One Tool Is Enough: Reinforcement Learning for Repository-Level LLM Agents
Abstract: Locating the files and functions requiring modification in large open-source software (OSS) repositories is challenging due to their scale and structural complexity. Existing LLM-based methods typically treat this as a repository-level retrieval task and rely on multiple auxiliary tools, which overlook code execution logic and complicate model control. We propose RepoNavigator, an LLM agent equipped with a single execution-aware tool-jumping to the definition of an invoked symbol. This unified design reflects the actual flow of code execution while simplifying tool manipulation. RepoNavigator is trained end-to-end via Reinforcement Learning (RL) directly from a pretrained model, without any closed-source distillation. Experiments demonstrate that RL-trained RepoNavigator achieves state-of-the-art performance, with the 7B model outperforming 14B baselines, the 14B model surpassing 32B competitors, and even the 32B model exceeding closed-source models such as Claude-3.7. These results confirm that integrating a single, structurally grounded tool with RL training provides an efficient and scalable solution for repository-level issue localization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces RepoNavigator, a smart helper built on a LLM that can find the exact places in a huge codebase where a bug needs to be fixed. Instead of using many different tools, RepoNavigator uses just one simple but powerful tool that follows how code actually runs: “jump to definition.” The model is trained with reinforcement learning (a trial-and-error method) so it gets better at navigating code without needing a stronger “teacher” model.
Objectives
Here are the main goals of the paper, explained simply:
- Build a code navigation agent that uses only one tool (“jump to definition”) that matches how programs really execute.
- Train the agent to find the right files and functions related to a bug (issue localization) using reinforcement learning, without copying from closed-source models.
- Show that this simple design can beat more complicated, multi-tool systems and even larger models on real benchmarks.
Methods and Approach
To make the ideas clear, think of a big code repository like a massive library with many books (files) and chapters (functions). The problem is figuring out exactly which pages you need to read or edit to solve a complaint (a bug report).
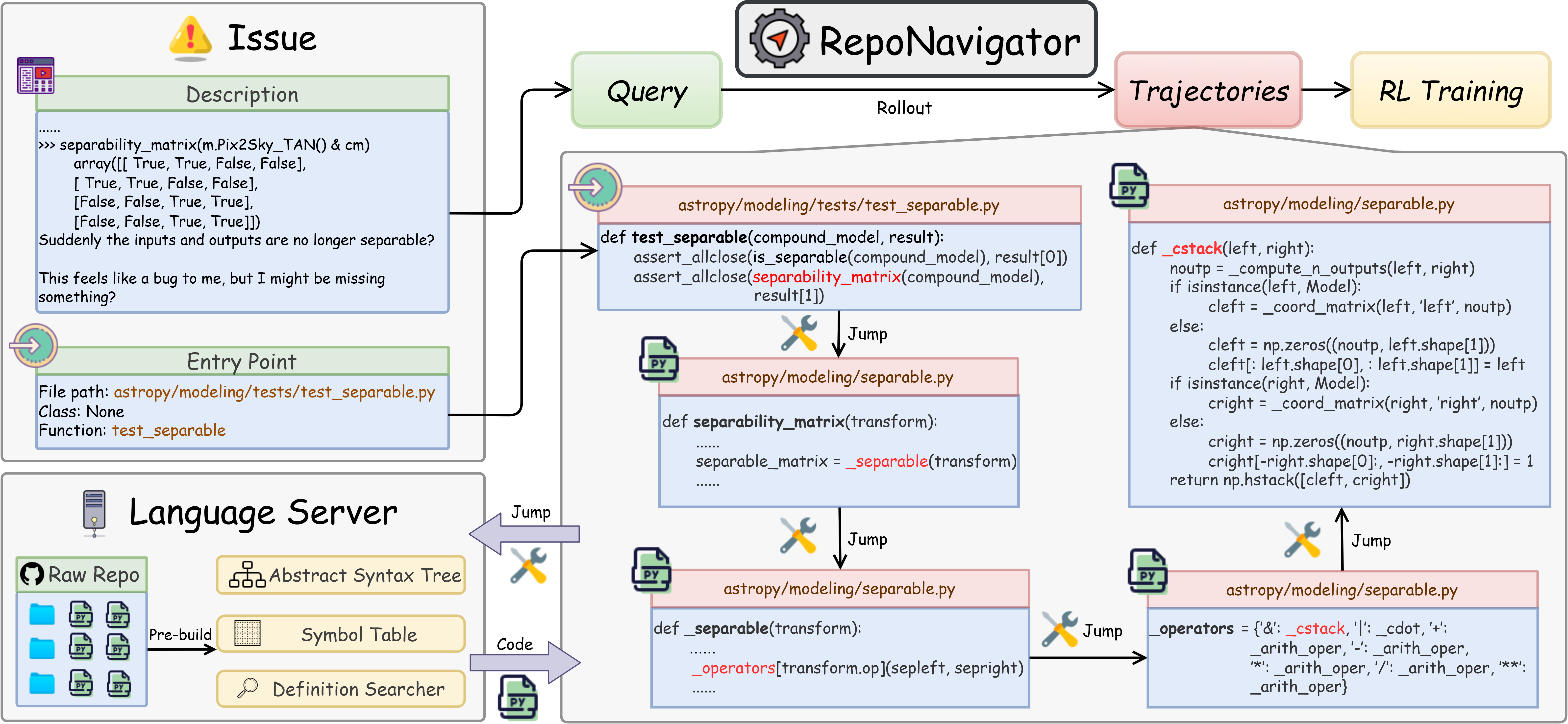
What is the task? Issue localization
Issue localization means: given a bug report, point to the specific files and functions likely causing the problem. This doesn’t fix the bug yet—it finds where to look. That’s useful because big codebases are too large to read all at once.
