Revealing the Learning Dynamics of Long-Context Continual Pre-training
Abstract: Existing studies on Long-Context Continual Pre-training (LCCP) mainly focus on small-scale models and limited data regimes (tens of billions of tokens). We argue that directly migrating these small-scale settings to industrial-grade models risks insufficient adaptation and premature training termination. Furthermore, current evaluation methods rely heavily on downstream benchmarks (e.g., Needle-in-a-Haystack), which often fail to reflect the intrinsic convergence state and can lead to "deceptive saturation". In this paper, we present the first systematic investigation of LCCP learning dynamics using the industrial-grade Hunyuan-A13B (80B total parameters), tracking its evolution across a 200B-token training trajectory. Specifically, we propose a hierarchical framework to analyze LCCP dynamics across behavioral (supervised fine-tuning probing), probabilistic (perplexity), and mechanistic (attention patterns) levels. Our findings reveal: (1) Necessity of Massive Data Scaling: Training regimes of dozens of billions of tokens are insufficient for industrial-grade LLMs' LCCP (e.g., Hunyuan-A13B reaches saturation after training over 150B tokens). (2) Deceptive Saturation vs. Intrinsic Saturation: Traditional NIAH scores report "fake saturation" early, while our PPL-based analysis reveals continuous intrinsic improvements and correlates more strongly with downstream performance. (3) Mechanistic Monitoring for Training Stability: Retrieval heads act as efficient, low-resource training monitors, as their evolving attention scores reliably track LCCP progress and exhibit high correlation with SFT results. This work provides a comprehensive monitoring framework, evaluation system, and mechanistic interpretation for the LCCP of industrial-grade LLM.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper studies how large AI LLMs learn to handle very long pieces of text. Think of it like training a student to remember and use information from an entire book, not just a page. The authors focus on a special training step called “Long-Context Continual Pre-training” (LCCP), which teaches a model to pay attention over longer spans of text. They track how a big, production-scale model (Hunyuan-A13B) improves as it’s trained on a huge amount of data.
The main goal and questions
The researchers wanted to answer three simple questions:
- How much extra training data does a big model really need to get good at long texts?
- Are popular tests (like “Needle-in-a-Haystack”) giving a true picture of progress, or do they “say done” too early?
- What’s happening inside the model’s attention mechanism—do certain parts act like “finders” that locate and copy the right information from far away in the text?
How they studied it (in everyday terms)
They trained a very LLM to look further back in text (from a “memory window” of 32,000 tokens to 64,000 tokens). A “token” is a small chunk of text—like a word piece. Extending the “context window” is like giving the model a longer attention span.
To understand learning progress, they used a three-layer approach:
- Behavioral level: They gave the model a quick, light “tune-up” (called Supervised Fine-Tuning, or SFT) and checked how well it did on real tasks involving long documents. This is like giving a student a short practice quiz to see what they’ve learned.
- Probabilistic level: They measured “perplexity” (PPL), which you can think of as a “surprise meter.” Low PPL means the model is confident and likely correct; high PPL means it’s uncertain. They turned the classic “Needle-in-a-Haystack” test into a continuous PPL score to track small improvements, instead of just pass/fail.
- Mechanistic level: They looked inside the model’s attention layers to find “retrieval heads.” You can imagine these as tiny “search-and-copy specialists” that learn to find and copy the right bits from earlier in the text. They measured how many such heads appear and how strong they are.
Training details in simple terms:
- They used 200 billion tokens of extra training focused on long documents (like books, research papers, and code).
- They balanced data so the model didn’t forget general language skill (about 25% shorter texts, 75% long texts).
- They adjusted the model’s internal “position system” so it could keep track of where words are in much longer sequences.
What they found and why it matters
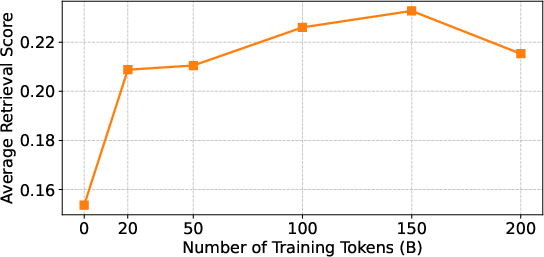
- Big models need a lot more data for long-context skill
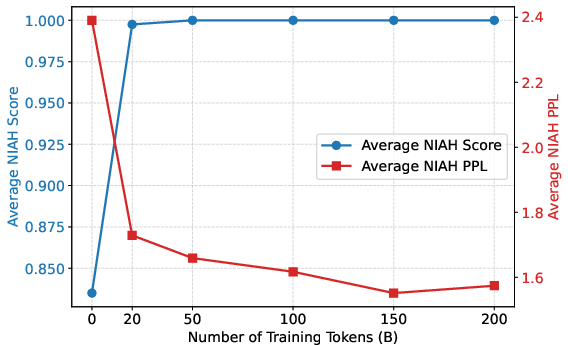
- Small studies often use tens of billions of tokens and report “done.” But this big model kept improving for much longer, only really stabilizing after about 150+ billion tokens.
