Multi-Mixer Models: Flexible Sequence Modeling with Shared Representations
Abstract: Softmax attention is the cornerstone of modern LLMs, but its memory scales linearly and compute quadratically with sequence length. Linear recurrent models, such as linear attention and state space models, have become widely studied as alternatives to attention due to their linear compute and constant memory. While these sub-quadratic token mixing methods, or mixers, achieve promising efficiency gains and competitive results on a wide range of benchmarks, current linear recurrent models still lag behind on tasks that require long-context retrieval or in-context learning. A growing body of work studies hybrid architectures that attempt to mitigate these trade-offs by statically interleaving or merging attention and recurrent blocks. In this work, we explore a new axis of developing hybrid models: across the token sequence. We propose Oryx, a hybrid model that can, throughout a sequence, flexibly switch between different mixers, for example quadratic attention for rich context utilization and linear recurrences for efficient generation. Oryx ties at least 90% of its parameters across mixers, enabling attention and recurrent modes to operate over shared internal representations. We validate our design with Mamba-2 and Gated DeltaNet variants, up to 1.4B models. Under fixed token budgets and a mixed-training strategy, Oryx achieves comparable or better performance than its single-mixer baselines. At the 1.4B scale, all instances of Oryx outperform their respective baselines by at least 0.7 percentage points on averaged language modeling tasks. On retrieval tasks, Oryx achieves performance comparable to the Transformer baseline even when processing only a tiny fraction (<10%) of the tokens in attention mode. These results suggest that attention and linear recurrent models can share internal representations, and motivate sequence-axis hybridization as a promising direction.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Multi-Mixer Models: Flexible Sequence Modeling with Shared Representations” (Oryx)
What is this paper about?
This paper introduces Oryx, a new kind of AI model that can read and write text using two different “reading styles,” and switch between them while processing a single piece of text. The goal is to get the best of both worlds: strong accuracy when the model needs to look back over many earlier words, and fast, memory‑friendly processing when it doesn’t.
The big idea in simple terms
Imagine you’re studying:
- Sometimes you carefully look through all your notes to find exactly what you need. That’s like “attention,” which is very thorough but gets slow and memory‑heavy when notes get long.
- Other times, you keep a small summary in your head and update it as you go. That’s like a “linear recurrent” method, which is faster and uses less memory but can be worse at looking up specific old details.
Oryx can do both—and even switch between them mid‑reading—while sharing most of the same knowledge underneath.
1) Overview of the paper’s purpose
The paper’s purpose is to design and test a “multi‑mixer” model that can:
- Use attention (great at retrieving details from long context, but expensive),
- Use linear recurrent updates (fast and light, but not as good at detailed retrieval),
- Share most of the same internal knowledge between the two,
- And switch between these modes across different parts of the input text.
This flexible switching aims to save time and memory without losing important capabilities.
2) Key questions the researchers asked
The authors focused on three main questions:
- Can one model share most of its inner “representations” (its learned knowledge) between attention and linear methods?
- Can it switch between these two modes mid‑text without getting confused or losing quality?
- Will this hybrid approach match or beat regular models on real tasks like language understanding and retrieval?
3) How the model works (methods), in everyday language
Here’s the core idea, step by step:
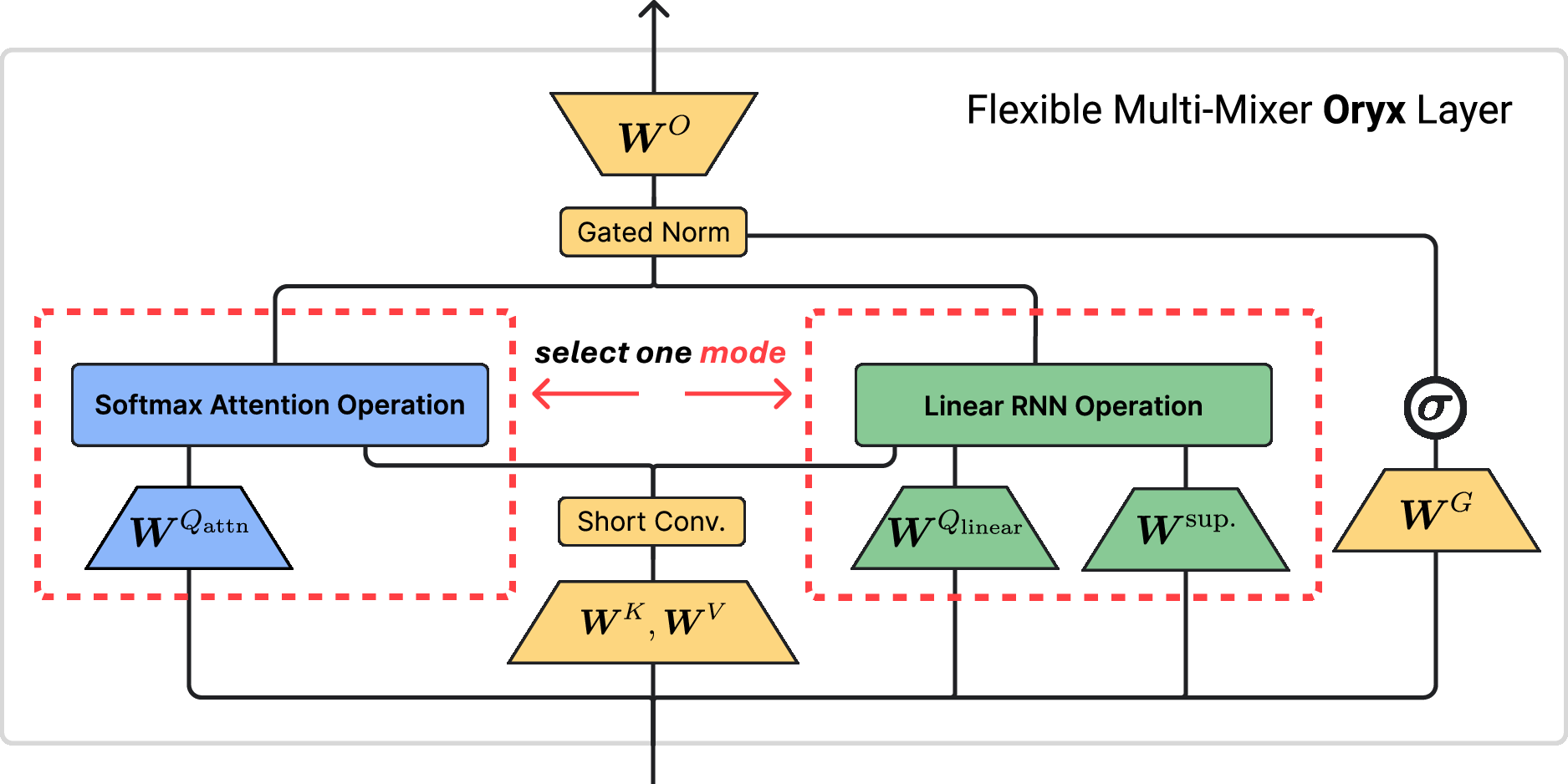
- Shared memory “ingredients”: Both attention and linear methods use three basic parts for each word:
- Keys and values: think of them as the memory you store from each word.
