- The paper introduces PLT, featuring cross-loop parallelism to compress sequential operations and significantly reduce inference latency.
- The paper presents an efficient representation enhancement strategy using KV-cache sharing and gated sliding-window attention to mitigate memory growth.
- The paper demonstrates through experiments that PLT achieves near-parity in accuracy with traditional loop transformers while reducing computational cost.
Introduction
LLMs are increasingly employed due to their exceptional capabilities; however, they suffer from high inference latency and memory costs. Loop transformers present a potential solution by reusing weights across multiple computation loops. These models achieve parameter efficiency but suffer from increased latency due to the sequential execution of loops. The introduction of the Parallel Loop Transformer (PLT) aims to address these issues by maintaining the advantages of loop transformers while minimizing inference latency.
PLT consists of two primary components: Cross-Loop Parallelism (CLP) and an Efficient Representation Enhancement strategy. CLP decouples sequential loop dependencies by executing different loops for different tokens concurrently. This effectively transforms multiple sequential operations into a parallel process, reducing latency without sacrificing model depth.
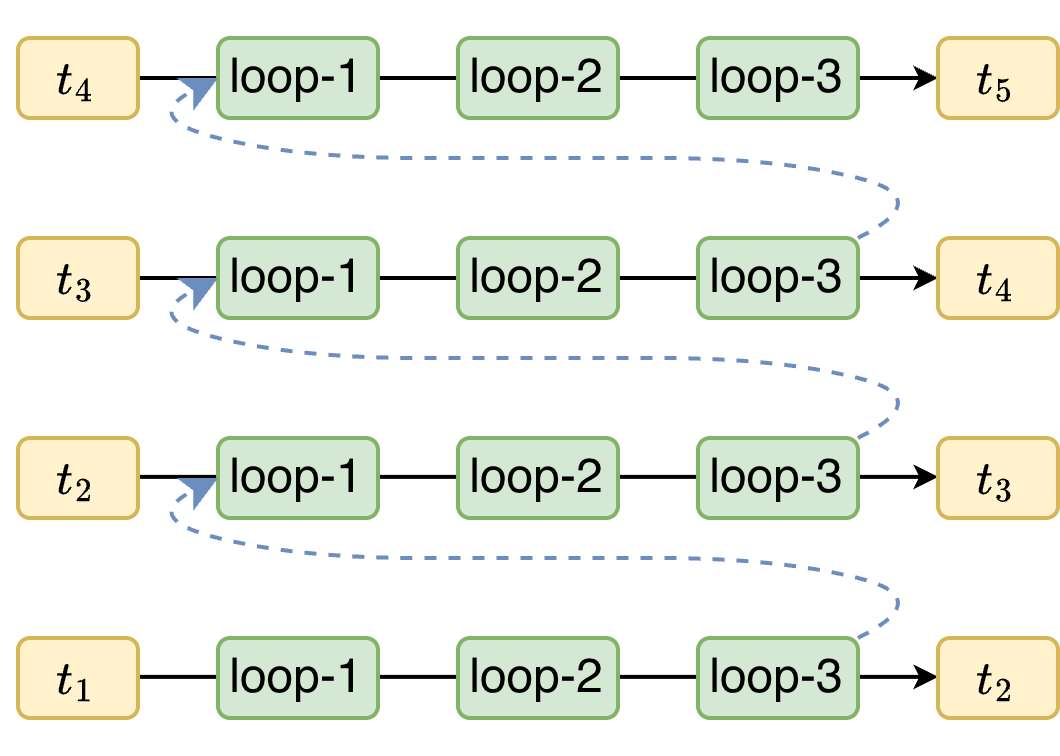
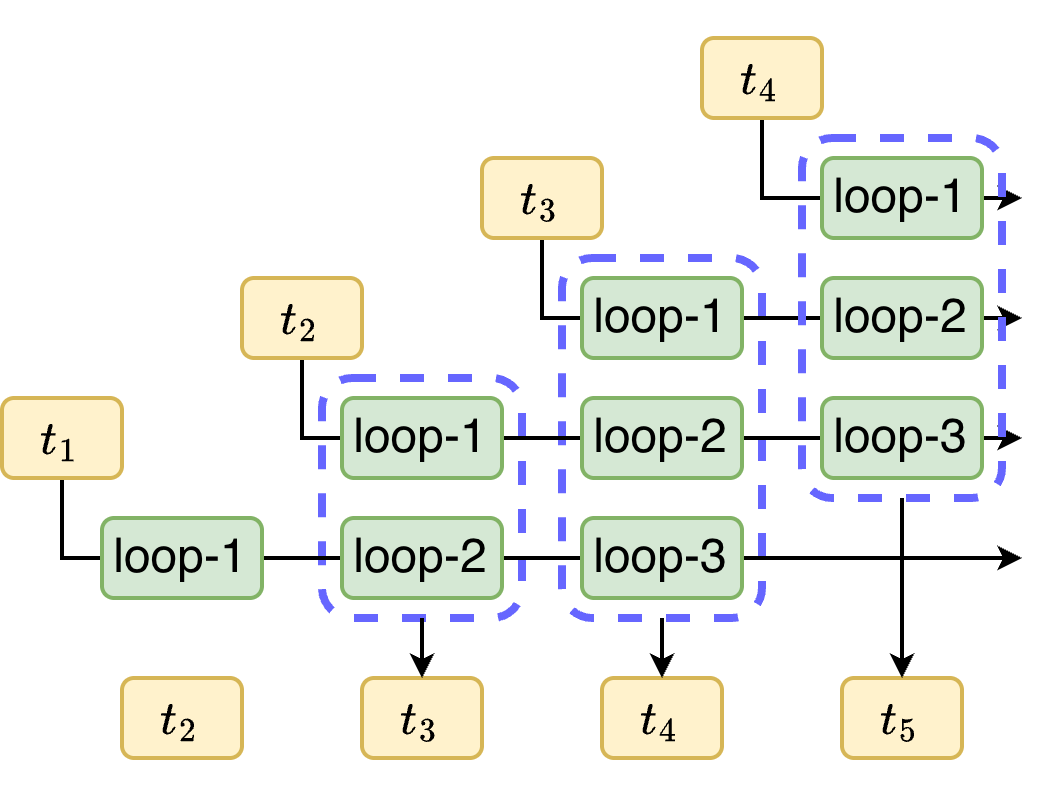
Figure 1: Inference pipeline in vanilla loop transformer.
Cross-Loop Parallelism
CLP allows loops to operate on separate tokens simultaneously, effectively compressing L serial steps into one. For instance, while decoding a sequence, the l-th loop for the current token can be processed alongside the (l+1)-th loop of the previous token. This staggering allows for loop depth without the associated latency increase, as shown in the inference pipeline of PLT.
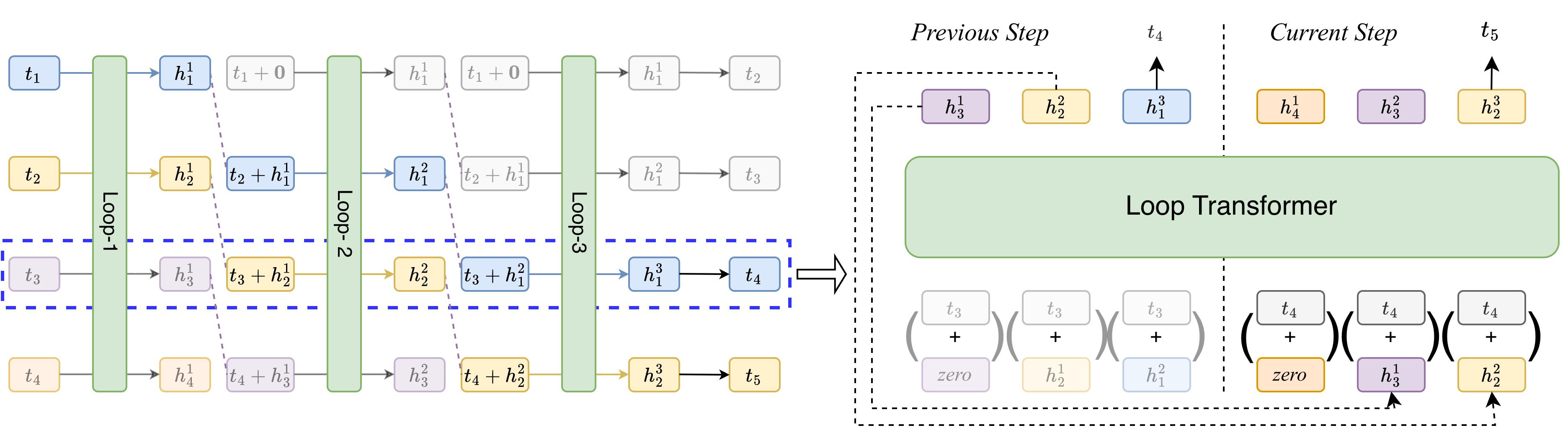
Figure 2: Training and inference pipeline of PLT with loop count L=3.