- Translation: for truly large, production models, you need much more training to make long-text abilities solid.
- Some tests “say done” too early (“deceptive saturation”)
- The classic Needle-in-a-Haystack test hit perfect scores early and looked “finished.”
- But the continuous PPL version showed steady improvements well past that point, and PPL matched real task performance better.
- Translation: a pass/fail test can be fooled; measuring confidence (PPL) is a better way to see real progress.
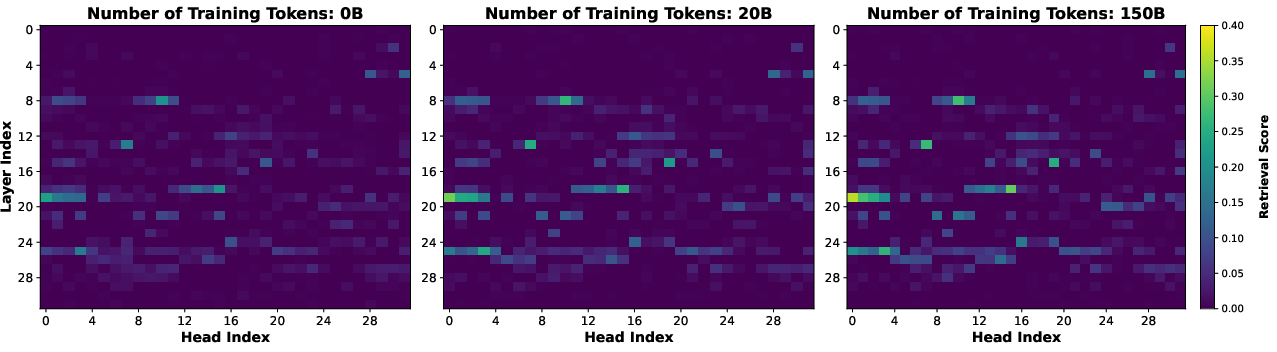
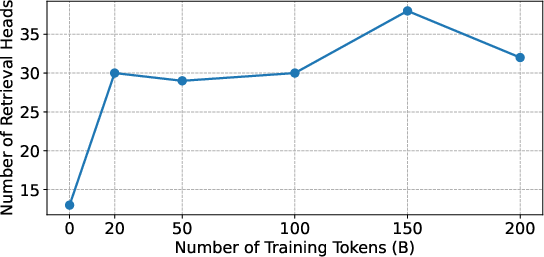
- You can monitor training by watching “retrieval heads”
- The number and strength of these “search-and-copy” attention heads grew as the model learned, and their scores matched how well the model performed after the light SFT.
- Translation: instead of running heavy, expensive tests all the time, you can peek inside the model and watch these heads as a quick, reliable progress meter.
Extra interesting notes
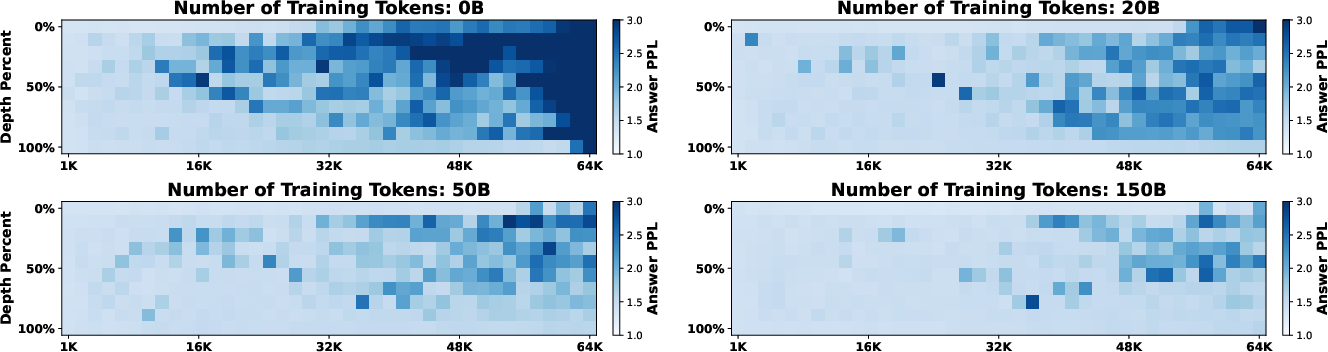
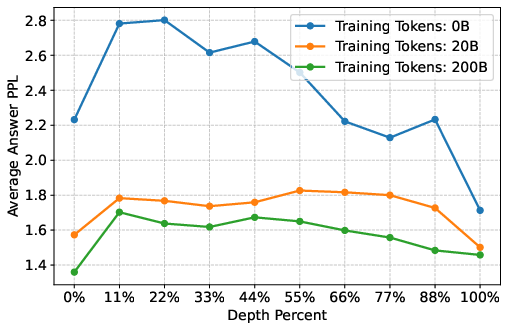
- “Lost in the middle” gets better: Models often struggle to pick up facts in the middle of very long texts. After more long-context training, the model got better at finding information no matter where it was, not just at the beginning or end.