- Queries: the questions you ask the memory at each step.
- Oryx uses the same keys and values for both methods but gives each method its own queries. Why? Because the two methods “read” memory differently, so they benefit from different ways to ask questions.
- Keeping two states in sync: As the model reads, it updates both:
- An attention memory (a “KV cache” of all earlier keys and values), and
- A smaller, constantly updated summary state for the linear method.
- This way, if the model switches from one method to the other mid‑text, both are already up to date and can continue smoothly.
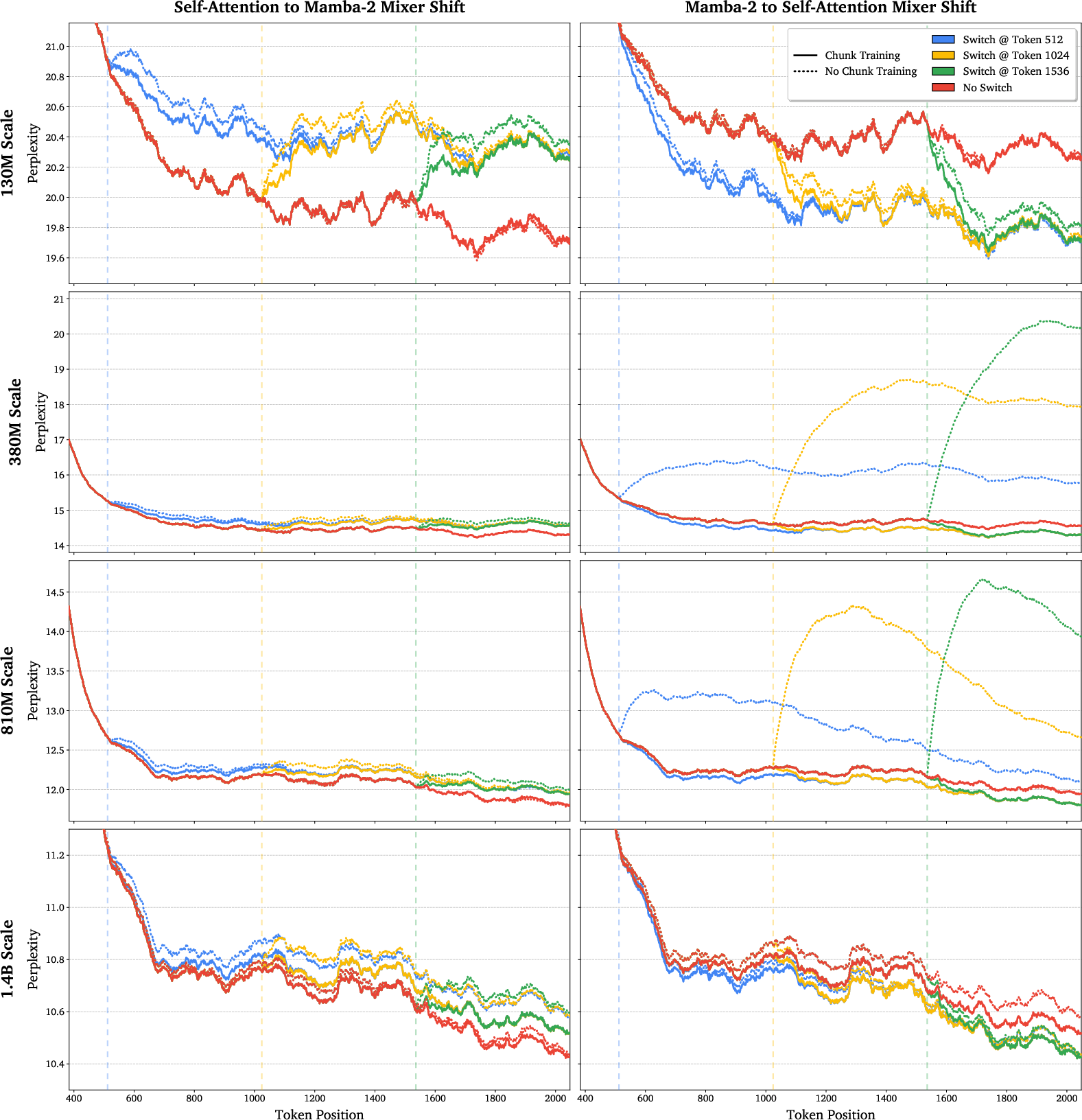
- Training with “chunks”: During training, each long text is divided into chunks (for example, 128 tokens). Each chunk is randomly assigned to be processed by attention or by the linear method. This teaches the model to handle switching modes during real use.
