- The paper introduces Agent-CoEvo, a framework that coevolves code and behavioral constraints to boost repository-level issue resolution performance.
- It employs multi-agent cross-population evaluation, semantic recombination, and elite retention to iteratively refine both code patches and test artifacts.
- Empirical results on SWE-bench Lite and SWT-bench Lite demonstrate significant improvements over baselines, confirming the efficacy of the coevolution approach.
Coevolutionary Framework for Repository-Level Issue Resolution: A Technical Essay on "Beyond Fixed Tests: Repository-Level Issue Resolution as Coevolution of Code and Behavioral Constraints" (2604.04580)
Repository-level issue resolution increasingly tests the practical limits of LLMs for software engineering automation. A persistent problem in prior work is the assumption that test suites, once constructed, constitute perfect and static constraints during automated repair. This paradigm, inherited from function-level APR, fails to capture the iterative and co-specifying nature of real-world bug resolution, where engineers interleave patching code and updating or clarifying tests as understanding of the issue evolves.
The central claim of "Beyond Fixed Tests: Repository-Level Issue Resolution as Coevolution of Code and Behavioral Constraints" (2604.04580) is that the typical fixed-constraint formulation both under-constrains or over-constrains code search, leading to overfitted or brittle patches. Instead, the authors propose a search paradigm in which not only code, but also behavioral constraints are explored and updated—a coupled optimization over implementation and evolving specification.
Agent-CoEvo: Framework Structure and Pipeline
The paper introduces Agent-CoEvo, a multi-agent framework that operationalizes repository-level repair as a coevolutionary search over a code patch population (CodeAgent) and a test patch population (TestAgent). The process begins with an issue localization agent, which parses the natural language issue and localizes relevant code within the repository through synthesized reproduction scripts and dynamic traces.
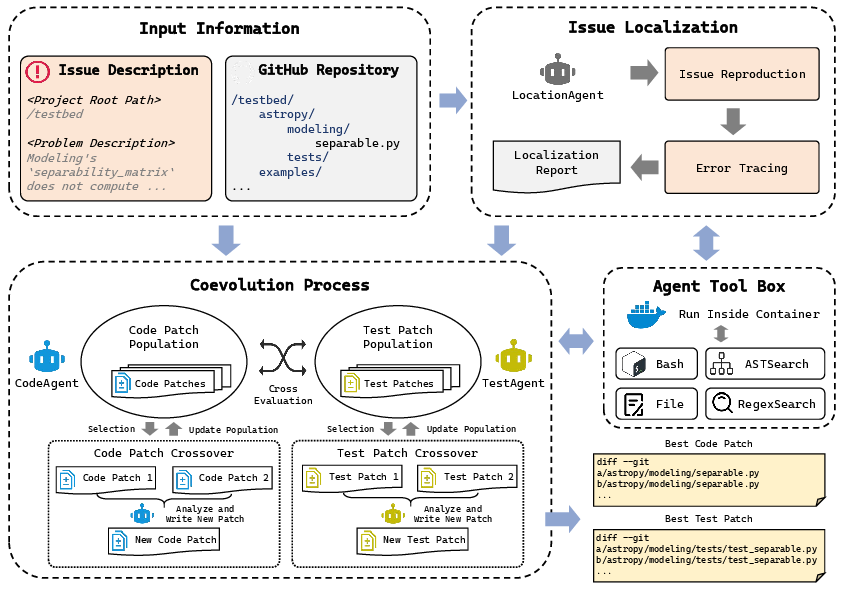
Figure 1: The Agent-CoEvo framework couples code and test populations via mutual selection, cross-evaluation, and recombination, reflecting the mutual refinement of implementation and behavioral constraints.
After localization, Agent-CoEvo initializes populations of code and test candidates using LLMs. Generative sampling, followed by filtering, ensures that test candidates actually fail on the buggy repository. The core search proceeds via repeated iterations:
- Cross-Population Evaluation: Fitness of code patches depends on the subset of tests they pass, weighted by consensus across code population. Fitness of a test patch reflects its ability to be passed by high-quality code.
- Semantic recombination (crossover): Rather than syntactic crossover, semantic fusion is performed via prompting LLMs to synthesize new artifacts that merge complementary parents. This promotes the transfer of partial behavioral corrections.
- Elite reservation: Ensures that high-quality code and test artifacts are never lost across generations, preserving behavioral alignment.
By deploying all agents in isolated Docker environments, Agent-CoEvo guarantees reproducibility of evaluations and codebase integrity.
Empirical Results
Evaluation is conducted on SWE-bench Lite and SWT-bench Lite, reflecting repair and reproduction, respectively. The primary metrics are issue resolution rate (repairs passing oracle tests), test reproduction rate (tests inducing correct failure/pass before/after gold fix), and coverage ΔC.
Agent-CoEvo is compared to state-of-the-art baselines, separated into code-centric (Agentless, DARS, KGCompass), test-centric (AssertFlip, SWE-Agent+), and generalist agent (AutoCodeRover, OpenHands, SWE-Agent) methodologies.
Agent-CoEvo outperforms all baselines on both repair and test reproduction:
- SWE-bench Lite: 41.33% resolution (vs. prior best 37.00%)
- SWT-bench Lite: 46.4% (vs. prior best 38.0%), ΔC 56.0%
The union-recall and overlap analysis shows not just absolute performance improvements but that Agent-CoEvo subsumes the robust solution sets of prior systems while uniquely solving cases that require joint reasoning over both dimensions.
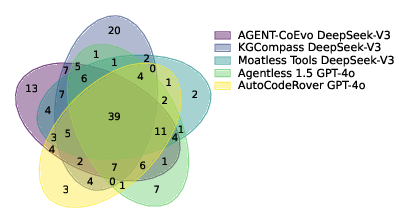
Figure 2: The Venn diagram quantifies how Agent-CoEvo covers both the consensus issues solved by prior systems and uniquely hard cases requiring behavioral constraint evolution.
Agent-CoEvo's performance arises not from searching more or overfitting, but from its ability to align partial code and constraint hypotheses, thus adapting to incomplete or imprecise initial validation signals.
Evolutionary Process Characteristics
The iterative nature of the coevolution is essential. Across five iterations, repair success increases monotonically, with the most significant jumps in earlier iterations and steady gains with more compute spent. Quality and behavioral consistency of generated artifacts are refined iteratively rather than through naive sampling.
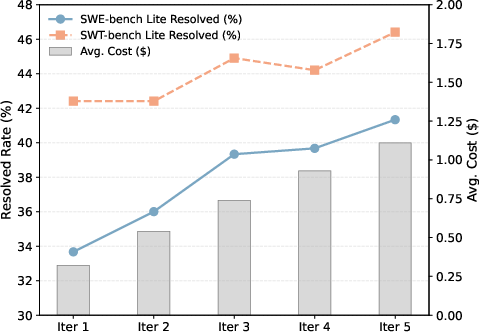
Figure 3: Plot of resolved rates and mean cost per issue over five evolutionary iterations, showing improved performance with roughly linear cost scaling.
Ablation studies confirm that removing the TestAgent (evolving constraints), semantic crossover, or elite retention each yield substantial degradation. The alignment dynamics among code and test populations are critical for robust convergence.
Mechanistic Case Analysis
The authors provide detailed case studies capturing the essence of behavioral alignment. In one SymPy issue, the initial code populations include one patch that improves local recursion handling and another that encodes a global, but bloated, dimensionality check. Through semantic crossover, alignment combines the minimality of the former and correctness of the latter, yielding a concise, specification-conforming patch.