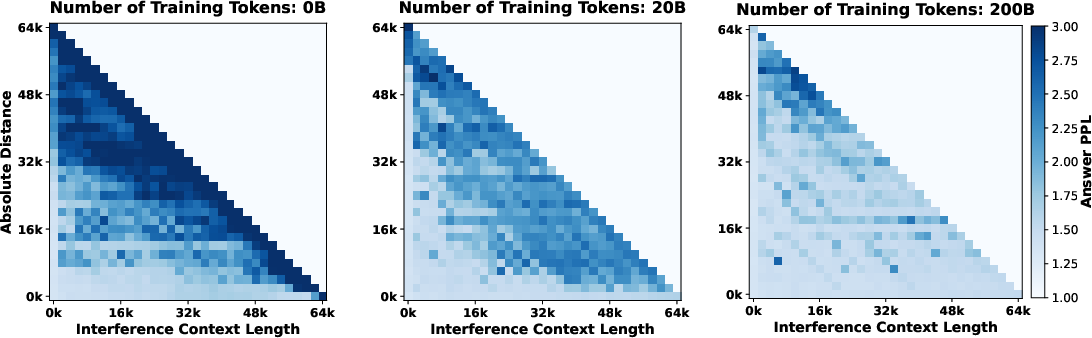
- More robust to distractions: When the text before the “important sentence” (the needle) got very long and noisy, the trained model stayed confident and accurate, meaning it learned to ignore distractions.
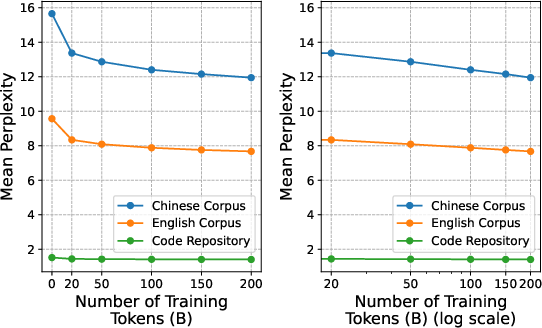
- Scaling pattern: Perplexity dropped roughly in a straight line when plotted against the log of training tokens, showing a predictable “more training → smaller improvements over time” pattern.
- Retrieval heads mostly “born early,” then strengthen: The specific heads that act as finders show up early in training and stay mostly the same; later training makes them stronger rather than replacing them.
Why this research matters
- For companies and labs building real-world AI, this study shows that upgrading a model’s long-text skills takes a lot more training than many academic tests suggest.
- It also offers better tools to measure progress (PPL-based tests and watching retrieval heads), making training more stable, efficient, and predictable.
- Ultimately, this helps build AI that can understand and reason over long documents—useful for reading research papers, legal records, big codebases, and more.
Limitations and what’s next
- They only went up to 64K context and 200B training tokens in this phase. They plan to:
- Push to even longer contexts (like 256K+).
- Do fuller post-training (more instruction tuning and reinforcement learning).
- Test different data mixes and settings.
- Try guiding or improving retrieval heads on purpose.
- Check if these findings hold for other big models from different families.
In short: Teaching a big AI to remember and use very long texts takes lots of training, simple pass/fail tests can be misleading, and watching the model’s internal “search specialists” is a smart way to track real learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
Scope and generalization
- Single-architecture focus: Results are shown only for Hunyuan-A13B (80B total MoE, 32/8 GQA, RoPE base=2M). Generalizability to dense models, different sizes (e.g., 7B/30B/70B), and other attention/head configurations is untested.
- Positional scaling methods: Only RoPE base scaling (500K→2M) is used; no comparison to alternative context-extension techniques (e.g., YaRN, NTK-aware scaling, ALiBi, linear/flash/λ-attention) or hybrids.
