Sliding Window Attention Adaptation
Abstract: The self-attention mechanism in Transformer-based LLMs scales quadratically with input length, making long-context inference expensive. Sliding window attention (SWA) reduces this cost to linear complexity, but naively enabling complete SWA at inference-time for models pretrained with full attention (FA) causes severe long-context performance degradation due to training-inference mismatch. This makes us wonder: Can FA-pretrained LLMs be well adapted to SWA without pretraining? We investigate this by proposing Sliding Window Attention Adaptation (SWAA), a set of practical recipes that combine five methods for better adaptation: (1) applying SWA only during prefilling; (2) preserving "sink" tokens; (3) interleaving FA/SWA layers; (4) chain-of-thought (CoT); and (5) fine-tuning. Our experiments show that SWA adaptation is feasible while non-trivial: no single method suffices, yet specific synergistic combinations effectively recover the original long-context performance. We further analyze the performance-efficiency trade-offs of different SWAA configurations and provide recommended recipes for diverse scenarios. Our code is available at https://github.com/yuyijiong/sliding-window-attention-adaptation

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making big LLMs—the AI systems that read and write long texts—work faster when they have to handle very long inputs, like full books or long chat histories. The usual way these models “pay attention” to every word in the input is powerful but gets extremely slow as the text gets longer. The authors explore a faster method called sliding window attention (SWA), and they show how to adapt existing top models to use it without having to retrain them from scratch.
What problem are they trying to solve?
- Big LLMs normally use “full attention,” which means every word can look at every other word. That’s accurate, but becomes super slow as inputs get longer.
- Sliding window attention only lets each word look at nearby words (a “window”), which is much faster. But if you turn it on suddenly for a model trained with full attention, the model often performs poorly with long texts.
- The question: Can we teach already-trained models to use sliding window attention well—without redoing their expensive training?
How did they try to fix it? (Methods explained simply)
To adapt models, the authors combined five practical tricks—think of them as tools you can mix and match:
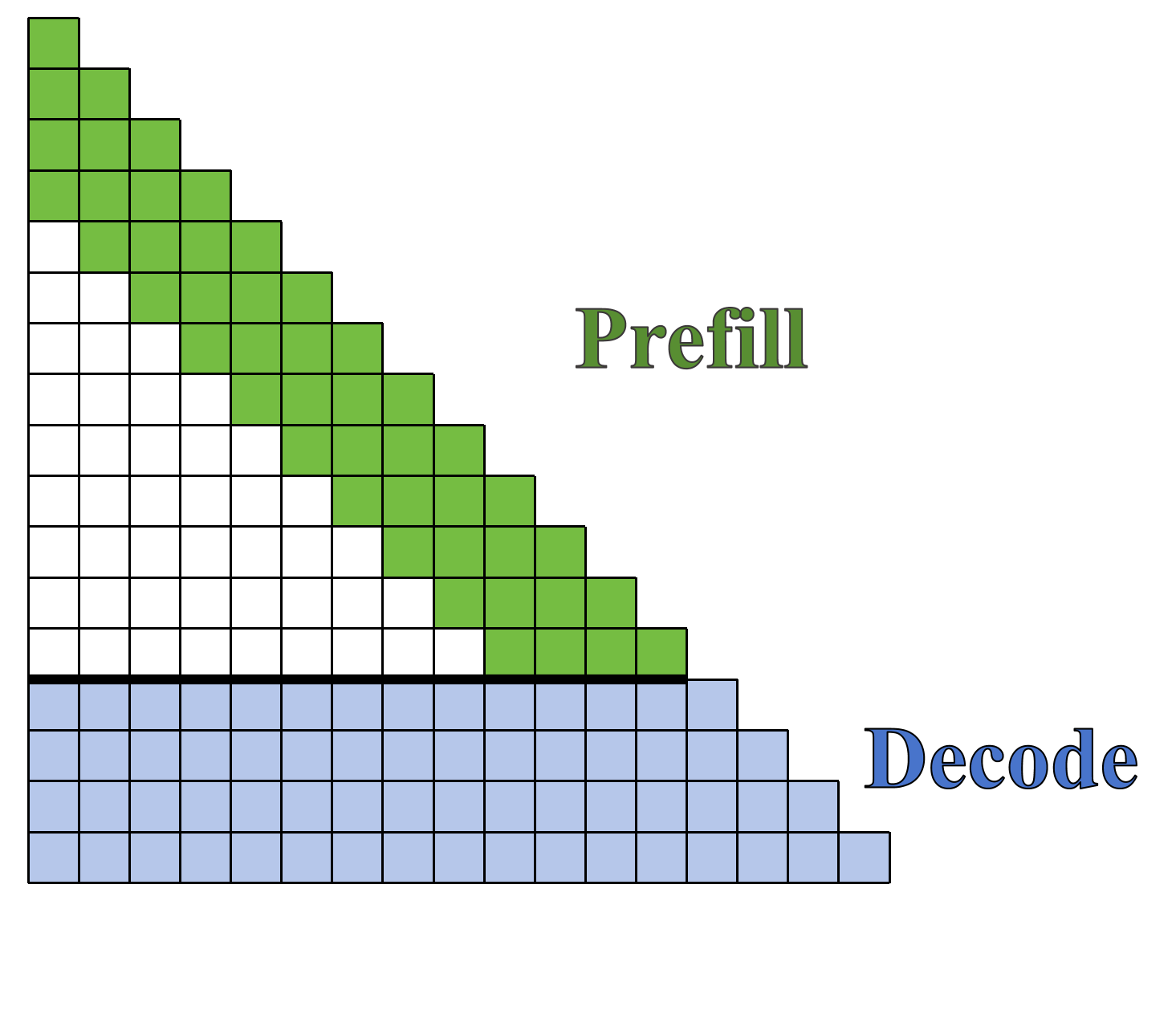
- FA Decode: Use sliding windows only while the model is “reading” the prompt (prefilling), then switch back to full attention while it’s “writing” the answer (decoding). Analogy: skim the article quickly, but think carefully and use all notes when writing your response.
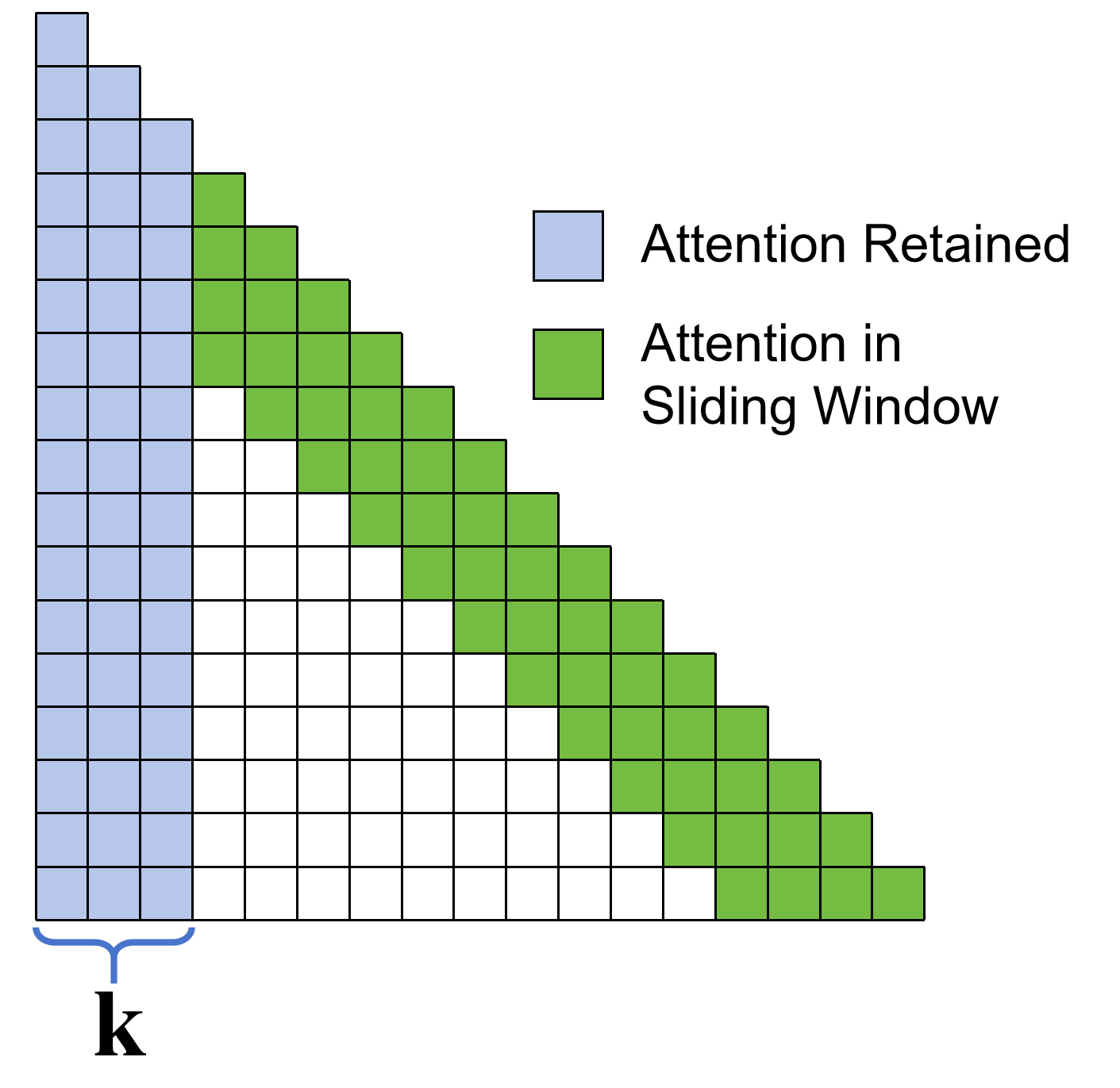
- Keep First k Tokens: Always let the model see the first few tokens (like the first sentences) no matter how long the context is. Analogy: keep a bookmark at the beginning because it often contains key info (like instructions or the topic).
