- The paper presents SWE-Explore, a benchmark that isolates repository exploration by ranking code regions to improve evidence retrieval for automated repair.
- It employs aggregated LLM agent trajectories and rigorous metrics including line-level precision, recall, and nDCG to assess exploratory behaviors.
- Experimental results show that agentic explorers outperform traditional retrieval methods, though improving line-level recall remains a key challenge.
SWE-Explore: Isolating Repository Exploration for Coding Agent Evaluation
Motivation and Problem Setting
Repository-level coding benchmarks have enabled the rapid progress of automated coding agents; however, these benchmarks often reduce evaluation to a binary pass/fail metric, disregarding crucial intermediate capabilities like repository understanding, context retrieval, code localization, and bug diagnosis. This holistic evaluation protocol prohibits a decomposition of failure modes, effectively masking the distinction between failures in exploring the relevant code versus failures in patch synthesis. Such an approach limits the visibility into agentic strengths and weaknesses, especially regarding the agent's ability to surface the precise code evidence necessary for successful repair.
SWE-Explore addresses this evaluative shortcoming by introducing a benchmark that isolates the repository exploration task. Given a repository and an issue, an explorer must return a ranked list of relevant code regions (with a fixed line budget). This formulation abstracts away patch generation and validation, focusing solely on the exploratory behaviors of coding agents. The goal is to enable direct comparison among retrieval baselines, long-context selectors, agentic explorers, and other localization systems, with grounded metrics that correlate with downstream repair outcomes.
Benchmark Design and Data
SWE-Explore leverages three established benchmarks—SWE-bench Verified, SWE-bench Pro, and SWE-bench Multilingual—as data sources, but applies a solution-verification filter to retain only those instances for which at least two independent agent trajectories successfully resolve the issue. The resulting evaluation set comprises 848 issues spanning 10 programming languages and 203 unique repositories, providing both Python-centric and multilingual repository coverage.
Across this dataset, each instance involves, on average, 4.3 ground-truth files, 4.7 read regions, and approximately 1,578 relevant lines—embedded within codebases of substantial scale (759 files and 180k non-test lines on average). The distribution over programming languages is shown below.
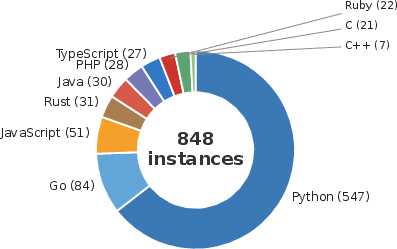
Figure 1: SWE-Explore instances are diverse, covering 10 languages across 848 issues.
To obtain reliable, fine-grained ground truth, the authors collect observable "read actions" from the trajectories of strong LLM-based coding agents (e.g., GPT-5.4, Gemini-3-Pro, Sonnet-4.6, GLM-5.1, Kimi-K2.6). These read actions—mapped to explicit file/line intervals—are aggregated, with core evidence defined as the intersection of regions repeatedly surfaced in successful trajectories. LLM-assisted refinement further promotes optional evidence to the core as necessary, with manual auditing ensuring relevance and precision.
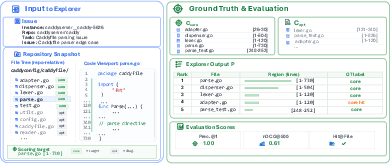
Figure 2: Example SWE-Explore instance illustrating how core regions are distilled from agent trajectories.
Metrics for Repository Exploration
SWE-Explore introduces a comprehensive metric suite for evaluating ranked region predictions against the ground-truth core evidence:
- Line-level Precision/Recall/F1: Mapping coverage at fine granularity.
- File/Region Hit Rates: Measuring whether the agent surfaces the correct files or regions at all.
- nDCG under Line Budget: Ranking utility is measured by discounted cumulative gain, reflecting the benefit of surfacing evidence early within a bounded context size.
- Context Efficiency and Noise: Quantifying the proportion of selected lines that are genuinely relevant, as opposed to off-target or redundant evidence.
- First Useful Hit: Indexing how rapidly evidence is surfaced.
To validate external consistency, a restricted-context downstream protocol is implemented: the only code visible to a fixed code patcher is the explorer's selected context, and patch success is then evaluated using the original test harness.
