Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
Abstract: A widespread practice in software development is to tailor coding agents to repositories using context files, such as AGENTS.md, by either manually or automatically generating them. Although this practice is strongly encouraged by agent developers, there is currently no rigorous investigation into whether such context files are actually effective for real-world tasks. In this work, we study this question and evaluate coding agents' task completion performance in two complementary settings: established SWE-bench tasks from popular repositories, with LLM-generated context files following agent-developer recommendations, and a novel collection of issues from repositories containing developer-committed context files. Across multiple coding agents and LLMs, we find that context files tend to reduce task success rates compared to providing no repository context, while also increasing inference cost by over 20%. Behaviorally, both LLM-generated and developer-provided context files encourage broader exploration (e.g., more thorough testing and file traversal), and coding agents tend to respect their instructions. Ultimately, we conclude that unnecessary requirements from context files make tasks harder, and human-written context files should describe only minimal requirements.
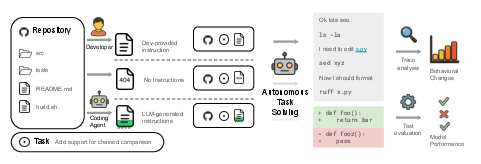
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: do special “cheat sheets” for code projects actually help AI coding assistants do their jobs better?
These cheat sheets are files like AGENTS.md or CLAUDE.md that live in a code repository. They tell an AI agent how the project is organized, which tools to use, how to run tests, and what rules to follow. Lots of developers and AI tool makers recommend adding these files—but no one had carefully tested if they really help.
The big questions the researchers asked
The authors focused on a few clear questions you can think of as “does this really help?” checks:
- Do context files (the cheat sheets) make AI coding agents more likely to solve real coding tasks?
- Are human-written context files better than ones auto-written by AI?
- How do these files change the agent’s behavior (for example, do they make it test more, explore more files, or think longer)?
- Are there downsides, like higher cost or slower progress?
How did they study it? Their approach
First, a couple of simple definitions:
- A “coding agent” is an AI assistant that can read files, run commands, write code, and try to fix or add features on its own.
- A “context file” (like AGENTS.md) is a special document that gives the agent project-specific tips and rules.
- A “benchmark” is a set of tasks used to fairly compare performance.
To test the effect of context files, they used two sets of real-world coding tasks:
- SWE-bench Lite: a popular benchmark with tasks from big, well-known Python projects. These usually didn’t have developer-written context files.
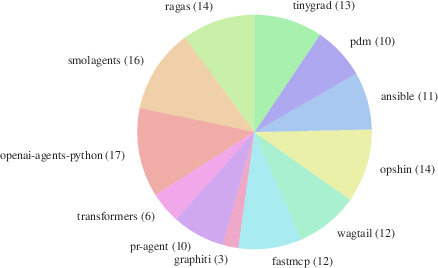
- AGENTbench: a new benchmark they created with 138 tasks from smaller, newer GitHub repositories that actually include developer-written context files.
They ran coding agents in three different settings for each task:
- None: no context file provided.
- LLM: a context file auto-generated by an AI model, following tool-makers’ recommended prompts.
- Human: the real, developer-written context file (available only for AGENTbench).
They measured:
- Success rate: did the agent’s code make all tests pass?
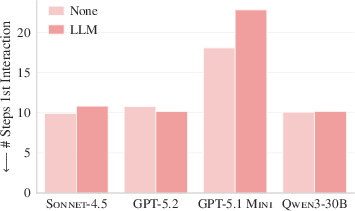
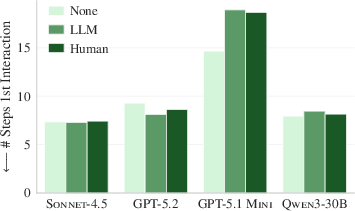
- Steps: how many actions the agent took (like running commands, reading files).
- Cost: how much AI compute was used (in dollars).
- Behavior: which tools the agent used, how much it explored, and how much it “reasoned” (longer thinking = more tokens).