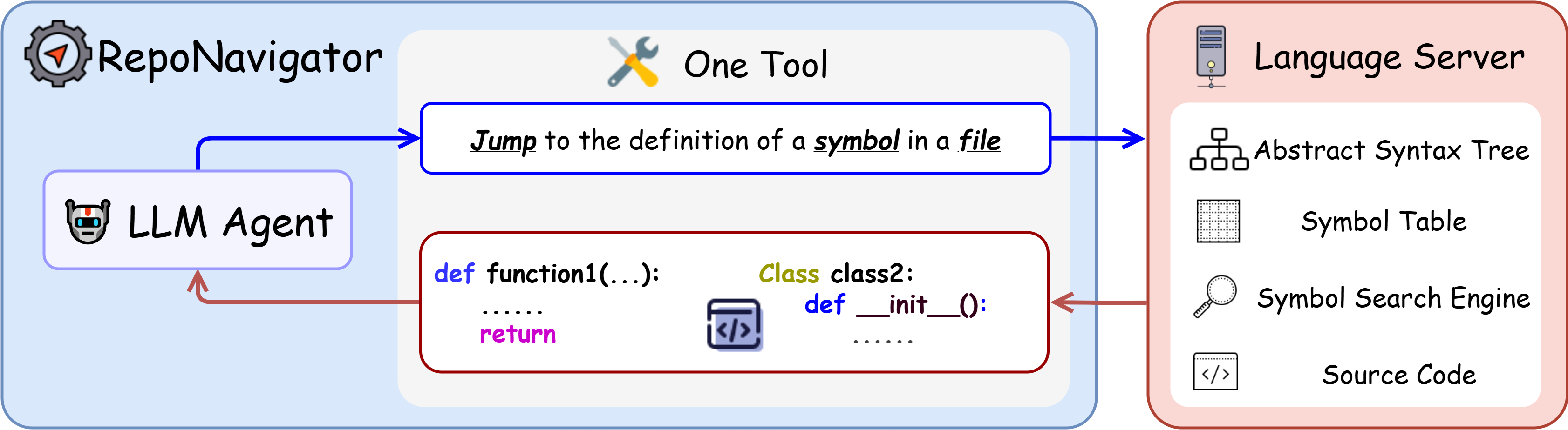
The single tool: “jump to definition”
- Imagine you see a function name in code and click it to go to its original definition—just like clicking a link on a webpage. That’s “jump to definition.”
- RepoNavigator uses a language server (a code-understanding helper) to do this reliably across files. It follows the code’s actual execution flow: when a function calls another, you jump to the definition of the called function, and so on.
- This tool keeps navigation focused and reduces confusion from using many different tools.
How the agent thinks and acts
RepoNavigator works in a loop:
- Reason: Think in natural language about what to look at next.
- Act: Make a structured tool call (a small JSON command) to jump to a symbol’s definition.
- Observe: Read the code snippet returned and continue thinking.
- Repeat until it decides which files/functions are relevant to the bug.
This “reason → act → observe” cycle helps the agent gather the right pieces of the code step by step.
How it learns: reinforcement learning (RL)
- The agent tries many navigation paths on training examples. For each try, it gets a score (reward).
- The reward is higher when:
- Its predicted locations overlap more with the true locations (measured by overlap metrics like F1 and IoU—think “how much did we correctly match the answer set?”).
- Its tool calls are correct and successful (no broken formats or invalid symbols).
- They use a method called GRPO (Group Reference Policy Optimization). In simple terms: it pushes the model toward actions that earn better rewards, while also keeping it close to its previous behavior so it doesn’t change too wildly in one step.
How it’s tested
- Benchmarks: SWE-bench-Verified and SWE-bench-Pro, which contain real GitHub bugs with known “golden patch” locations.
- Metrics: They report recall and precision, but focus on better-balanced scores like Sample-F1 and IoU (which tell you how much the predicted set overlaps with the true set).