- Context-length extrapolation: Training and evaluation are capped at 64K. It remains unknown whether the observed “saturation after ~150B tokens,” PPL trends, and retrieval-head stability persist at 128K/256K+ or degrade beyond the training maximum.
- Cross-model reproducibility: No results across different codebases, tokenizers, or seeds; the stability of conclusions w.r.t. random initialization, training noise, or alternative optimizers is not evaluated.
Training data and recipe uncertainties
- Data-mixture ablations: The impact of the chosen 25% short / 75% long-context split and long-data source ratios (CC 36.3%, Books 28.6%, arXiv 24.0%, Code 10.8%) on convergence speed, short-context retention, and domain generalization is unquantified.
- Length curriculum and distribution: How the training length distribution (e.g., proportion of 32–48K vs. 48–64K tokens) affects scaling, stability, and retrieval ability is not studied.
- Language/domain balance: The long-context mix is skewed toward technical/structured sources; effects on narrative comprehension, multilingual performance, and general capabilities are not assessed.
- Hyperparameter sensitivity: The choice of constant LR (1.2e−5), batch size (16M tokens), and RoPE base=2M is not ablated. Effects of LR schedules, warmup, clipping, weight decay, dropout, or gradient noise on stability and convergence remain unknown.
- Catastrophic forgetting: Beyond internal PPLs, there is no systematic measurement of short-context capability retention (e.g., standard short-context benchmarks) before vs. after LCCP.
Evaluation and metric gaps
- External validity of NIAH-PPL: The proposed continuous NIAH (answer-token PPL) shows stronger correlations than binary scores, but its predictive power for real-world, instruction-following tasks (without SFT) and across diverse datasets is not fully established.
- Calibration vs. retrieval disentanglement: NIAH-PPL may conflate retrieval with calibration/confidence. No controls (e.g., length-normalized cross-entropy, entropy measures, or contrastive retrieval likelihood) are used to separate these factors.
- Benchmark breadth: Downstream evaluation relies on RULER, MRCR, and subsets of LongBio after lightweight SFT. Coverage of long-document QA, long-form reasoning, code-level long-context tasks, safety (e.g., LongSafetyBench), and RAG scenarios is limited.
- SFT-probe dependence: The SFT probe uses an internal 0.25B-token dataset with a specific schedule; the extent to which probe design masks or amplifies pretraining differences is untested (e.g., varying SFT data size, difficulty, or domains).
- Statistical robustness: Correlations are reported, but confidence intervals, effect sizes, and robustness to small sample sizes (few checkpoints) are not extensively documented; some correlations (e.g., LongBio) are not statistically significant.
- OOD generalization: No evaluation on contexts longer than the training maximum, adversarial distractors (near-duplicates/conflicts), paraphrased needles, or multi-needle/multi-hop retrieval settings.
Mechanistic interpretability and causality
- Causal tests on retrieval heads: Findings rely on correlations and rankings. There are no causal interventions (e.g., ablating, masking, or amplifying specific heads) to establish whether “retrieval heads” drive performance vs. being epiphenomena.
- Metric and threshold sensitivity: The retrieval score uses a max-attention criterion and a fixed threshold (r=0.1). Sensitivity to threshold choice, alternative definitions (e.g., attention mass aggregates, attention rollout), and noise is not analyzed.
- Head identity stability: Stability is shown across consecutive checkpoints in one run. Cross-seed stability, cross-model robustness, and sensitivity to architectural/hyperparameter changes are untested.
- MoE routing dynamics: No analysis of expert routing patterns during LCCP (e.g., entropy, expert specialization for long sequences) or their relationship to retrieval-head emergence and long-context performance.
Training dynamics, stability, and systems aspects
- Online training monitors: Although retrieval heads are proposed as monitors, there is no demonstration of their use for real-time training control (e.g., early stopping, curriculum pacing, or data scheduling).
- Attention entropy and instability: The paper does not measure training-time instability indicators (e.g., attention entropy collapse, loss spikes) or relate them to long-context adaptation and mechanistic metrics.
- Efficiency and throughput: System-level costs (memory footprint/KV cache growth, latency, throughput, parallelization overheads) for 64K LCCP are not reported; no comparison of strategies that trade compute vs. data for similar gains.
- Partial fine-tuning strategies: It remains unknown whether freezing subsets of layers/experts, head-specific regularization, or adapters could achieve similar long-context gains with lower compute.
Safety, alignment, and broader impacts
- Alignment interactions: How LCCP affects alignment stages (full-scale SFT/RLHF/RLAIF), instruction-following, and reasoning is untested; potential trade-offs or synergies remain unknown.
