HydraHead: From Head-Level Functional Heterogeneity to Specialized Attention Hybridization
Abstract: The quadratic complexity of attention poses a critical bottleneck for long-context processing, spurring interest in hybrid attention designs. Most open-source hybrid models adopt a layer-wise strategy. Yet, prior work has noted the inherent difficulty of integrating Linear Attention (LA) with Full Attention (FA), suggesting that the design space of attention hybridization remains underexplored. To probe this space, we conduct interpretability analysis and observe that layers exhibit block-wise functional similarity, while individual heads within the same layer display distinct functional specialization despite sharing input features. This head-level heterogeneity suggests that the head dimension provides a natural and principled granularity for fusing heterogeneous attention signals. Building on this insight, we introduce HydraHead, a novel architecture that hybridizes FA and LA along the head axis. HydraHead features two key innovations: (1) an interpretability-driven selection strategy that identifies retrieval-critical heads and preserves FA only for them, and (2) a scale-normalized fusion module that reconciles the distributional gap between FA and LA head outputs. By leveraging a three-stage transfer pipeline with parameter reuse and distillation, we achieve high-performance hybrid models with minimal training overhead. Under a unified training setup, HydraHead outperforms other hybrid designs in long-context tasks while maintaining strong general reasoning. With interpretability-driven head selection, it matches a 3:1 layer-wise hybrid's long-context performance at a 7:1 LA-to-FA ratio. Crucially, trained on only 15B tokens, HydraHead achieves over 69% improvement over the baseline at 512K context length, approaching Qwen3.5, a leading model of comparable size with a native context length of 256K. This highlights the significant scaling potential of head-level hybridization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making LLMs better at handling very long texts without needing huge amounts of computer power. The authors introduce a new design called “HydraHead” that mixes two types of attention—Full Attention (FA) and Linear Attention (LA)—in a smarter way so the model can remember and retrieve important details across long documents more efficiently.
The big idea: mix attention at the “head” level, not just by layers
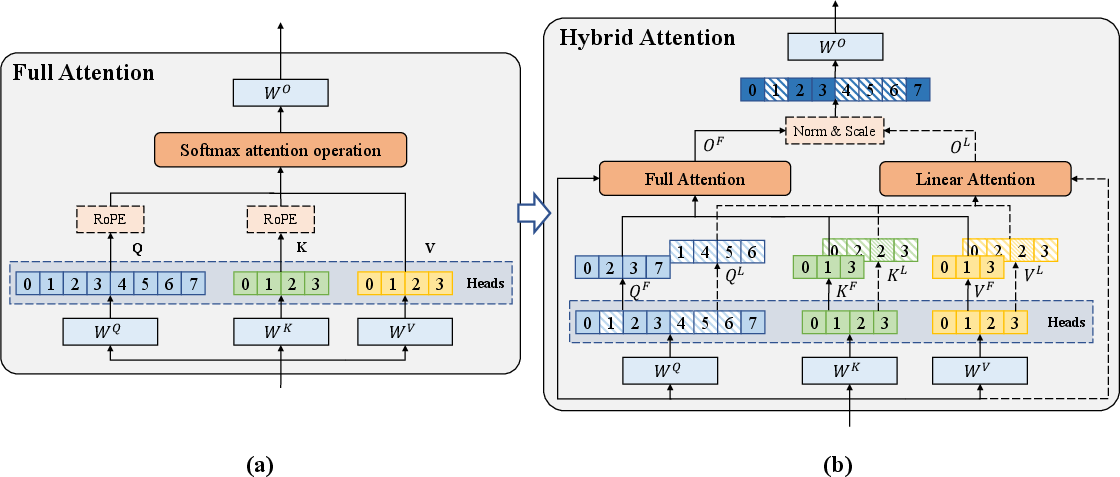
Transformers (the tech inside most LLMs) have layers, and each layer has multiple “heads.” You can think of each head as a tiny specialist reader that focuses on different patterns or relationships in the text. Many current models mix different kinds of attention by alternating whole layers (some layers use FA, others LA). This paper shows it’s better to decide at the head level—which heads keep FA (precise but expensive) and which switch to LA (fast but less precise). That way, you keep precise attention only where it’s truly needed.
What questions the researchers asked
The authors focused on simple but important questions:
- Can we build a long-context model that is both fast and accurate by mixing FA and LA at the head level instead of the layer level?
- Which heads are truly important for precise retrieval (like finding a key fact hidden deep in a long document)?
- How can we combine the outputs from FA heads and LA heads so they work well together instead of clashing?
- Can we convert an existing model into this hybrid with minimal extra training?
How they did it (methods explained simply)
First, some plain-language background:
- Full Attention (FA): Imagine every word in a document checking every other word. It’s very thorough (great for exact look-ups), but slow and costly when the document is huge.
- Linear Attention (LA): Instead of comparing everything to everything, it keeps a running “summary state” as it reads. It’s much faster and works well with very long texts, but it can miss fine details.
The authors’ approach has three main parts:
1) Find the “critical heads” using interpretability
- Think of each head as a team member with a special skill. The team works in layers.
