Rethinking the Role of Efficient Attention in Hybrid Architectures
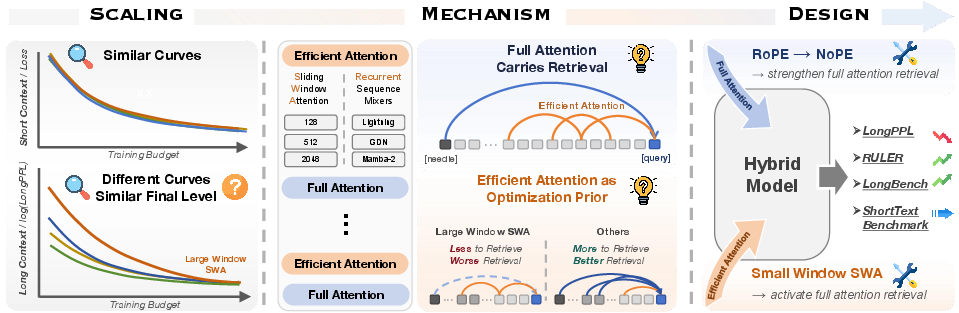
Abstract: Modern LLMs increasingly adopt hybrid architectures that combine full attention with efficient attention modules, such as sliding-window attention (SWA) and recurrent sequence mixers. However, how these efficient modules shape model capabilities remains poorly understood. To address this gap, we conduct a systematic analysis across hybrid architectures from three perspectives: scaling behavior, mechanism analysis, and architecture design. First, from a scaling perspective, we find that efficient-attention design primarily affects how fast long-context capability emerges, while different hybrids eventually converge to comparable long-context performance under sufficient training. Second, mechanistically, we show that long-range retrieval is mainly carried by full attention, whereas efficient attention shapes its optimization trajectory. This explains a counter-intuitive phenomenon we call Large-Window Laziness: larger SWA windows can delay the formation of retrieval heads in full-attention layers. Third, guided by this mechanism, we show that applying NoPE to only the full-attention layers of a small-window SWA hybrid substantially improves long-context performance with negligible impact on short-context performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Rethinking the Role of Efficient Attention in Hybrid Architectures — Explained Simply
1) What is this paper about?
This paper studies how different “attention” tricks inside LLMs help them read and understand very long texts. Many modern models mix two kinds of attention:
- Full attention: the model can look anywhere in the whole text.
- Efficient attention: the model looks only nearby (sliding windows) or keeps a short summary of the past (recurrent mixers like Mamba).
The authors ask: in these mixed (hybrid) models, what really makes long-text understanding work, and how should we design these models to be better?
2) What questions did the researchers ask?
The paper focuses on three simple questions:
- Scaling behavior: As models get bigger and train longer, how do their short-text and long-text skills improve?
- Mechanism: In hybrid models, which part actually carries the long-distance information—the full attention or the “efficient” modules—and how do these parts affect training?
- Design: Given what we learn, how should we build hybrid models to get stronger long-text understanding?
3) How did they study it?
To make fair, easy-to-compare tests, they used a few clear ideas:
- Measuring two kinds of skill
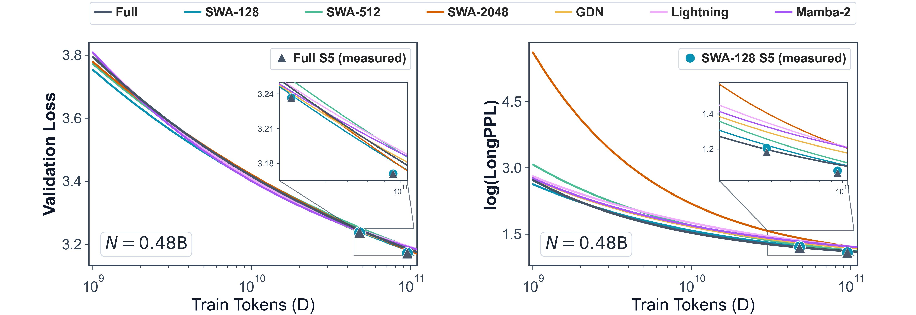
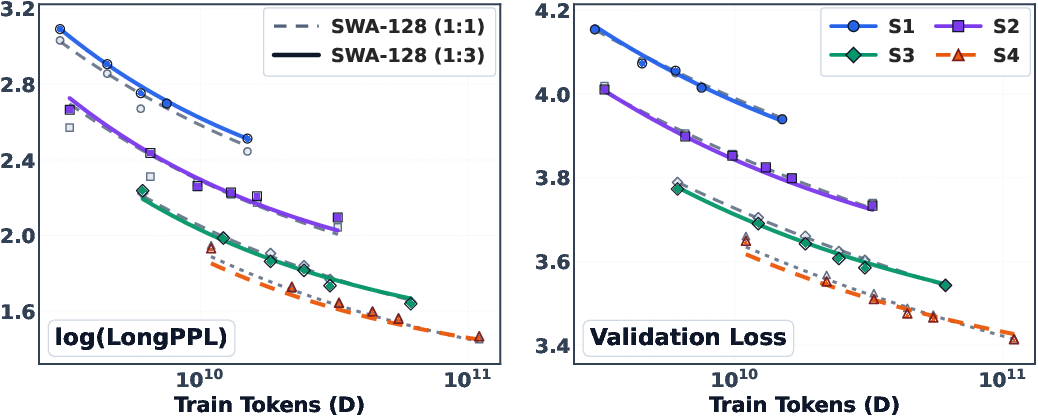
- Short-text skill: “validation loss,” a standard score that says how well the model predicts the next word on regular-length text.
