- The paper demonstrates that a single refinement loop (R=2) markedly improves prediction accuracy and benchmark results compared to the baseline.
- It introduces innovations like cross-loop position offsets and shared-KV gated sliding-window attention to keep latency and memory demands nearly constant.
- Empirical analysis reveals that beyond the second loop, additional iterations yield diminishing returns due to constant offset costs and increased model redundancy.
Introduction and Motivation
Looped Transformer architectures have established themselves as an avenue for scaling the effective computational depth of LLMs while mitigating parameter and training costs. Rather than stacking multiple non-shared layers, looped architectures recursively apply the same parameter block. This approach allows for dynamic test-time scaling of latent computation, which has been shown to improve reasoning and in-context learning capabilities in recent transformer models.
However, the deployment cost of sequential recursive application—particularly in terms of latency and KV-cache memory—grows linearly with loop count, making large recurrent depths infeasible for many applications. The Parallel Loop Transformer (PLT) mitigates these costs by introducing cross-loop position offsets (CLP) and shared-KV gated sliding-window attention (G-SWA), so that both latency and memory requirements become nearly independent of loop count. This architectural efficiency poses a new question: How should one select the loop count for a PLT at test time to maximize output quality under fixed computational constraints?
Overview of Loss-Gain Analysis for PLT Loop Count
The central contribution of this work is a rigorous investigation of loop-count selection in PLT, framed as a gain–cost trade-off. While each additional loop may refine token representations through further latent computation, the insertion of a CLP incurs a positional mismatch: at each boundary, token positions are offset, perturbing the information available to subsequent loops. The authors quantify both the marginal representational gain and the offset-induced cost for each loop, using diagnostic metrics spanning hidden-state dynamics, attention patterns, and output prediction shifts.
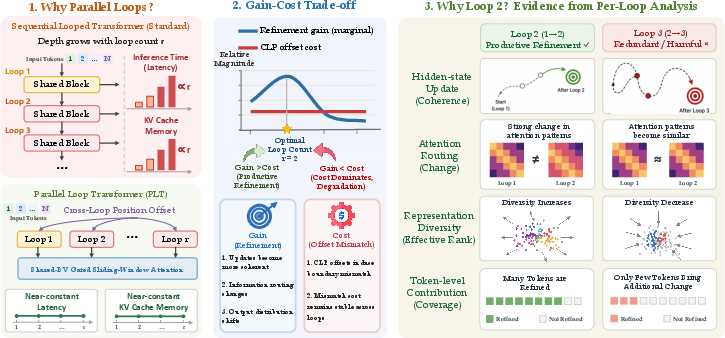
Figure 1: PLT loop-count selection concept; left: PLT's latency/memory costs are nearly constant with respect to loop count; middle: per-loop refinement gain peaks early, offset cost is constant—yielding an optimal operating point at r=2; right: loopwise representational dynamics identify productive vs redundant loops.
Experimental Design and Empirical Findings
Model and Training Protocol
LoopCoder-v2, a family of 7B parameter PLT models varying only in loop count R∈{1,2,3,4}, were trained on 18T tokens of a well-balanced text-code corpus. The code portion covers 100+ programming languages, with major domains detailed for reproducibility. Training, instruction tuning, and evaluation protocols are tightly matched across variants. The infrastructure supports weight-tied loop unrolling and optimized cross-loop computation and communication.
Macroscopic Benchmark Results
The core empirical finding is that downstream performance shows a strongly non-monotonic dependence on loop count. The R=2 variant achieves significant improvements across code generation and agentic reasoning benchmarks compared to the baseline (R=1). For example:
- SWE-bench Verified: from 43.0 (R=1) to 64.4 (R=2)
- Multi-SWE: from 14.0 to 31.0
- On other competitive agentic/code tasks, the R=2 LoopCoder-v2 nearly matches or outperforms much larger models.
However, additional loops (R≥3) produce diminishing or negative returns, with performance on some tasks regressing below the baseline.
Microscopic Interpretability Analysis
Hidden-State Dynamics
Hidden-state statistics across loops demonstrate that the first loop (context-building) is followed by a single high-gain refinement step (loop 2), after which loops become increasingly oscillatory and less productive.
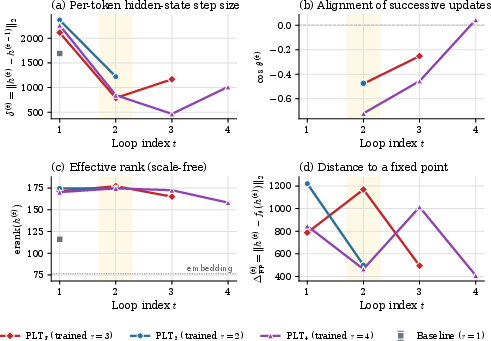
Figure 2: Hidden-state step size and angular change sharply drop past loop 2; effective rank peaks at loop 2 then declines, indicating loss of representational diversity.
The intrinsic offset cost Ω(r)—the average shift-induced mismatch between adjacent token representations—remains nearly constant across loops. Thus, as refinement gains collapse, this cost dominates the effect of further loops.