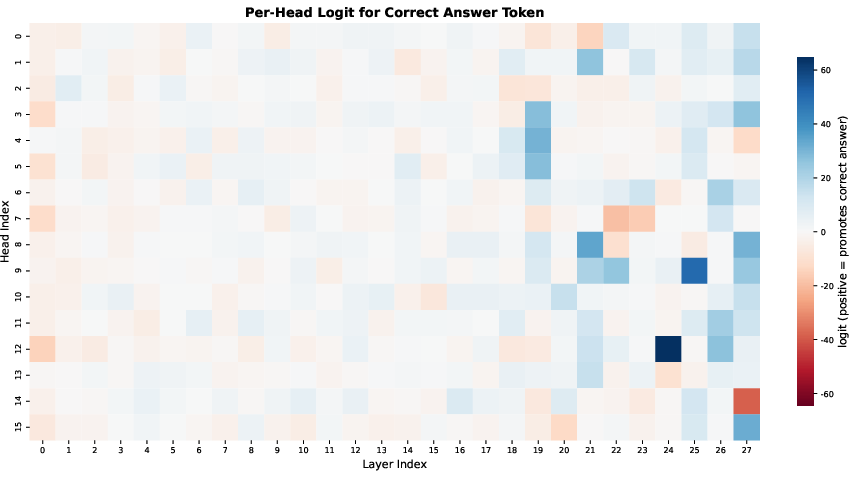
- The researchers used “causal tests” that are like flipping a switch on one head at a time to see how much the model’s answer changes. If turning off a head makes the model fail at retrieving the right token in a long text, that head is “critical.”
- They also traced which heads feed important information to other heads (like following the wires in a circuit).
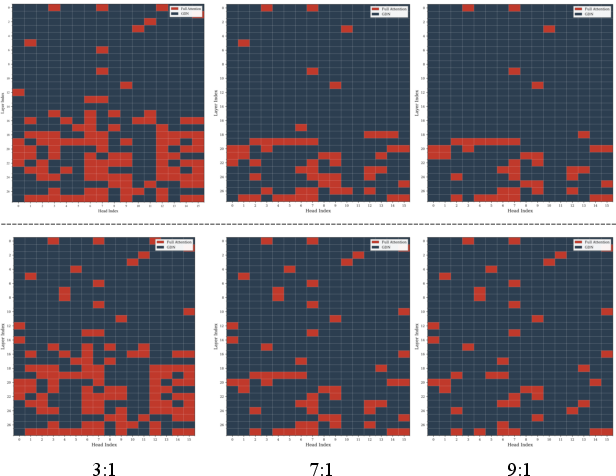
- Result: only a small number of heads are truly crucial for precise retrieval. Those get to keep FA. Most other heads can safely switch to LA.
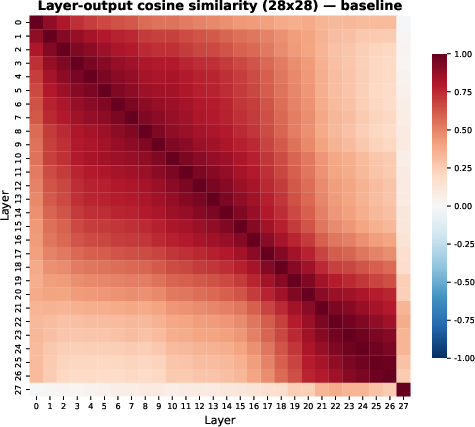
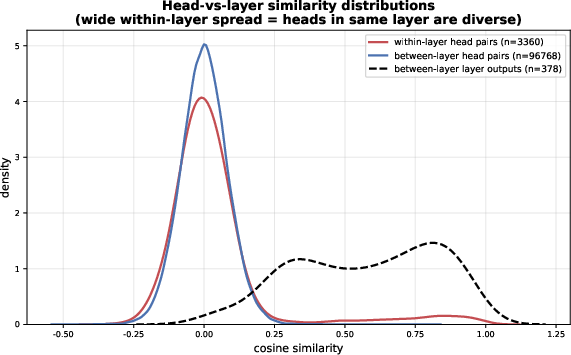
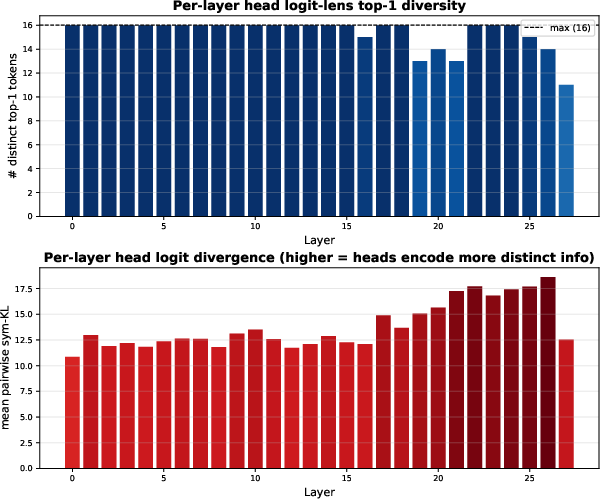
Why heads, not layers? Heads within the same layer behave very differently (some do a lot; others do very little), while neighboring layers tend to look more similar to each other. That makes heads a more natural place to mix FA and LA.
2) Mix FA and LA at the head level and make them play nice
- After choosing which heads keep FA and which switch to LA, the model runs both kinds in parallel within the same layers.