- Which linear methods? The team tried two:
- Mamba‑2 (a popular state‑space/linear recurrent model),
- Gated DeltaNet (a “fast‑weight” style model).
- Sharing most of the parameters: About 90% of the model’s parameters are shared between the two modes. This makes the two modes learn and use the same underlying knowledge, which helps smooth switching and saves training effort.
- Some helpful extras: The model uses components like short convolutions and gates (think of them as small helpers that organize and filter information) that are especially useful for the linear method, but they also don’t hurt attention.
Analogy: Think of Oryx as a student with one set of study notes (shared keys/values) but two different reading strategies (two types of queries). The student updates both strategies as they go, so switching is easy at any time.
4) Main findings and why they matter
Here are the main results in plain language:
- Strong performance with shared knowledge:
- Across many language understanding tests, Oryx performed as well as or better than standard “one‑method” models.
- At the 1.4B parameter size (a medium‑large model), both modes of Oryx beat their single‑method counterparts by about 0.7 percentage points on average (a meaningful improvement at this scale).
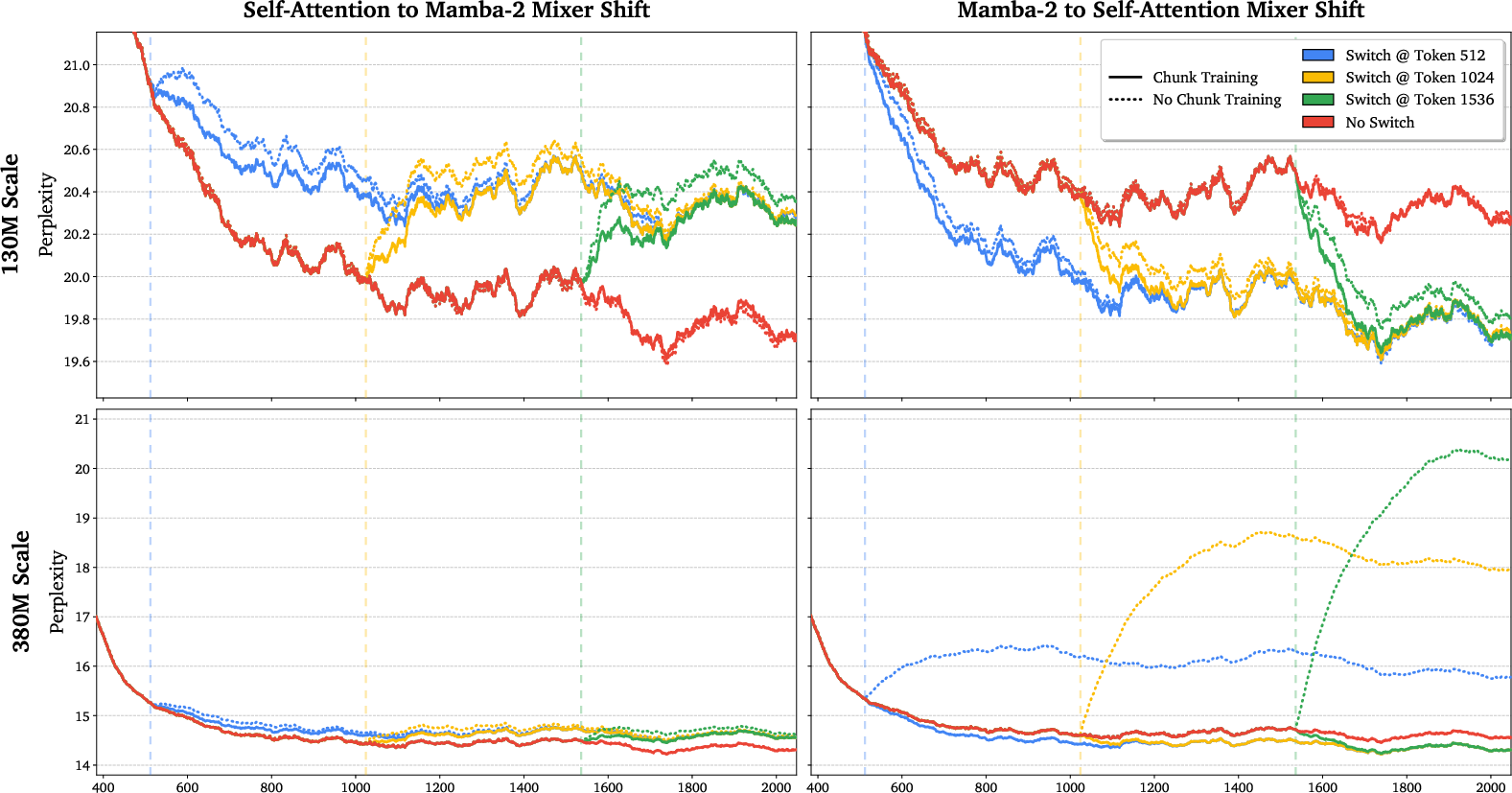
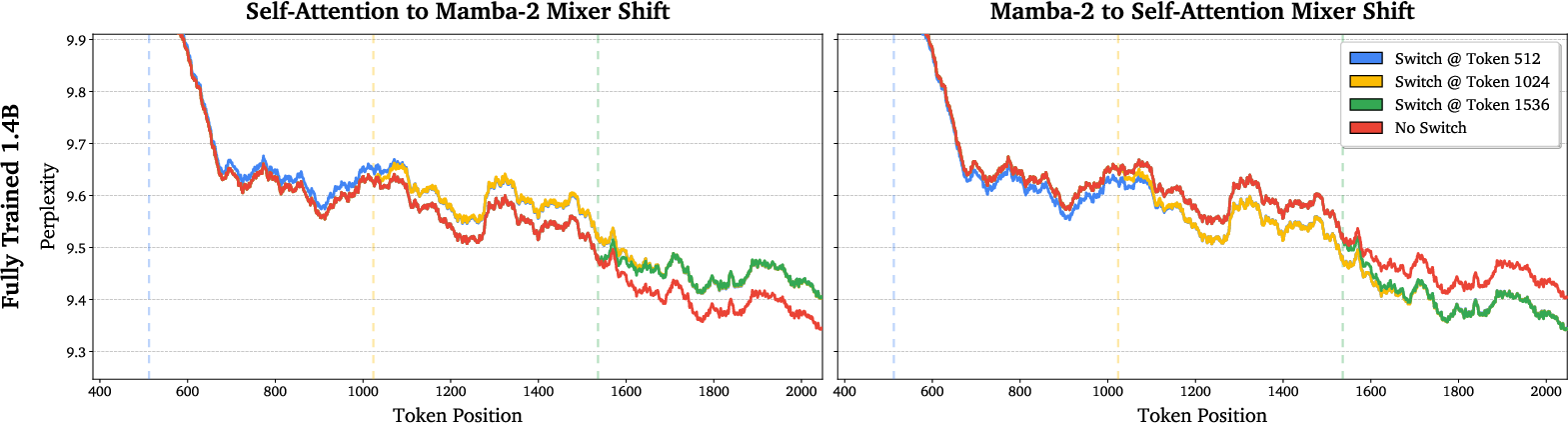
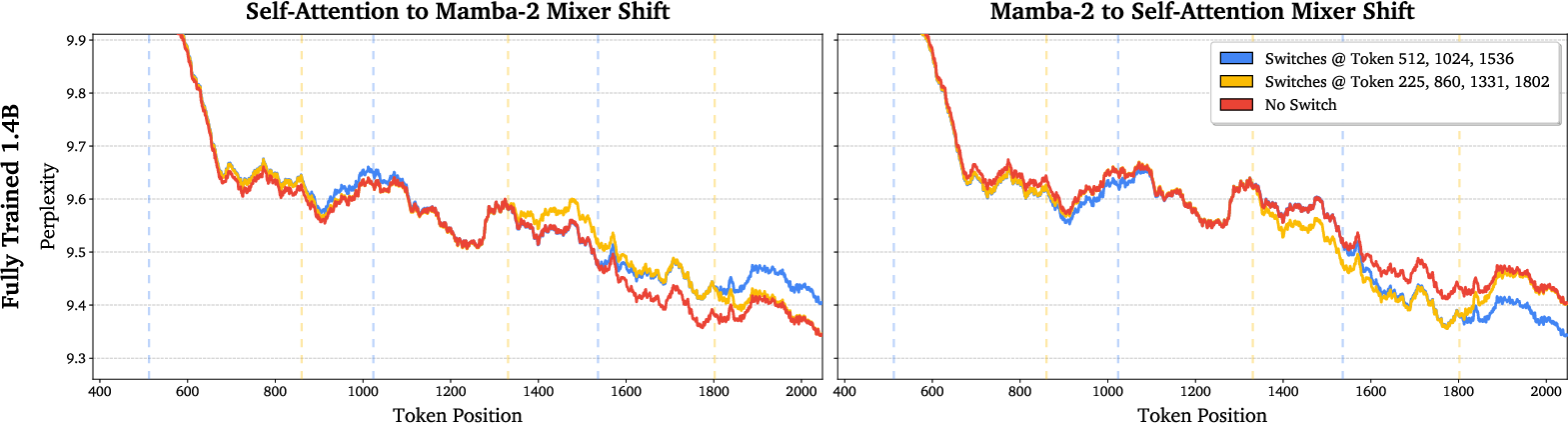
- Switching works smoothly:
- When the model switches from attention to linear, or from linear to attention, the quality quickly returns to what you’d expect if it had used that method the whole time. This means the two modes really do share compatible internal representations.
- Retrieval is strong—even with limited attention:
