- The paper introduces Ctx2Skill, a framework that automatically extracts modular skills from context, achieving up to 5.4% improvements on CL-bench tasks.
- It employs a self-evolving multi-agent system and a Cross-Time Replay mechanism to mitigate adversarial collapse and optimize skill generalization.
- Experimental results demonstrate robust gains in complex reasoning tasks with effective transferability across different language model backbones.
Ctx2Skill: Autonomous Discovery of Context-Specific Skills for LLMs
Ctx2Skill addresses a critical gap in current LLM capabilities: robust context learning in scenarios where domain-specific, complex contexts must be used for reasoning, rather than relying on parametric knowledge acquired during pretraining. In realistic use cases—such as interpreting technical documentation, scientific data, or extensive legal texts—current LMs struggle to extract, synthesize, and operationalize procedural rules or latent knowledge from context alone. Previously, most skill augmentation approaches have relied on costly manual annotation or external feedback (such as programmatic task success signals). These are infeasible for dense, specialized contexts and have limited utility for black-box or closed LMs that cannot be further fine-tuned.
The Ctx2Skill framework redefines skill acquisition as an automated, feedback-free process, leveraging only the context itself to produce reusable natural language skills—modular, explicit procedural rules or strategies—packaged for injection at inference time. This approach aims to circumvent prohibitive annotation requirements and the absence of external evaluative signals ubiquitous in document-centric tasks.
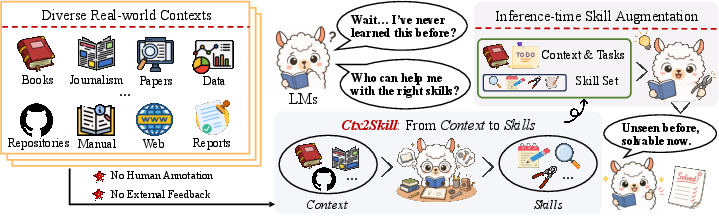
Figure 1: Ctx2Skill autonomously extracts skills in natural language from complex context, requiring neither annotation nor feedback signals.
Framework Architecture
At its core, Ctx2Skill implements a self-evolving multi-agent system featuring three primary roles:
- Challenger: Generates probing tasks and associated rubrics from the context and its current skill knowledge, seeking to expose overlooked or poorly captured context-specific knowledge.
- Reasoner: Attempts to solve these tasks using the same context plus its current skill set, which is iteratively distilled and augmented.
- Judge: Provides fine-grained binary feedback per rubric but uses no gold standard or additional external signals.
Failure-driven skill updates are coordinated via two additional sub-agents—Proposer (diagnosis) and Generator (update synthesis)—on both the Challenger and Reasoner sides. Importantly, both Challenger and Reasoner evolve through updates to their skill documents rather than model parameters, maintaining compatibility with closed-source or API-based LMs.
A unique challenge uncovered is adversarial collapse: as iterations proceed, the Challenger may hyper-specialize task generation around remaining Reasoner weaknesses, causing overfitting and diminishing broader generalization. Ctx2Skill mitigates this through a Cross-Time Replay mechanism, re-evaluating skill sets from each iteration on representative probe tasks to select the maximally generalizable configuration.