- Long-text skill: “LongPPL,” a smooth, continuous score that acts like perplexity but is designed to reflect how well a model handles very long contexts.
- Comparing different hybrid designs
- Sliding-Window Attention (SWA): the model can only look back a fixed number of tokens (like reading only the last few pages).
- Recurrent mixers (e.g., Mamba-2, Lightning, Gated DeltaNet): the model keeps a running summary of the past (like keeping notes as you read).
- Scaling experiments
- They trained models of different sizes for different amounts of data to see overall trends, not just final scores.
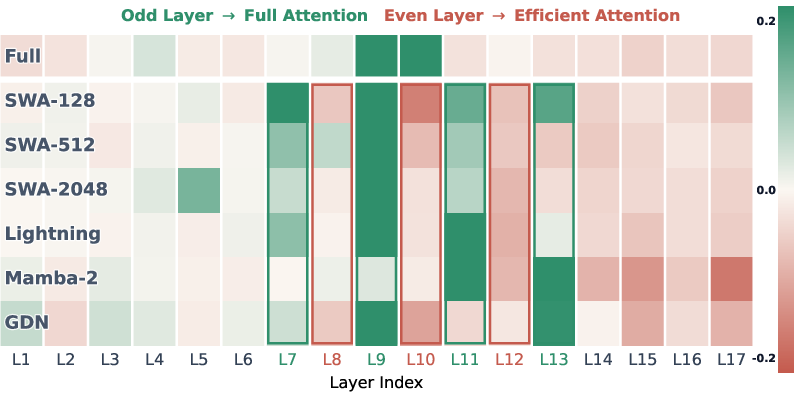
- Mechanistic tests (what’s really happening inside)
- Receptive-field restriction: at test time, they artificially limited how far each part (full attention vs efficient attention) could look to see which one is actually carrying long-range information.
- Layer-wise probing: they inserted a “needle in a haystack” (a hidden fact far back in the text) and checked layer by layer which parts of the model are bringing that far-away fact to the surface.
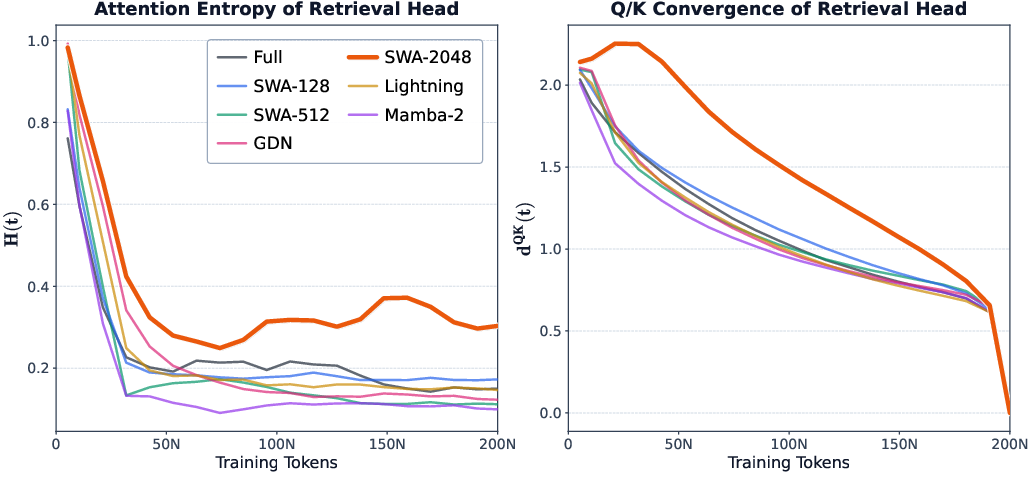
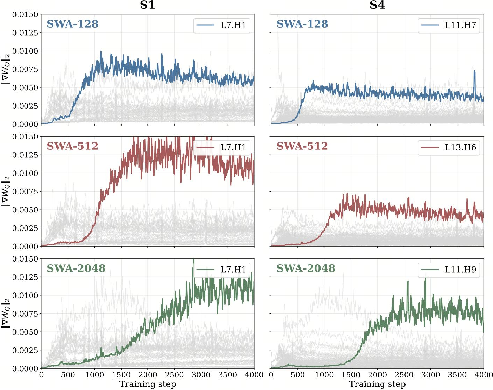
- Tracking “retrieval heads”: these are special attention heads that learn to jump to the right place in the text to fetch needed info. They watched how fast these heads form during training.
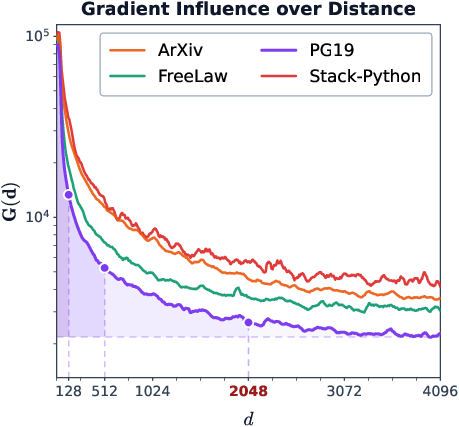
- Gradient influence profiling: they measured how much the training signal depends on words at different distances, to see how helpful nearby vs far-away tokens are during learning.
