- The paper introduces a 15B-parameter supernet that enables runtime per-layer token mixer selection to dynamically balance speed–quality tradeoffs.
- It employs stochastic distillation and a surrogate-guided placement search to efficiently explore 4^48 configurations and identify Pareto-optimal setups.
- Empirical results demonstrate significant throughput gains (up to 10.7×) with graceful quality degradation, empowering flexible, workload-adaptive LLM deployment.
Super Apriel: Surpassing Speed-Quality Tradeoffs via Serving-Time Placement Flexibility
Introduction and Motivation
Super Apriel introduces a 15B-parameter token-mixer supernet enabling dynamic throughput-quality tradeoffs at inference time by supporting runtime per-layer mixer selection. Unlike prior hybrid LLM architectures, which expose a single, fixed placement determined at design or conversion time, this work realizes the vision of one checkpoint serving many speeds: a single release artifact in which every decoder layer offers four interchangeable token mixer implementations—Full Attention (FA), Sliding Window Attention (SWA), Kimi Delta Attention (KDA), and Gated DeltaNet (GDN). This design allows the deployment of models that can be instantaneously reconfigured to match heterogeneous workload requirements without repeated training, distinct model deployments, or compromise at release time.
The methodology is motivated by real-world LLM serving constraints: inference cost and memory bottlenecks under FA, especially at long context; the need for per-application speed-quality preset selection; and the limitations of conventional hybrid attention architectures that rigidly prescribe placement. Super Apriel reframes placement selection as a runtime policy, integrating a tractable surrogate-based optimization procedure to efficiently sweep the massive 448 placement space and curate Pareto-optimal configurations.
Supernet Architecture and Training Regimen
Design and Mixer Vocabulary
Super Apriel is built atop Apriel 1.6—a 48-layer, grouped-query attention, 15B-parameter multimodal decoder model with expansive context, vocabulary, and vision support. In the supernet, each decoder layer contains all four mixer variants, but only one is active per inference pass. The four mixers are:
- FA: canonical O(n2) softmax attention with per-layer KV cache,
- SWA: windowed GQA, bounding attention span,
- GDN: dynamically gated, recurrent mixing via delta rule,
- KDA: channel-wise-gated extension of GDN.
The configuration space spans all assignments of mixer-types across the 48 layers (Figure 1).
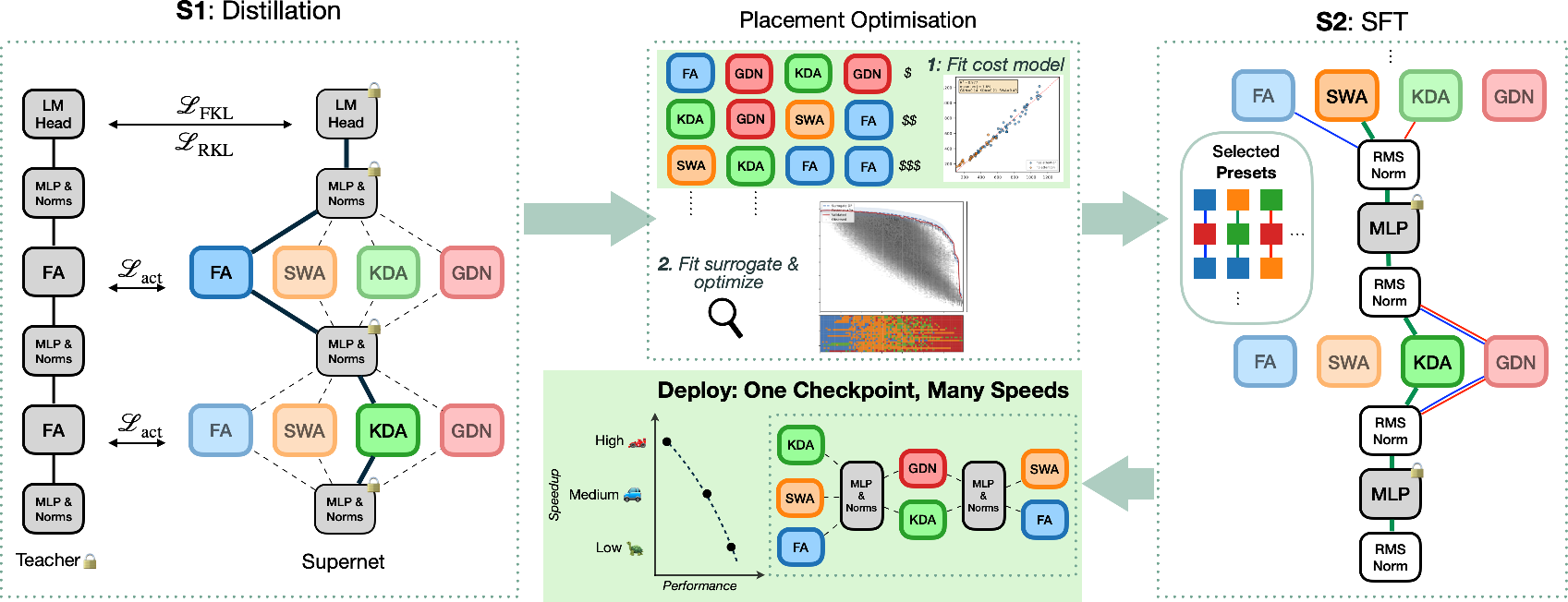
Figure 1: Super Apriel’s supernet architecture enables flexible runtime selection among four trained mixer types per layer, with a multi-stage (distillation → placement search → SFT) training pipeline.