- On “find the needle in a haystack” style tests, Oryx could reach performance close to a Transformer (attention‑based model) even when it used attention for under 10% of the tokens. In other words, it saved a lot of compute but still found what it needed.
- When using a mixed setup (linear for the long context, attention for the final question), Oryx beat purely linear models by large margins on both real‑world and synthetic retrieval tasks:
- Real‑world tasks: around +8.6 to +13.5 percentage points,
- Synthetic “needle” tests: around +38.6 to +40.3 percentage points.
- Why this matters:
- Attention is powerful but gets very expensive as texts get longer.
- Linear methods are fast and memory‑light, but usually worse at detailed lookups.
- Oryx gives you a slider to trade off speed vs. retrieval power within the same model, on the fly.
5) What this could mean for the future
- Flexible, task‑aware computing: A model could read long background material with the fast linear method, then switch to attention for the final steps that require precise recall or summarization. This could make apps faster, cheaper, and still accurate.
- Dynamic routing: In the future, the model could learn when to switch modes by itself—choosing attention only when needed, saving compute most of the time.
- Better long‑context handling: As people ask models to read longer documents, being able to choose the right method at the right time becomes more important.
- Some trade‑offs remain: If you plan to switch modes during use, the model needs to keep both the attention memory and the linear state updated, which uses extra memory and compute. But for very long texts, attention’s memory dominates anyway, so the extra cost is often acceptable.
