- The paper introduces the CSTS framework to decompose tasks into subtasks and generate, assess diverse skills with collective model intelligence.
- It leverages Collective Skill Reinforcement Learning (CSRL) to optimize skills across heterogeneous LLMs, enhancing planning, tool use, and execution.
- Empirical results on QwenClawBench and PinchBench demonstrate significant improvements in procedural robustness and transferability.
OpenClaw-Skill: Structured, Diverse, and Transferable Skill Construction for Agentic LLMs
Motivation and Challenges in Skill Construction
Modern LLM agents exhibit increasing competence in open-ended, agentic environments, notably OpenClaw, which imposes intricate requirements including multi-step reasoning, tool usage, file operations, and dynamic decision-making. The operational bottleneck for scalable agent deployment remains effective skill construction, as extant paradigms are predominantly handcrafted, fragmented, and lack cross-model transferability and diversity. The paper identifies three principal deficiencies: skill fragmentation (local, shallow procedures), limited diversity (single-model bias), and poor transferability (performance drop across LLM backbones). By leveraging collective intelligence and explicit compositional structure, the proposed CSTS paradigm addresses these gaps.
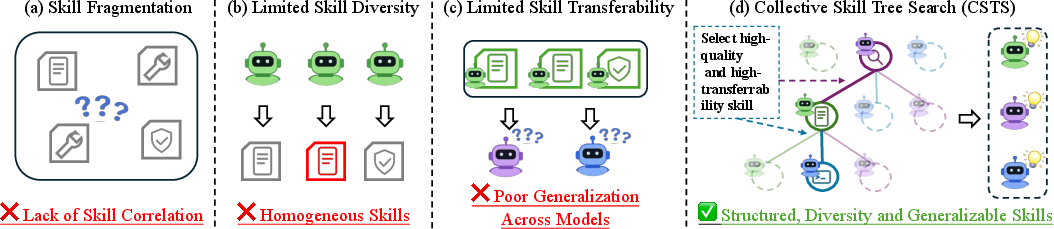
Figure 1: Motivation for CSTS; skill construction suffers from fragmentation, limited diversity, and poor transferability across LLM backbones.
Collective Skill Tree Search Framework
OpenClaw-Skill is built upon the CSTS framework, which systematically decomposes complex tasks into ordered subtasks and organizes procedural skills via a tree-search-based construction. CSTS proceeds in two iterative phases:
- Collective Skill Node Generation (CSN-Gen): Multiple heterogeneous models generate diverse trajectories for each subtask, furnishing a spectrum of candidate skills.
- Collective Skill Node Assessment (CSN-Assess): Multiple model judges independently score each candidate skill for procedural quality and empirically measure transferability by evaluating whether a synthesized skill generalizes to other models.
The resulting skill hierarchies form tree-structured search spaces, where paths encode compositional skill plans with stage-wise dependency resolution.
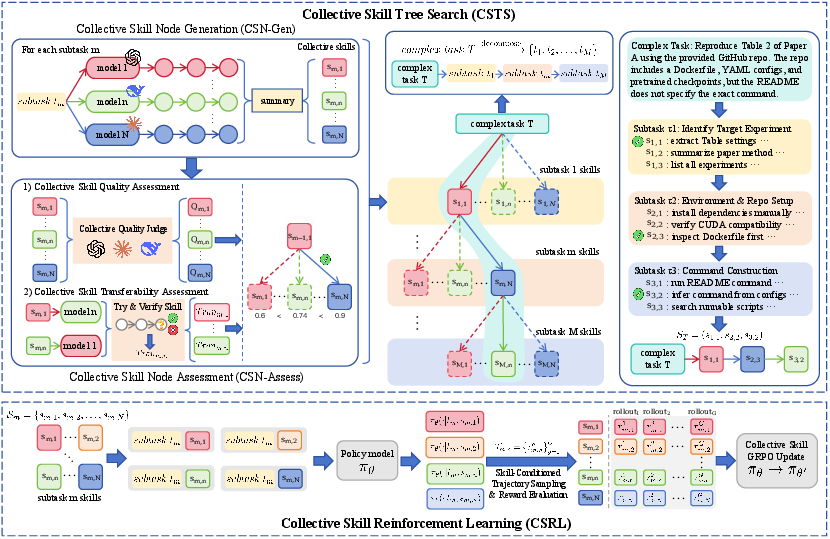
Figure 2: CSTS decomposes tasks into subtasks, generating and assessing diverse candidate skills; selected nodes form a tree-structured compositional skill plan.