Stochastic Distillation and SFT
Training initiates with stochastic distillation: at each optimization step, for every layer, a mixer type is uniformly sampled, forwarding activations through the resulting sub-network. Mixer parameters are updated via a loss function that combines activation matching, forward KL, and reverse KL with respect to a frozen Apriel 1.6 teacher. The stochasticity exposes all mixer combinations to the data, ensuring robust mixer specialization and shared FFN/embedding/norm parameterization.
After distillation, SFT is employed with targeted placement sampling focused on a small set of previously-identified Pareto-optimal placements, further adapting mixers using instruction-finetuning data. Notably, in all stages, the shared parameters are kept frozen, a design choice empirically superior to full-model adaptation for this pipeline.
Placement Search: Surrogate-Guided Exploration of the Combinatorial Landscape
The critical challenge is the astronomical size of the placement space. Rather than heuristic search or manual ablation, the authors introduce a surrogate-guided pipeline based on a cluster expansion—a decomposable statistical physics-inspired parameterization—which expresses downstream benchmark quality for a sub-network (placement) as a function of low-order, short-range layer interactions.
The search proceeds by sampling diverse placements, evaluating them (efficient due to no weight reloading), fitting a regularized Bayesian linear surrogate, and performing exact cost-constrained dynamic programming to sweep the speed-quality Pareto curve. This process, iterating safe/exploratory candidate selection (Figure 2), rapidly identifies globally optimal presets for any feasible operating point.