Summary in one sentence
Oryx shows that a single model can share most of its knowledge across two different sequence‑processing styles—attention and linear recurrence—and smoothly switch between them within the same text, delivering strong performance, better flexibility, and the potential for major efficiency gains.
Knowledge Gaps
Unresolved limitations and open questions
Below is a concise list of gaps, limitations, and open questions that remain after this work and that future research could concretely address:
- Generalization beyond two mixers:
- The approach is only validated with softmax attention + Mamba-2 and softmax attention + Gated DeltaNet; it remains unknown how well the shared K/V scheme and mode switching extend to other mixers (e.g., RetNet, RWKV, linear attention variants, S4/S5, sparse/flash attention, KV-Compressed attention).
- Scalability to larger models and longer contexts:
- Experiments stop at 1.4B parameters and 2K context; it is unclear how representation compatibility, retrieval quality, and switching stability behave at >7B models or at long contexts (e.g., 32K–1M), where linear modes would be most beneficial.
- Dynamic routing and learned policies:
- Mode assignment is static (chunked with a 1:3 attention:linear ratio, chunk size 128). There is no learned or adaptive router to decide when/where to switch based on content, compute budget, or latency constraints; policies for token-, layer-, or segment-level routing remain unexplored.
- Switching granularity and per-layer heterogeneity:
- All blocks share the same chunk assignment; the benefits and stability of per-layer, per-head, or per-token switching, and heterogeneous switching schedules across layers, are not studied.
- Robustness and failure modes of switching:
- The paper shows smooth perplexity after switches but does not systematically characterize failure cases (e.g., observed sensitivity in Transformer→Mamba-2 on synthetic NIAH) or provide diagnostics for when/why representation compatibility breaks under different switch directions, frequencies, or boundary alignments.
- Multiple switches and long-horizon stability:
- While multiple switches are shown qualitatively, there is no quantitative study of error accumulation, degradation under many switches, or the maximum safe number/frequency of switches over very long horizons.
- Memory and compute overheads in practice:
- The method requires maintaining and updating both KV cache and linear recurrent state at all steps when switching is enabled; the paper acknowledges overhead but does not provide systematic profiling (latency, throughput, memory footprint) or engineering strategies to mitigate it (e.g., lazy updates, on-demand reconstruction, compression, or hybrid KV/state sharing).
- Fair and detailed cost-to-quality comparisons:
- Results are reported under fixed token budgets and matched parameters, but there is no wall-clock or FLOPs-normalized comparison versus strong inter-layer or intra-layer hybrid baselines; the real trade-offs in training/inference efficiency versus quality remain uncertain.
- Head structure constraints:
- For weight sharing, linear mixers are constrained to attention’s MHA head structure; the performance trade-offs relative to their native structures (e.g., MVA for Mamba-2) are not quantified, and alternative mappings (e.g., adapters between head organizations) are unexplored.
- Representation sharing design space:
- Only K and V are shared while Q is mixer-specific; partial sharing, low-rank ties, or adapter-based sharing for Q (or selectively for K/V across depth) is not explored, nor is the minimal degree of sharing required for compatibility.
- Role of short convolutions and gating:
- Short convolution is applied only to shared K/V (not Q); the impact of convolving mixer-specific Q, alternative convolution kernels/receptive fields, or different gating placements/activations on switching and performance is not investigated.
- Theoretical understanding of compatibility:
- The paper conjectures that mixer-specific Q helps extract mode-specific information but provides no theoretical analysis or probing studies (e.g., representational similarity, attention maps vs. state dynamics) to explain why and when shared K/V suffice and Q must differ.
- Training regime sensitivity:
- Chunked mixed-mode training is crucial for switching, yet the sensitivity to chunk length, attention:linear ratio, curriculum over training, or alternative schedules (e.g., annealing, stochastic token-level mixing) is not systematically explored.
- In-context learning and few-shot behavior:
- Although the motivation includes ICL and retrieval, there is no targeted evaluation of few-shot or instruction-following scenarios to test whether switching improves ICL (e.g., with attention on exemplars and linear on filler).
- Retrieval boundary policies:
- Real-world retrieval experiments fix the context/prompt split to 97.5%/2.5%; there is no study of how different boundary choices, multiple question-answer turns, or mid-generation switches affect retrieval accuracy and consistency.
- Long-context retrieval and memory decay:
- Linear mixers often have decay dynamics; how these interact with shared K/V and switching for very long-range retrieval (beyond 2K) is untested (e.g., recall vs. recency bias when switches occur far from the needle).
- Compatibility with KV compression/quantization:
- The feasibility of combining KV compression/quantization with linear state maintenance under switching is unknown, as is reconstructing one state from the other to avoid dual-state storage.
- Broader task coverage:
- Evaluations focus on standard LM and retrieval; code generation, mathematical reasoning, multi-hop QA, tool use, multilingual tasks, and safety/robustness benchmarks are not assessed under switching.
- Hyperparameter and optimizer confounds:
- Oryx uses different peak learning rates (e.g., 10× vs baseline references); the sensitivity of results to optimizer settings, regularization, and training tokens per parameter is not disentangled from architectural gains.
- Integration with other hybridization paradigms:
- How sequence-axis switching interacts with inter-layer or intra-layer hybrids (or with MoE and sparse routers) is not evaluated; combined designs may yield better cost-quality trade-offs.
- Software/hardware implications:
- Kernel fusion, cache management, and scheduling for on-the-fly switching are not discussed; practical implementations on GPUs/TPUs and their impact on utilization and batching remain open engineering problems.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s findings now. Each item lists target sectors, likely tools/workflows that could emerge, and feasibility notes.