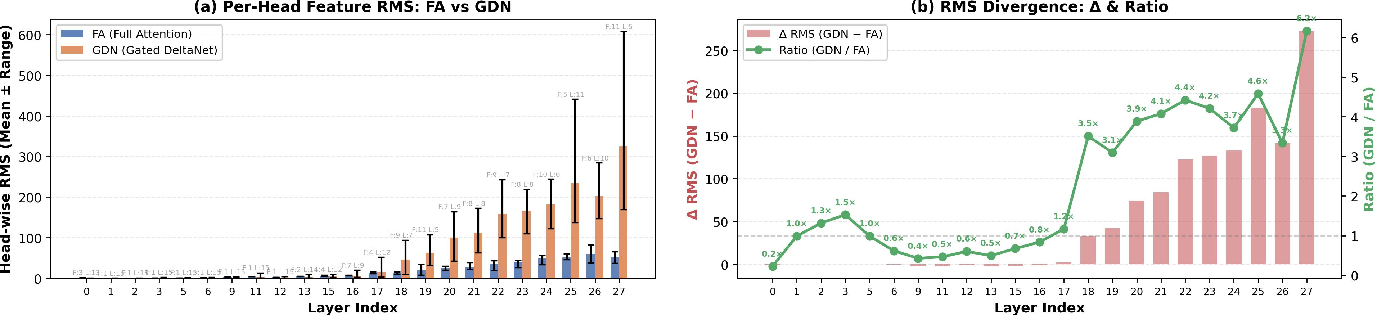
- Problem: FA and LA produce outputs with different “styles” (FA tends to be sharp and focused; LA tends to be smoother and more averaged). If you just stick them together, they can interfere.
- Solution: normalize each head’s output separately and give each head a learnable “volume knob” (a simple scale factor). This keeps the signals balanced so neither side overwhelms the other.
They used a modern LA variant called GDN (Gated DeltaNet). You can think of it as a smart running memory with a “forget” gate that keeps important info and tosses out the rest.
3) Convert a regular model into HydraHead with minimal training
Training a whole new model from scratch is expensive. Instead, they:
- Reuse the original model’s weights wherever possible.
- Align each layer’s outputs with the original model (so the hybrid behaves similarly).
- Distill knowledge from the original model (like a student learning from a teacher).
- Finally, fine-tune the hybrid for long texts.
This three-step pipeline helps the hybrid stabilize quickly without lots of data or compute.
What they found (main results and why they matter)
Here are the key takeaways:
- Better long-context performance: HydraHead beat other hybrid designs on tasks that require finding specific information in very long inputs, while still doing well on general reasoning tasks.
- Strong results with fewer “expensive” heads: By picking FA heads using interpretability, they matched the long-context performance of a layer-wise hybrid that used much more FA—achieving similar accuracy with a 7:1 LA-to-FA ratio (more LA, less FA).
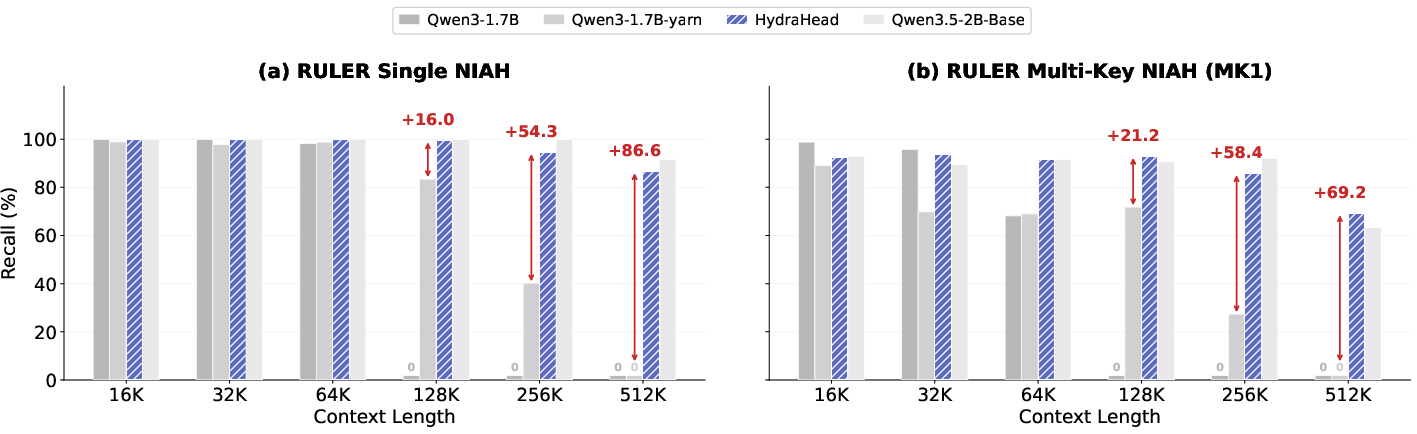
- Big gains with little training: With only 15 billion training tokens, HydraHead improved performance by over 69% on “Needle-in-a-Haystack” style tests at 512K tokens (that’s half a million tokens!), compared to the original baseline model.
- Competitive with leading models: It approaches the performance of Qwen3.5 (a strong, similar-sized model that natively supports long contexts), despite using far less training.