- Safety and factuality at long range: Although retrieval heads are linked to factuality in prior work, this study does not directly assess hallucination rates, conflict resolution across long contexts, or safety vulnerabilities (e.g., jailbreaks embedded deep in context).
Reproducibility and transparency
- Data/process reproducibility: Core training datasets are internal; deduplication, contamination checks, and exact sampling pipeline are not detailed, limiting replication and rigorous leakage audits.
- Code and tooling: There is no release of scripts or tools for computing NIAH-PPL, retrieval scores, or head identification, impeding independent verification and broader adoption.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s methods, metrics, and training recipes.
- Industrial LCCP monitoring dashboards for training progress and stability
- Sector: software/AI infrastructure; MLOps
- What: Integrate “continuous NIAH” (PPL over answer tokens) and retrieval-head metrics (count and average score) as low-cost, checkpoint-level monitors to track convergence and detect “deceptive saturation.”
- Tools/workflows:
- Add a continuous-NIAH PPL module to existing eval pipelines (e.g., OpenCompass, lm-eval-harness).
- Build a lightweight attention-head analyzer that ranks heads by retrieval score on a fixed NIAH-style probe set.
- Set quality gates (thresholds on PPL trend and retrieval-head stats) for early stopping or continuation.
- Assumptions/dependencies: Requires white-box access to attention weights for head analysis; a standardized NIAH-style probe set; modest extra compute for periodic evaluation.
- More faithful long-context evaluation for base models without SFT
- Sector: academia, industry R&D, vendor selection
- What: Replace binary NIAH scores with continuous PPL-based evaluation to avoid “fake saturation” and better predict downstream performance.
- Tools/workflows:
- Publish a “continuous NIAH” script that formats context–question–answer inputs and computes answer-token PPL.
- Add correlation reporting between PPL curves and small SFT probes on RULER/MRCR/LongBio.
- Assumptions/dependencies: Requires curated answer-known evaluation sets; evaluation fidelity depends on good coverage across lengths/depths.
- Practical training recipe adoption for 32K→64K context extension
- Sector: AI model engineering
- What: Apply the paper’s recipe for LCCP: adjust RoPE base frequency (e.g., 500K→2M), use a large global batch (e.g., ~16M tokens), constant small LR (~1.2e-5), and GQA with reduced KV heads.
- Tools/workflows:
- Training templates for DeepSpeed/ColossalAI with the specified settings.
- Sanity checks using retrieval-head heatmaps and PPL trendlines.
- Assumptions/dependencies: Architecture similarities to Hunyuan-A13B (MoE, GQA) help; stability may vary on dense models; KV cache/memory must handle 64K.
- Data and compute planning for long-context adaptation at industrial scale
- Sector: enterprise AI, finance (budgeting), sustainability
- What: Use the empirical finding that >150B LCCP tokens are needed to reach true saturation for an ~80B-parameter MoE to plan budgets and timelines.
- Tools/workflows:
- Project compute using 4×1023 FLOPs for ~200B-token runs; track energy/carbon in reporting tools.
- Adopt the 25% short + 75% long-document mixture with sources skewed to books/arXiv/code for robust long-range modeling.
- Assumptions/dependencies: Availability of high-quality long documents and rights to use them; results may shift with different architectures/sizes.
- Release-readiness “quality gates” for long-context features
- Sector: product/QA, enterprise LLM deployment
- What: Define acceptance thresholds using retrieval-head metrics (e.g., minimum number of retrieval heads and average score) and PPL slope improvements instead of relying on NIAH 100% scores.
- Tools/workflows:
- Automated CI that computes head metrics and PPL maps for every candidate checkpoint.
- Assumptions/dependencies: White-box access or reproducible measurements on a development build; thresholds should be calibrated per architecture.
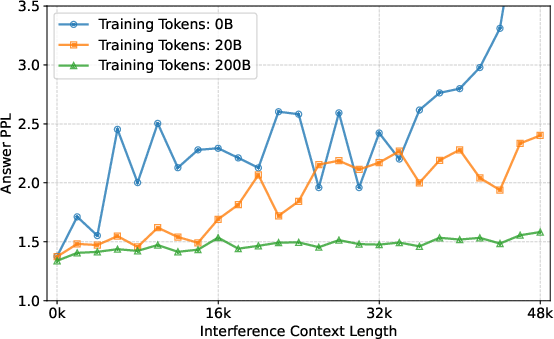
- Robustness testing against long-context “interference”
- Sector: model QA, safety
- What: Evaluate model stability by fixing absolute distances and varying interference context length, as described in the paper’s modified NIAH.