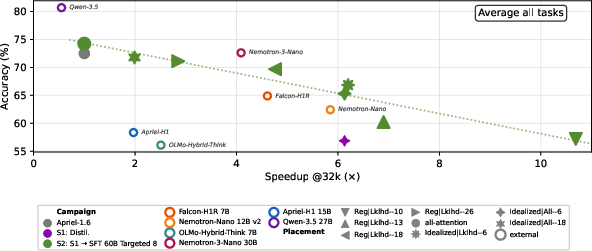
Figure 2: Surrogate optimization pipeline for placement search balances exploration of unexplored allocations and exploitation of surrogate-predicted optima.
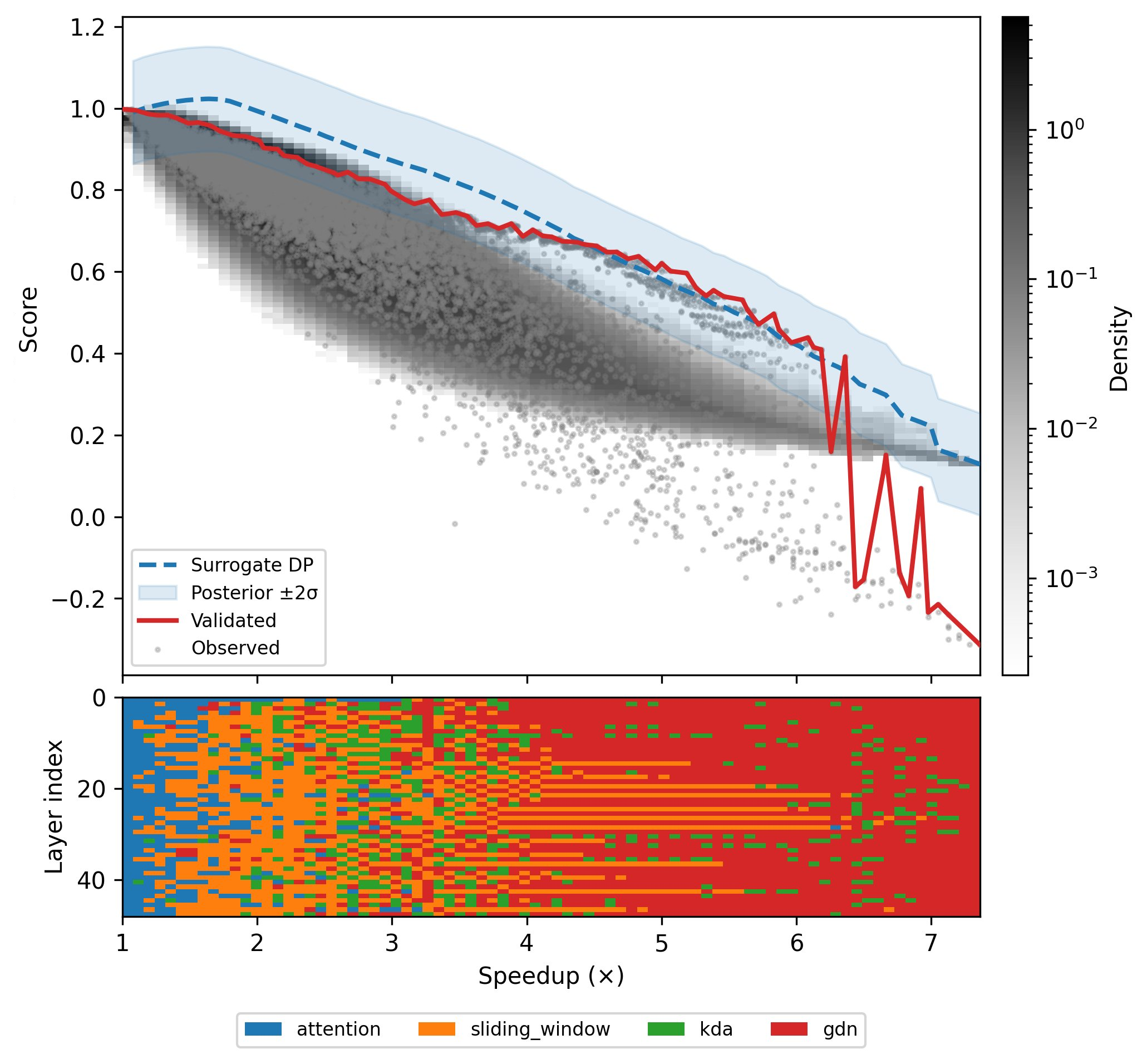
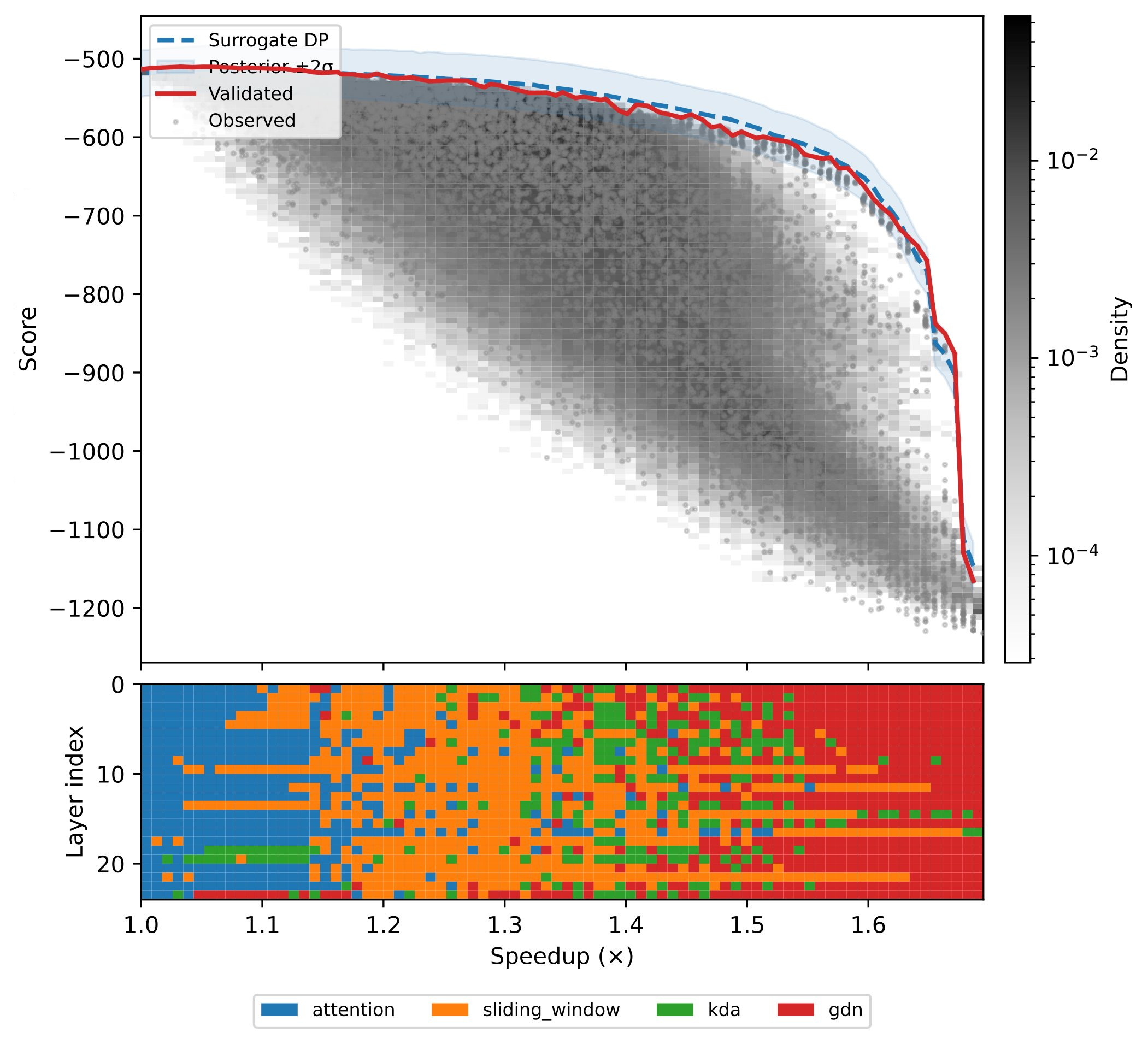
Figure 3: Placement-quality Pareto frontier for the 15B supernet; layer-wise mixer assignments of optimal placements reveal systematic retention of FA in mid-network layers.
Placement Dynamics and Rank Stability
A central empirical investigation addresses when placement rankings (i.e., which mixer arrangements are best at a given cost) become stable during training, and whether they can be reliably predicted at scale. Rigorous ablation with 0.5B and 15B supernets demonstrates:
- Overall rankings crystallize early under stochastic training (Spearman ρ>0.98 within 3–6% of steps at both scales, see Figure 4).
- Frontier (deployment-relevant) placements, especially at the 15B scale, exhibit pronounced rank volatility—rank order along the Pareto frontier can shift even late in training, and findings at small scale (0.5B) do not extrapolate reliably to large models (Figure 5).
- Stochastic distillation is empirically robust to false optima, as no configuration’s relative performance is overfit by exposure bias (contrasting with targeted/hybrid regime experiments from Figure 6).
This cautions against “early selection and targeted SFT” workflows at production scale.
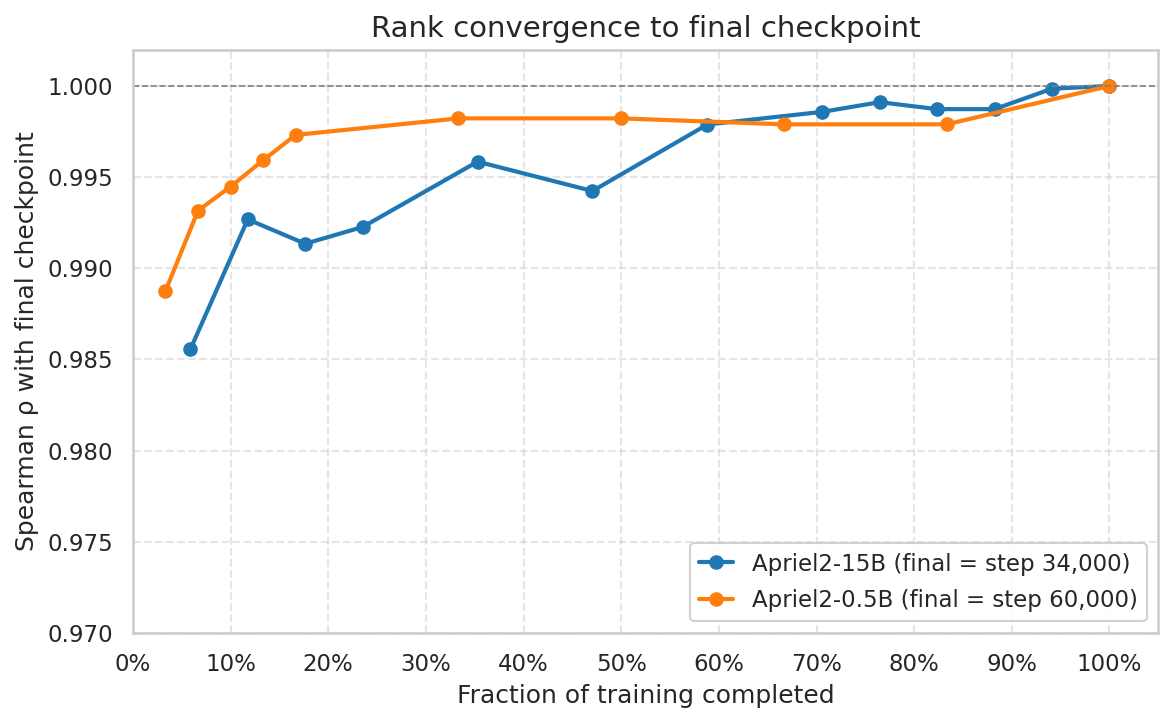
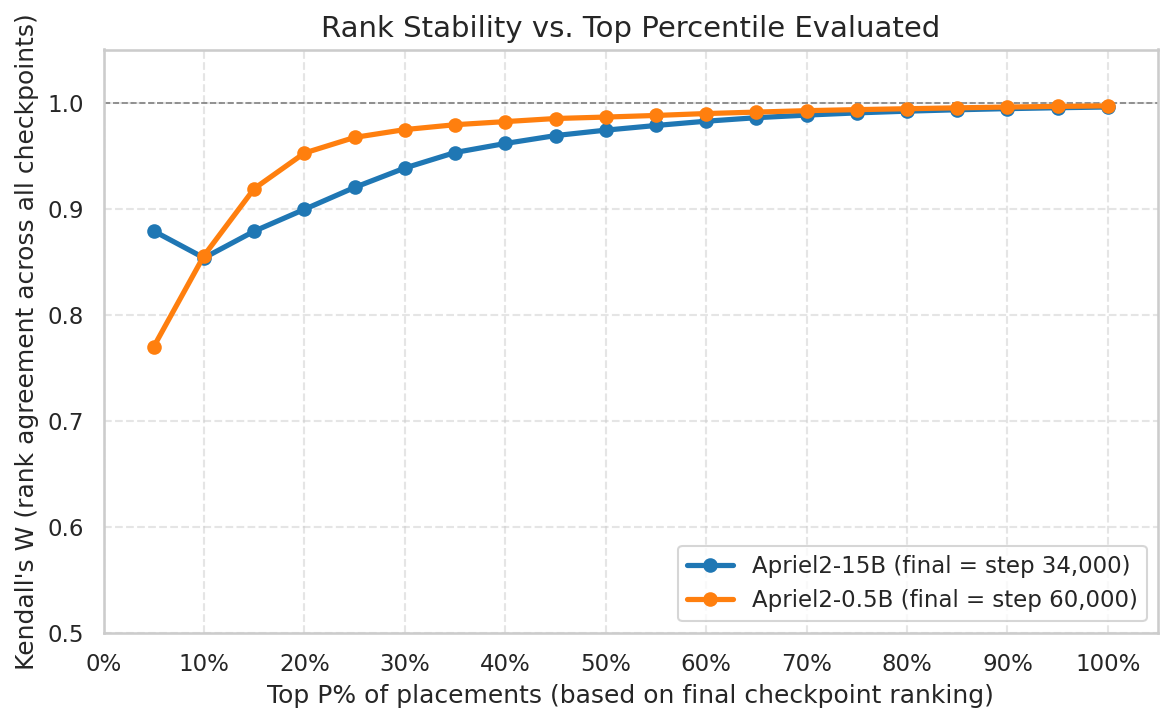
Figure 4: Convergence of placement ranking stability—high overall but less stable near the Pareto frontier, especially in 15B.