Why it matters: This shows you can scale LLMs to much longer texts efficiently without sacrificing accuracy, by being selective about where to keep FA.
What this could change (implications)
- Cheaper, faster long-context models: Processing books, long transcripts, codebases, or entire research papers becomes more affordable and practical.
- Better design principle: The work suggests a clear rule of thumb—treat attention heads (not layers) as the key unit for mixing precise and efficient attention.
- Smarter use of interpretability: Using “turn off and see what breaks” tests to guide architecture decisions can lead to better models with less guesswork.
- Broad applicability: Although they used GDN for LA, the head-level mixing idea and the balancing tricks (normalize + per-head scaling) could apply to other fast attention types too.
In short, HydraHead shows that understanding what each head actually does lets you keep precision exactly where it matters and speed up everything else—building models that read long texts accurately without burning through compute.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper, organized to guide future research.
- Head selection reproducibility and cost:
- How large is the calibration set for activation/path patching, what prompts are used, and how sensitive are head rankings to seed, dataset choice, and prompt design?
- What is the end-to-end computational overhead of the one-shot interpretability procedure relative to standard fine-tuning, and how does it scale with model size?
- Stability of static head assignment:
- Are the “retrieval-critical” heads stable across domains and tasks, or does the set drift after hybrid training and long-context fine-tuning?
- Would periodic re-estimation or curriculum-based reallocation of FA/LA heads during training outperform a fixed, one-shot selection?
- Generality across architectures and scales:
- Results are reported on Qwen3-1.7B; do the findings hold for larger models, encoder–decoder models, and architectures without GQA (e.g., MHA) or with different KV-sharing schemes?
- How does HydraHead interact with MoE layers, multimodal encoders, or multilingual settings?
- Interaction with Grouped-Query Attention (GQA):
- When FA and LA heads coexist in a layer, how is KV grouping handled if FA heads share KV (GQA) while LA heads maintain per-head recurrent states? Are there conflicts or performance regressions due to mixed sharing patterns?
- What are the implications of converting some heads to MHA-like KV (for LA) while others remain in GQA (for FA) on memory footprint and kernel efficiency?
- Efficiency accounting and hardware practicality:
- Precise latency, throughput, and memory breakdowns (training and inference) for FA:LA ratios (e.g., 7:1) are not provided; how do kernel launch overheads and cache management affect real-world speedups?
- Does head-wise heterogeneity impede fused-kernel optimization (e.g., FlashAttention-style kernels), and what implementation strategies mitigate this?
- Robustness and domain transfer:
- How robust is the head selection to distribution shift (e.g., from synthetic retrieval to code, legal, biomedical, or multilingual long documents)?
- Does the method degrade on tasks requiring exact token copying, structured reasoning (math proofs), or multi-document synthesis vs. single-document retrieval?
- Dynamic or input-adaptive routing:
- Could a learned router dynamically toggle FA vs. LA per head per sequence or per token span, improving efficiency and robustness over a static assignment?
- What are the stability and consistency costs of dynamic routing at very long context lengths?
- LA variant dependence:
- GDN is used as the LA branch; how do results change with other high-performing linear/SSM variants (e.g., Mamba2, HyenaDNA, DeltaNet2)? Is the fusion strategy agnostic to the LA kernel?
- Are there cases where LA’s state dimensionality or gating must be scaled up to match a given FA budget?
- Scale-normalized fusion design:
- The paper introduces per-head RMSNorm and learned scaling γ; what ablations quantify the contribution of each (RMSNorm alone, γ alone, alternative normalizers)?
- How does fusion affect gradient flow, representation anisotropy, and interference between FA and LA features over very long contexts? Any failure modes?
- Positional encoding choices:
- FA branch drops RoPE and uses a log-scale coefficient; LA branch adds RoPE. How sensitive are results to the exact scaling function and to RoPE frequency extrapolation settings?
- Do these asymmetric positional designs produce inconsistencies across heads that harm some sequence lengths or tasks?
- Training pipeline specifics and ablations:
- The three-stage transfer procedure references HALO-like steps but lacks precise loss formulations, teacher choice, distillation targets (logits, hidden states, attention maps), and data mixtures per stage.
- What is the minimal effective token budget for successful transfer? How do different schedules or temperatures in distillation impact long-context recall vs. general reasoning?
- Head-importance aggregation across capabilities:
- Equal weighting of capabilities (w_c) in head scoring may not reflect application priorities. How does a task-weighted or curriculum-weighted fusion affect performance trade-offs?
- Are heads important for general reasoning systematically different from long-context retrieval heads, and does joint optimization induce conflicts?
- Sensitivity to FA budget (K) and head distribution:
- What are the performance curves as K varies, and how do they compare to layer-wise hybrids at the same FLOP/memory budget?
- Are certain layers consistently better targets for FA heads than others, or is importance highly model/task-dependent?
- Circuit depth and path patching:
- The paper states that long-context retrieval converges in roughly two rounds of path patching; is this general, and how does circuit depth vary across tasks (e.g., multi-hop reasoning)?
- Can deeper path analyses uncover non-obvious sender–receiver chains that improve selection beyond top-K receivers?
- Long-context limits and failure modes:
- Performance is reported to 512K; what happens at 1M+ tokens under streaming and online settings (e.g., KV eviction, chunked decoding)? Are there stability thresholds for LA states?