Figure 4: The textual issue description grounds the defect as an underdetermined system detection problem in solve_poly_system.

Figure 5: Code patch evolution: partial parents from iteration 2 (local vs global fix) are fused in iteration 3, combining their respective strengths through LLM-driven semantic synthesis.
Concurrently, test evolution shifts from partial or misaligned failure oracles to a convergent, specification-faithful NotImplementedError-raising test.

Figure 6: Test patch evolution: semantic crossover aligns behavioral constraint with correct exception logic in sync with code repair refinement.
These trajectories empirically support the theoretical claim: coevolution induces convergence to a (code, test) pair accurately representing the intended resolution to the issue, even when both spaces are complex or initially mis-specified.
Practical and Theoretical Implications
Practical
- Robustness: By dynamically refining constraints, the framework reduces the false negatives of code-only approaches under incomplete or noisy test beds.
- Artifact production: The process yields not only a fix but also its behavioral verification, reflecting actual software engineering workflows.
- Cost–benefit analysis: While coevolution incurs higher inference compute compared to simple pipelines, the cost is amortized by improved resolution rate and reduced brittle patching.
Theoretical
- Problem reframing: Repository-level repair should be viewed as search over equivalence classes consistent with evolving operational specifications, generalizing function-level approaches that treat specifications as oracles.
- Alignment as search: Semantic crossover operationalizes alignment, favoring partial consensus discovery over winner-take-all selection.
Limitations and Future Directions
- Complexity Sensitivity: Overhead may be unnecessary for trivial bugs; hybrid strategies are needed for adaptivity.
- Initial localization: The framework's performance may degrade under poor initial code localization—a perennial open problem.
- Learned constraint fidelity: Generated tests may still encode failings, although coevolution mitigates this through iterative correction.
Conclusion
This paper decisively demonstrates that repository-level issue resolution is not optimization under fixed tests, but a coupled search over implementation and evolving behavioral constraints. Agent-CoEvo, by modeling coevolution and enforcing continuous alignment via semantic recombination and elite retention, establishes new state-of-the-art benchmarks in code repair and test generation under realistic conditions.
The framework's practical success and mechanistic clarity suggest a reorientation in automated repair research: future systems should privilege alignment between implementation and operational specifications, likely enabling further progress by integrating search-based and learning-based advances in coevolutionary optimization.

