- The paper demonstrates that probe-and-refine tuning significantly improves coding agent resolve rates from 25.5% to 33.0% by refining repository guidance.
- The paper details a method using synthetic bug-fix probes and iterative guidance updates that enhance evaluation coverage and actionable workflows.
- The paper finds that model-specific calibration of guidance is crucial, as mismatched tuning can harm performance and impede cross-model transferability.
Probe-and-Refine Tuning for Repository Guidance in Coding Agents
Motivation and Problem Framing
The operational effectiveness of LLM-based coding agents in real-world software engineering tasks fundamentally depends on access to repository-level procedural and structural knowledge not embedded in code. Traditionally, engineers use AGENTS.md or similar context files to supply actionable guidance. However, previous studies have yielded conflicting results regarding whether such files improve agent performance, with some reporting efficiency gains and others reporting diminished resolve rates when LLM-generated guidance is applied. This paper posits that the decisive variable is not the concept of guidance itself, but the method of its generation.
Probe-and-Refine Tuning Procedure
The central contribution is the probe-and-refine tuning pipeline, which iteratively refines repository guidance using synthetic probe tasks and direct single-shot diagnosis via LLM calls, absent any agentic tool use or multi-step reasoning.
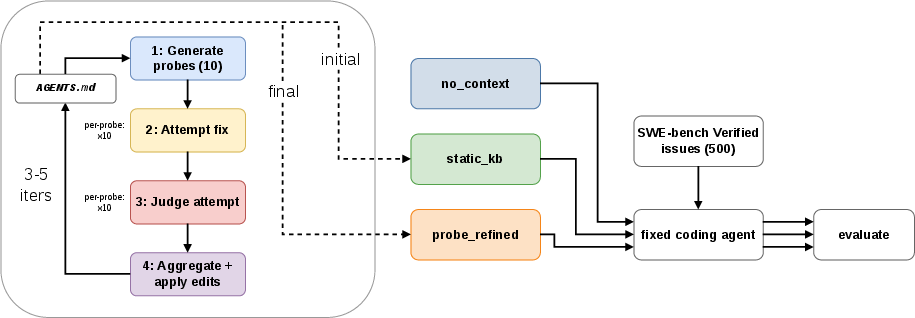
Figure 1: Pipeline illustrating the transformation from static knowledge base to refined guidance using probe-and-refine tuning and synthetic probes.
The procedure unfolds as follows:
- Probe Generation: Ten diverse, synthetic bug-fix tasks are created per iteration, targeting different subsystems and failure modes, carefully deduplicated from prior probes to avoid contamination.
- Attempt and Judge: For each probe, a candidate patch is generated and then critically evaluated in a single shot, with actionable edits proposed for guidance improvement.
- Aggregated Guidance Update: A deterministic merging and editing process applies up to five guidance updates per iteration, with explicit capping and trimming for compactness.
This loop typically converges in 3–5 iterations, yielding repo-specific instructions in a concise artifact (≤3000 characters), reusable for subsequent agent runs.

Figure 2: Guidance evolution: generic advice is replaced by repo-specific diagnostic and navigation workflows, e.g., subsystem tracing instructions and test path annotations, over several iterations.
Experimental Design and Evaluation
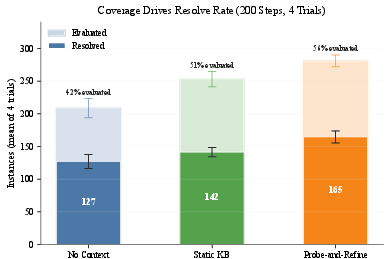
The experimental apparatus employs the SWE-bench Verified benchmark, a fixed coding agent scaffold, and evaluates three context conditions: unguided baseline, static knowledge base, and probe-refined guidance across 500 instances and four independent trials, primarily using Qwen3.5-35B-A3B (Mixture-of-Experts 35B, 16k-token context truncation for uniformity). Statistical rigor is ensured via mixed-effects logistic regression accounting for instance and trial variance.
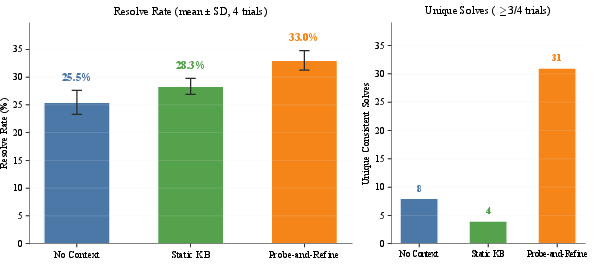
Figure 3: Mean resolve rates across four trials; probe-and-refine guidance yields statistically significant improvement over both baselines (p<0.001).