- Elastic-cost LLM inference with sequence-axis mixer scheduling
- Sectors: AI infrastructure, cloud platforms, MLOps
- Tools/workflows: Inference schedulers that prefill most tokens with linear mode and enable attention only on critical segments; integration into engines like vLLM/TensorRT-LLM to support dual state (KV cache + recurrent) and per-chunk mode flags; operator/kernels for shared K/V projections and mixer-specific Q
- Assumptions/dependencies: Requires Oryx-like models trained with chunked mixed-mode; memory overhead of keeping both states; head-structure alignment (MHA/GQA) in linear mixer; segmenting logic (heuristics) to keep attention fraction small (<10%) while sustaining quality
- Cost-optimized Retrieval-Augmented Generation (RAG)
- Sectors: Enterprise search, customer support, legal discovery, BI/analytics
- Tools/workflows: RAG pipelines that ingest/score large context in linear mode and switch to attention for question interpretation and generation; simple boundary annotation (Context vs Prompt) to control mixers; budget knobs for “attention fraction”
- Assumptions/dependencies: Effectiveness depends on context/prompt boundary detection and task retrieval hardness; validated up to 1.4B parameters; exact-match retrieval can be sensitive to switching direction and mixer (per paper)
- Long-context document QA and summarization at lower cost
- Sectors: Legal, healthcare (EHR summarization), finance (report analysis), public sector records
- Tools/workflows: Document chunkers that process bulk text with linear mode and apply attention for answer synthesis/section summaries; content-aware schedulers (e.g., headings/figures trigger attention)
- Assumptions/dependencies: Must maintain both states; ensure privacy/compliance for sensitive text; small attention windows may need tuning per domain
- Large-repo code assistants with efficient context handling
- Sectors: Software engineering, DevTools
- Tools/workflows: IDE extensions that read files/projects in linear mode and switch to attention for symbol queries, refactor plans, or cross-file resolution; batch prefill of codebase with linear mode
- Assumptions/dependencies: Requires robust cross-mode retrieval; repository-scale context ingestion workflows; integration in existing model servers
- Efficient chain-of-thought (CoT) and agent planning
- Sectors: Consumer assistants, enterprise copilots, education
- Tools/workflows: Generate long reasoning traces in linear mode; switch to attention for verification and final answer; prompt templates that explicitly segment “think” vs “answer”
- Assumptions/dependencies: Alignment/safety considerations for CoT; small attention windows must still capture key retrieval for correctness
- Streaming transcription and captioning with contextual corrections
- Sectors: Media, conferencing, accessibility
- Tools/workflows: Real-time ASR uses linear mode for running transcript; attention activates for disambiguation near speaker turns or ambiguous vocabulary
- Assumptions/dependencies: Low-latency kernels for rapid mode switches; domain heuristics for “when to attend”
- On-device or edge assistants under tight memory/latency budgets
- Sectors: Mobile, embedded/IoT
- Tools/workflows: Mostly-linear inference with occasional attention bursts; quantized shared K/V projections; memory managers that keep KV cache minimal and compress recurrent state
- Assumptions/dependencies: Efficient dual-state management on-device; optimized kernels for short-conv and gate components; task-specific schedules to preserve accuracy
- Academic experimentation on shared representations and switching behavior
- Sectors: Academia, industrial research
- Tools/workflows: Benchmarks for “attention-fraction vs quality”; ablation suites for tied K/V and mixer-specific Q; token-level perplexity probes pre/post switching; long-context retrieval stress tests
- Assumptions/dependencies: Availability of open Oryx-like checkpoints or reproducible code; consistent training (chunked mixed-mode) to maintain switchability
- Energy-aware deployments and budget-transparent SLAs
- Sectors: Government, nonprofits, regulated utilities
- Tools/workflows: Operator policies that cap attention fraction per SLA tier; dashboards reporting energy/compute saved by linear mode use
- Assumptions/dependencies: Governance buy-in; need for standardized metrics of “attention utilization” and service quality tradeoffs
Long-Term Applications
These opportunities will require further research, scaling, or engineering before they are broadly deployable.