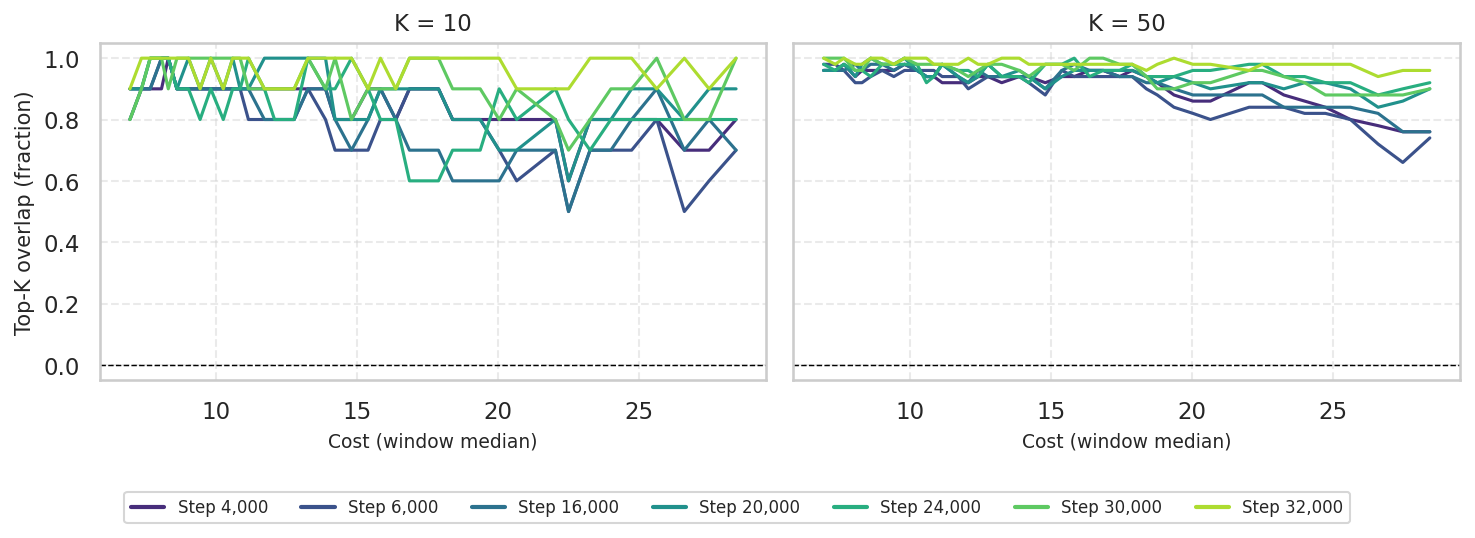
Figure 5: Top-k overlap between early and final placement rankings confirming incremental drift in frontier assignment at greater scale.
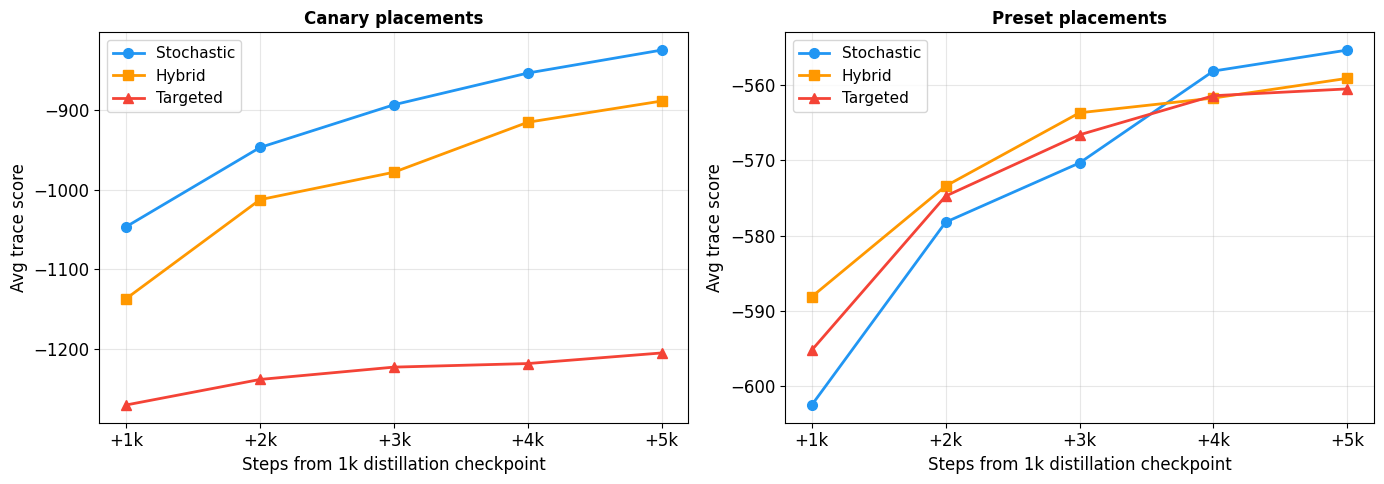
Figure 6: 0.5B regime ablation—targeted and hybrid training accelerate preset improvement but curtail out-of-preset generalization.