Main Findings
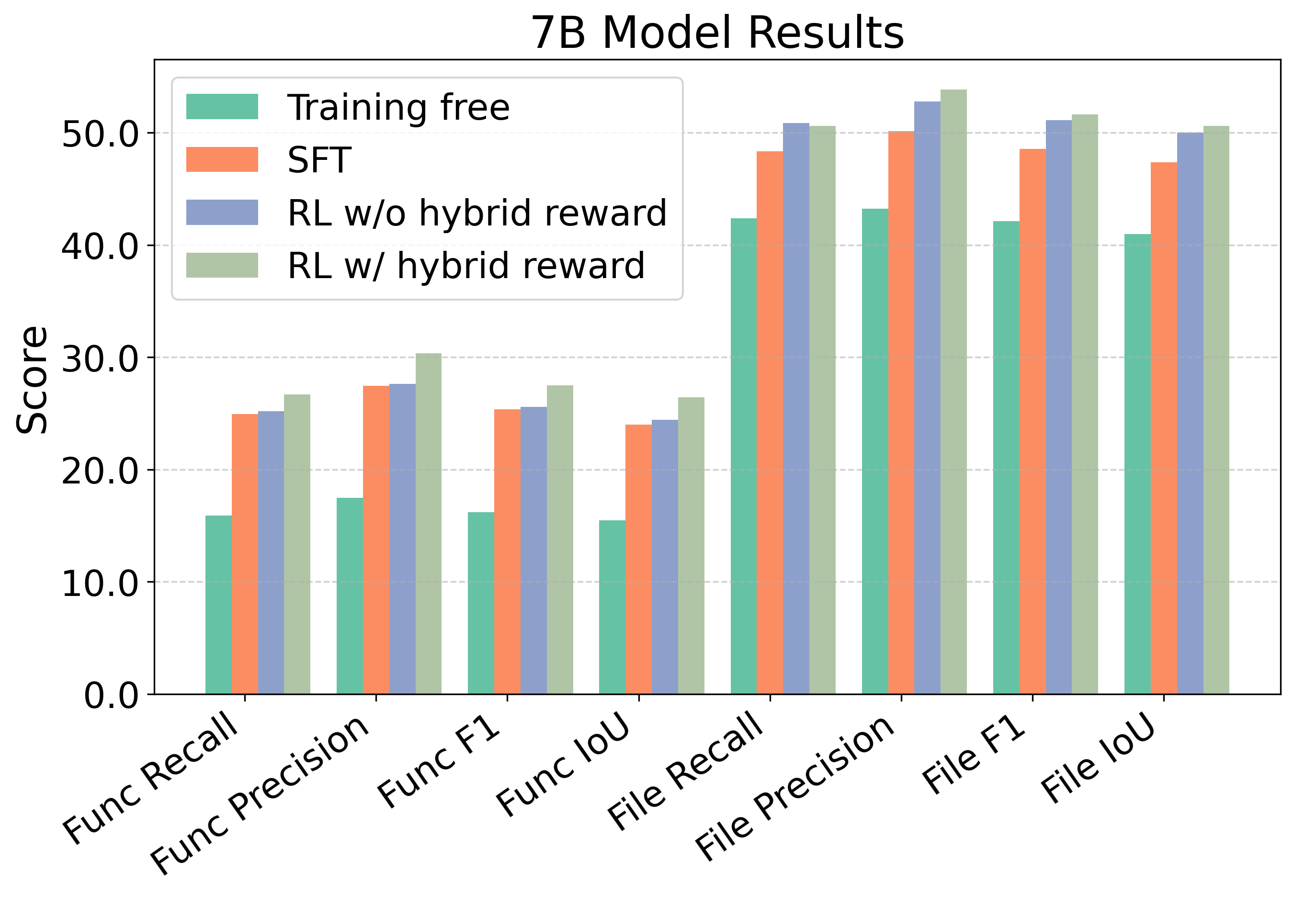
The authors report strong performance improvements:
- Using only the “jump” tool, RepoNavigator trained with RL beats other systems that use multiple tools.
- A 7B model (smaller) trained with RL outperforms several 14B baselines; the 14B version beats 32B baselines; and the 32B version can even rival or exceed some closed-source models on their tests.
