- The paper presents TraceRepair, which integrates runtime execution traces with a multi-agent debate framework to repair complex software bugs.
- It employs diagnostic probing, multi-strategy patch generation, and arbitration to accurately localize faults and synthesize effective fixes.
- Empirical results show significant improvements over static methods, reducing overfitting and hallucination while lowering computational costs.
TraceRepair: Multi-Agent Automated Program Repair Guided by Runtime Execution Traces
Introduction
Automated Program Repair (APR) is tasked with automatically correcting software defects to reduce manual debugging costs. Recent advances using LLMs have shifted APR from heuristic search and template-based methods toward neural patch generation and agentic reasoning. However, prevailing LLM-based approaches remain limited by their reliance on static information (source code, test results, error streams), making them ineffective against complex logic bugs—especially silent failures that manifest as incorrect outputs without explicit crashes.
"Runtime Execution Traces Guided Automated Program Repair with Multi-Agent Debate" (2604.02647) introduces TraceRepair, a novel agentic framework designed to address these shortcomings by integrating runtime execution traces as objective constraints within a multi-agent debate protocol. TraceRepair assigns trace collection and patch generation to specialized agents, combining dynamic analysis with structured cross-verification to both enhance repair effectiveness and increase robustness against overfitting and hallucination.
Motivation: Static vs. Trace-Guided Repair
Traditional static-only APR, even when augmented by test outputs, often falls short when bugs affect non-crashing control flows or subtle data dependencies. TraceRepair is explicitly motivated by scenarios where static reasoning fails to correctly localize faults due to insufficient context. Consider the Compress-26 bug from Defects4J: the static agent incorrectly targets an unreached arithmetic operation, while TraceRepair—using a Probe Agent for runtime instrumentation—identifies the exact control path and context (e.g., a premature loop BREAK due to a zero return, revealing the need for a read fallback).
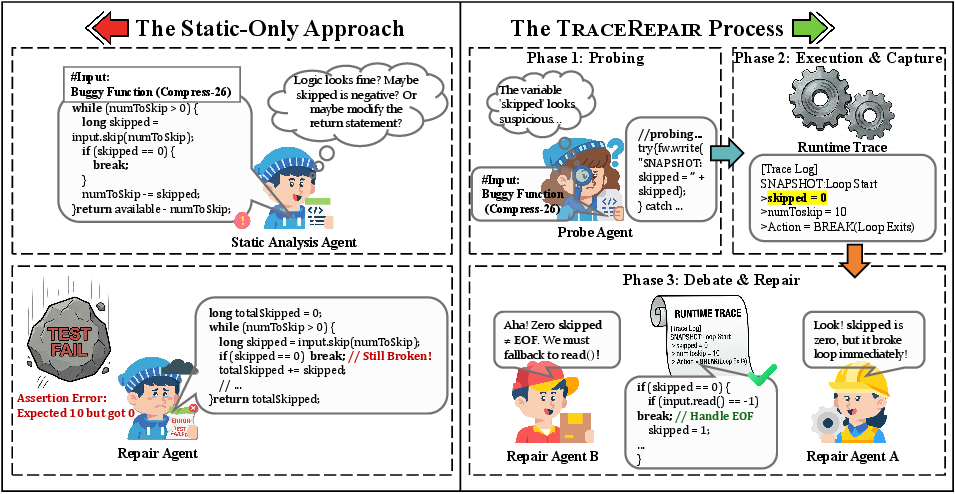
Figure 1: Compress-26 repair comparison between the static-only approach (left) and TraceRepair (right); only the trace-guided agent localizes the correct faulty logic using execution evidence.
This concrete example demonstrates that static repair lacks visibility into actual state transitions, whereas trace-guided approaches can precisely identify both the location and nature of the defect by observing real execution.
TraceRepair Architecture
TraceRepair comprises three core phases, each executed by dedicated agents within a sandboxed environment:
- Diagnostic Probing: The Probe Agent instruments code by injecting runtime logging into critical program points, focusing on variables and branches implicated by the test and stack trace.
- Multi-Strategy Debate: A committee of agents—each embodying distinct strategies (Defensive, Causal, Semantic)—iteratively generates, critiques, and refines candidate patches. At each debate round, these agents must ensure their proposals are consistent with the captured trace.
- Arbitration and Synthesis: The Judge Agent consolidates all candidate patches and critique history, synthesizing a final patch that satisfies the constraints imposed by the runtime trace.