Benchmarking: Throughput–Quality Pareto Frontiers
Super Apriel’s key contribution is delineation of runtime operating points from a single checkpoint. On MATH500, AIME, GSM8K, MMLU, and several retrieval, code, tool-calling, and instruction-following dev and unseen benchmarks, recommended presets demonstrate:
- The all-FA preset matches teacher Apriel 1.6 across all tasks.
- Presets with as few as 0 FA / 16 SWA / 13 KDA / 19 GDN layers deliver 6.9× throughput at 81% quality retention, scaling to 10.7× at 77% retention.
- Quality degrades gracefully with increasing replacement of FA, task-sensitively; long-context retrieval degrades first as recurrent mixers erase long-range dependencies.
- For long context windows (32k tokens), throughput advantage of efficient placements compounds—Super Apriel achieves 80-155% additional speedup from 16k to 32k compared to 5–46% for external hybrids (Figure 7).
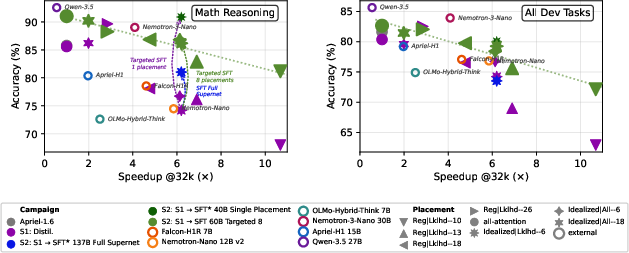
Figure 8: Placement-wise throughput–quality tradeoff and the effect of global, targeted, and single-placement SFT.
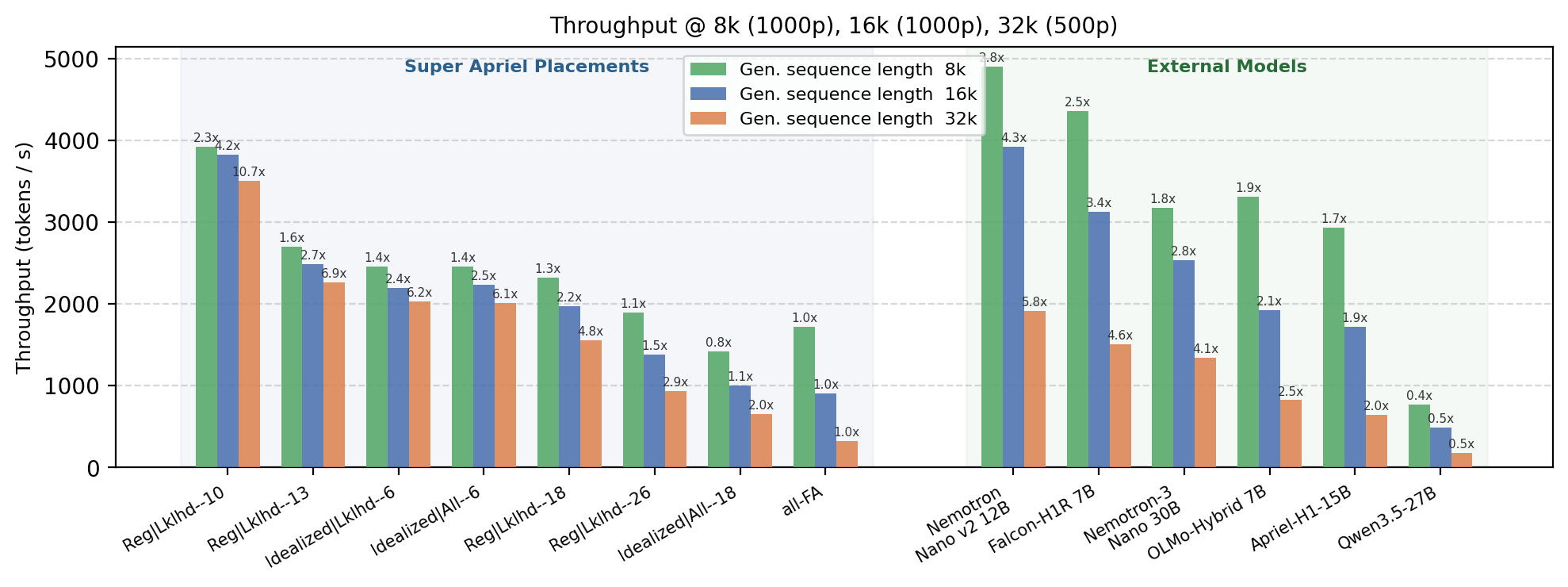
Figure 7: Placement and context-wise decode throughput for Super Apriel and external hybrid baselines: gains amplify with longer contexts.