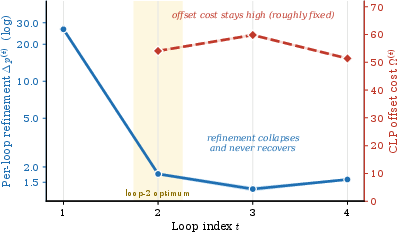
Figure 3: Loop gain-cost scissors; refinement gain per loop (Δp(r), log scale) diminishes rapidly after loop 2, while offset cost R∈{1,2,3,4}0 remains unchanged.
Attention Pattern Analysis
Attention heat-map cosine similarity reveals that head diversity peaks at loop 2 and progressively erodes, with later loops exhibiting increased attention redundancy.
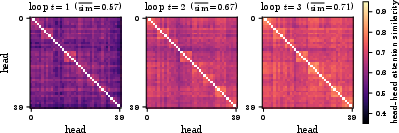
Figure 4: Head R∈{1,2,3,4}1 head cosine similarities per loop index; redundancy increases with loop index, reflecting collapsing attention specialization.
Statistical measures of attention entropy and inter-loop KL divergence further confirm that significant attention re-routing ceases after loop 2.
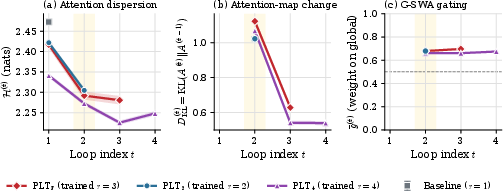
Figure 5: Attention entropy, inter-loop KL divergence, and G-SWA gate mean per loop; divergence drops steeply past loop 2, gate values indicate sustained reliance on frozen global context.
Output Distribution Shifts
Logit-lens analysis of the ground-truth token rank shows that iterative refinement improves predictions primarily at loop 2, with subsequent loops contributing minimal or no gains.
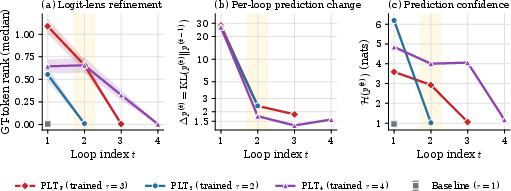
Figure 6: Logit-lens ground-truth rank falls (better prediction) at loop 2; output KL divergence and entropy also saturate after loop 2.
A per-token breakdown indicates that the majority of post-context refinement occurs during loop 2, as assessed by output shift, attention re-routing, and maximal per-token contribution metrics.
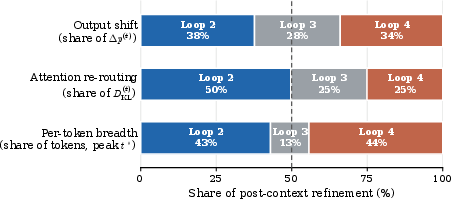
Figure 7: Post-context refinement distribution—loop 2 carries the largest share for all interpretability lenses; subsequent loops are mostly redundant or act as output readouts.
Complementarity With Explicit Chain-of-Thought (CoT)
A comparative study between instruction-tuned (latent) and explicit CoT variants of the R∈{1,2,3,4}2 LoopCoder-v2 shows that explicit and latent reasoning mechanisms are complementary. The aggregate performance with both far exceeds the sum of single-mechanism gains, indicating that latent looped refinement and explicit CoT decomposition operate at different levels of the problem.
Theoretical and Practical Implications
The results provide a diagnostic framework for selecting loop count without exhaustive empirical sweeps. A practical guideline emerges: the loop where the effective rank of hidden states stops rising (here, R∈{1,2,3,4}3) marks the optimal point, beyond which additional loops only incur the CLP-induced offset cost. This interpretable approach obviates indiscriminate application of additional latent computation and informs architectural choices for deployment of PLT-family LLMs.
The theoretical consequence is that, in efficient looped architectures such as PLT, latent refinement is fundamentally limited by the information bottleneck imposed by the cross-loop offset. While recurrent stacking is computationally cheap, representational and routing redundancy, as well as offset mismatch, restrict the depth at which further loops offer net positive gains. In contrast, architectural innovations focusing on adaptive offsets, dynamic loop halting, or richer loop mixing may be necessary to harness deeper latent computation.
Prospects for Future Research
This work highlights several promising directions:
- Adaptive offset mechanisms: Can the CLP offset be dynamically modulated per loop or per sequence?
- Loop halting and selective recurrence: Per-token or per-segment halting could retain heterogeneity in representational depth, as explored in ACT and related architectures.
- Architectural extensions: Incorporating lightweight per-loop adaptation or inter-loop mixing may alleviate representational narrowing.
- Latent/explicit reasoning integration: Deeper study of how looped latent refinement and explicit token-level decomposition interact and compound.
Conclusion
Comprehensive analysis of LoopCoder-v2 demonstrates that, for PLT architectures, a single explicit refinement loop (R∈{1,2,3,4}4) suffices to capture almost all benefits of recurrent latent computation, with higher loop counts yielding diminishing or negative returns due to the constant representational cost of the CLP offset. This effect is mechanistically traced to per-loop dynamics of hidden states, attention, and outputs. The work offers interpretable diagnostics for loop-count selection and elucidates fundamental constraints in the design of efficient, scalable looped LLMs (2606.18023).