- Interleaving FA/SWA Layers: Mix layers that use full attention with layers that use sliding windows. Analogy: alternate between zoomed-out and zoomed-in views as you read.
- Chain-of-Thought (CoT): Encourage the model to show its reasoning steps as it answers. Analogy: “Think out loud,” which helps it reason better using the limited window.
- Fine-tuning: Do a small amount of extra training so the model gets used to sliding windows, especially on long-context tasks. They use efficient methods (LoRA) and long datasets to keep this affordable.
Before training, they test different combinations of these tricks; after training, they test again to see which combos work best.
Key terms in everyday language
- Attention: How the model decides which earlier words to look at while processing a new word.
- Full attention vs. sliding windows: Full is like having a map of the whole city; sliding windows is like only seeing your street and nearby blocks—faster, but fewer details.
- Prefilling vs. decoding: Prefilling is when the model reads the prompt; decoding is when it writes the answer.
- Sink tokens: Important tokens near the start that models rely on a lot; hiding them can make the model confused.
- Chain-of-Thought: The model shows step-by-step reasoning instead of jumping to the final answer.
What did they find?
Here are the main results, explained simply:
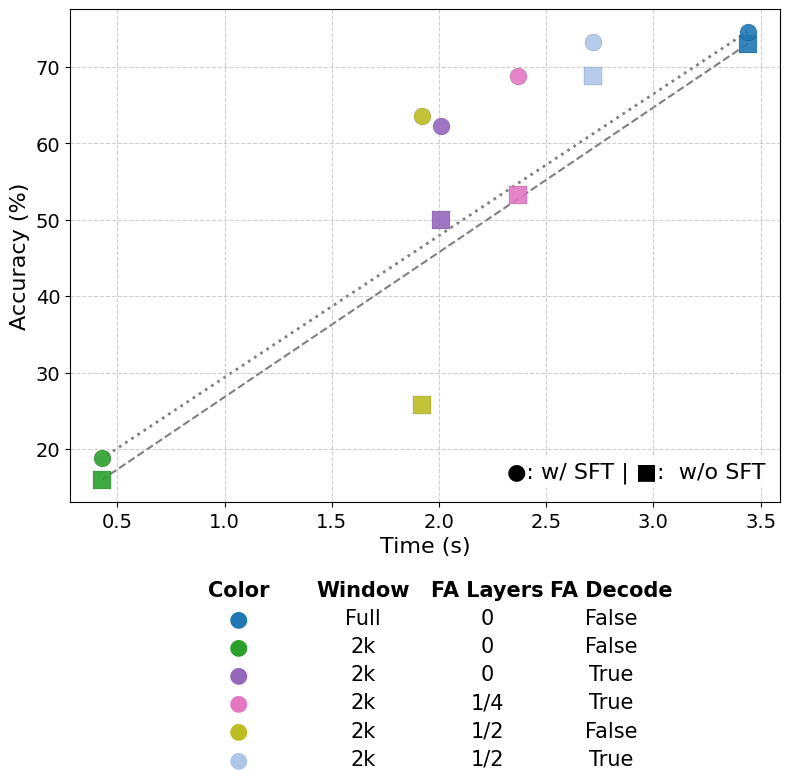
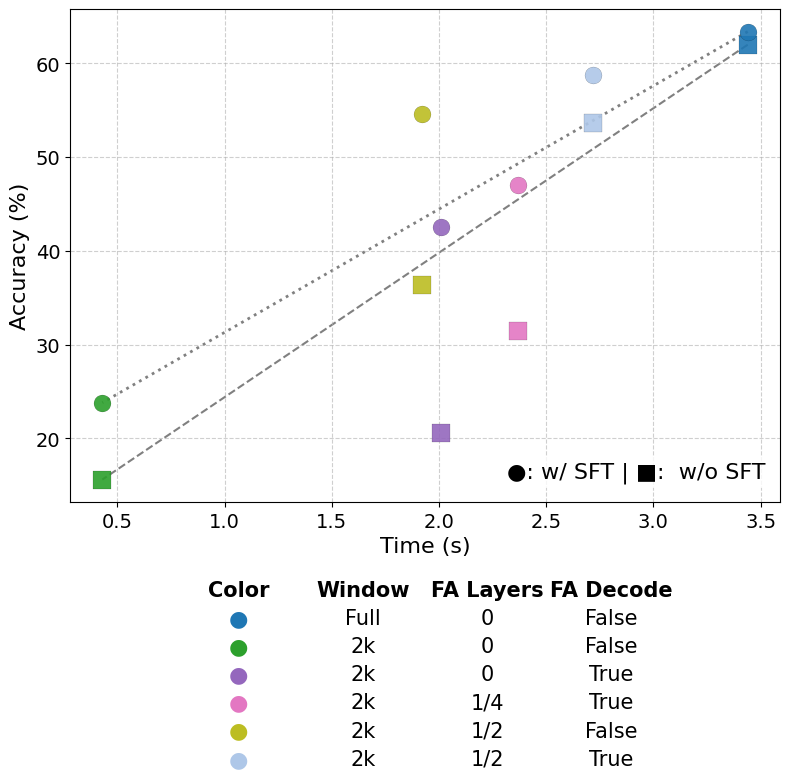
- Naive SWA performs poorly: Just turning on sliding windows everywhere hurts long-context performance a lot.
- No single trick fixes everything: Each method helps a bit, but combining them is what really works.
- Strong combo without training: Using FA Decode + Interleaving layers + (optionally) keeping the first few tokens can recover most of the lost performance, even with small windows.
- Chain-of-Thought helps especially with FA Decode: If the model thinks out loud while it has full attention in the “writing” phase, it uses the limited reading phase more effectively.
- After fine-tuning, results get even better: Fine-tuning with SWA makes the model much more comfortable with sliding windows. After this, FA Decode and interleaving layers become the main boosts, and “Keep First k Tokens” becomes optional.
- Bigger windows help, but aren’t the most important: Increasing the window size adds some accuracy, but the biggest gains come from FA Decode and interleaving.
- Layer choices depend on the model: Which layers should use full attention varies by model family and size, so there isn’t a one-size-fits-all pattern.