Think of it like testing a reading strategy: they watched how models learn to flip back to earlier pages, whether they rely on summaries, and which parts of the “brain” do the most useful long-distance lookups.
4) What did they find, and why is it important?
Here are the main findings, with plain-language explanations:
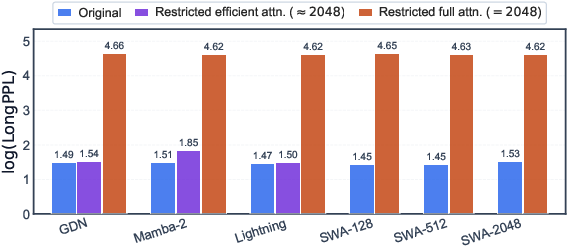
- Full attention does the heavy lifting for long-range understanding.
- When they restricted how far full attention could look, long-text performance dropped a lot.
- When they restricted efficient attention’s range, performance barely changed.
- Probing showed that the layers with full attention were the ones adding most of the useful long-distance information.
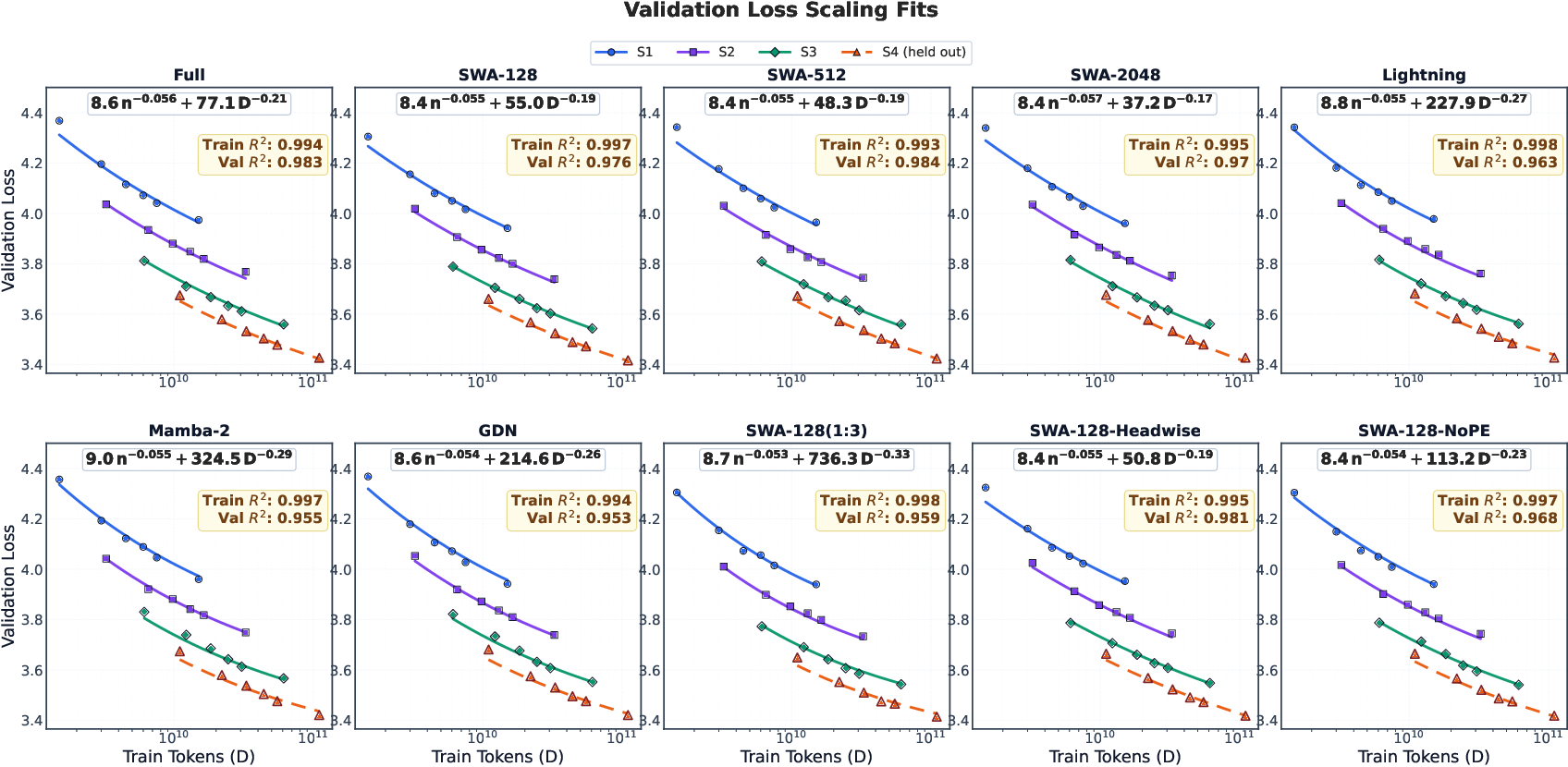
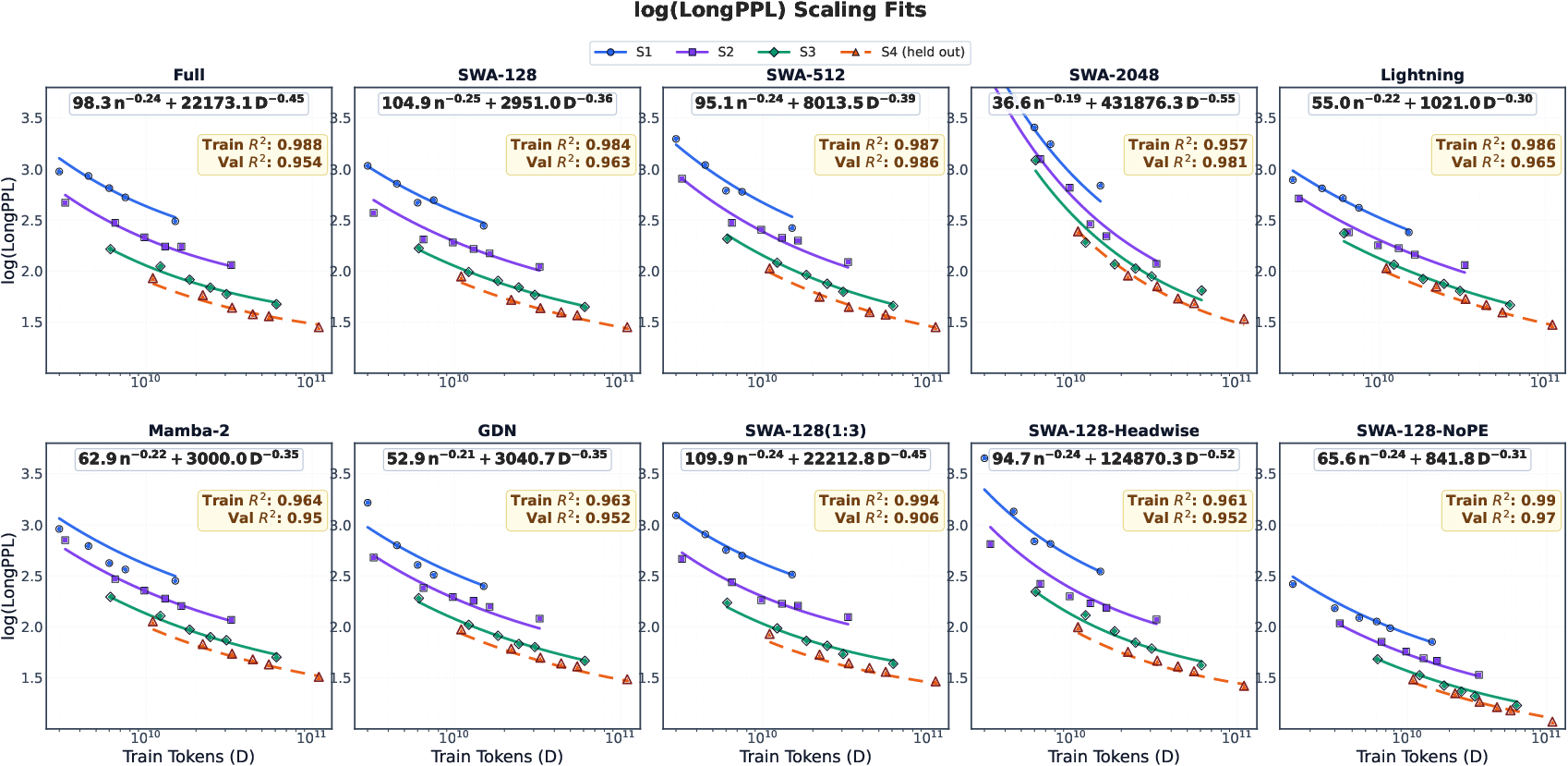
- Efficient attention doesn’t set the final ability—it changes how fast the model learns it.
- With enough training, most hybrids reach a similar long-text level because they all share the same full-attention layers that ultimately do the long-distance retrieval.
- But the type of efficient attention strongly affects the speed at which long-context skill appears.
- Large-Window Laziness: bigger local windows can slow down learning to retrieve far-away info.
- If the sliding window is very large, the model can often solve prediction tasks using only nearby text. That means there’s less “pressure” for full attention to learn long jumps to far-away tokens.
- They saw this by tracking retrieval heads: with very large windows (like SWA-2048), these heads formed later and remained weaker during training.