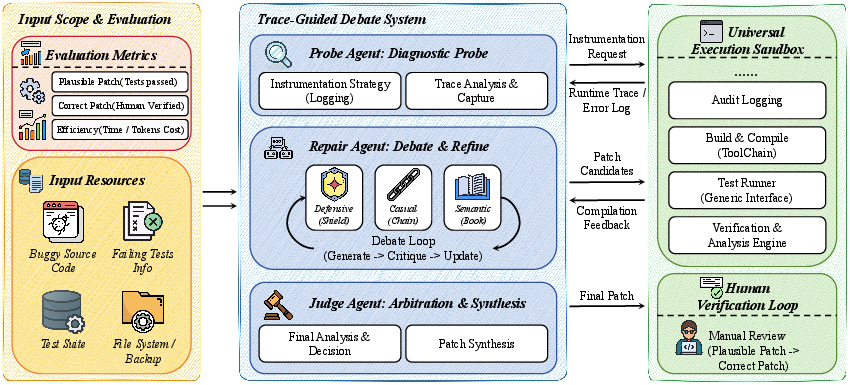
Figure 2: The Architecture of TraceRepair, consisting of a Trace-Guided Debate System orchestrating multiple agents with a Universal Execution Sandbox.
This architecture systematically enforces logical consistency throughout the repair process, with runtime traces serving both as localization signals and as invariants that candidate patches must not violate.
Methodology
Trace-Guided Multi-Agent Repair Loop
The repair process—detailed in the TraceRepair algorithm—operates as follows:
- The Probe Agent, guided by failures, selects and instruments key variables/branches to generate a runtime trace. Instrumentation is robustified using defensive try-catch wrappers and adaptive rollback to avoid compilation failures.
- The trace, capturing the trajectory of variable values and key control flow transitions, acts as a hard constraint for downstream reasoning.
- Three strategy agents (Defensive, Causal, Semantic) independently generate high-quality initial patch hypotheses via a "Best of N" scheme, then enter a debate loop. Each round consists of mutual critique, where contradictions with the trace are treated as hard errors, requiring counter-examples or logical refutations from peers.
- If no correct fix emerges, arbitration fuses successful elements from divergent strategies, pruned by trace consistency, to yield a final candidate.
Mitigating Overfitting and Hallucination
A distinctive claim of TraceRepair is its explicit prevention of test suite overfitting and LLM hallucination: since every patch must not only pass tests but also remain logically compatible with actual runtime behavior (as observed), the risk of spurious or coincidental fixes is substantially reduced.
Experimental Results
Benchmarks and Baselines
TraceRepair was extensively evaluated against ten state-of-the-art APR systems on standard (Defects4J) and newly constructed leakage-free (Recent-Java) bug datasets, using both advanced open-source (DeepSeek-V3.2, DeepSeek-Coder) and proprietary (GPT-3.5) LLMs to control for backbone capabilities.
Summary of Strong Empirical Results
- Repair Effectiveness: TraceRepair with DeepSeek-V3.2 fixed 392 defects on Defects4J, surpassing retrieval-augmented and conversational agentic methods. With GPT-3.5 (matching most baselines), TraceRepair still achieved 224 fixes, outperforming almost all static or agentic approaches.
- Challenging Bug Types: Unique success was demonstrated on logic-dependent, multi-function failures often unaddressed by alternative methods.
- Generalization: On Recent-Java (post-training-cutoff bugs), TraceRepair resolved more defects than both static and conversational LLM approaches, validating strong dynamic reasoning and minimal reliance on memorized pattern matching.
- Efficiency: Average token and monetary costs per fix were markedly reduced (down to 77k tokens and <$0.02 USD for DeepSeek-V3.2), and time to fix improved or remained competitive relative to all agentic baselines.
Ablation and Component Analysis
Both runtime trace and multi-agent debate independently convey strong empirical benefits, but their combination yields the largest improvement (+73.5% over DeepSeek baseline in ablations). All three strategies (defensive, causal, semantic) contribute uniquely, particularly for diverse defect classes.
Implications and Future Prospects
TraceRepair introduces several significant theoretical and practical advances:
- Objective Repair Constraints: Runtime traces impose non-heuristic, ground-truth constraints, reframing APR as consistency reasoning over factual evidence rather than speculative static analysis or test suite mimicry.
- Multi-Agent Cross-Verification: Structured debate mitigates single-agent hallucination, echoing successes of adversarial and committee-based reasoning in other high-stakes LLM domains.
- Scalability and Robustness: Strong efficiency and generalization, coupled with high robustness to localization errors, make TraceRepair practical for deployment in realistic (low-granularity) defect settings.
Potential future work includes extending the trace-guided, multi-agent paradigm to more complex repository-level repair (e.g., SWE-Bench), enhancing probe generality for polyglot codebases, and integrating more advanced dynamic analysis and symbolic reasoning capabilities to further automate specification inference and repair validation.
Conclusion
TraceRepair establishes a new standard for LLM-based automated program repair by combining diagnostic runtime trace collection with structured, trace-guided multi-agent debate. By anchoring repair candidates to observed execution behavior and enforcing cross-agent consistency, the framework addresses major limitations of prior methods involving overfitting, brittle static reasoning, and single-agent hallucination. Its empirical superiority, evidenced both on legacy and unseen datasets, confirms that dynamic, execution-driven reasoning is an effective path forward for robust, scalable AI-driven software repair.