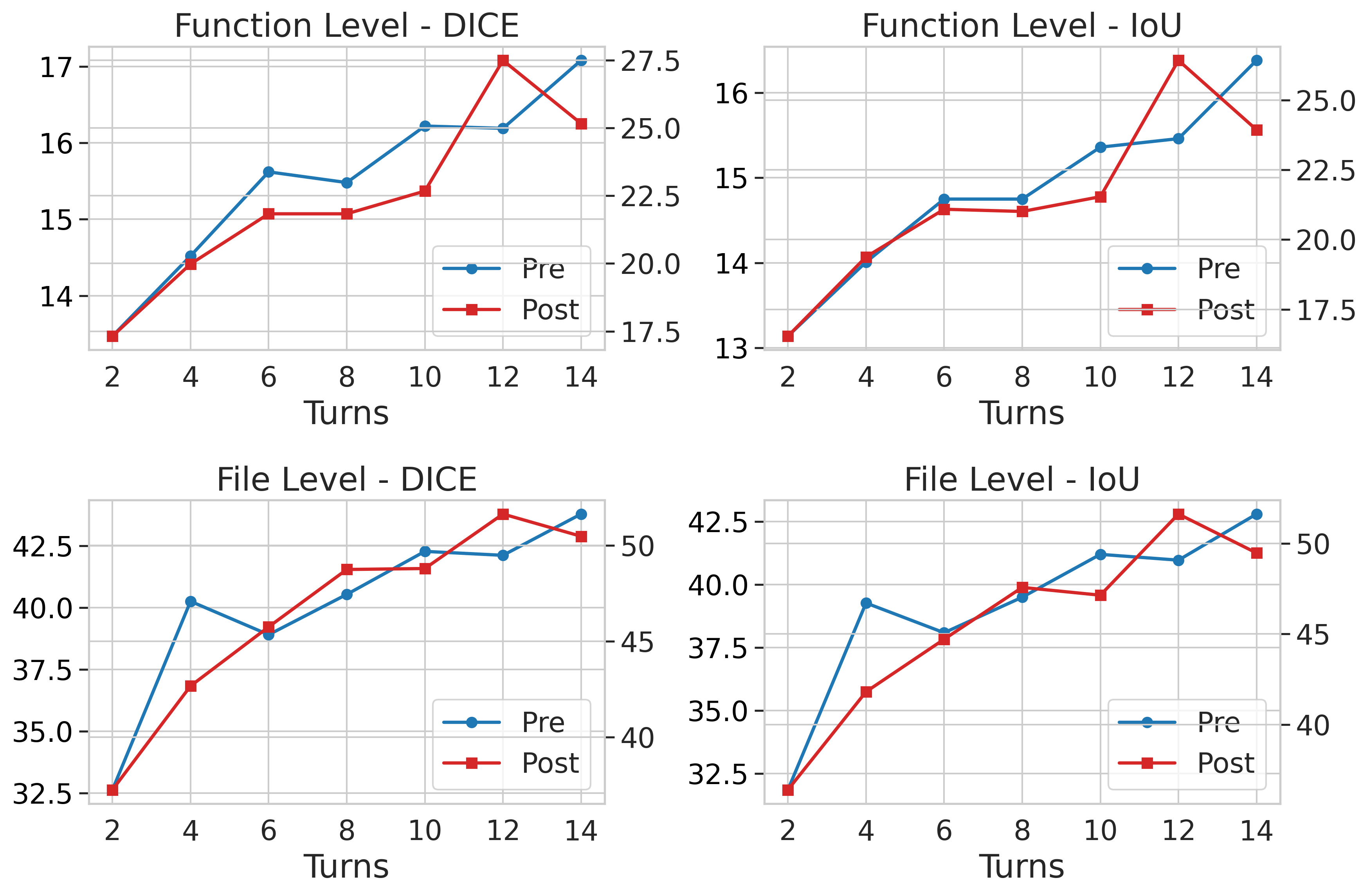
- Allowing more “jump” steps generally improves results—like letting the agent follow more links to understand the code better.
- RL training directly (without a teacher) works well. It performs better than methods that only do self-generated supervised finetuning (RFT).
- Including “tool-call success rate” in the reward is important—the model learns not just what to look for, but how to use the tool correctly.
- Adding extra tools (like separate class/function search or structure dump tools) did not help; the single, execution-aware tool was more reliable and simpler to control.
Why these results matter:
- Fewer tools mean fewer chances to make mistakes and less confusion.
- A single tool aligned with real execution makes the agent’s path more precise, reducing false leads.
- Training with verifiable rewards (did you find the right files/functions?) scales better than training by actually fixing and running patches, which is expensive.
Implications and Impact
- Practical benefit: Developers can use RepoNavigator to quickly narrow down where a bug lives in huge codebases, saving time and making fixes easier.
- Design lesson: Building fewer, more capable tools that match how code truly runs (like “jump to definition”) can beat complex multi-tool setups.
- Training insight: Reinforcement learning with simple, verifiable rewards is a powerful way to teach LLM agents to use tools effectively.
- Scalability: Even mid-sized open-source models can achieve top performance with the right tool and training.
- Future directions: Extend this approach beyond Python to other programming languages, and integrate it into full bug-fixing pipelines to further increase automation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research:
- Clarify and evaluate the agent’s bootstrap step: how are the initial
file_pathandsymbolselected without global search tools? Specify the entry-point derivation (e.g., from issue text, tests, stack traces), measure its accuracy, and analyze its impact on end-to-end performance. - Quantify language server fidelity on real-world Python: provide coverage and failure rates of the jump tool across dynamic Python features (e.g., monkey patching, runtime imports, reflection,
eval,__getattr__, plugin systems), and identify classes of bugs where static resolution fundamentally fails. - Extend beyond Python: demonstrate portability of the single-tool paradigm to other languages (e.g., Java, TypeScript, C++), including adapting jump semantics to language-specific resolution rules and cross-language repositories.