- Tools/workflows:
- Add interference tests to regression suites to ensure models remain confident (low PPL) under distracting context.
- Assumptions/dependencies: Requires standardized test generators; careful control of context placement.
- Improved procurement and vendor evaluation of long-context models
- Sector: enterprise IT, compliance
- What: Request continuous-NIAH PPL curves over lengths/depths and interference settings from vendors as part of due diligence; prefer vendors demonstrating low PPL plateaus and robust head metrics (if accessible).
- Tools/workflows:
- Vendor scorecards that weight PPL slope/plateau over binary NIAH scores.
- Assumptions/dependencies: Some vendors may not expose attention internals; PPL-only comparisons still yield value.
- Immediate product enhancements for long-document assistants
- Sector: legal, healthcare, finance, scientific R&D, software engineering
- What: Deploy 64K-capable LLMs trained with LCCP for:
- Legal e-discovery and contract analysis (thousands of pages).
- Long-form clinical summaries and longitudinal patient chart synthesis.
- Financial filings (10-K/10-Q) analysis and cross-referencing.
- Scientific literature review (arXiv-scale documents) with fewer “lost-in-the-middle” errors.
- Repository-level code Q&A and refactoring assistance.
- Tools/workflows:
- Ingest entire documents or repositories directly; reduce chunking/fragmentation; lean less on brittle retrieval heuristics.
- Assumptions/dependencies: Availability of a properly LCCP-trained 64K model; domain-specific privacy/compliance constraints.
- Education and research training modules
- Sector: academia, upskilling
- What: Use the hierarchical framework (behavioral SFT probing, PPL monitoring, head-level analysis) as course labs for interpretability and training dynamics.
- Tools/workflows:
- Notebooks that compute PPL maps and retrieval-head heatmaps on public checkpoints.
- Assumptions/dependencies: Public models must expose attention weights; students need GPUs for small-batch evaluation.
- Early stopping and curriculum scheduling based on PPL scaling laws
- Sector: AI training ops
- What: Track PPL ~ A·log(N)+B to decide when marginal gains justify more tokens; adjust long/short context ratios accordingly.
- Tools/workflows:
- Budget-aware schedulers that stop when PPL plateaus at token counts consistent with target performance.
- Assumptions/dependencies: Scaling behavior may shift with data mix/architecture; requires periodic evaluation.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem alignment before widespread deployment.
- Mechanistic interventions to optimize retrieval heads
- Sector: AI research, safety
- What: Actively encourage or constrain retrieval-head behavior during training to improve factuality, reduce verbatim copying, or tune copy/paste tendencies for privacy.
- Tools/products:
- “Retrieval-head regularization” losses, head-level gating or dropout, targeted fine-tuning curricula.
- Assumptions/dependencies: Requires stable identification and controllability of heads; potential interaction with other capabilities.
- Ultra-long context (≥256K) model development with principled monitoring
- Sector: enterprise AI, legal discovery, scientific curation, software
- What: Extend the framework to 256K–1M context to enable whole-case litigation review, complete EMR timelines, book-level reasoning, and monorepo-scale code navigation.
- Tools/products:
- Training pipelines that track PPL maps and head metrics at extreme lengths; memory-efficient attention variants.
- Assumptions/dependencies: Significant compute and memory; data availability for ultra-long sequences; stability of RoPE or alternative positional schemes.
- Industry-standard benchmarking and certification for long-context capability
- Sector: policy, procurement, standards bodies
- What: Establish continuous PPL-based long-context benchmarks (with interference tests) as procurement standards; move beyond binary NIAH.
- Tools/products:
- Open datasets and reference implementations; certification badges for “no deceptive saturation.”
- Assumptions/dependencies: Community consensus and broad adoption; reproducibility across architectures.
- Automated LCCP controllers (AutoML for long-context training)
- Sector: AI infrastructure
- What: Closed-loop systems that adjust learning rates, data mix, and training length in real time using PPL slope and retrieval-head metrics to meet target performance at minimal compute.
- Tools/products:
- “LCCP autopilot” integrated with training orchestrators (Ray, Kubernetes) and experiment trackers.
- Assumptions/dependencies: Reliable online metrics; robust causal links between metrics and downstream performance.
- Safety and compliance features informed by retrieval-head telemetry
- Sector: security/compliance, privacy
- What: On-device or server-side runtime monitors that detect excessive verbatim copying from sensitive regions in context; guardrails for PII leakage in long documents.
- Tools/products:
- Real-time attention auditing; policy engines that trigger redactions or warning prompts.
- Assumptions/dependencies: Efficient access to attention signals at inference (may require model/API changes); low overhead.