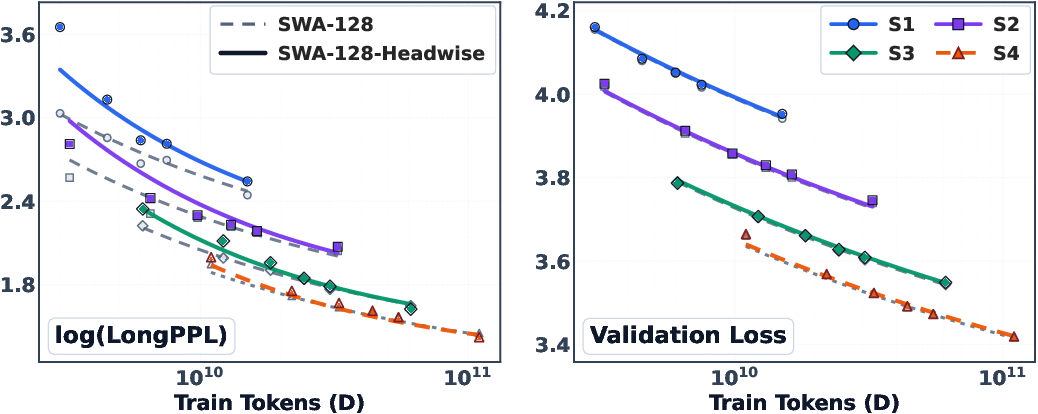
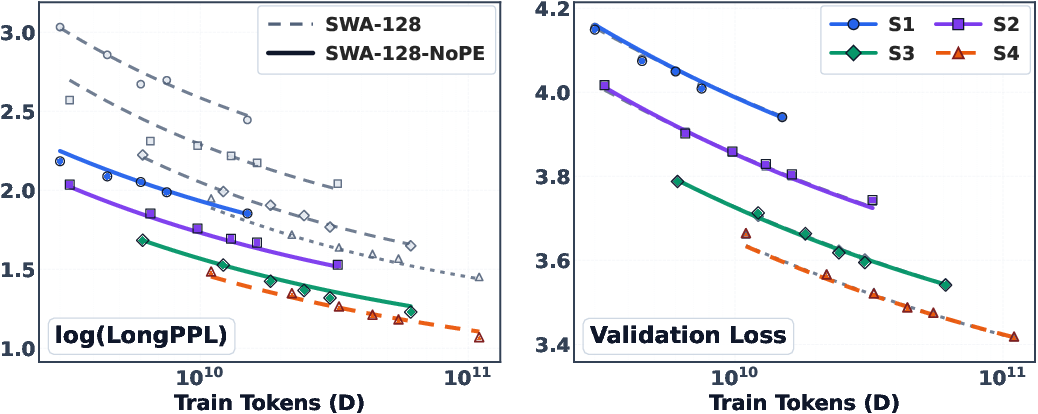
- A simple design tweak helps a lot: use NoPE in the full-attention layers (with a small window SWA).
- NoPE changes how the model handles positions so it’s less tied to exact distances. This made retrieval across long distances easier.
- Result: much better long-text performance with almost no cost to short-text skill.
Why this matters: If you’re building a model for long documents, don’t just make the “efficient” part bigger. Focus on helping full attention learn to retrieve from far away—quickly and reliably.
5) What’s the impact and what should designers do next?
The big takeaway: Efficient attention acts like training wheels. It shapes the learning path but doesn’t carry the final long-distance understanding. So:
- Under limited training budgets, prefer designs that push full attention to learn long-range retrieval sooner, not ones that let it “coast” on big local windows.
- Use smaller SWA windows to keep strong pressure to learn long jumps.
- Strengthen full attention directly, for example by applying NoPE to its layers.
- You can also reduce how many full-attention layers you use once the model is big enough, but don’t starve the model of full attention early on.
In short: Full attention is the key for long texts. Efficient attention should be chosen to help full attention learn faster—not to replace it.
Note on limits: The study used sub-billion-parameter models and contexts up to 32K tokens, which are smaller than the very largest industrial models. Still, the patterns they found are clear and useful for guiding practical hybrid designs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain, missing, or unexplored, framed to guide follow-up research.
- External validity at larger scales: Results are demonstrated up to ~0.66B parameters and ~100B tokens. It remains unknown whether the convergence of long-context performance across hybrids and the “Large-Window Laziness” effect persist for 7B–70B+ models and 300B–1T+ tokens.
- Context-length generalization: All models are pretrained at 16K and (partially) extended to 32K. It is unclear if conclusions hold for 64K–1M token contexts, and whether efficient modules begin to carry more long-range information at extreme lengths.
- Training recipe dependence: The study trains directly at long context; the industry-standard short-to-long curriculum is not tested. How do scaling curves, retrieval-head formation, and the “laziness” phenomenon change under curriculum schedules?
- Efficient-attention coverage: Only SWA (128/512/2048) and three recurrent mixers (Lightning, Mamba-2, GDN) are examined. Other widely used designs (e.g., RWKV-7, Kimi-Linear, Hyena, dilated/sparse/k-NN attention, memory tokens/global tokens, retrieval-augmented hybrids) are not tested.
- Static vs dynamic window schedules: Only fixed SWA windows are used. Do curriculum schedules that start small and grow (or decay) window size alter optimization pressure and mitigate Large-Window Laziness?
- Full-attention density and placement: Beyond a limited 1:1 vs 1:3 comparison, the minimal number and optimal placement (early/mid/late) of full-attention layers for different model scales and budgets are not characterized.
- Head-wise vs layer-wise mixing generality: The head-wise vs layer-wise comparison is limited to one SWA setting. It is unknown if head-wise mixing helps recurrent hybrids, larger models, or different positional encodings.
- Positional encoding design space: Only NoPE-in-full-attention is tested. The interaction of RoPE variants (e.g., ALiBi, YaRN, XPOS, rotary scaling), absolute/relative encodings, or hybrid PE schedules with efficient-attention modules is not explored.
- Mechanistic causality of Large-Window Laziness: Evidence is correlational. Controlled interventions (e.g., masking local windows at fixed loss, adding retrieval-specific auxiliary losses) are needed to causally verify the mechanism.
- Gradient influence profiling validity: Gradient-distance profiles are estimated using Llama-3.1-8B, assuming model-agnosticity. Measuring profiles directly on the trained hybrids would remove this assumption and test robustness across data domains.