- Resolve ambiguity in multi-definition cases: define and evaluate strategies to disambiguate symbols with multiple valid definitions (aliases, re-exports, union types), including policies for branching, ranking, or exploration when
jumpreturns a set. - Make observation sourcing explicit: specify how the agent acquires “structured observations” (code snippets, error messages) and whether tests are executed during localization; evaluate different observation providers and their effect on performance.
- Calibrate and ablate reward components: detail the weighting between
DICEandS(τ)(currently an unweighted sum); run sensitivity analyses to determine optimal weights, trade-offs between conservativeness and recall, and robustness to noisy tool-call success signals. - Provide complete GRPO details for reproducibility: fix the corrupted objective equation, specify advantage estimation, reference grouping, value baselines, KL schedules, and implementation choices (e.g., truncation, clipping, normalization).
- Address evaluation validity and multiplicity of ground truths: golden patches may not uniquely identify all correct locations. Build or adopt benchmarks with multi-annotated or alternative valid localization sets, and measure the method’s ability to find any sufficient set.
- Conduct a rigorous data leakage audit: quantify overlap between training (SWE-smith) and evaluation (SWE-bench-Verified, SWE-bench-Pro), release deduplication scripts, and report leakage-sensitive splits to support reliable generalization claims.
- Report efficiency metrics: measure latency, token usage, number of tool calls, wall-clock compute, and memory footprint; compare single-tool vs multi-tool pipelines on these dimensions to substantiate efficiency claims.
- Characterize performance vs repository properties: analyze how localization accuracy scales with repo size, topology (import graph depth), presence of type hints, test availability, and dynamic features; identify regimes where the approach degrades.
- Study tool-calling turn limits and diminishing returns: move beyond the qualitative “more turns helps” claim to identify optimal turn budgets, early stopping criteria, and failure modes (loops, redundant jumps) under constrained budgets.
- Investigate exploration strategies: compare greedy vs stochastic inference, temperature schedules, entropy bonuses, and curiosity signals for better long-horizon tool-chaining without sacrificing precision.
- Evaluate hybrid single-tool extensions: test whether augmenting
jumpwith a single “capable” project index (e.g., static call graph, symbol table) improves recall while keeping action space small, instead of adding many narrow tools. - Strengthen end-to-end validation: run full SWE-bench issue resolution pipelines (including patch generation and test execution) with and without RepoNavigator localization to quantify downstream gains across diverse repos and issue types.
- Build an error taxonomy for
jumpfailures: log and categorize resolution errors (e.g., missing definitions, third-party packages, generated code, vendor folders), and design mitigations (dependency installation, stubs, fallback heuristics). - Handle external dependencies: evaluate symbol resolution that crosses into installed packages (site-packages), version-specific APIs, or vendored code; specify environment setup and language server configuration needed for accurate cross-boundary jumps.
- Improve NL-to-code grounding: analyze how issue descriptions are mapped to candidate entry symbols and files; compare retrieval-augmented prompting, stack-trace extraction, and semantic linking methods to increase initial localization accuracy.
- Compare language servers and settings: test multiple Python LSs (e.g., Jedi, Pylance/Pyright configurations), type-checker strictness levels, and stub libraries to determine the best resolution backend and its generalization.
- Balance conservativeness vs coverage: since RepoNavigator is “more conservative,” study methods (reward shaping, thresholds, calibration) to increase recall without degrading IoU/S-F1, and quantify the trade-offs.
- Assess training data filtering effects: the policy of discarding samples with zero scores may bias the training distribution; analyze its impact and propose reweighting or curriculum strategies to avoid overfitting to “easy” localizations.
- Specify termination criteria: clearly define and evaluate stopping rules for the reasoning–action loop (e.g., confidence thresholds, max steps, no-new-info heuristics), and measure their effect on precision and runtime.
- Broaden ablations on tool sets: the
GetClass/GetFunc/GetStrucadditions may not represent strong multi-tool baselines; run more realistic comparisons with modern retrieval tools (semantic search, cross-file grep, call graph builders) under the same RL framework. - Measure sensitivity to type annotations: quantify how the presence/absence and quality of type hints impact jump resolution and localization accuracy; propose methods (e.g., on-the-fly type inference or stub generation) to mitigate missing annotations.
- Cover non-symbol bug sources: many fixes involve configuration files, data schemas, templates, and test assets. Define how a symbol-centric tool can surface such locations or whether a minimal non-symbol tool is needed.
- Release full reproducibility artifacts: publish code, data splits, tool-call grammars, hyperparameters, and training/inference scripts to enable independent verification of results and facilitate adoption by the community.