To build AGENTbench, they:
- Collected real GitHub issues and the pull requests (PRs) that fixed them from repos with context files.
- Standardized the task descriptions so they were clear but didn’t spoil the answer.
- Created or cleaned up tests (sometimes with AI help) to check whether a solution works.
- Ensured tasks were realistic and testable.
Think of it like giving the same set of tricky homework problems to different AI “students,” sometimes with a cheat sheet, sometimes without, and seeing who does better.
What did they find, and why does it matter?
Here are the main takeaways:
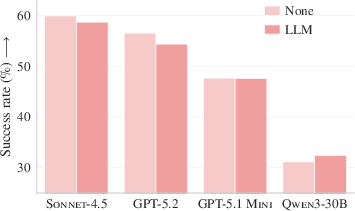
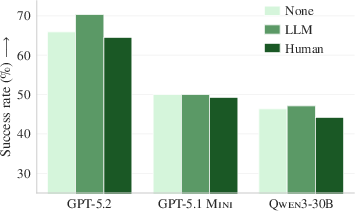
- Auto-generated context files usually hurt, not help. On average, AI-made context files slightly reduced success and increased cost by over 20%. They also made agents take more steps, meaning more time and money.
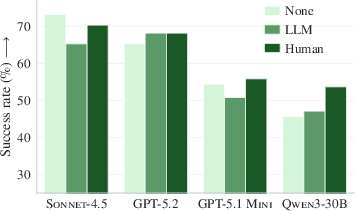
- Human-written context files gave a tiny boost, but still cost more. They slightly improved success (around +4% on average) compared to having no context file, but also made agents take more steps and spend more.
- Agents do follow instructions in context files. When a context file said “use this tool” (like a specific test runner), agents used it a lot more. So the problem isn’t that agents ignored the files.
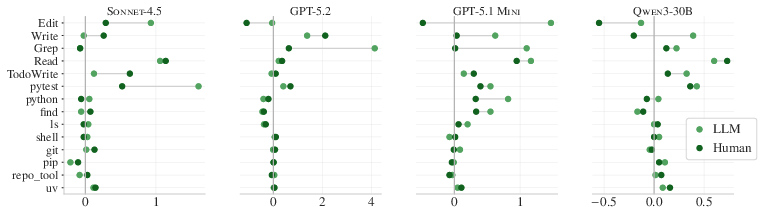
- The files pushed agents to explore and test more—but that didn’t translate into better results. With context files, agents ran more tests, read and wrote more files, and used repository-specific tools more often. But this “do more” behavior didn’t reliably help them solve tasks.
- Context files weren’t good at helping agents find the right code faster. Even with overviews of the codebase, agents didn’t reach the important files in fewer steps.
- Why do auto-generated files sometimes “feel” helpful? When the researchers removed all other docs (like README.md and docs/), AI-generated context files started helping and sometimes beat human ones. That suggests these AI-made files are often just repeating things already in the repo’s documentation. If the repo is poorly documented, the AI-made file can fill a gap. If the repo is already documented, the AI-made file becomes noise.
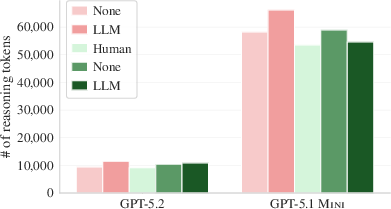
- More rules made the tasks feel harder to the AI. Models that can “think longer when needed” used more thinking tokens when context files were present. In other words, extra requirements in the file made the agent work harder—without clearly helping it finish.
- Stronger AI doesn’t automatically write better context files. Using a bigger model to create the file didn’t consistently help, especially on the new AGENTbench tasks.
- The exact prompt used to generate the context file didn’t matter much. Different “good” prompts produced similar outcomes.
Why this matters: Many teams are told to add AGENTS.md to help AI assistants. This study shows that, in most real settings, AI-generated context files don’t help and can make things worse. Human-written files help only a little—and still add cost.
What should developers and teams do now?