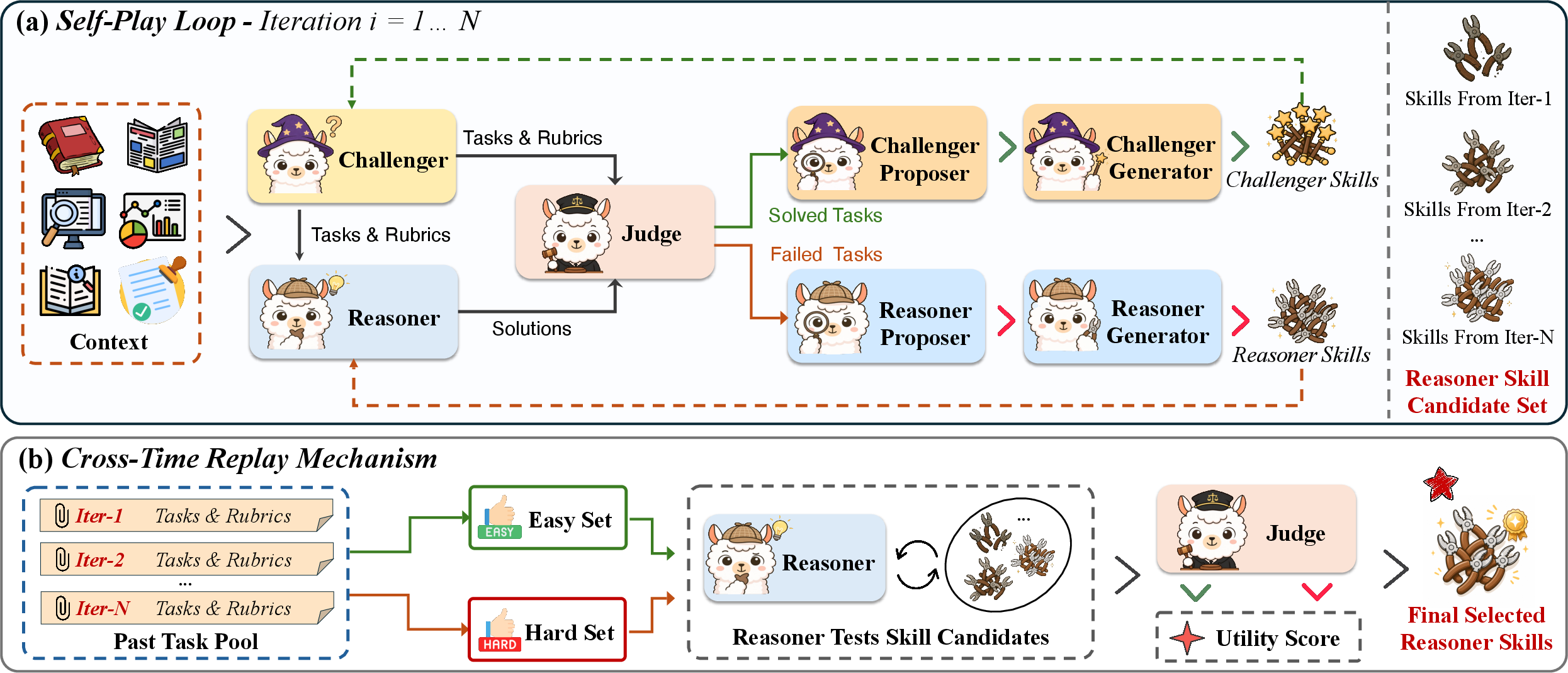
Figure 2: Schematic of Ctx2Skill: (a) self-play cycle for skill evolution, (b) Cross-Time Replay selects the optimal skill set per context for downstream robustness.
Experimental Validation
Evaluation is conducted on the CL-bench benchmark, encompassing 500 contexts and 1,899 diverse tasks across four categories: Domain Knowledge Reasoning, Rule System Application, Procedural Task Execution, and Empirical Discovery Simulation. Each task strictly requires that all specified rubrics be satisfied for a 'solved' outcome.
Ctx2Skill consistently delivers substantial improvements independent of the LM backbone, using only inference-time skill augmentation. Notable results include:
- GPT-4.1: Solving rate increases from 11.1% to 16.5% (+5.4%), surpassing stronger models without skill augmentation.
- GPT-5.1: Solving rate rises from 21.1% to 25.8% (+4.7%).
- GPT-5.2: Solving rate grows from 18.2% to 21.4% (+3.2%).
Gains are most significant for categories requiring complex, inductive procedures and multi-step context composition. Ablation studies strongly support the necessity of adversarial co-evolution (both Challenger and Reasoner skill updates) and the Cross-Time Replay mechanism. Direct comparison with baseline single-pass skill extraction (Prompting) and prior automated techniques (AutoSkill4Doc) shows that Ctx2Skill yields superior skill quality in terms of conciseness, clarity, faithfulness, and reusability, with increases of 2–3 points in multi-dimensional GPT-based scoring.