They test on several models (Qwen3 and Llama3.1) and long-context benchmarks (like LongMemEval). In many setups, they get close to the original full-attention performance while being faster.
Why is this important?
- Speed: Sliding window attention makes models process long inputs much faster.
- Cost: Adapting existing models is cheaper than training entirely new models with sparse attention from scratch.
- Flexibility: Their “recipes” let developers choose the right balance of speed and accuracy for different applications, like long customer chats, research papers, or codebases.
What does this mean for the future?
- Practical deployment: Teams can plug these recipes into current LLM systems to handle long contexts more efficiently.
- Better long-context tools: Apps that involve long histories (like chat assistants that remember months of conversations) can become faster without losing quality.
- Research direction: Future work can refine which layers to interleave, try smarter training (like reinforcement learning) to improve reasoning with limited windows, and extend to larger models.
Summary
- Problem: Full attention is too slow for very long inputs; sliding windows are fast but hurt accuracy if used naively.
- Solution: Mix practical methods (FA Decode, keep first tokens, interleave layers, CoT, fine-tuning) to adapt existing models.
- Outcome: The right combinations make sliding windows work well, often close to full attention, while being faster and cheaper to deploy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address.
- Scaling to larger model sizes: Do the findings (e.g., best SWAA combinations) generalize to 70B+ models and mixture-of-experts architectures, and how do scaling laws interact with SWA-induced information loss?
- Robustness across model families: Can a principled, model-agnostic procedure be developed for selecting FA/SWA layers that generalizes across families (Qwen, Llama, Mistral, etc.) rather than relying on ad-hoc odd/even layer choices that flip by model?
- Data-driven layer selection: What automated criteria (e.g., attention span statistics, gradient-based importance, attention entropy, intervention-based probing) can reliably identify “global” vs “local” layers to interleave FA/SWA per model?
- Dynamic, input-adaptive layer scheduling: Can FA/SWA layer selection be decided per input (or per decoding step) based on uncertainty, retrieval difficulty, or saliency signals rather than fixed schedules?