- Learned token/segment routers for dynamic mode selection
- Sectors: AI infrastructure, platform providers
- Tools/workflows: RL- or differentiable-routing policies that select attention vs linear per token/chunk using FLOPs/latency as reward; uncertainty- or retrieval-signal-based gating
- Assumptions/dependencies: Additional training objectives; robust credit assignment; safety/accuracy monitoring to avoid silent regressions
- Hardware and runtime co-design for dual-state models
- Sectors: Semiconductors, cloud accelerators
- Tools/workflows: Memory hierarchies optimized for concurrent KV cache and SSM state; fused kernels for shared K/V projections + short conv + gating; scheduling primitives for mode transitions
- Assumptions/dependencies: Vendor support (cuDNN, ROCm, TensorRT-LLM) and standardized “mixer mode” op semantics; proven demand for mixed-mode workloads
- Multimodal sequence-axis hybridization
- Sectors: Vision (video), speech, robotics
- Tools/workflows: Video encoders that process most frames in linear mode and attend sparsely at keyframes; speech models with linear recurrent backbone and attention bursts for speaker changes; robotics policies that handle long sensor streams linearly and attend near critical events
- Assumptions/dependencies: Extending Oryx-like tying to modality-specific mixers; stability of short conv/gate inductive biases across modalities; benchmarks for high-variance event windows
- Large-scale long-context LLMs with standardized “mode schedule” APIs
- Sectors: Foundation model vendors, cloud providers
- Tools/workflows: 7B–70B models trained with chunked mixed-mode and exposed inference APIs that accept per-segment mode schedules; client libraries that auto-derive schedules from prompts/workflows
- Assumptions/dependencies: Demonstrated scaling benefits; standardization of head structures across mixers (MHA/GQA) and training recipes; ecosystem updates (tokenizers, routers)
- Privacy-preserving split computing
- Sectors: Healthcare, finance, government
- Tools/workflows: Sensitive context processed locally in linear mode; only minimal, non-sensitive spans receive cloud attention; cryptographic attestations of mode usage
- Assumptions/dependencies: Clear privacy guarantees and audits; switch schedules that don’t leak sensitive content indirectly; regulatory approval
- Workflow-level compute orchestration and SLO-governed attention budgets
- Sectors: MLOps, DevOps
- Tools/workflows: Orchestrators that assign attention budgets to steps (retrieval, synthesis, verification) based on SLOs; observability that ties quality metrics to mode usage
- Assumptions/dependencies: Robust monitoring and causality between attention fraction and task KPIs; operator guardrails and rollback mechanisms
- Knowledge management and continuous ingestion at scale
- Sectors: Enterprise content platforms
- Tools/workflows: Continuous corpora indexing in linear mode; attention invoked at query-time or during critical merges; energy-efficient background updates
- Assumptions/dependencies: Router policies tuned for heterogeneous document types; consistency/recall targets validated against fully-attentive baselines
- Domain-specialized decision support with event-aware attention
- Sectors: Healthcare (longitudinal EHR), finance (market streams), energy (grid telemetry)
- Tools/workflows: Linear processing of historical streams; attention windows near lab-result changes, earnings/volatility windows, or grid anomalies; interpretable reports showing where attention was used
- Assumptions/dependencies: High-stakes validation; clinician/analyst oversight; failure-mode detection for missed events if attention triggers fail
- State and memory footprint reduction for mixed-mode models
- Sectors: AI infrastructure, edge devices
- Tools/workflows: KV cache compression, state distillation, or reversible attention; lazy or sparsified updates to non-active mixer state; learned state projection for compatibility
- Assumptions/dependencies: New algorithms to compress/approximate without accuracy loss; compatibility with switchability guarantees
- Standards and benchmarks for “attention fraction vs quality”
- Sectors: Standards bodies, policymakers, procurement
- Tools/workflows: Task suites measuring performance as a function of attention share; procurement specs that require reporting “attention utilization” and energy per token
- Assumptions/dependencies: Community consensus on metrics; reproducibility across model families and sizes
Cross-cutting assumptions and dependencies
- Chunked mixed-mode training is key to reliable switching; sequence-level mixed training can impair switchability in some directions.
- Maintaining both KV cache and recurrent state during inference increases memory/compute; savings depend on keeping attention fraction low and on efficient kernels.
- Head-structure compatibility (e.g., using MHA-style heads for both attention and linear mixers) was important in the paper; reusing MVA-style linear mixers may require architectural changes.
- Results are shown up to 1.4B parameters; behavior at larger scales is promising but still unverified.
- Domain deployment requires robust, ideally learned, routing policies; rule-based heuristics may not generalize across tasks or domains.
- Integration into existing serving stacks (e.g., vLLM, Ray Serve, Triton) needs new APIs for segment-level mode schedules and dual-state lifecycle management.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update in Adam. "and AdamW~\citep{loshchilov2019decoupledweightdecayregularization} with and $0.1$ weight decay was used as the optimizer."
- associative memory view: A perspective that unifies attention and linear models as maintaining key-value associations queried by keys. "they can all be unified under the associative memory view"
- bfloat16: A 16-bit floating-point format with a larger exponent range than FP16, often used for mixed-precision training. "Training used bfloat16 mixed precision"
- causal mask: A masking matrix that prevents a token from attending to future tokens. " is the causal mask."
- Chinchilla scaling law: A guideline relating optimal training tokens to model parameters. "Chinchilla scaling law token count ( tokens-to-parameter ratio)"
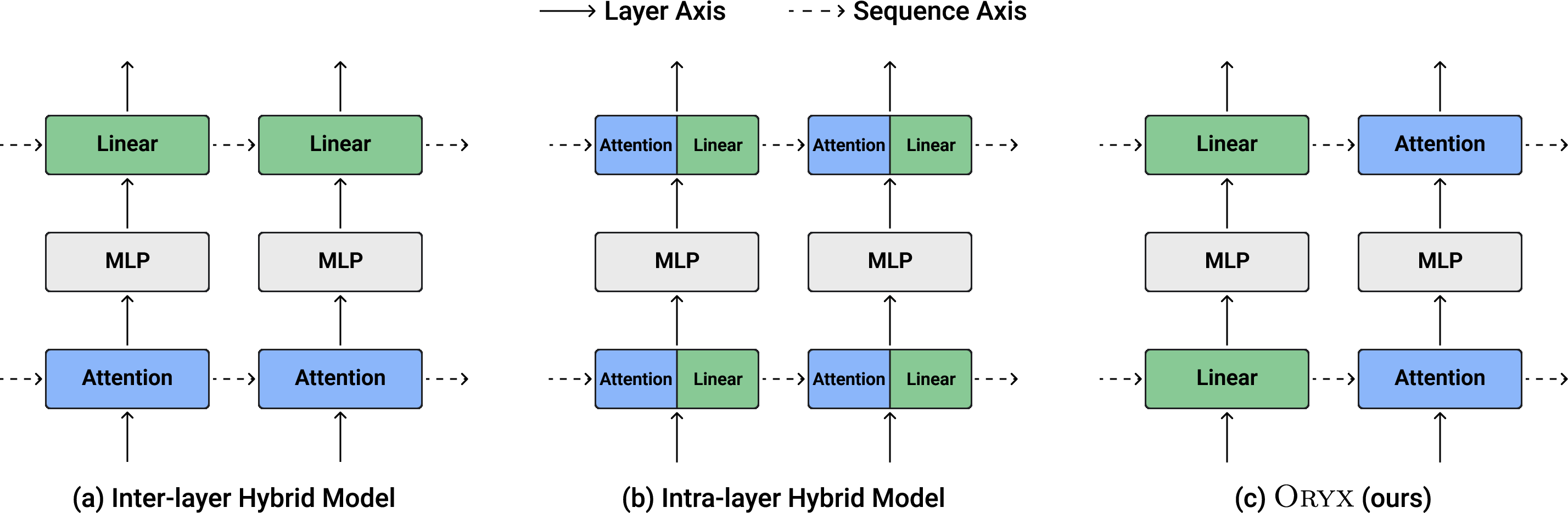
- chunked mixed-mode training: Training where each sequence is split into chunks and each chunk is randomly assigned a different mixer type. "we train Oryx with chunked mixed-mode training"
- cloze format: An evaluation style where a model fills in missing information in text. "real-world retrieval tasks in cloze format"
- cosine scheduler: A learning rate schedule that follows a cosine decay curve. "A cosine scheduler was used with of total steps allocated to warmup"
- discretization (parameters): Settings involved in converting or parameterizing continuous-time models for discrete computation. "We also ignore the discretization parameters and the tied nature of and in this section for clarity."