Based on the results, the authors suggest:
- Don’t rely on auto-generated context files yet. They tend to lower success and raise cost.
- If you add a context file, keep it short and focused. Include only must-have details (for example, “use this specific tool and these commands to run tests”), not broad overviews that the agent can discover itself.
- Improve your regular documentation. If your repo already has clear docs, an AI-made context file is probably redundant. If your repo lacks docs, better normal docs may help both humans and AI more than a special AGENTS.md.
Limitations and future directions
- Most tasks were in Python. Results might differ in niche languages or complex toolchains where agents know less and need more guidance.
- They measured task completion, not other qualities like performance or security. Future work could test whether context files improve safer or faster code.
- There’s room to design better, smarter context files. For example, files that adapt to the task or are learned over time from past attempts might help more than static, one-size-fits-all summaries.
Bottom line
Context files for AI coding agents are not a magic fix. AI-generated ones often make things slower and costlier, and human-written ones help only a little while also adding overhead. The best bet today is minimal, practical guidance that tells the agent exactly what tools and commands to use—nothing more.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored, phrased to enable concrete follow-up work.
- Limited language coverage: The study focuses almost exclusively on Python repositories. It is unknown whether the findings generalize to other languages and toolchains (e.g., Rust, Go, C/C++, mobile/embedded stacks) that are less represented in LLM training data and may rely on more specialized tooling.
- Narrow agent/model scope and configurations: Only four agent–model combinations were evaluated, mostly with fixed temperatures and single-shot sampling. The robustness of results under repeated runs, different sampling configurations (e.g., best-of-n, temperature sweeps), and across additional agents/harnesses (e.g., OpenHands, Devin-like systems) is untested.
- Statistical reliability of effect sizes: Reported performance differences are small (±0–4%) without confidence intervals or hypothesis testing. It is unclear whether observed effects are statistically and practically significant across instances and repositories.
- Test suite validity and alternative-solution fairness: Unit tests were LLM-generated using access to the golden patch , and only 10% of instances were manually spot-checked for leakage. More systematic validation is needed to ensure tests do not overfit to , penalize valid alternative implementations, or inadvertently encode solution details.
- Coverage limitations and task stratification: Coverage is measured on modified code (avg 75%, but as low as 2.5%). The impact of context files may vary for high- vs low-coverage tasks, bug-fixes vs feature additions, or simple vs complex changes. Stratified analyses are missing.
- Repository selection bias and representativeness: AGENTbench emphasizes 12 niche repositories with developer context files, while SWE-bench Lite comprises popular repos without them. It is unclear whether results generalize to (i) popular projects that use AGENTS.md/CLAUDE.md and (ii) broader open-source ecosystems with different documentation and contribution norms.
- Content-level ablation of context files: The paper identifies that overviews are often redundant but does not perform fine-grained ablations of specific sections (e.g., tooling commands, style guides, contribution policies, test execution instructions). Which content types consistently help or harm task resolution remains unknown.
- Optimal context length and structure: Context files increase cost and steps, but the “right size” and organizational patterns (e.g., task-centric snippets, minimal tooling directives, repository maps vs file pointers) are uncharacterized. How brevity, formatting, and structured schemas (headings, tables, checklists) affect outcomes is an open question.
- Redundancy with existing documentation: LLM-generated context files improve performance only when other documentation is removed. The interaction between AGENTS.md and existing docs (README, docs/, examples) needs quantification: which documentation artifacts should be summarized, linked, or pruned to avoid redundancy and cognitive overload?
- Dynamic, task-specific context vs static files: The study evaluates static repository-level files. It remains unclear whether dynamically generated, issue-specific context (e.g., RAG-based retrieval of only relevant snippets, “context-on-demand” during planning/execution) would retain benefits while reducing costs.
- Instruction strictness and “unnecessary requirements”: The paper posits that extraneous instructions make tasks harder but does not formalize or detect them. Methods to identify, prune, or soften harmful directives (e.g., strict tool/version mandates) and measure their impact are missing.