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling (language servers, LSP clients, existing LLMs) and modest integration effort. They leverage RepoNavigator’s single-tool jump design and RL-trained behaviors for repository-level issue localization.
- IDE plugin for issue localization and execution-aware navigation (Sector: Software/Developer Tools)
- Use case: Assist developers in large repos by suggesting the most likely files/functions impacted by a reported bug or failing test; provide jump-driven call-chain exploration from entry points.
- Tools/products/workflows: VS Code/JetBrains plugin that wraps RepoNavigator; integrates with a Python language server (e.g., Pyright) for symbol resolution; constrained decoding ensures valid tool calls; presents localized candidates with Dice/IoU confidence.
- Assumptions/dependencies: Availability and correctness of the language server for the target language; primarily Python today; repo must be accessible and indexed; agent needs inference compute and context window management.
- CI/CD triage bot for failing tests and new issues (Sector: Software/DevOps)
- Use case: Automatically localize fault regions when unit/integration tests fail or when new GitHub/Jira tickets arrive; attach suspected files/functions to tickets and route to code owners.
- Tools/products/workflows: GitHub Action or Jenkins step invoking RepoNavigator; emits JSON of suspected locations; integrates with CODEOWNERS for assignment; links to diffs and relevant symbols via LSP.
- Assumptions/dependencies: Deterministic test failures or clear issue descriptions; access to repo and test artifacts; reliable symbol resolution under dynamic Python patterns.
- Repair pipeline front-end to boost resolution rates (Sector: Software/Automation)
- Use case: Replace heuristic/multi-tool localization stages in agents like Agentless/OpenHands/SWE-Agent to improve downstream patching success.
- Tools/products/workflows: Drop-in localization module that outputs candidate files/functions for repair models; uses RepoNavigator’s RL-trained reasoning-action loop; validated on SWE-bench metrics.
- Assumptions/dependencies: Repair component still required; patch validation (Docker/test suites) remains compute-heavy; localization quality drives—but does not guarantee—successful fixes.
- Execution-aware code search and call-chain exploration (Sector: Software/Knowledge Management)
- Use case: Enhance code search by following symbol definitions across modules, producing concise execution paths and dependency chains from a given entry point.
- Tools/products/workflows: Internal developer portal API; jump-based traversal to generate call graphs and “access scopes” for features/bugs; attach to code review diffs.
- Assumptions/dependencies: Static analysis must approximate runtime binding; complex metaprogramming/dynamic imports may reduce precision.
- Developer onboarding and feature-impact assessment (Sector: Education/Software)
- Use case: For new team members, automatically produce the minimal set of files/functions that matter for a given feature or bug, reducing cognitive load and ramp time.
- Tools/products/workflows: Onboarding assistant that starts at feature entry points and recursively applies jump to produce a navigable guide; embeds RepoNavigator’s reasoning traces.
- Assumptions/dependencies: High-quality issue/feature descriptions; availability of LSP indices; Python-focused until extended.
- Security/compliance grep-with-structure (Sector: Security/Software)
- Use case: Quickly localize definitions and data sinks related to sensitive symbols (e.g., authentication tokens, PII handlers) to scope audits and remediations.
- Tools/products/workflows: CLI or service that takes sensitive symbol names and generates jump-driven access scopes; feeds static analyzers or rule engines.
- Assumptions/dependencies: Symbol names must be discernible; static resolution limits on dynamic flows; best used as a pre-filter for deeper taint/flow analyses.
- Academic benchmarking and training for tool-augmented agents (Sector: Academia)
- Use case: Reproduce RLVR-style training with verifiable rewards (Dice/IoU) for repository tasks; compare SFT/RFT vs GRPO outcomes; study “single unified tool” design.
- Tools/products/workflows: Training scripts using verl + vLLM; SWE-bench(-Verified/Pro) datasets; enforce JSON grammar via constrained decoding; report Sample-F1/IoU.
- Assumptions/dependencies: Compute availability (A100s recommended); curated datasets with ground-truth locations; reward signals from set comparisons.
- Open-source project triage assistant (Sector: Daily life for OSS maintainers)
- Use case: Automatically reply on new GitHub issues with suspected code locations and navigation pointers, helping maintainers handle volume.
- Tools/products/workflows: GitHub App using RepoNavigator; posts localization suggestions and links; maintainers validate or refine.
- Assumptions/dependencies: Issue text must be sufficiently descriptive; community acceptance and governance policies for bot suggestions.
Long-Term Applications
The following opportunities require further research, scaling, language coverage, or operational hardening before broad deployment.
- End-to-end RL agents for full patch generation with scalable verification (Sector: Software/Automation)
- Use case: Train agents that both localize and repair using RLVR-like frameworks, reducing reliance on expensive Docker/test execution by leveraging proxy rewards and semi-verification.