- Carbon- and cost-aware training governance for long-context runs
- Sector: policy, enterprise governance
- What: Governance policies that tie LCCP continuation to measured PPL gains per FLOP; require reporting of FLOPs and energy alongside evaluation metrics.
- Tools/products:
- Dashboards aligning PPL slopes with energy/carbon footprints; decision frameworks for halting or continuing runs.
- Assumptions/dependencies: Accurate energy metering; organizational commitment to sustainability targets.
- Dynamic prompt/packaging compilers informed by “lost-in-the-middle” mitigation
- Sector: software tooling, RAG
- What: Prompt compilers that place critical evidence in positions optimized for the model’s long-context retrieval profile, adjusting as models improve.
- Tools/products:
- Document layout optimizers that use learned PPL/attention profiles to structure inputs.
- Assumptions/dependencies: Model-specific profiles; potential drift with future fine-tuning.
- Cross-model generalization studies and tooling
- Sector: academia, open-source ecosystems
- What: Extend the framework to other families (Qwen, DeepSeek) to validate universality; create comparable head-metrics APIs.
- Tools/products:
- Unified evaluation suite for continuous NIAH + head analysis across models.
- Assumptions/dependencies: Access to internal attention for diverse models; comparable pretraining data conditions.
- Hardware–software co-design for attention diagnostics
- Sector: semiconductor, AI systems
- What: Add low-overhead primitives to expose attention statistics and token-to-token attributions, enabling cheap retrieval-head monitoring during training/inference.
- Tools/products:
- Accelerator kernels/APIs that export head-level telemetry.
- Assumptions/dependencies: Vendor support; verifying negligible performance impact.
- Consumer-grade long-document assistants with reduced brittleness
- Sector: education, personal productivity
- What: Broadly available assistants that can ingest books, manuals, or class notes without chunking pitfalls and fewer mid-context failures.
- Tools/products:
- Apps embedding ultra-long context models and robust formatting heuristics informed by PPL profiling.
- Assumptions/dependencies: Lower-cost deployment of long-context models; privacy safeguards for personal documents.
Glossary
- Attention head: A single attention subcomponent in a multi-head attention layer that computes attention weights over tokens. "The retrieval scores of all attention heads across all layers of the Hunyuan-A13B base model at different stages of LCCP."
- Autoregressive decoding: Generating tokens sequentially, each conditioned on previously generated tokens. "\citet{retrieval2025} introduces a retrieval score to measure the frequency of an attention head's copy-paste behavior during autoregressive decoding."
- Catastrophic forgetting: The tendency of a model to lose previously learned knowledge when trained on new data. "This configuration allows the model to progressively adapt to extended sequences while mitigating the risk of catastrophic forgetting of the knowledge acquired during the initial pre-training phase."
- Context window: The maximum number of tokens a model can attend to in a single input sequence. "The evolution of LLMs has recently shifted from scaling parameter counts to extending effective context windows"
- Copy-paste behavior (in attention): An attention behavior where tokens are directly copied from the context into the output. "identify the specific retrieval heads responsible for retrieval and copy-paste behaviors for further analysis."
- Cosine schedule: A learning rate decay schedule that follows a cosine curve over training steps. "We employ a learning rate that decays from to using a cosine schedule."
- Deceptive saturation: A misleading plateau in evaluation metrics that masks ongoing intrinsic improvements. "which often fail to reflect the intrinsic convergence state and can lead to "deceptive saturation"."
- Downstream benchmarks: Task-oriented evaluations used after pre-training to assess applied performance. "current evaluation methods rely heavily on downstream benchmarks (e.g., Needle-in-a-Haystack)"
- Dynamic routing: The mechanism in MoE architectures that selects which experts process each token/input on the fly. "the latter of which are dynamically routed to select 8 experts during inference."
- Feed-Forward Network (FFN): The position-wise multi-layer perceptron component in Transformer blocks. "Additionally, the model implements the SwiGLU activation function, with a hidden dimension of 4096 and an internal FFN hidden size of 3072 for each expert."
- Floating-point operations (FLOPs): A measure of computational cost counting basic arithmetic operations. "The cumulative computational cost of LCCP stage is estimated at total floating-point operations (FLOPs)."
- Global batch size: The total number of tokens (or examples) processed per optimization step across all devices. "We employ a global batch size of 16M tokens."
- Grouped-Query Attention (GQA): An attention variant that shares key/value projections across groups of query heads to reduce memory/compute. "the architecture employs Grouped-Query Attention with 32 query heads and 8 KV heads, effectively minimizing KV cache overhead."