Numerical Results
Mechanistic Insights
Analysis of patch timing illustrates that probe-and-refine guidance enables agents to utilize late steps productively—unlike unguided agents, which exhaust useful actions early and rely on ineffective fallback mechanisms.
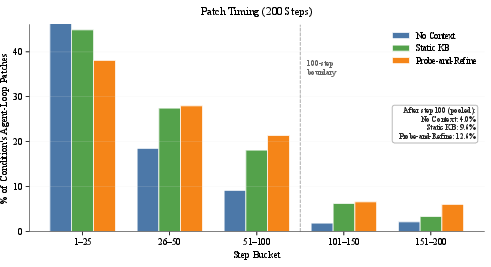
Figure 5: Distribution of patch production timing: probe-and-refine agents generate a substantial fraction of patches after 100 steps, reflecting workflow-driven exploration.
Localization analysis confirms that probe-refined guidance primarily aids instances where symbolic mismatch between problem statement and actual fix location exists, disproportionately benefitting repositories with idiosyncratic internal structure.
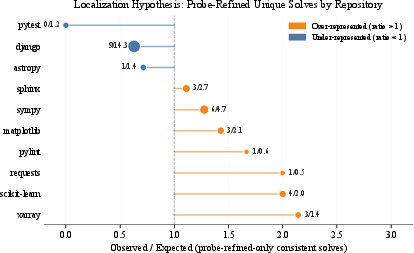
Figure 6: Ratio of probe-refined-only solves to base-rate, sorted by repository; benefits are concentrated in repositories with less predictable file layouts.
Step Budget Moderation
Guidance effectiveness is contingent on the agent's step budget. At small budgets, all conditions are equivalent; the benefits of workflow-driven guidance materialize only as the agent is permitted more steps. Static-KB activates at 50 steps; probe-and-refine improves up to 200 steps.
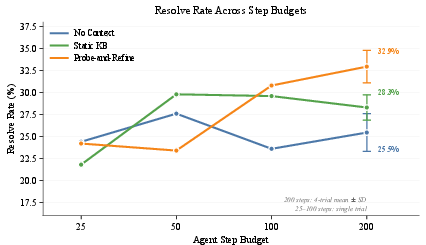
Figure 7: Resolve rate scaling with step budgets: unstructured exploration saturates quickly, whereas probe-and-refine guidance continues to yield gains with increasing steps.
Cross-Model Generalization and Model Fit
Applying probe-and-refine guidance to capacity-constrained models (e.g., NVIDIA-Nemotron-3-Nano-30B-A3B) reveals degraded tuning loop efficacy: guidance calibrated for one model interferes with another, causing catastrophic coverage loss while maintaining per-patch precision. This demonstrates that refined repository guidance is not transferable between models with divergent behavioral profiles; guidance encodes behavioral calibration rather than generic repository knowledge.
Implications and Speculative Insights
- Instruction Quality: Guidance quality is as significant as model capability or step budget in agent reliability; improvement comes from structurally actionable and workflow-specific content, not from generic length expansion.
- Model-Practitioner Guidance Match: Guidance must be tuned with the consuming model and deployed with an appropriate step budget to realize benefits. Mismatched guidance can actively harm agent performance.
- Prompt-Level Activation: Empirical evidence suggests prompt-level iterative refinement may activate latent operational capabilities analogous to broad behavioral effects seen in narrow fine-tuning, but this remains an interpretive hypothesis.
Limitations and Open Questions
Key constraints include lack of ablation isolating guidance length effects, single-model demonstration, probe sensitivity analysis, and benchmark repository concentration (notably Django-heavy). Cross-model generalization has only been surveyed in transfer failures; positive transfer remains untested.
Conclusion
Probe-and-refine tuning demonstrates that iterative refinement of repository guidance, driven by synthetic diagnostic probes and single-shot LLM calls, significantly improves coding agent resolve rates and coverage on SWE-bench Verified. The improvement arises from better localization and actionable workflows, not from increased patch precision or generic length expansion. Guidance is model-specific; practitioners must calibrate guidance with the target model and provide a budget aligned with prescribed workflows. Future theoretical exploration should probe mechanistic parallels with prompt-level cluster activation and further investigate optimal guidance transfer across model families.