- Tools/products/workflows: Hybrid reward design combining localization Dice/IoU, tool-call success, and lightweight static checks; staged curriculum (localize → propose → validate).
- Assumptions/dependencies: New reward shaping for patch quality; scalable sandboxing; safety/rollback mechanisms; robust handling of multiple valid patches.
- Polyglot language support via LSPs and cross-language resolution (Sector: Software/Enterprise)
- Use case: Extend jump-based agents to Java, C/C++, TypeScript, Go, and polyglot monorepos; traverse cross-language boundaries and build unified access scopes.
- Tools/products/workflows: LSP integration for each language; cross-language symbol linking (e.g., API boundaries, FFI); enterprise plugins/SaaS for large codebases.
- Assumptions/dependencies: Mature language servers and stable AST/type inference; standardized cross-language metadata; handling of build systems (Bazel/Maven/CMake).
- Automated large-scale refactoring and dependency upgrades (Sector: Software/Platform Engineering)
- Use case: Plan and execute refactors or migrations (API deprecations, framework upgrades) by computing minimal impacted scopes from entry points.
- Tools/products/workflows: Impact analyzer uses exhaustive jump traversal; generates change plans and test selection; pairs with patching agents and CI gates.
- Assumptions/dependencies: Accurate symbol resolution across versions; tests that cover refactor risks; governance for bulk code changes.
- Architecture mining and call-graph intelligence (Sector: Software/Management Insight)
- Use case: Derive execution-logic-aligned maps of the system to inform technical debt reduction, modularization, and team ownership boundaries.
- Tools/products/workflows: Visualization service that records jump traversals; correlates access scopes with incident history; produces risk hot spots and maintenance forecasts.
- Assumptions/dependencies: Scalable indexing; consistent LSP outputs; privacy and security compliance for code analytics.
- General design pattern for agentic tooling: “One unified tool” principle across domains (Sector: Software/AI Platforms; Cross-sector)
- Use case: Apply the single-tool, execution-aligned approach to other agent domains (retrieval, GUI, math), reducing orchestration complexity and error propagation.
- Tools/products/workflows: RLVR/GRPO training with constrained action spaces and verifiable rewards; template agents that favor a powerful unified tool over many narrow ones.
- Assumptions/dependencies: Existence of a tool that matches the domain’s true operational semantics (e.g., web search, calculator, GUI action); reliable verification signals.
- Governance and policy guidance for AI-assisted development (Sector: Policy/Org Governance)
- Use case: Establish policies on AI localization assistance in code reviews and incident response; mandate execution-aware tooling to reduce hallucinations and brittle multi-tool chains.
- Tools/products/workflows: Org-level standards for tool use; audit logs of agent actions; human-in-the-loop checkpoints; risk controls for code changes suggested by agents.
- Assumptions/dependencies: Regulatory clarity (software safety/security); internal compliance frameworks; cultural adoption and training.
- Education at scale: executable-code comprehension tutors (Sector: Education)
- Use case: Teaching materials that show real execution flows by stepping through symbol definitions; interactive lessons for students in large repos.
- Tools/products/workflows: Web-based tutors that run jump traversals; highlight scopes and dependency paths; embed agent reasoning traces for explanation.
- Assumptions/dependencies: Robust language server support; curated curricula; adaptation beyond Python to commonly taught languages.
- Security program augmentation with structured pre-triage (Sector: Security)
- Use case: Combine execution-aware localization with static/dynamic analysis to pre-triage findings (e.g., CVEs, secret leaks), narrowing the remediation search space before intensive audits.
- Tools/products/workflows: Security pipeline step that computes access scopes for suspect symbols/APIs; feeds downstream SAST/DAST tools; prioritizes hotspots.
- Assumptions/dependencies: Integration with existing security tooling; careful handling of dynamic features and obfuscation; organizational appetite for AI-assisted triage.
Cross-cutting assumptions and dependencies
- Python-first: Current results and tooling (Pyright) focus on Python; expanding requires high-quality LSPs and static analysis for other languages.
- Static analysis fidelity: Jump relies on static resolution approximating runtime semantics; heavy use of dynamic imports, reflection, or metaprogramming can degrade accuracy.
- Data and compute: RL training benefits from verifiable rewards (Dice/IoU) and sufficient compute; production inference should manage context limits and tool-call budgets.
- Integration and safety: Human oversight and CI gates are required for any downstream automated code changes; auditability of agent actions is essential.
- Repository access: Agents must have permissioned access to codebases and issue/test artifacts; enterprise deployments need privacy/security controls.
Glossary
- Abstract Syntax Tree (AST): A tree representation of the syntactic structure of source code used by compilers and analyzers. "the source file is parsed into an abstract syntax tree (AST)."