- Linking increased exploration/testing to success: Context files lead to more testing and repository traversal, but the causal relationship to success/failure is not analyzed. When does extra exploration help, and when does it degrade performance due to distraction or token/cost budget?
- Outdated or incorrect context content: Developer-written files may contain stale or erroneous guidance. The prevalence and impact of incorrect instructions (e.g., obsolete commands, mismatched environments) and mechanisms to auto-detect and adapt to such errors remain unexplored.
- Harness ingestion and placement effects: Context files were written to agent-specific filenames (AGENTS.md, CLAUDE.md) and injected into the context. The sensitivity to ingestion method (e.g., preloaded vs retrieved vs tool-assisted reads), file location, and visibility in different harnesses is not studied.
- Web access and real-world constraints: Agents had web access (albeit minimal usage). The interaction between web access, existing documentation, and context files in real workflows—especially under offline, restricted, or enterprise settings—remains unclear.
- Cost–performance trade-offs and budgets: Context files consistently increase inference cost and steps. Formalizing acceptable trade-offs (e.g., max cost per task, step budgets), and designing context strategies that optimize success under resource constraints are open problems.
- Adaptive reasoning across models: Only GPT-5.* models’ reasoning token usage was analyzed. Whether other models exhibit similar adaptive behavior—and how context file content influences reasoning depth across architectures—remains unknown.
- Per-repository moderators: The per-repo analysis is shallow. Which repository characteristics (size, structure, test rigor, documentation quality, domain complexity) moderate the impact of context files is not established.
- Guidance for developers beyond “minimal requirements”: The recommendation to include only minimal requirements is descriptive. A prescriptive, evidence-driven template (e.g., a validated schema of sections and content styles) and checks (linting/validation tools) for writing effective AGENTS.md are not provided.
- Improving automatic context generation: While stronger LLMs occasionally help on SWE-bench Lite, they hurt on AGENTbench. Systematic approaches to auto-generate concise, accurate, non-redundant, and task-relevant context (e.g., planning, test-time adaptation, prior-task memory, content deduplication against docs) remain to be designed and evaluated.
- Multi-objective evaluation: The study centers on pass/fail success and cost. Other objectives—code quality, performance, security, maintainability, style conformity, and developer satisfaction—are unmeasured, leaving the broader utility of context files unresolved.
Practical Applications
Overview
This paper evaluates whether repository-level context files (e.g., AGENTS.md, CLAUDE.md) actually help coding agents resolve real-world tasks. It introduces AGENTbench (a new benchmark of 138 tasks from 12 repositories that actively use developer-written context files) and compares three settings across multiple agent/model pairs: no context file, LLM-generated context file, and developer-written context file. Core findings:
- LLM-generated context files tend to reduce task success rates and increase inference costs (>20%).
- Developer-written context files slightly improve success rates but also increase steps and costs.
- Context files increase testing and exploration but do not function well as repository overviews.
- When all documentation is removed, LLM-generated context files become more beneficial than human-written ones, suggesting they mainly provide redundant information otherwise.
- Agents carefully follow instructions in context files, which can make tasks harder when those instructions are unnecessary.
The following applications translate these findings and methods into concrete, real-world uses.
Immediate Applications
The items below can be adopted now with minimal engineering effort and are grounded in the paper’s evaluated results and tooling.
- Industry (Software Engineering, DevTools): Adopt “minimal AGENTS.md” policies
- Replace verbose, LLM-generated AGENTS.md with short, human-written files that only specify essential commands and repository-specific tooling (e.g., how to run tests/build, which tool manager to use like uv/pdm, any repo-specific scripts).
- Update engineering guidelines and code review checklists to prevent over-specification (avoid directory overviews and duplicated documentation).
- Dependencies/Assumptions: Repositories must have basic test/build commands; teams agree on minimal templates; current results are strongest for Python repos.
- Agent Framework Vendors (Software)
- Adjust default init commands and prompts to generate concise, tooling-focused context files rather than expansive overviews.