Efficient Representation Enhancement
To manage memory growth traditionally tied to KV caches in loop transformers, PLT introduces two mechanisms. KV-cache sharing utilizes a common cache for all loops, mitigating the L-fold memory increase. Gated Sliding-Window Attention (G-SWA) complements this by enhancing local context with minimal additional memory. This approach separates global and local attention information, balancing memory usage and performance.
Inference Efficiency
Analyses reveal PLT sustains low latency comparable to standard transformers while avoiding exponential KV cache growth. This efficiency positions PLT as significantly more resource-effective during inference than traditional looped models. Experiments show PLT outperforms vanilla loop transformers regarding accuracy and efficiency, achieving similar or superior results with fewer activated parameters.
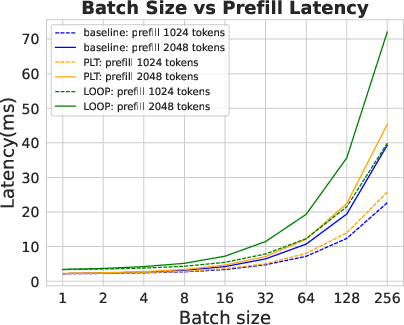
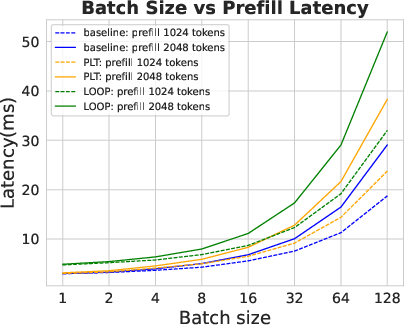
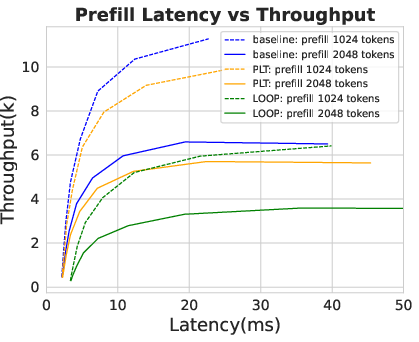
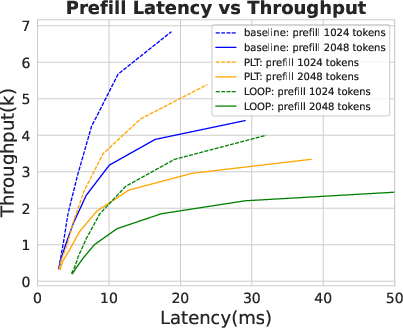
Figure 3: Dense latency.
Experimental Results
Comprehensive evaluations across various datasets demonstrate PLT's superiority in both performance and resource usage. PLT models, even with modest loop counts, achieve near-parity in accuracy with loop transformers but with markedly reduced latency and memory overhead. The scalability of PLT further promises enhanced model performance without compromising inference efficiency.
Conclusion
The Parallel Loop Transformer represents a significant advancement in LLM inference efficiency, effectively combining the performance benefits of looped computation with the low latency of traditional architectures. The novel parallelism techniques in PLT offer significant reductions in computational and memory requirements, making it an attractive choice for real-world applications where resource constraints and speed are critical. This work underscores the potential of hybrid approaches that generalize scope and processing efficiency, setting a new standard for scalable computation in deep learning architectures.