- How does the method behave with repeated entities, adversarial distractors, or extreme duplication in long contexts?
- KV cache and memory management:
- With head-wise heterogeneity, can KV caching be partially pruned for LA heads while retaining FA caches for critical heads? What are the memory/time trade-offs?
- How does HydraHead interact with retrieval-augmented generation pipelines that frequently update context?
- Interaction with downstream components:
- Do MLP layers adapt to mixed attention distributions in a way that reduces complementarity over training? Would MLP re-initialization or gating improve synergy?
- Any effects on calibration, uncertainty estimation, or safety behaviors due to heterogeneous attention signals?
- Evaluation breadth and transparency:
- The paper highlights “meticulous optimization” of data and hyperparameters; reproducibility would benefit from explicit details on data composition, curricula, and training schedules.
- Beyond NIAH and a few reasoning benchmarks, broader evaluation (code, math, tool-use, multilingual) is needed to validate generality.
- Theory and principled guarantees:
- While interpretability motivates head-wise hybridization, there is no theoretical analysis of when head-level FA/LA mixing is provably beneficial or when it may fail.
- Can we characterize conditions (e.g., attention entropy, query-norm statistics) under which FA vs. LA heads are optimal, guiding principled selection without patching?
- Implementation and deployment concerns:
- How to package FA and LA heads in a production-ready kernel stack, including batching, quantization support, and mixed-precision stability?
- Are there interactions with speculative decoding, caching strategies, or test-time compute scaling that amplify or diminish the benefits of HydraHead?
Practical Applications
Immediate Applications
Below are actionable, real-world uses that can be deployed now by leveraging the paper’s head-wise hybrid attention (HydraHead), interpretability-driven head selection, and the three-stage transfer pipeline.
- Industry: Cost-effective long-context LLM inference for enterprise document processing
- Sectors: legal, finance, healthcare, government, enterprise search
- What: Convert existing FA-based LLMs into HydraHead-style hybrids to process 100K–512K token contexts at lower latency/memory (e.g., e-discovery across millions of tokens, 10-K analyses, contract and policy comparison, EHR timelines).
- Tools/workflows: “HydraHead conversion” pipeline that (i) runs head-importance profiling on a small calibration set, (ii) assigns FA to retrieval-critical heads and LA (e.g., GDN) to others, (iii) applies the three-stage parameter reuse + distillation + long-context finetune.
- Assumptions/dependencies: Access to model weights; ability to modify attention kernels per head (framework integration); availability of a small, task-relevant calibration set; FA/LA kernel support on deployment hardware; evaluation for domain-specific accuracy.
- Software engineering: Repository-scale code understanding and planning
- Sectors: software tools, DevEx, IDEs
- What: Enable assistants to ingest large codebases or long diffs with fewer chunking heuristics, preserving cross-file reasoning; use FA-heads for exact token recall (e.g., symbol references), LA-heads for global scanning.
- Tools/workflows: IDE plugin that routes attention per head, with configurable LA:FA ratios (e.g., 7:1) based on latency budgets; cached head-level diagnostics to tune FA allocation for code tasks.
- Assumptions/dependencies: Accurate head selection for code retrieval patterns; integrate with inference engines (e.g., vLLM) supporting per-head attention; ensure compatibility with code-specific tokenization and evaluation.
- Long meeting and customer-interaction summarization
- Sectors: contact centers, productivity, sales ops
- What: Summarize and query day-long calls/chats without aggressive chunking; FA-heads retain precise recall for decisions and commitments, LA-heads maintain broad context.
- Tools/workflows: Streaming inference with mixed per-head attention; pre-built “meeting summarizer” templates using the paper’s normalization and head-wise scaling to prevent degradation.
- Assumptions/dependencies: Inference platform must handle mixed per-head attention; ensure diarization metadata is either encoded or supported by prompt structure.
- Scientific and technical literature review at scale
- Sectors: R&D, pharma, academia
- What: Analyze hundreds of papers/patents within a single context window; FA-heads for exact recall of definitions/equations, LA-heads for thematic aggregation.
- Tools/workflows: Literature-review agent that uses HydraHead-converted base models; batch ingest + dedup + long-context QA pipelines.
- Assumptions/dependencies: Task-tuned calibration for head selection; benchmark against retrieval-heavy tasks to confirm precision.
- Compliance and risk monitoring across long logs
- Sectors: finance, healthcare, regulated industries
- What: Identify non-compliant language or anomalies in months of communications/logs using very long context with reduced compute.
- Tools/workflows: Log analysis service with head-wise hybrid LLM; policy templates for compliance terms; alerting pipeline with head-importance audits.
- Assumptions/dependencies: Validation against false negative risks; data governance for sensitive logs.
- Enterprise search/RAG reduction of chunking and re-retrieval overhead
- Sectors: enterprise software, knowledge management
- What: Use longer native contexts to reduce chunk granularity, simplifying RAG systems and improving coherence; LA-heads for scan, FA-heads for precise retrieval.
- Tools/workflows: “RAG-lite” architecture that passes larger doc windows and uses HydraHead to reduce KV cache burden.
- Assumptions/dependencies: Still requires FA KV caches for selected heads; storage and caching layers must be aware of mixed attention.