- Add harness features that prevent redundant reading of context files and cap “documentation budget” (e.g., de-duplicate context ingest, warn on repeated reads, limit reasoning tokens attributable to context).
- Dependencies/Assumptions: Access to harness internals and telemetry; willingness to change defaults; model hooks to control token budgets.
- Open-Source Maintainers and Teams (Industry/Daily Life)
- Replace existing AGENTS.md/CLAUDE.md with a minimal template: tooling to use, exact test/build commands, known caveats, and repository-specific “do/don’t” rules.
- If repository documentation is minimal, temporarily enable agent auto-init of context files in isolated runs (docless mode) to bootstrap helpful guidance (as the paper shows LLM-generated files help most when documentation is absent).
- Dependencies/Assumptions: Maintainers can edit repository docs; test suite exists or is easy to run; teams accept docless runs for agents in CI sandboxes.
- DevOps/CI (Software)
- Add CI jobs that A/B test agent performance “with vs without” context files and track success rate, steps, and cost per task; block merging if a new context file worsens resolution rates or significantly increases cost.
- Include a “Context File Impact” check in PR templates (flag when AGENTS.md changes and require an impact report).
- Dependencies/Assumptions: Benchmarks/tasks available (e.g., AGENTbench instances or internal task suites); CI capacity; agents integrated into pipeline.
- QA and Testing (Software)
- Use context files to explicitly instruct agents to run tests with the correct tooling (the paper shows context files increase testing frequency), but keep instructions minimal to avoid making tasks harder.
- Dependencies/Assumptions: Tests must be reliable; agents have test-running tools; maintainers validate that added test instructions don’t over-constrain behavior.
- Cost and Operations (Finance/IT)
- Incorporate “agent-cost impact” metrics (steps, reasoning tokens, inference cost) into ROI calculators and procurement decisions; prioritize minimal human-written context over LLM-generated files in well-documented repos.
- Dependencies/Assumptions: Access to model pricing data and agent telemetry; consistent tasks for measurement.
- Academia and Research
- Use AGENTbench alongside SWE-bench Lite to assess agent changes; replicate “docless” ablations and trace analyses (tool-use frequencies, intent categorization).
- Adopt the paper’s trace analysis methods (tool-equivalence classes, intent classification) to study behavior changes induced by guidance.
- Dependencies/Assumptions: Availability of AGENTbench code and prompts; compute and model access; reproducible environments.
- Education (Education/Training)
- Teach “agent-aware documentation” best practices: why verbose overviews can harm outcomes, how minimal instructions improve alignment, and how to measure agent cost/performance impacts.
- Use AGENTbench-style labs to show students the effect of documentation changes on autonomous coding agents.
- Dependencies/Assumptions: Classroom access to agents and benchmarks; instructors can run Dockerized environments.
- Tools/Products (Software)
- Context File Linter: A CLI that flags redundancy (e.g., directory listings), over-specification, and missing essentials (test/build commands, repo-specific tool names).
- Agent Doc Impact Analyzer: A utility that runs A/B tests with/without context files, reports changes in success rate, steps, cost, and reasoning tokens.
- Trace Visualizer: Dashboard to inspect tool calls, intents, and repeated doc reads; suggests doc simplifications.
- Dependencies/Assumptions: Access to agent traces and logs; stable APIs from harness vendors; organizational buy-in for linting and A/B testing.
Long-Term Applications
These items require additional research, scaling, or development beyond the current findings.
- Adaptive, Self-Evolving Context Generation (Software/Research)
- Build agent systems that learn “dynamic cheat sheets” from prior tasks, generating minimal, task-relevant context that avoids redundancy and reduces unnecessary exploration.
- Use planning and curriculum learning to refine context files over time (e.g., agentic context engineering).
- Dependencies/Assumptions: Longitudinal task data; tooling for continuous learning; safety checks to prevent instruction bloat.
- Model Training and Alignment (Software/AI)
- Train models to (i) ignore redundant repository overviews, (ii) privilege high-signal instructions (tooling and commands), and (iii) calibrate tool use to reduce steps and reasoning tokens.