- Window size scheduling: Instead of a fixed window per SWA layer, can layer-wise or token-adaptive window sizes be learned or selected online to minimize compute at a given accuracy target?
- Sink token selection beyond “first k”: Are there better, content-aware strategies for “global tokens” (e.g., learned anchors, section headers, system tokens, retrieved key sentences) than statically keeping the first k tokens?
- Automatic k selection: Can we estimate the minimal k per model/task/dataset online (e.g., via calibration or validation-time heuristics) to avoid manual tuning of the “keep first k tokens” hyperparameter?
- Decoding-time FA budget: How to constrain FA during decoding for very long generations (e.g., long-form writing) to avoid quadratic blowup while maintaining quality—e.g., chunked FA decode, periodic FA snapshots, or hybrid decode policies?
- Streaming/online settings: How does FA Decode behave in live streaming or multi-turn chat where both prefill and decode are interleaved and outputs can be long? Are there stable policies to switch between FA and SWA mid-conversation?
- KV cache memory reduction: The current approach improves speed but not memory. How should KV eviction/compaction policies (e.g., windowed KV, TTL, learned eviction, per-layer policies) be designed for SWAA, especially when Keep First k is used?
- Interactions with inference engines: How robust are SWAA gains across kernels and serving stacks (FlashAttention variants, Triton, TensorRT-LLM, custom kernels) and under mixed precision (fp16/bf16/quantized KV)?
- Quantization compatibility: Does SWA adaptation interact with KV/value quantization (e.g., 4-bit KV, NF4) in accuracy and stability? Are there quantization-aware recipes for SWAA?
- Effects on short-context tasks post-SFT: Although LoRA can be disabled for short inputs, does SWA-aware SFT introduce any hidden regressions on short-context tasks or safety/alignment behaviors when adapters are active?
- Training objectives for “thinking” under SWA: The paper hypothesizes longer reasoning may compensate for SWA information loss. What training signals (RL like GRPO, process rewards, length/coverage regularizers) best induce effective “longer-but-productive” reasoning for SWAA?
- Distillation target quality: The SFT data come from the FA model’s answers filtered for correctness. Does training on FA-style solutions cap the potential of SWAA models that might need different (longer or differently-structured) reasoning traces?
- Dataset composition and scale: What is the minimal/optimal amount and mix of long-context SFT data (domains, tasks, languages) to achieve robust SWAA adaptation without overfitting? How do multilingual and code-heavy corpora affect outcomes?
- Generalization across task types: Beyond LongMemEval and LongBench-V2, how does SWAA perform on diverse long-context tasks (multi-document QA, legal/biomedical summarization, codebase reasoning, retrieval-augmented generation, long-form creative writing)?
- Length sensitivity curves: What are accuracy and latency curves across a wide range of context lengths (e.g., 8k to 1M) and output lengths, and where do specific SWAA configurations break down?
- Positional encoding interactions: How do RoPE scaling variants, ALiBi, or dynamic position interpolation interact with SWAA and FA Decode, especially at extreme lengths?
- Decoding strategies: The experiments use greedy decoding. Do beam search, nucleus/top-k sampling, or speculative decoding alter SWAA’s effectiveness, stability, or throughput?
- Safety, calibration, and stability: How do SWAA configurations affect calibration, hallucination rates, and safety behaviors under long-context stress? Are there alignment regressions or brittle failure modes (e.g., over-reliance on early “sink” tokens)?
- Theoretical understanding: Why do FA Decode and interleaving layers synergize so strongly? Can we model information bottlenecks introduced by SWA and formally explain which layers must remain global?
- Extending beyond SWA: Do the SWAA principles transfer to other sparse schemes (block-sparse, ring/strided attention, global-token patterns like Longformer/BigBird, semantic token selection), and what adaptations are needed?
- Systems-level throughput under load: How do SWAA recipes behave in multi-tenant serving with heterogeneous prompts, prefix caching, admission control, and batching constraints? What is the end-to-end cost/throughput benefit at scale?
- Automated recipe selection: Can we build an autotuner that selects window size, k, FA/SWA layer set, and decode policy to meet a given accuracy/latency/memory budget on a target workload?
- Reproducibility and artifacts: To what extent do results depend on the specific FA-model teachers, filtering heuristics, and engine precision differences (vLLM vs HF)? Can standardized evaluation harnesses be provided for fair comparisons?
Practical Applications
Immediate Applications
The following items summarize concrete, deployable use cases that directly leverage the paper’s SWAA recipes (FA Decode, Keep-First-k sink tokens, Interleaving FA/SWA layers, CoT, and optional SWA-aware fine-tuning) and the plug-and-play implementation on FlashAttention-2 and vLLM.