- Education and training content assistants
- Sectors: edtech
- What: Summarize, align, and quiz across multi-chapter textbooks/lecture notes without losing cross-chapter coherence.
- Tools/workflows: Course authoring assistants with head-wise hybrid inference; adjustable LA:FA per course/subject difficulty.
- Assumptions/dependencies: Calibration on education-specific tasks; monitoring for factual consistency.
- Healthcare longitudinal summarization and cohort report generation
- Sectors: healthcare IT
- What: Summarize patient histories over years of notes while preserving exact medication/timing details (FA heads) and overall clinical trajectory (LA heads).
- Tools/workflows: On-prem or VPC deployment of HydraHead models; templated clinical summarization modules.
- Assumptions/dependencies: HIPAA/PHI controls; clinical validation and guardrails; careful evaluation of position-encoding modifications for timeline fidelity.
- Model optimization and debugging via head-level interpretability
- Sectors: ML platforms, MLOps
- What: Use activation/path patching to identify “retrieval-critical” vs. “dispensable” heads, guiding compression, pruning, and targeted finetuning.
- Tools/workflows: “HeadScope” profiler: a lightweight head-scoring tool producing suggested FA head sets; integration into training dashboards.
- Assumptions/dependencies: Requires carefully designed counterfactual calibration tasks; reproducibility across data distributions.
- Platform engineering: Library and kernel support for per-head hybrid attention
- Sectors: AI infrastructure, cloud
- What: Release/consume PyTorch/Transformers modules with head-wise FA/LA, RMSNorm head fusion, learnable head scales, and modified RoPE settings.
- Tools/workflows: CUDA kernels and scheduler for mixed per-head attention; integration into vLLM, FlashAttention-like backends; KV-cache partitioning (FA-only).
- Assumptions/dependencies: Engineering effort for kernels; performance varies with hardware; QA for numerical stability with mixed precision/quantization.
Long-Term Applications
These opportunities require further research, scaling, engineering, or validation before widespread deployment.
- Dynamic, task-aware per-head routing at inference time
- Sectors: all inference-heavy domains (search, code, analytics)
- What: Replace static head assignments with dynamic gating based on token saliency or runtime signals; allocate FA only when a head is likely retrieval-critical for the current input.
- Tools/workflows: Learned or heuristic routers with stability constraints; token-level budget controllers; A/B testing across tasks.
- Assumptions/dependencies: Robustness under distribution shift; preventing oscillations; maintaining latency predictability.
- Native training of head-wise hybrids at larger scales
- Sectors: foundation model developers
- What: Pretrain large LLMs with head-wise hybrid attention from scratch, co-evolving FA/LA roles and head specialization.
- Tools/workflows: Curriculum and objective design for long-context; architecture search over FA head placement; multi-objective training (long-context + reasoning).
- Assumptions/dependencies: Compute budget; reproducibility across model sizes; stability of branch-specific positional encodings at scale.
- Multimodal long-context hybrids (text + audio/video)
- Sectors: media, healthcare (medical imaging reports + notes), assistive tech
- What: Extend head-wise hybridization to audio/video streams (LA for continuous streams, FA for precise cross-modal alignments).
- Tools/workflows: Cross-modal attention kernels with per-head FA/LA; fused normalization across modalities.
- Assumptions/dependencies: Modality-specific position encodings; synchronization and memory management; new benchmarks.
- Energy/sustainability standards and procurement guidelines for long-context AI
- Sectors: policy, public sector, ESG
- What: Codify efficiency gains from head-wise hybrids into procurement criteria and audit frameworks; promote per-head hybrids to reduce energy per token.
- Tools/workflows: Reporting templates (LA:FA ratio, KV-cache footprint, Joules/token); evaluation protocols for long-context accuracy/efficiency.
- Assumptions/dependencies: Consensus metrics; third-party auditing capacity; vendor transparency of internals.
- Safety and capability steering via head assignment
- Sectors: AI safety, compliance
- What: Assign LA to heads implicated in risky exact-recall behaviors (e.g., memorized secrets), dampening precision recall while maintaining context reasoning.
- Tools/workflows: Interpretability audits to identify sensitive circuits; gated FA escalation under policy conditions.
- Assumptions/dependencies: Reliability of head-level causal attributions; avoiding collateral capability loss; governance and red-teaming.
- Hybrid RAG that leverages longer context to reduce retrieval complexity
- Sectors: enterprise search, analytics
- What: Rebalance pipelines: use much larger native contexts with head-wise hybrids, shrinking retriever complexity and chunk heuristics; FA-heads provide exact anchoring.
- Tools/workflows: Co-design retrievers and models with LA:FA-aware prompts; fewer, larger chunks; latency/quality trade-off dashboards.
- Assumptions/dependencies: Document distribution assumptions; latency constraints; model must retain precise retrieval across long windows.
- Hardware co-design for per-head hybrid attention
- Sectors: semiconductors, cloud providers
- What: Architect accelerators that natively schedule FA and LA per head, optimizing KV-cache allocation and memory bandwidth.
- Tools/workflows: Compiler support for mixed-kernel graphs; memory managers that separate FA KV caches from LA states.
- Assumptions/dependencies: Vendor adoption; software stack alignment; quantization-aware mixed kernels.