- Incorporate cost-aware objectives so models learn to maximize task success under inference budgets.
- Dependencies/Assumptions: Access to training data and agent traces; vendor willingness to change training objectives.
- Standards and Governance (Policy/Industry Consortia)
- Publish a minimal AGENTS.md standard/template and audit criteria (success rate, steps, cost deltas). Encourage organizations to require evidence that context files help before adoption.
- Define documentation redundancy guidelines to reduce overlap between AGENTS.md and README/docs.
- Dependencies/Assumptions: Collaboration among foundations, vendors, and OSS communities; sustained benchmarking infrastructure.
- Cross-Language and Toolchain Expansion (Software/Academia)
- Extend AGENTbench to less common languages (Rust, C/C++, Java) and diverse toolchains to see if minimal context files have larger impact where parametric knowledge is weaker.
- Dependencies/Assumptions: Multi-language benchmarks; standardized environment setup; community participation for PR mining.
- Security-Oriented Context Files (Security/Software)
- Explore whether concise secure-coding guidance in AGENTS.md improves security of agent-generated patches (e.g., “sanitize inputs,” “avoid unsafe APIs,” “enforce auth checks”).
- Dependencies/Assumptions: Security benchmarks and tests; careful prompt engineering to avoid over-constraint; collaboration with SecureAgentBench-like efforts.
- Enterprise Risk and Compliance (Policy/Enterprise)
- Establish policies that audit context file changes for unintended constraints, compliance violations, or leakage risks; log agent adherence to instructions for traceability.
- Dependencies/Assumptions: Governance tooling; audit workflows; legal reviews; integration with existing compliance frameworks.
- IDE and Agent Harness Enhancements (Software)
- Introduce “doc shaping” features: summarize large docs on-the-fly, suppress redundant sections, and surface just-in-time minimal context tailored to the current task.
- Add auto-detection of repo-specific tools and dynamic extraction of build/test commands to generate slim, structured configs (e.g., agent.yaml) rather than free-form markdown.
- Dependencies/Assumptions: IDE vendor support; robust static/dynamic analysis; runtime telemetry.
- Benchmarking-as-a-Service (Software/Industry)
- Offer hosted AGENTbench-like services for vendors and enterprises to evaluate agents on their own repositories, with automated report cards (success, steps, cost) and recommendations to optimize context files.
- Dependencies/Assumptions: Scalable infrastructure; secure sandboxing; reproducibility; customer data policies.
Notes on Assumptions and Dependencies
- Findings are strongest for Python repositories with existing test suites; generalization to other languages and weakly tested repos requires further validation.
- Results depend on the specific agents and models evaluated; different harness/toolsets may alter outcomes.
- Cost estimates are model- and vendor-dependent; organizations should instrument their own cost tracking.
- The beneficial effect of LLM-generated context files in “docless” environments implies an operational dependency: whether a repository already has adequate documentation.
- Security, performance, and broader non-functional aspects were out of scope; integrating these into future benchmarks may change best practices.
Glossary
- adaptive reasoning: A model capability that dynamically allocates more computation (tokens) to harder problems. "as their adaptive reasoning~\citep{adaptive_reasoning} allows them to use more reasoning tokens for tasks that they deem harder."
- AGENTbench: A benchmark of real-world coding tasks designed to evaluate the impact of repository context files. "AGENTbench complements SWE-bench Lite, which we leverage for the evaluation of automatically generated context files on popular repositories."
- AGENTS.md: A repository-level context file intended to guide coding agents with project-specific instructions. "providing context files like AGENTS.md, a README specifically targeting agents, has become common practice."
- agent harness: The tool-enabled runtime that lets an LLM interact with files, shells, and the environment. "Many agent harnesses provide built-in commands to initialize such context files automatically using the coding agent itself"
- agentic framework: The set of built-in tools and capabilities an agent uses to operate (e.g., Read, Write). "For tools included in the agentic framework (e.g., Read, Write, or TodoWrite), we record the name of the tool being called."