- Cost-optimized long-context LLM serving
- Sectors: software, cloud platforms, AI infrastructure
- Tools/workflows: vLLM-based serving with SWAA recipes; runtime toggles for FA Decode, Interleaving, and Keep-First-k; per-query policy to select window size and FA-layer pattern based on accuracy/latency targets; dashboards to monitor TTFT/TPOT and throughput
- Assumptions/dependencies: FA-pretrained models (e.g., Qwen, Llama); FlashAttention-2 kernels; model-specific layer selection (odd/even differences observed across model families); CoT synergy for thinking models; GPU support
- Enterprise RAG over ultra-long documents
- Sectors: legal, compliance, finance, healthcare, public policy
- Tools/workflows: RAG pipeline that ingests very long contexts (16k–128k+) with SWA during prefilling and FA during decode; Keep-First-k to stabilize attention distribution; less aggressive chunking/summarization, leaner retrieval post-processing
- Assumptions/dependencies: long-context QA style tasks; fine-tuning optional for domain-specific reliability; secure hosting and data governance; window/k values tuned for task difficulty
- Project-scale coding assistants
- Sectors: software development, DevOps
- Tools/workflows: IDE extensions that can read large repositories, monorepos, or log histories; SWA for fast prefilling on large code contexts, FA Decode for high-quality reasoning; Interleaving FA layers to balance latency and accuracy
- Assumptions/dependencies: thinking models (CoT) yield better accuracy-efficiency trade-offs; repository token budgets; model-specific layer selection experimentation
- Knowledge-base chatbots with very long memory
- Sectors: customer support, enterprise IT, internal tools
- Tools/workflows: multi-session memory QA (LongMemEval-style) using SWA+FA Decode; Keep-First-k for stability; per-department knowledge bases with reduced server costs and improved responsiveness
- Assumptions/dependencies: correct memory scoping and privacy controls; tuning window size to match session length; occasional SFT for stability in specialized domains
- Meeting/transcript summarization with persistent memory
- Sectors: enterprise productivity, education
- Tools/workflows: agents that aggregate multi-day transcripts, agenda notes, and action items; SWA for prefilling long histories and FA Decode for synthesis; CoT for detailed reasoning and rationale
- Assumptions/dependencies: sensitive data handling; accuracy thresholds validated on tasks exceeding 16k tokens; compute resource planning
- Document review platforms (eDiscovery and FOIA)
- Sectors: legal, government
- Tools/workflows: long-case review and FOIA document triage; SWAA recipes to process full exhibits with fewer summaries; audit trails capturing CoT rationales when permissible
- Assumptions/dependencies: domain-specific evaluation; SFT recommended for legal-domain reliability; policy-compliant CoT exposure
- Financial research assistants scanning filings and transcripts
- Sectors: finance, investor relations, equity research
- Tools/workflows: SEC 10-K/10-Q ingestion, earnings calls, analyst reports; SWA-prefill to process entire report; FA Decode to maintain synthesis quality; query-time trade-off selection (accuracy vs. latency)
- Assumptions/dependencies: compliance and data licensing; optional domain SFT for accounting/finance terminology
- EHR summarization and longitudinal patient timelines
- Sectors: healthcare
- Tools/workflows: assistants that read long EHRs, clinical notes, and sensor logs; SWA for fast intake, FA Decode for clinical-grade reasoning; CoT for stepwise plan generation and differential diagnosis explanation
- Assumptions/dependencies: PHI privacy and regulatory compliance; medical accuracy safeguards; domain SFT highly recommended
- Academic literature review across many papers
- Sectors: academia, research
- Tools/workflows: meta-analysis assistants that ingest many PDFs; SWA to handle very large corpora in one pass; FA Decode for structured synthesis; CoT to improve traceability of claims and citations
- Assumptions/dependencies: domain SFT or prompt strategies for citation accuracy; PDF parsing quality; window/k tuning
- LMS plugins for grading long essays and theses
- Sectors: education
- Tools/workflows: LMS integrations that process long submissions at lower latency; Interleaving FA layers to preserve evaluation quality while cutting costs; CoT-enabled rubrics
- Assumptions/dependencies: fairness and transparency requirements; CoT visibility policy; calibration per course domain
- Latency-aware serving policies and auto-tuners
- Sectors: AI ops, MLOps
- Tools/workflows: runtime controllers that choose among SWAA recipes per query (e.g., FA Decode on complex tasks, full SWA on simpler ones); automated selection of window size and Keep-First-k; cost-saving estimators
- Assumptions/dependencies: accurate task difficulty heuristics; service-level objectives; integration with vLLM/paged attention
- Personal archive assistants (daily life)
- Sectors: consumer productivity
- Tools/workflows: tools that read years of emails, notes, and documents in one context; SWA for fast intake, FA Decode for high-quality personal summaries; local or private cloud deployment
- Assumptions/dependencies: privacy and security; device compute constraints; CoT preference settings
Long-Term Applications
The items below are promising directions that require further research, scaling, or engineering to become robust products.