Structured skill composition in CSTS directly mitigates fragmentation, enabling long-horizon orchestration and dependency management. Diversity is achieved by aggregating heterogenous trajectories, while transferability is enforced via explicit cross-model rollout validation. CSTS produces skill-augmented data for supervised fine-tuning; the skill path for each task is an ordered sequence of maximally scored skills.
Collective Skill Reinforcement Learning
To avoid suboptimal convergence to homogeneous or single-skill strategies, Collective Skill Reinforcement Learning (CSRL) is introduced. CSRL operates over skill-conditioned trajectory groups for each subtask, employing group-relative policy optimization: advantages are computed across all candidate skills’ rollouts, normalizing via cross-skill group statistics. This paradigm encourages competitive selection among candidate skill-conditioned strategies and constrains the policy to adaptively fit effective procedural variants.
The CSRL objective extends the GRPO-style loss to action-level optimization across collective skill groups, amplifying the likelihood of actions from rollouts demonstrating relative merit and suppressing ineffective behaviors. This directly translates skill diversity into actionable policy improvement, augmenting agent robustness and flexibility.
Empirical Results and Analysis
QwenClawBench
OpenClaw-Skill demonstrates consistent improvements on QwenClawBench across all evaluated Qwen backbones. For instance, OpenClaw-Skill 9B achieves a 10.4-point gain over vanilla Qwen3.5-9B, with notable improvements in categories demanding long-horizon tool use and execution feedback (SVM: 33.2→70.9; CS: 30.2→78.4). The ablation study reveals incremental gains from CSN-Gen, CSN-Assess, and full CSRL, substantiating that both collective skill construction and reinforcement learning are necessary for maximal agentic performance.
PinchBench
OpenClaw-Skill outperforms corresponding Qwen baselines on both the original and expanded PinchBench benchmarks. For the 123-task setting, OpenClaw-Skill 9B boosts the best score from 61.1 to 68.2 and the average score from 47.1 to 53.6. Smaller backbones also benefit substantially, showing improvements in average execution robustness and peak performance.
Ablation
Incremental addition of CSN-Gen, CSN-Assess, and CSRL yields monotonic performance gains, underscoring the necessity of each component. Diverse skills (CSN-Gen) improve procedural coverage; judge-based skill selection and transfer validation (CSN-Assess) filter noise and enhance generalizability; reinforcement learning via CSRL further optimizes agentic performance over the composite skill space.
Implications and Prospects
The CSTS paradigm represents a shift toward leveraging collective intelligence and explicit task decomposition for scalable, generalizable agentic skill construction. Practically, the framework reduces manual intervention, enhances procedural diversity, and improves transferability across heterogeneous LLM backbones. Theoretically, it aligns skill construction with structured search and compositional reasoning, facilitating hierarchical policy learning and adaptive execution.
Future developments may include integration of CSTS with larger, multimodal LLMs, automatic discovery and refinement of novel skills via unsupervised or meta-learning paradigms, and cross-environment skill transfer. The explicit use of collective evaluation and transfer in skill selection suggests directions for federated agent training and robust cross-domain adaptation.
Conclusion
OpenClaw-Skill establishes a unified, automatic skill construction and training pipeline for agentic LLMs, built on Collective Skill Tree Search and reinforced via skill-conditioned group relative optimization. Systematic empirical evidence demonstrates substantial improvements in long-horizon planning, tool use, and execution robustness. The paper represents a rigorous advance in compositional, transferable skill acquisition for LLM agents, with broad implications for scalable agentic autonomy.

