic spatial reasoning. The framework provides a foundation for reinforcement learning and automatic error recovery in future work.
Conclusion
SpatialClaw establishes code as the central action interface for spatial reasoning, outperforming all structured and single-pass alternatives across a comprehensive benchmark suite and backbone variants. The expressiveness and adaptability of persistent kernel code, rather than toolset augmentation or backbone tuning, drive substantive performance improvements. Further research should prioritize compositional interface design and systematic error recovery to advance spatial agent intelligence.