- KV cache eviction/overwriting for memory reduction
- Sectors: AI infrastructure, edge deployment
- Tools/workflows: SWAA with KV eviction to cut VRAM and enable longer contexts on smaller GPUs or edge devices
- Assumptions/dependencies: kernel/runtime engineering; correctness and stability testing; compatibility with paged attention
- Automated layer selection and adaptive recipes
- Sectors: software, research tooling
- Tools/workflows: profilers that learn per-model optimal FA/SWA layer patterns (odd/even differences, fraction of FA layers); AutoSWAA controllers that adapt recipes per request type
- Assumptions/dependencies: reliable profiling signals; generalization across model families and sizes; tight integration with serving stacks
- RL-based reasoning trajectory optimization under SWA
- Sectors: research, advanced LLM training
- Tools/workflows: GRPO-style training to learn longer, more effective CoT traces compensating for SWA information loss; self-distillation pipelines tailored to SWA
- Assumptions/dependencies: training stability and cost; reward design; safety and hallucination controls
- 70B+ model generalization and multi-GPU scaling
- Sectors: enterprise, cloud AI
- Tools/workflows: SWAA evaluation and tuning for very large models; efficient tensor-parallel implementations; recipe routing across shards
- Assumptions/dependencies: kernel scalability; interconnect performance; cost-benefit validation versus full attention
- Standardized long-context efficiency benchmarks and procurement policy
- Sectors: public policy, enterprise IT governance
- Tools/workflows: metrics that combine accuracy with TTFT/TPOT/throughput; guidelines for energy-efficient attention in public-sector AI procurements
- Assumptions/dependencies: consensus on evaluation protocols; disclosure practices for CoT; regulatory engagement
- Sector-specific SWA-aware fine-tuning corpora and validation suites
- Sectors: healthcare, legal, finance, education
- Tools/workflows: curated long-context datasets with verified answers/rationales; domain validators; continuous evaluation harnesses
- Assumptions/dependencies: data access and labeling; privacy and compliance; model-version stability
- Streaming analytics for long, continuous logs
- Sectors: cybersecurity, energy/grid ops, IoT
- Tools/workflows: SWA+Keep-First-k for continuous log ingestion; FA Decode for incident summaries; KV eviction to control memory footprints; near-real-time alerting
- Assumptions/dependencies: robust streaming integration; latency constraints; anomaly detection coupling
- Hybrid architectures combining SWA with linear attention
- Sectors: foundational model R&D
- Tools/workflows: interleaving SWA with Mamba/SSMs or RWKV variants; recipe-level switches to optimize specific reasoning chains
- Assumptions/dependencies: architecture compatibility; training cost; stability and quality versus vanilla Transformers
- Hardware–software co-design for sparse attention
- Sectors: semiconductors, HPC
- Tools/workflows: specialized kernels for SWAA masks (FA Decode, Keep-First-k); dynamic window scheduling; memory-friendly operators
- Assumptions/dependencies: vendor support; compiler/runtime integration; cross-framework compatibility
- Privacy-first on-device long-memory assistants
- Sectors: consumer devices, enterprise endpoints
- Tools/workflows: SWAA plus KV memory optimizations to fit very long personal contexts on laptops or mobile GPUs; local-only CoT reasoning
- Assumptions/dependencies: hardware constraints; careful energy management; local indexing and storage
- Compliance and audit-friendly CoT exposure policies
- Sectors: regulated industries
- Tools/workflows: configurable CoT visibility (full, redacted, or suppressed) aligned to SWAA recipes; audit logging for decisions made under long-context reasoning
- Assumptions/dependencies: legal review; UX for rationale disclosure; user consent and governance
- Accuracy–latency trade-off routers and SLAs
- Sectors: MLOps, platform engineering
- Tools/workflows: service routers that match SWAA configurations to SLAs (e.g., FA Decode+Interleaving for premium accuracy, full SWA for fast/low-cost tiers); dynamic scaling policies
- Assumptions/dependencies: observability and explainability; robust fallback mechanisms; customer segmentation
Notes on Assumptions and Dependencies (General)
- Model family differences matter: odd/even FA-layer selection performed differently across Qwen3-4B, Qwen3-30B, and Llama3.1-8B, so layer selection should be profiled per model.