- Retrieval-head identification and scope: Tracing focuses on NIAH-style retrieval. Whether conclusions hold for diverse long-range phenomena (entity coreference, multi-hop QA over books, code-level dependency chains, math proofs, long dialogues) remains untested.
- Do recurrent mixers truly fail to store long-range info or were they under-optimized? The study finds minimal long-range contribution from mixers, but does not vary state size, decay/gating parameterization, initialization, or training objectives designed to promote memory retention.
- Task- and domain-dependence of scaling: Pretraining uses a 1:1 long/short mixture (C4-like). How do results change with code-heavy corpora, multilingual data, scientific texts, or corpora with denser long-range dependencies?
- Metric dependence of long-context scaling: LongPPL uses GovReport and a single reference model. Sensitivity to the choice of corpus, reference model, chunking, and tokenization is not assessed; multi-reference validation and additional continuous metrics are needed.
- Benchmark coverage: Downstream evaluation centers on RULER/LongBench. Realistic very-long tasks (book QA, legal/financial document reasoning, streaming transcripts) and in-the-wild agentic workflows are not assessed.
- Short-context side effects of NoPE: While ShortAvg remains comparable, per-task impacts (e.g., tasks requiring fine-grained positional order) are not reported. Are there systematic trade-offs between NoPE gains at long range and position-sensitive tasks?
- Compute–efficiency trade-offs: The paper focuses on capability scaling but does not quantify throughput, memory footprint, wall-clock time, or energy for each hybrid. Practitioners lack guidance on capability-per-FLOP or capability-per-latency.
- KV-sharing and head allocation: Models fix Q-head vs KV-head counts and head dimensions. The effect of KV sharing (MQA/GQA), head count, and head dimension on retrieval-head emergence is not explored.
- Interaction with optimizer/hyperparameters: Potential interactions with learning-rate schedules, optimizers (AdamW vs Lion/Adafactor), warmup, weight decay, dropout, and normalization are not ablated; these may materially affect retrieval learning.
- Minimal full-attention schedule for compute-optimal training: The study suggests fewer full-attention layers may suffice at scale, but does not provide principled curves or recipes to select density/placement under a fixed compute budget.
- Hybrid-specific regularization/objectives: No targeted objectives (contrastive retrieval, needle reconstruction, associative recall) or regularizers are tried to accelerate retrieval-head formation without hurting short-context loss.
- Dynamic hybrid controllers: It remains unknown whether learnable controllers (routing gates deciding when to invoke global vs local/recurrent modules) could avoid Large-Window Laziness while preserving efficiency.
- Continual pretraining and post-hoc context extension: The effects of continued training from short-context checkpoints or rope-scaling at inference on hybrids are not evaluated; many production systems rely on such workflows.
- Mixed precision, quantization, and KV compression: The robustness of conclusions under low-precision training/inference, 4–8 bit quantization, and KV cache compression is not tested, yet these are crucial in deployment.
- Streaming and online settings: How do hybrids behave in streaming generation with long histories, truncation, and limited KV cache, where recurrent mixers could have advantages?
- Theoretical grounding: No formal analysis explains why different hybrids converge to similar long-context performance or precisely how efficient modules shape optimization trajectories; a theoretical treatment could guide principled design.
- Safety and robustness: The impact of hybrid design choices on robustness to adversarial long-context prompts, position-shift perturbations, or distribution shifts in context length/content is unstudied.
- Multimodal and tool-augmented scenarios: Whether conclusions transfer to vision–language or tool-using LLMs (where long context and memory are critical) is unknown.
- Code/data variability and reproducibility: While code is released, sensitivity to tokenization, vocabulary size, dataset deduplication, and preprocessing choices is not quantified, which could affect the generality of the scaling fits and mechanistic findings.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s findings that long-range retrieval is primarily carried by full attention and that efficient attention acts as an optimization prior affecting convergence speed.
- Training recipes to accelerate long-context capability under limited compute (sectors: software/AI, academia)
- Use small-window SWA (e.g., 128–512) and apply NoPE to full-attention layers to speed up the emergence of retrieval heads without hurting short-context quality.
- Maintain a denser full:efficient layer ratio (e.g., 1:1) at small model/data scales to avoid stalling long-context emergence; reduce to sparser ratios (e.g., 1:3) only at larger scales.
- Avoid head-wise hybridization for now (layer-wise full attention performs similarly and converges faster in long-context metrics).
- Tools/products/workflows: ready-to-use training configs in common libraries (e.g., Hugging Face Transformers templates), open-source “long-context starter” recipes with SWA-128 + NoPE-on-full-attn.
- Dependencies/assumptions: results empirically validated up to ~0.66B params and ~100B tokens; benefits may vary with tokenizer/architecture and larger scales.
- Monitoring and QA for long-context readiness (sectors: software/AI, academia, LLMOps)
- Track LongPPL (or log(LongPPL)) during pretraining as a smooth, early indicator of long-context emergence; fit simple scaling curves to predict convergence.
- Add retrieval-head diagnostics (attention entropy, Q/K drift) to training dashboards to confirm that full-attention retrieval is forming on schedule.
- Use inference-time receptive-field restriction tests (limit full-attn vs efficient-attn) to verify that long-range information indeed flows through full attention.
- Tools/products/workflows: Weights & Biases dashboards for LongPPL and retrieval-head metrics; evaluation harnesses with RF-ablation tests; CI checks for “long-context readiness.”