- Compression and pruning synergies guided by head importance
- Sectors: model compression vendors, edge AI
- What: Combine head-level importance with structured pruning/low-rank adapters: prune inactive heads, convert “medium-importance” heads to LA, keep only critical FA heads.
- Tools/workflows: Joint search over pruning + FA/LA assignment with distillation; auto-tuning for device constraints.
- Assumptions/dependencies: Calibration set coverage; maintain robustness after pruning; device-specific validation.
- Personal knowledge management and on-device assistants with ultra-long context
- Sectors: consumer productivity
- What: Enable local assistants to reason over entire email archives, notes, and ebooks with lower memory footprints.
- Tools/workflows: Mobile/edge deployment with per-head LA-heavy configurations; privacy-preserving on-device conversion.
- Assumptions/dependencies: Mobile kernels for mixed attention; memory and power constraints; user privacy requirements.
- Domain-adaptive head selection catalogs
- Sectors: academia, model hubs
- What: Maintain catalogs of FA-head assignments tuned for domains (e.g., legal, coding, biomedical), shareable as configuration layers.
- Tools/workflows: Community-driven benchmarks and head maps; plug-and-play configs for open models.
- Assumptions/dependencies: License compatibility; generalization across model families; versioning and governance.
Notes on feasibility and dependencies across applications
- General dependencies
- Access to base-model weights and ability to modify attention internals.
- Framework support for per-head mixed attention, RMSNorm fusion, and head-wise scaling.
- Distillation/finetuning compute for the three-stage transfer pipeline.
- Small, representative calibration sets to drive head-importance estimation (activation/path patching).
- Performance caveats
- FA KV-cache is still required for FA heads; memory savings depend on the LA:FA ratio.
- Results demonstrated on Qwen3-1.7B; verify scaling to larger or different architectures.
- Branch-specific positional encoding tweaks (e.g., RoPE adjustments) may need task-specific validation.
- Stability with quantization/mixed precision and compatibility with inference backends must be tested.
If these dependencies are met, the paper’s approach can immediately lower the cost of long-context deployments while preserving general reasoning, and it opens clear R&D paths for dynamic routing, multimodal extensions, and hardware-accelerated per-head hybrids.
Glossary
- Activation patching: A causal intervention method that replaces a component’s activation to measure its necessity for a behavior. "Activation patching~\cite{heimersheim2024useinterpretactivationpatching} is a causal intervention technique for quantifying the contribution of individual model components to a target behavior."
- Attention sink: A phenomenon where attention mass gets trapped in uninformative tokens or positions. "This design not only boosts the model's representational capacity but also effectively alleviates the ``attention sink'' phenomenon commonly observed in high-precision attention heads~\cite{xiao2024efficientstreaminglanguagemodels}."
- Block-wise functional similarity: The observation that neighboring layers have smoothly varying, similar outputs forming coarse “blocks.” "we conduct interpretability analysis and observe that layers exhibit block-wise functional similarity"
- Causal intervention: An approach that changes internal activations to test whether a component is necessary for a behavior. "Activation patching~\cite{heimersheim2024useinterpretactivationpatching} is a causal intervention technique for quantifying the contribution of individual model components to a target behavior."
- Counterfactual: An alternative input or answer used to flip the model’s target output while keeping other factors similar. "with a randomly generated counterfactual of the same type and token length"
- Delta rule: A learning/update rule treating key–value state updates as gradient-like adjustments to an associative memory. "updated via the delta rule for precise credit assignment"
- Distillation: Transferring knowledge from a teacher model to a student model, often to a different architecture. "The prohibitive cost of pre-training hybrid architectures from scratch catalyzes a surge in cross-architecture distillation methods, aiming to transfer the reasoning capabilities of pre-trained Transformers into more efficient counterparts."
- Expressivity collapse: A degradation where a model class (e.g., linear attention) struggles to match the precision of full attention. "they frequently suffer from ``expressivity collapse,'' struggling to maintain the high-precision retrieval required for sophisticated reasoning tasks."
- Fast-weight memory: A perspective where attention (or linear analogs) acts as an associative memory updated rapidly with input. "A complementary perspective views linear attention through the lens of fast-weight memory~\cite{katharopoulos2020transformersrnnsfastautoregressive}"
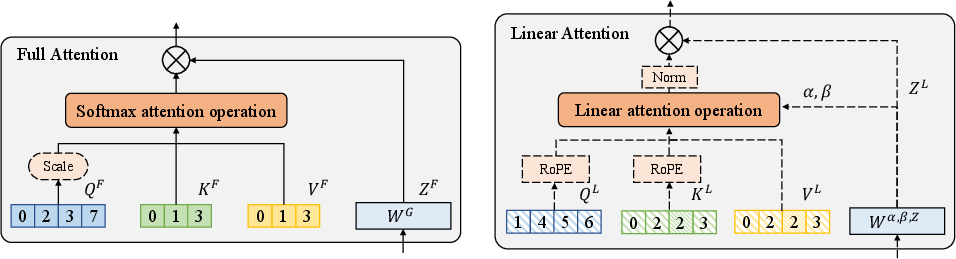
- Full Attention (FA): Standard softmax attention with quadratic time/space complexity enabling precise token-to-token interaction. "yet the quadratic complexity of standard Full Attention (FA) remains a rigid computational barrier."