- CoT synergy: “thinking” models benefit more from FA Decode; CoT often improves the accuracy–latency ratio.
- Window size and Keep-First-k: larger windows help but are not decisive; Keep-First becomes optional after SWA-aware fine-tuning (SFT).
- Serving stack: results assume FlashAttention-2 and vLLM; quality may differ across frameworks/precisions; throughput numbers depend on hardware (e.g., H100).
- Memory: current implementation improves speed primarily; KV cache eviction is not yet implemented, so VRAM savings may require future work.
- Data and compliance: for healthcare/legal/finance use cases, domain SFT and strict privacy/compliance are essential.
Glossary
- Attention mask: A binary matrix that specifies which token positions a token is allowed to attend to during computation. "Attention mask for FA Decode."
- Attention sink: Tokens (often at the beginning of the sequence) that attract disproportionately high attention, stabilizing model behavior. "allocate a disproportionate amount of attention to the initial tokens ("attention sink"),"
- Auto-regressive generation: The decoding process where each next token is generated conditioned on all previously generated tokens. "decoding (auto-regressive generation) stage"
- Causal attention: An attention mechanism that restricts each token to attend only to previous tokens, preserving autoregressive causality. "full-causal-attention models"
- Chain-of-Thought (CoT): A prompting or modeling technique that elicits explicit step-by-step reasoning before producing the final answer. "Chain-of-Thought (CoT)"
- FA Decode: A recipe that uses sliding-window attention during prefilling but switches to full attention during decoding. "Full Attention (FA) Decode: applying SWA only during the prefilling stage while switching back to full attention for decoding."
- Flash-Attention-2: An optimized GPU kernel for attention that improves speed and parallelism while reducing memory overhead. "Flash-Attention-2"
- Full Attention (FA): Standard dense self-attention where each token can attend to all tokens in the sequence. "full attention for decoding."
- GRPO: A reinforcement learning method used to improve reasoning capability by optimizing generation trajectories. "GRPO"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without sampling. "We use greedy decoding (temperature )"
- Interleaving FA/SWA layers: Mixing full-attention and sliding-window-attention layers to balance performance and efficiency. "interleaving FA/SWA layers"
- Keep First k Tokens: A mechanism that preserves visibility to the first k “sink” tokens for all subsequent tokens under SWA. "Keep First Tokens"
- KV cache: Cached keys and values from attention layers used to accelerate decoding by avoiding recomputation. "KV cache"
- KV cache eviction: Dropping or overwriting older cached keys/values to reduce memory usage during long-context inference. "KV cache eviction (or overwriting) mechanism"
- Linear attention: Attention variants with linear complexity in sequence length, often via kernelization or state-space formulations. "linear attention"
- LoRA (Low-Rank Adaptation): Parameter-efficient fine-tuning that injects low-rank adapters into selected model projections. "LoRA"
- Prefilling stage: The initial pass that processes the prompt and populates the KV cache before decoding. "prefilling stage"
- Query, key, and value projection: The linear transformations that produce Q, K, and V tensors for attention computation. "query, key, and value projection modules"
- Self-distillation: Using a model’s own outputs to create training targets that better align distributions for fine-tuning. "self-distillation"
- Sliding Window Attention (SWA): Local sparse attention that restricts each token’s receptive field to a fixed-size window, reducing complexity to linear. "Sliding Window Attention (SWA)"
- Sliding Window Attention Adaptation (SWAA): A set of recipes combining multiple methods to adapt FA-pretrained models to SWA without pretraining. "Sliding Window Attention Adaptation(SWAA)"
- Streaming attention: An attention scheme that retains sink tokens’ visibility while using a sliding window to stabilize outputs. "streaming attention"
- Structured state-space models (SSMs): Sequence models that maintain a latent state evolving over time to achieve linear-time processing. "structured state-space models (SSMs) like Mamba"
- Supervised fine-tuning (SFT): Gradient-based training on labeled data to align model behavior with task requirements. "supervised fine-tuning"
- Time-per-output-token (TPOT): The average latency to generate each output token during inference. "time-per-output-token (TPOT)"
- Time-to-first-token (TTFT): The latency from request start to the generation of the first token. "time-to-first-token (TTFT)"
- vLLM: A high-throughput LLM serving system with efficient memory management (PagedAttention) and batching. "vLLM"
Collections
Sign up for free to add this paper to one or more collections.