- Dependencies/assumptions: LongPPL references a chosen model (e.g., Llama-3.1-8B); ensure consistent setup for comparability.
- Cost-aware curriculum scheduling (sectors: software/AI, academia)
- Begin pretraining with small SWA windows to force retrieval learning, then optionally widen windows or reduce full-attn density after retrieval heads stabilize.
- Dependencies/assumptions: requires periodic retrieval-head/LongPPL checks; optimal switching points may be data/architecture dependent.
- Inference-time configuration policies for long documents (sectors: enterprise software, document analytics, legal, healthcare, finance)
- For tasks requiring cross-document or long-range recall, allocate sufficient full-attention capacity (activate all full-attn layers; avoid relying on recurrent mixers for long-range retrieval).
- For short-context tasks, shift more load to efficient attention to reduce latency/compute.
- Products/workflows: dynamic routing policies in serving stacks that enable/disable full-attn based on input length and task requirements.
- Dependencies/assumptions: serving system must support layer gating and per-request policies.
- Model selection and procurement guidelines (sectors: industry, public sector, policy)
- Require vendors to report LongPPL and to disclose hybrid design (window sizes, full:efficient ratios, positional encodings in full-attn).
- Favor models trained with small-window SWA and NoPE-in-full-attn for long-document use cases under constrained budgets.
- Workflows: add “long-context readiness” criteria to RFPs; request RF-restriction ablation evidence.
- Dependencies/assumptions: standardization of LongPPL evaluation and datasets used for assessment.
- Benchmarking and evaluation upgrades (sectors: academia, standards bodies, eval providers)
- Complement discrete long-context benchmarks (e.g., RULER, LongBench) with continuous LongPPL tracking to capture training dynamics.
- Adopt NIAH-style probing at multiple layers to confirm that long-range info increases in full-attn layers.
- Products: evaluation suites that ship with LongPPL/NIH probes and RF-restriction scripts.
- Dependencies/assumptions: correlation between LongPPL and downstream tasks holds on target domains.
- Domain-specific deployment choices for long documents
- Legal/Compliance/Finance/Healthcare document processing: select or fine-tune hybrids with small SWA windows and NoPE in full-attn to improve cross-section retrieval, contract clause linking, longitudinal patient record recall, or risk report synthesis.
- Education/Knowledge management: for textbook- or note-spanning Q&A, prefer models following the above recipe to achieve stronger long-range recall at smaller scales.
- Dependencies/assumptions: domain data must contain long-range dependencies; fine-tuning should preserve full-attn retrieval behavior.
Long-Term Applications
The following opportunities require further research, scaling, or systems development to realize at larger model sizes, longer context lengths, or broader modalities.
- Adaptive window and ratio schedulers (sectors: software/AI, MLOps)
- Auto-tune SWA window sizes and full:efficient ratios during training by monitoring gradient influence profiles and retrieval-head maturity, maximizing retrieval pressure early and efficiency later.
- Products: “Window Curriculum” trainers that automatically adjust windows/ratios based on LongPPL and diagnostic triggers.
- Dependencies/assumptions: reliable online diagnostics at large scale; stability across data distributions.
- Full-attention–centric architectural innovation (sectors: software/AI, hardware co-design)
- Design new positional encoding variants or attention parameterizations that further accelerate retrieval-head formation beyond NoPE, potentially co-designed with memory/compute-efficient kernels.
- Products: next-gen hybrid blocks where efficient modules explicitly serve as optimization priors for full-attn; kernel libraries optimized for mixed full-attn density.
- Dependencies/assumptions: empirical validation at multi-billion to trillion parameter scales; integration with specialized hardware (e.g., attention-friendly accelerators).
- Memory routing and hybrid systems with external memory (sectors: agents, retrieval-augmented systems)
- Use the insight that full attention is the primary long-range retriever to design systems where efficient modules handle local context while full-attn routes to external memory/RAG stores for distant information.
- Workflows: training curricula where local dependencies are left to SWA/mixers and far dependencies are enforced via retrieval-grounded objectives.
- Dependencies/assumptions: stable training with retrieval supervision; robust memory indexing and latency control.
- Multimodal and long-horizon agent transfer (sectors: robotics, multimodal AI, enterprise agents)
- Extend the optimization-prior perspective to video, audio, and action sequences (e.g., long-horizon planning), shaping when and how global attention learns cross-episode retrieval.
- Products: multimodal hybrids where full-attn layers are targeted for long-range cross-frame/event linking; scheduler policies for window sizes in temporal mixers.
- Dependencies/assumptions: modality-specific gradient influence may differ; requires new diagnostics analogous to retrieval-head tracing for non-text modalities.
- Standards and regulatory frameworks for long-context claims (sectors: policy, standards bodies)
- Establish continuous metrics (LongPPL-like) and RF-restriction ablations as standardized disclosures for long-context capability claims in model cards.
- Dependencies/assumptions: consensus among industry and academic stakeholders; reproducible reference setups.
- Training at ultra-long contexts (e.g., 128K–1M tokens) with compute-optimal recipes (sectors: frontier labs, cloud providers)
- Develop scaling laws and curricula that ensure retrieval heads emerge rapidly even as context scales; combine NoPE-like advances with novel sparse/full-attn scheduling and memory management.
- Dependencies/assumptions: new datasets with meaningful ultra-long dependencies; kernel and memory innovations to sustain efficiency.