Experimental Results
Explorer Comparison and Key Findings
Experiments compare four explorer families: classical retrieval baselines (BM25, TF-IDF), a RAG-based dense retriever, general-purpose coding agents (e.g., Claude Code, Mini-SWE-Agent, OpenHands, Codex, AweAgent), and specialized localization systems (e.g., AutoCodeRover, LocAgent, OrcaLoca, CoSIL).
- Agentic explorers decisively outperform non-agentic retrieval: TF–IDF, BM25, and the RAG baseline achieve metrics close to random, failing to reach the ground-truth files for most issues. In contrast, agentic explorers routinely achieve high file-level hit rates and superior nDCG scores.
- Line-level recall is the core bottleneck: Despite strong file-level accuracy, line recall and span coverage are significantly lower across all non-oracle agents (typically between 0.14–0.23), indicating that surfacing the exact evidence necessary for repair remains a challenge even for sophisticated agents.
- LLM backbone affects performance but does not remedy bottlenecks: Across different LLMs, the coverage and ranking profiles are similar, with the GPT-family leading but still failing to close the recall gap.
- Specialized localizers help when exploration is broadened, not by mere precision: Agents like CoSIL, which incorporate iterative code-graph search, can improve recall, but conservative localizers may under-cover even when precise.
- General coding agents are homogeneous in exploration quality: Differences among agents like Claude Code, OpenHands, and Mini-SWE-Agent are minor relative to their contrast against retrieval baselines.
Metric–Outcome Correlation and Robustness
- Context efficiency, file hit, and early surface metrics show highest correlation to downstream repair success: For instance, context efficiency demonstrates a Pearson correlation of 0.950 with downstream resolve rate, confirming its evaluative value.
Validation experiments further reveal that missing core context is far more damaging, in terms of downstream resolve rate, than the injection of redundant/irrelevant context, especially in easier subsets of the benchmark.
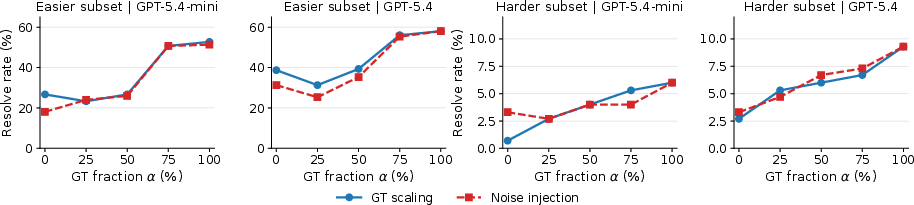
Figure 3: Sweeping context degradation highlights the threshold-like effect of missing core context on repair success.
Theoretical and Practical Implications
By structuring repository exploration as a standalone, rank-sensitive, line-level selection task, SWE-Explore formalizes agentic repository reading as a measurable axis of performance. This supports the development and comparison of specialized explorers, context compressors, and retrieval-augmented architectures, isolating the precondition of sufficiency in repository evidence exposure before synthesis is evaluated.
Practically, these findings call for targeted enhancement of line-level recall and efficient region discovery within coding agents. The results provide guidance for future research on long-context management, evidence aggregation mechanisms, iterative search, and the integration of symbolic/stateful repository navigation.
From a theoretical perspective, SWE-Explore bridges the gap between retrieval and patching assessment, revealing that holistic success/failure evaluation can obscure critical deficits in evidence gathering capabilities; optimizing patch generation alone will remain insufficient without parallel advances in exploration.
Future Directions
Potential extensions fostered by SWE-Explore include:
- Generalization to previously unsolved issues: Extension to instances currently beyond state-of-the-art agents' reach.
- Dynamic trajectory-guided supervision: Incorporation of interactive and adversarial trajectories to further refine exploration targets.
- Integration with experience-driven and debate-based multi-agent frameworks: Leveraging heterogeneous agent behaviors for ensemble evidence discovery.
- Context compression and expansion techniques: Systematic exploration of redundancy-control versus recall in line budgeted scenarios.
Conclusion
SWE-Explore introduces and standardizes repository exploration as a central, distinct evaluation target for coding agents, supported by trajectory-derived, manually audited line-level supervision and validated by downstream resolve rates. The benchmark reveals the decisive role of exploration in agentic repair, the limitations of current models at the line granularity, and the inadequacy of basic retrieval strategies for repository-scale evidence gathering. SWE-Explore thus constitutes a critical infrastructure for accelerating progress on robust, generalizable, and effective exploratory behaviors in automated software engineering systems.