- fast-weight programmers: Models that rapidly write and use associative memories via fast-changing parameters. "Fast-weight programmers~\citep{schlag2021lineartransformerssecretlyfast, yang2025parallelizinglineartransformersdelta}"
- FLOPs: A measure of computational cost in floating point operations. "using RL to train routers that dynamically route tokens using FLOPs saved as the reward."
- Gated DeltaNet (GDN): A fast-weight linear recurrent model with a gated delta update rule for state updates. "Gated DeltaNet (GDN)~\citep{yang2025gateddeltanetworksimproving}"
- GatedRMSNorm: An RMS normalization variant modulated by a learned gate. "Y = \text{GatedRMSNorm}\left(O, \sigma(\bmXWG)\right) WO,"
- GPT-2 tokenizer: The subword tokenizer used by GPT-2 for text tokenization. "using the GPT-2 tokenizer~\citep{Radford2019LanguageMA}"
- grouped-query head (GQA): An attention head configuration where groups of queries share keys/values. "grouped-query head (GQA)"
- Hadamard product: Element-wise multiplication of matrices or vectors. "applied with a Hadamard product ()"
- in-context learning: Learning or task adaptation performed via examples in the prompt without parameter updates. "tasks that require long-context retrieval or in-context learning."
- key-value (KV) cache: Memory storing keys and values for past tokens used by attention at inference. "softmax attention maintains a key-value (KV) cache of all previous tokens"
- linear attention: Attention variants that compute attention with linear complexity in sequence length. "linear attention~\citep{katharopoulos2020transformersrnnsfastautoregressive,yang2025gateddeltanetworksimproving}"
- Linear Recurrent Neural Networks (RNNs): Sequence models with fixed-size states updated per token, enabling linear-time processing. "Linear Recurrent Neural Networks (RNNs)."
- Mamba-2: A recent state-space model–based linear recurrent architecture with input-dependent decay. "Mamba-2~\citep{dao2024transformersssmsgeneralizedmodels}"
- mode switching: Changing the active sequence mixer (e.g., attention vs. linear) during processing. "mode switching capabilities"
- multi-head (MHA): An attention mechanism with multiple parallel heads to capture diverse relationships. "multi-head (MHA)"
- multi-value (MVA): A head structure (used by some linear models) with multiple value vectors per head. "multi-value (MVA) structure"
- needle-in-a-haystack (NIAH): Synthetic retrieval tests where a single relevant item must be found within long distractor text. "needle-in-a-haystack (NIAH) tests"
- outer-product: A matrix formed by multiplying a column vector by a row vector, used here to write key-value associations. "via an outer-product."
- positional encodings: Representations added to inputs to inject token position information. "We ignore positional encodings and other complementary components"
- prefill: The initial phase that processes context before token-by-token generation. "The models can flexibly change between mixers during prefill with little to no degradation in perplexity"
- readout: The mapping from internal state to output, often a linear projection. "The output is determined using a simple readout with the current query."
- rotary embeddings: A method of encoding relative positions by rotating query/key vectors in complex space. "Rotary embeddings, the short convolution, etc., are abstracted away in the class."
- RMSNorm: Root Mean Square Layer Normalization, a normalization technique without mean centering. "default RMSNorm outperforms grouped RMSNorm."
- short convolution: A lightweight convolution applied over nearby tokens to inject local inductive bias. "Oryx incorporates the short convolution, multiplicative gate, and pre-output projection normalization"
- SiLU: The Sigmoid Linear Unit activation function. "usually SiLU~\citep{hendrycks2023gaussianerrorlinearunits}"
- state-space models (SSMs): Sequence models based on state-space formulations enabling efficient parallel inference/training. "state-space models (SSMs)~\citep{dao2024transformersssmsgeneralizedmodels}"
- structured transition matrix: The matrix that governs how a recurrent state evolves over time in linear RNNs. "a structured transition matrix "
- SwiGLU MLPs: MLP layers using the SwiGLU activation, commonly interleaved with mixers in modern LMs. "interleaved SwiGLU MLPs."
- Transformer++: An enhanced Transformer configuration used in modern LLM training recipes. "Our model follows the Transformer++ setup"
- warmup: An initial training phase gradually increasing the learning rate. "with of total steps allocated to warmup"
- weight decay: A regularization term that penalizes large weights, often implemented in optimizers. "and $0.1$ weight decay was used as the optimizer."
Collections
Sign up for free to add this paper to one or more collections.