Transfer experiments corroborate that skills discovered by stronger LMs can be leveraged by weaker LMs, but the converse transfer is less effective, highlighting backbone-dependent extraction limits.
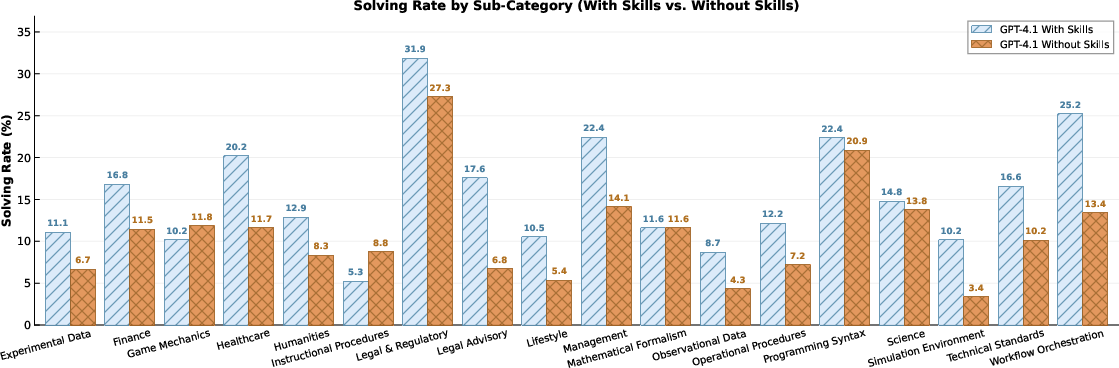
Figure 3: Ctx2Skill achieves higher solving rates across nearly all CL-bench sub-categories compared to the unskilled base model.
Theoretical and Practical Implications
Ctx2Skill’s paradigm constitutes an explicit, modular approach for enhancing LM context learning capacity—crucially, without parameter updates or external labels. This is particularly relevant for regulated environments, closed-source commercial LMs, and scenarios where context-Shots or in-context pattern induction are insufficient due to the knowledge complexity, domain novelty, or structure of the context.
From a theoretical perspective, Ctx2Skill demonstrates that multi-agent adversarial self-play—previously mainly used for policy distillation or RL in interactive environments—can extend to the purely textual context learning setting when paired with carefully constructed cross-time selection and iterative textual feedback. The explicit natural language skills generated are also inherently interpretable and auditable, supporting downstream explainability and skill-oriented audit processes.
For practical applications, Ctx2Skill offers a scalable, annotation-free pipeline for generating domain-adapted procedural abstractions, which can be integrated into LM deployments to: (i) improve accuracy on document-centric or knowledge-grounded tasks, (ii) reduce hallucination and knowledge-conflict errors, and (iii) provide a means for continual, context-driven evolution of model behavior with no retraining.
Future Directions
Future research directions emergent from Ctx2Skill’s architecture include:
- Extending the self-play and replay selection logic to multi-modal or multi-document scenarios.
- Joint or federated skill evolution across multiple related contexts to enable broader transfer and compositionality.
- Integration with retrieval-augmented or tool-augmented LM pipelines for end-to-end context learning with dynamic external sources.
- Formal exploration of connections to meta-learning, lifelong skill composition, and automated distillation of parametric knowledge into modular natural-language representations.
Conclusion
Ctx2Skill advances the state of the art for automated extraction and operationalization of context-dependent skills in LLMs. By fully decoupling skill acquisition from costly annotation and parameter tuning, and by incorporating adversarial and cross-time replay mechanisms, Ctx2Skill establishes a scalable, robust pipeline for context learning that is both practical and theoretically grounded. The empirical results demonstrate substantial improvements in complex reasoning, with strong transferability and interpretability properties, motivating further research into context-driven agent skill learning (2604.27660).