- Hunyuan-A13B: An industrial-grade sparse MoE LLM studied in this work. "In this paper, we present the first systematic investigation of LCCP learning dynamics in an industrial-grade production model: Hunyuan-A13B, a Sparse Mixture-of-Experts (MoE) model with 80B total parameters"
- In-Context Learning (ICL): The ability of models to learn from examples provided in the prompt without parameter updates. "To address this, existing frameworks like lm-evaluation-harness and OpenCompass predominantly rely on ICL."
- Instruction-following: The capacity of a model to follow task directives stated in natural language. "However, evaluating base models is challenging due to their limited instruction-following capabilities and the high computational costs of training."
- KV cache: Cached key/value tensors used to speed up autoregressive decoding by avoiding recomputation. "effectively minimizing KV cache overhead."
- KV heads: The attention heads (or projections) responsible for key and value representations. "with 32 query heads and 8 KV heads"
- Long-Context Continual Pre-training (LCCP): A continued pre-training phase designed to extend and adapt models to longer sequence lengths. "Existing studies on Long-Context Continual Pre-training (LCCP) mainly focus on small-scale models and limited data regimes (tens of billions of tokens)."
- Lost in the middle: A phenomenon where models perform worse at retrieving information located in the middle of long contexts. "LCCP substantially enhances the model's retrieval capability and alleviates the "lost in the middle" phenomenon \citep{liu2024lost}."
- Mechanistic analysis: An interpretability approach examining internal components (e.g., attention patterns) to explain model behavior. "This work provides a comprehensive monitoring framework, evaluation system, and mechanistic interpretation for the LCCP of industrial-grade LLM."
- Mixture-of-Experts (MoE): An architecture where inputs are routed to a subset of specialized expert networks for computation. "Each MoE layer integrates one shared expert and 64 specialized experts, the latter of which are dynamically routed to select 8 experts during inference."
- Needle-in-a-Haystack (NIAH): A synthetic long-context retrieval task where a specific fact (needle) must be found within a large context (haystack). "The original Needle-in-a-Haystack \citep{niah2023} is designed to quantitatively evaluate an LLM's ability to locate and recall specific information when processing long-sequence inputs."
- Pass@3: A metric indicating success if the correct answer appears within the top three attempts or generations. "We report the Pass@3 scores for all checkpoints following SFT."
- Pearson correlation coefficient: A statistic measuring linear correlation between two variables. "The Pearson correlation coefficients between NIAH metrics and performance on downstream SFT probe benchmarks."
- Perplexity (PPL): A probabilistic measure of a model’s uncertainty over next-token predictions; lower is better. "and compute the token-level PPL over the answer tokens for each sample."
- Query heads: Attention heads that produce query vectors to compute attention weights against keys. "with 32 query heads and 8 KV heads"
- Retrieval head: An attention head specialized for locating and copying relevant tokens from the context. "Retrieval heads act as efficient, low-resource training monitors"
- Retrieval-augmented generation (RAG): A technique that improves generation by incorporating retrieved external documents. "and sophisticated retrieval-augmented generation \citep{jiang2024longrag}."
- Retrieval score: A metric quantifying how often an attention head copies target tokens from the context into the output. "\citet{retrieval2025} introduces a retrieval score to measure the frequency of an attention head's copy-paste behavior during autoregressive decoding."
- RoPE base frequency: A hyperparameter controlling the frequency scaling in rotary position embeddings to support longer contexts. "we adjust the RoPE base frequency, increasing it from 500K to 2M."
- Rotary Positional Embedding (RoPE) interpolation: A method to extend usable context length by rescaling RoPE frequencies. "Rotary Positional Embedding (RoPE) interpolation \citep{su2024roformer}"
- Scaling law: An empirical relationship predicting performance as a function of model/data/compute scale. "This behavior is largely consistent with the scaling law \citep{kaplan2020scaling, caballerobroken}"
- Spearman coefficient: A rank-based correlation measure assessing monotonic relationships. "we calculate the Spearman coefficient to measure the rank correlation of attention heads between these models, ordered by their retrieval scores."
- Supervised Fine-Tuning (SFT): Post-pretraining training on labeled data to adapt base models to target behaviors/tasks. "Utilizing lightweight Supervised Fine-Tuning (SFT) probing to evaluate the model's long-context understanding abilities in downstream tasks."
- SwiGLU: A gated activation function variant used in Transformer FFNs that can improve performance and stability. "Additionally, the model implements the SwiGLU activation function"
- Token-level probability distribution: The probability distribution over next tokens used in language modeling and evaluation. "thereby overlooking the underlying token-level probability distribution; even when models produce identical outputs, their generation probabilities may diverge significantly."
Collections
Sign up for free to add this paper to one or more collections.