- Automated “long-context readiness” governance in LLMOps (sectors: platform providers, enterprise IT)
- Implement governance checks that gate releases on meeting LongPPL and retrieval maturity thresholds; auto-generate model-card sections with longitudinal diagnostics and ablations.
- Dependencies/assumptions: integration with CI/CD for model training; organizational adoption of readiness criteria.
- Cross-domain generalization studies and data curation (sectors: academia, industry research)
- Curate pretraining corpora to increase meaningful >512–2048-token dependencies early in training, reinforcing retrieval-head formation; study transfer to specialized domains.
- Dependencies/assumptions: data availability and privacy constraints; careful balance to avoid overfitting long-range patterns.
Each application above draws on the paper’s core insight: efficient attention’s primary value in hybrids is to shape the optimization trajectory that teaches full attention to retrieve over long ranges. Practical success depends on choosing window sizes, layer ratios, and positional encodings that maximize this pressure early, then capitalizing on efficiency once retrieval is established.
Glossary
- Attention entropy: The entropy of an attention distribution used as a measure of retrieval sharpness. "the normalized attention entropy when retrieving the needle token in the NIAH task:"
- Delta rule: A write-update mechanism that erases existing content associated with a key before writing a new association. "Here, the delta-rule term removes the existing content associated with before writing the new association ."
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, used here to measure parameter distances. " denotes the Frobenius norm"
- Full attention: Standard softmax attention over all previous tokens, computationally expensive at long lengths. "standard softmax attention, which we refer to as full attention, is costly at long sequence lengths"
- Full-to-Efficient Layer Ratio: The proportion between full-attention and efficient-attention layers within a hybrid model. "Full-to-Efficient Layer Ratio"
- Gated DeltaNet (GDN): A recurrent sequence mixer that uses data-dependent decay and update strengths with a delta-rule write. "GDN further adds controlled forgetting through a data-dependent decay and a data-dependent update strength :"
- Gradient influence: A diagnostic measuring how sensitive the prediction logit is to tokens at different distances. "we use Llama-3.1-8B to measure the gradient influence "
- Head-wise mixing: A hybrid design that mixes full and efficient attention across heads within a layer rather than across layers. "head-wise mixing"
- Hybrid attention architectures: Models that combine full attention with efficient-attention modules. "Hybrid Attention Architectures."
- Large-Window Laziness: The phenomenon where larger SWA windows delay the emergence of long-range retrieval in full-attention layers. "We term this phenomenon Large-Window Laziness."
- Layer-wise probing: A technique that trains simple classifiers on intermediate layer representations to localize where information emerges. "we conduct a layer-wise probing experiment"
- Lightning Attention: A linear attention variant with fixed per-head decay implementing a recurrent state update. "Lightning is a linear attention with a fixed per-head decay :"
- Logit: The pre-softmax scalar score for a token prediction. "s(x) denotes the logit used for prediction."
- Long-context capability: A model’s ability to handle and utilize information over extended input sequences. "how fast long-context capability emerges"
- Long-range retrieval: The mechanism by which attention accesses information far beyond local context windows. "long-range retrieval is mainly carried by full attention"
- LongPPL: A perplexity-style metric for long-context modeling quality, often used as . "We adopt as the fitting target for long-context capability."
- Mamba-2: A recurrent sequence mixer derived via structured state-space duality with data-dependent decay. "Following the structured state-space duality (SSD) form, Mamba-2 can be written as:"
- Needle-in-a-Haystack (NIAH): A diagnostic task for long-range retrieval where a “needle” token must be retrieved from long contexts. "Needle-in-a-Haystack (NIAH) classification task."
- NoPE: A positional-encoding choice that removes explicit position encodings in full-attention layers to aid long-range retrieval. "we apply NoPE to the full-attention layers of a small-window SWA hybrid."
- Optimization prior: An architectural inductive bias that shapes training dynamics rather than final representational capacity. "efficient attention does not directly determine long-context capability; instead, it acts as an optimization prior that shapes how full attention is trained."
- Positional encoding: A method to inject position information into attention layers. "positional encoding for the full-attention layers"
- Receptive field: The span of past tokens a mechanism can effectively access. "whose receptive field is in principle unbounded"
- Recurrent sequence mixers: Efficient-attention modules that compress history into a recurrent state instead of attending over all tokens. "recurrent sequence mixers that compress past history into a compact recurrent state"
- Retrieval heads: Specialized attention heads that perform long-range key-value lookup to recall relevant tokens. "retrieval heads form noticeably later in hybrid models equipped with larger SWA windows"
- RoPE: Rotary positional embeddings, a positional-encoding scheme contrasted with NoPE in this work. "RoPENoPE in full attention"
- Scaling law: A predictive relation characterizing performance as a function of model and data scale. "fit scaling laws for validation and "
- Separable power-law form: A scaling-law parameterization where performance decomposes into independent power laws of parameters and data. "using the separable power-law form as the fitting template:"
- Sliding-Window Attention (SWA): Attention restricted to a fixed-size local window around each token. "SWA restricts the summation range to a window of size :"
- Structured state-space duality (SSD): A theoretical connection enabling efficient sequence modeling via state-space forms. "Following the structured state-space duality (SSD) form,"
- Validation loss: The average negative log-likelihood on held-out data used to assess short-context modeling quality. "Validation loss is the standard target in language-model scaling laws"
Collections
Sign up for free to add this paper to one or more collections.