- Advantage function: A reinforcement learning signal estimating how much better an action is compared to the expected value at a state. "the first term is the standard policy gradient objective with an estimated advantage function "
- Agentic RL: Reinforcement learning methods tailored for LLM agents to learn tool use and multi-step behaviors. "Agentic RL \cite{jin2025search} is an on-policy RLVR methods requiring only the result for verifiying trajectories."
- Constrained decoding: A generation technique that enforces structural or format constraints (e.g., grammar) during token decoding. "Tool calls must satisfy a JSON grammar enforced via constrained decoding."
- Dice: A set-similarity metric that measures overlap between two sets, often used for evaluation. "Dice is a common metric for set-level comparison"
- Distillation: Training a smaller or target model to mimic a stronger teacher model’s behavior. "without any closed-source distillation."
- Docker environment: A containerized runtime environment used to reliably execute and evaluate code across repositories. "requires executing candidate patches inside a dedicated Docker environment for each repository"
- Group Reference Policy Optimization (GRPO): An RL algorithm that balances reward maximization with staying close to the previous policy via a KL penalty. "We apply ... Group Reference Policy Optimization (GRPO), which has the loss function:"
- Import dependency graph: A static graph of module imports that emulates Python’s module loading and symbol bindings across files. "Import Dependency Graph"
- Intersection over Union (IoU): A set-similarity metric computed as the size of the intersection divided by the size of the union. "IoU (intersection out of union)"
- JSON grammar: A formal specification of JSON structure used to validate tool call formats. "Tool calls must satisfy a JSON grammar enforced via constrained decoding."
- Kullback-Leibler (KL) divergence: A measure of difference between two probability distributions, used as a regularization term in RL. "The second term is a Kullback-Leibler (KL) divergence penalty"
- Language server: A tooling backend that provides code navigation and analysis (e.g., jump-to-definition) for editors and agents. "the language server will return the definition code of the symbol."
- LEGB rule: Python’s name resolution order: Local, Enclosing, Global (module), Built-ins. "following Python’s LEGB rule."
- Lexical Scope Resolution: Resolving identifiers by searching nested lexical scopes in a fixed order. "Lexical Scope Resolution"
- Member lookup: The process of finding an attribute or method within a type or class hierarchy. "must be inferred prior to member lookup."
- Method resolution order (MRO): The order in which Python looks up methods or attributes in a class hierarchy. "denotes the method resolution order of type ."
- On-policy: An RL training paradigm where data is collected using the current policy being optimized. "Agentic RL \cite{jin2025search} is an on-policy RLVR methods"
- Policy gradient objective: A core RL objective that adjusts the policy parameters in the direction of higher expected return. "the first term is the standard policy gradient objective"
- Pyright: A Python language server and type checker used for symbol resolution via static analysis. "Pyright computes a resolution mapping"
- Receiver expression: In attribute access, the expression on which the attribute is looked up (e.g., the ‘a’ in a.b). "Pyright treats as a receiver expression"
- Rejected-sampled finetuning (RFT): A training method using multiple rollouts and selecting higher-quality trajectories to finetune an agent. "Rejected-sampled finetuning (RFT) \cite{ahn2024large} utilizes generated trajectories of the agent itself via multiple rollouts."
- Reinforcement Learning with Verifiable Rewards (RLVR): RL methods that use task outcomes that can be programmatically verified as rewards. "Reinforcement Learning with Verifiable Rewards (RLVR)"
- Repository-level issue localization: Identifying the specific files, functions, or code spans responsible for an issue within a large codebase. "a reinforcement-learning agent for repository-level issue localization."
- Repository-level retrieval: Treating navigation of large codebases as a retrieval problem over repository content. "treat this as a repository-level retrieval task"
- Static analysis: Code analysis performed without executing the program, often using syntax and type information. "deterministic static analysis pipeline"
- Static Type Inference: Inferring types from code without running it, using annotations, flows, and stubs. "Static Type Inference"
- Stub files (.pyi): Type stub files in Python that provide type information for modules. "and stub files (.pyi)."
- Symbol resolution: Determining the defining location of a symbol occurrence in code. "Jump: Symbol Resolution"
- Test-time scaling: Increasing compute or inference-time steps (e.g., more tool calls) to boost performance without additional training. "Most existing agents rely on test-time scaling applied directly to pretrained LLMs"
- Tool-chaining: Orchestrating multiple tool calls in sequence to accomplish complex tasks. "multi-step tool-chaining behaviors"
- Trust region: A constraint in policy optimization that limits how far the new policy can deviate from the old one. "which acts as a trust region"
- vLLM: An efficient inference engine for LLMs. "we apply vLLM \cite{kwon2023efficient} as the inference engine."
- verl: A training framework used to implement RL for LLM agents. "we apply verl \cite{shen2024llm} as the training framework"
- Verifiable rewards: Rewards that can be automatically checked against ground truth or programmatic criteria. "We apply reinforcement learning with verifiable rewards to train the agent directly from the pretrained model"
Collections
Sign up for free to add this paper to one or more collections.