- Gated attention: An attention variant augmented with gating to modulate contribution or stability. "motivated by gated attention~\cite{qiu2025gatedattentionlargelanguage}, we introduce an auxiliary gate branch within the FA module."
- Gated DeltaNet (GDN): A linear attention mechanism with gated, delta-rule-inspired state updates for stable long-context processing. "GDN interprets the state update as online gradient descent on a reconstruction loss"
- Grouped-Query Attention (GQA): An attention scheme where multiple query heads share fewer key–value heads to save memory and computation. "Modern LLMs predominantly adopt Grouped-Query Attention (GQA) to balance inference efficiency and modeling capacity."
- Head-level heterogeneity: The idea that different attention heads specialize in distinct functions even within the same layer. "This head-level heterogeneity suggests that the head dimension provides a natural and principled granularity for fusing heterogeneous attention signals."
- Head-wise Hybrid Attention: A design that assigns different attention mechanisms (e.g., FA or LA) per head within the same layer. "To harness the complementary strengths of both mechanisms, we propose a Head-wise Hybrid Attention mechanism in Figure~\ref{fig:framework}."
- Head-wise scale-normalized fusion: A fusion scheme that normalizes and scales per-head outputs to reconcile distributional differences between FA and LA. "we introduce a head-wise scale-normalized fusion to mitigate interference when these heterogeneous attention signals are mixed."
- HydraHead: The proposed architecture that hybridizes FA and LA along the head dimension with interpretability-driven selection and fusion. "we introduce HydraHead, a novel architecture that hybridizes FA and LA along the head axis."
- Kernel-based approximations: Methods that approximate softmax attention with kernel tricks to reduce complexity. "or kernel-based approximations~\cite{schlag2021lineartransformerssecretlyfast,yang2025gated,kimiteam2025kimilinearexpressiveefficient,hatamizadeh2026gateddeltanet2decouplingerase}"
- KV cache: Stored key–value tensors during autoregressive inference to avoid recomputation across time steps. "necessitating the retention of full KV caches and thus undermining memory efficiency during inference."
- Layer-wise Hybridization: Mixing attention mechanisms by alternating them across layers. "Layer-wise Hybridization."
- Linear Attention (LA): Attention variants with O(T) complexity that replace explicit pairwise interactions with recurrent state updates or kernels. "Linear Attention (LA) paradigms—often rooted in State Space Models (SSMs)~\cite{mamba,mamba2,lahoti2026mamba3improvedsequencemodeling} or kernel-based approximations~\cite{schlag2021lineartransformerssecretlyfast,yang2025gated,kimiteam2025kimilinearexpressiveefficient,hatamizadeh2026gateddeltanet2decouplingerase}—offer linear-time complexity"
- Logit difference: A scalar metric measuring the margin between correct and counterfactual token logits for attribution. "measured by a scalar readout such as the logit difference"
- Logit lens: A diagnostic that projects intermediate activations to logits to analyze what representations encode. "Observational diagnostics such as logit lens projections (Figure~\ref{fig:comm_headlogit})"
- Long-context retrieval: Tasks that require retrieving specific information from very long input sequences. "on a long-context retrieval task"
- Mechanistic interpretability: Analyzing internal circuits and components of models to explain behaviors causally and structurally. "Mechanistic interpretability provides the necessary lens"
- Multi-head attention: The mechanism of using multiple attention heads to capture diverse patterns within a layer. "Recognizing the functional heterogeneity of multi-head attention"
- Neural Architecture Search (NAS): Automated search techniques to find optimal architectural configurations. "utilize Neural Architecture Search (NAS) to discover optimal layer-wise configurations"
- NIAH: A long-context benchmark used to evaluate retrieval performance at extreme sequence lengths. "on NIAH tasks"
- Path patching: A causal method that measures contributions along specific computational paths between components. "path patching~\cite{wang2022interpretabilitywildcircuitindirect} enables finer-grained attribution"
- Residual stream: The running sum of component outputs passed through layers in a Transformer. "the residual stream (the running sum of all component outputs that accumulates across layers)"
- RMSNorm: A normalization that scales activations based on their root-mean-square, often used per feature. "We first apply RMSNorm independently to each head's output to unify their feature scales:"
- Rotary Position Embedding (RoPE): A positional encoding method that rotates queries and keys to inject relative position information. "we depart from the standard Rotary Position Embedding (RoPE) protocol"
- Sliding-window attention: An efficient attention variant that restricts attention to a local window. "or blending full with sliding-window attention"
- Softmax attention: The standard attention mechanism using softmax over dot products to compute token weights. "integrating linear with softmax attention"
- Sparse attention: Attention kernels that attend to a sparse subset of tokens to reduce complexity. "full- or sparse-attention variants"
- State Space Models (SSMs): Sequence models with latent states evolving via linear dynamical systems, often used for linear attention. "State Space Models (SSMs)"
- Token-wise Hybridization: Mixing attention mechanisms at the token level within a sequence. "Token-wise Hybridization."
- Transfer pipeline: A staged procedure to convert and train hybrids from pretrained models with minimal instability. "By leveraging a three-stage transfer pipeline with parameter reuse and distillation"
- Windowed attention: A local attention mechanism focusing on a fixed-size window for efficiency. "such as windowed attention or linear approximations"
Collections
Sign up for free to add this paper to one or more collections.