- chat compression: A mechanism to reduce or summarize conversation state to fit context limits during long interactions. "For Qwen Code, we enable chat compression upon reaching $60$\% of the total context limit (set to $256$K tokens)"
- CLAUDE.md: A repository context file format used specifically by Claude-based coding agents. "either by writing it to AGENTS.md for Codex and Qwen Code, or to CLAUDE.md for Claude Code."
- Codex: An OpenAI coding agent/harness that pairs with GPT models for repository-level tasks. "Codex \citep{openaiCodex2026} with GPT-5.2 and GPT-5.1 mini \citep{singh2025openaigpt5card}"
- context files: Repository documents that provide agents with overviews, tooling, and instructions to improve task solving. "These context files typically contain a repository overview and information on relevant developer tooling"
- Docker container: A lightweight, isolated environment used to run agents and evaluate tasks reproducibly. "For AGENTbench instances, we run the coding agent in a Docker container with basic tooling (python, apt-get, uv, \ldots) and Internet access."
- equivalence classes: Groupings of different tool names treated as the same category for analysis and aggregation. "For tool names, we use the equivalence classes from \cref{tab:mapping}, and consider a tool to be mentioned in the context file if any tool from the corresponding equivalence class is mentioned in the context file."
- golden patch: The ground-truth code change that correctly resolves an instance’s task and passes tests. "and is the golden patch for that instance."
- LLM: A LLM used by coding agents to plan, reason, and modify code autonomously. "LLM-generated context files cause performance drops in 5 out of 8 settings across SWE-bench Lite and AGENTbench"
- OpenRouter API: A pricing and access interface used to estimate or pay for LLM inference across models. "For Qwen3-30b-coder, we estimate the cost from the average OpenRouter API price."
- parametric knowledge: Information embedded within a model’s learned parameters, not retrieved externally. "might be present in the models' parametric knowledge, nullifying the effect of context files."
- patch: A set of code modifications applied to a repository to fix bugs or implement features. "where the coding agent is tasked with predicting a patch given issue and repository state "
- pull request (PR): A proposed code change on GitHub with discussion and review metadata. "publicly tracked and documented changes, so-called pull requests (PRs)."
- reasoning tokens: Tokens spent by an LLM on internal chain-of-thought or analysis before producing actions/outputs. "we analyze the average number of reasoning tokens used by GPT-5.2 and GPT-5.1 mini"
- regression tests: Tests designed to ensure new changes don’t break existing functionality. "suitable for SWE-bench Lite-like regression tests."
- repository-level: Pertaining to tasks and evaluations conducted across an entire codebase rather than isolated functions. "Their impressive performance on repository-level coding tasks like SWE-bench \citep{swebench} led to rapid adoption"
- success rate: The percentage of instances for which an agent’s patch makes all tests pass. "We define the success rate as the percentage of predicted patches "
- SWE-bench Lite: A benchmark of issues from popular Python repositories used to evaluate coding agents. "We use SWE-bench Lite \citep{swebench}, which consists of 300 tasks sourced from GitHub issues across 11 popular Python repositories"
- Task tool: A Claude Code feature that spawns sub-agents to handle subtasks like exploration. "For Claude Code, we keep the Task tool enabled: it allows Sonnet-4.5 to invoke sub-agents, using Haiku-4.5, to solve sub-tasks."
- top-p sampling: A probabilistic decoding method that samples from the smallest set of tokens whose cumulative probability exceeds p. "and set the temperature of Qwen3-30b-coder to $0.7$ with top- sampling at $0.8$."
- uv: A Python-oriented tooling command used by agents for environment management or installs. "Lastly, adding context files causes agents to use more repository-specific tooling (e.g., uv and repo_tool)."
- vLLM: An inference framework for serving LLMs efficiently. "We deploy Qwen3-30b-coder locally using vLLM~\citep{vllm}."
Collections
Sign up for free to add this paper to one or more collections.