Speculative Decoding: Shared Checkpoint, Many Drafts
A notable innovation enabled by the supernet is coherent speculative decoding without the need for a separate draft network. The all-FA preset serves as verifier; efficient placements (e.g., all-GDN) yield high acceptance rates and the highest speculative speedup, as Super Apriel mixers are co-trained and distributions remain aligned (Figure 9).
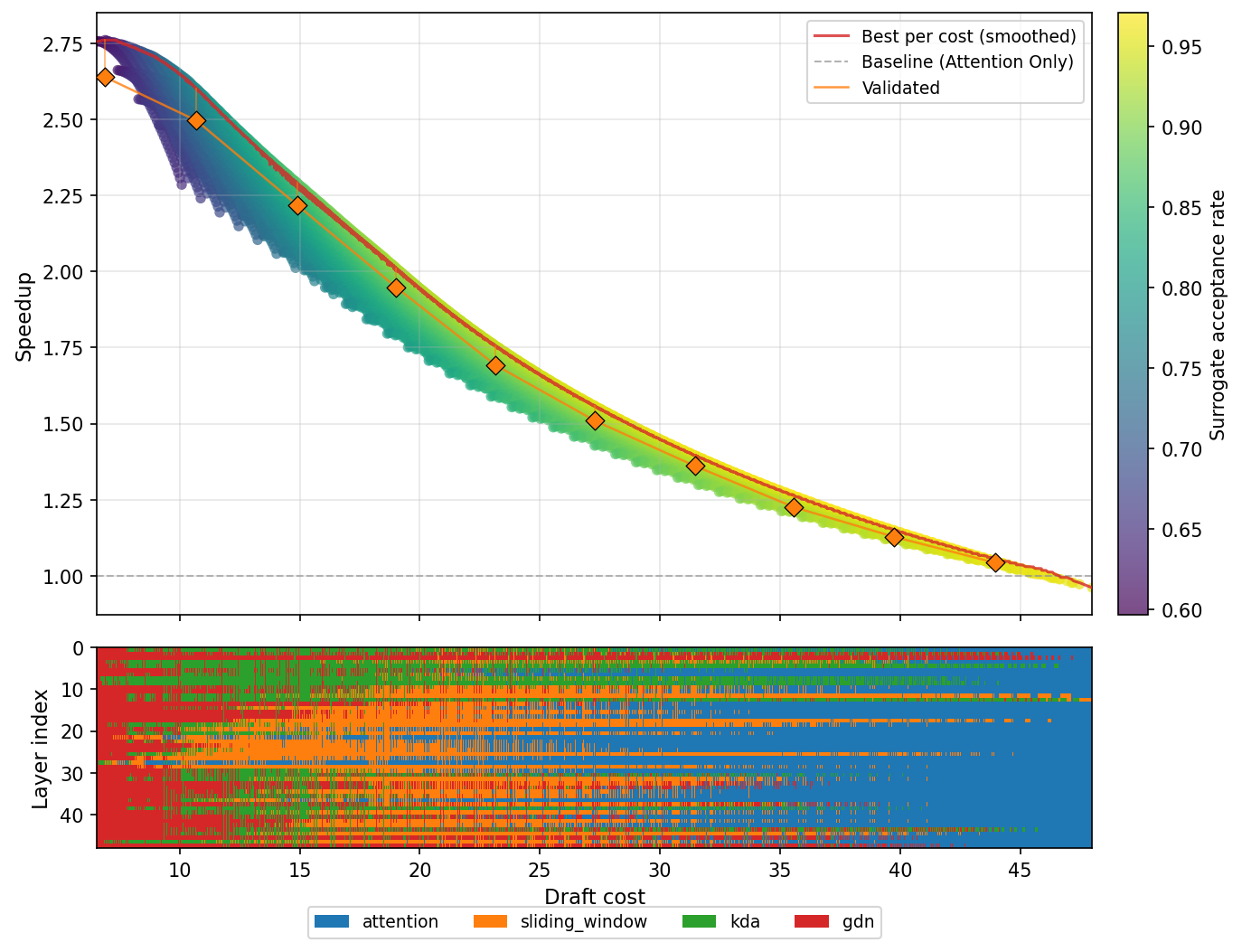
Figure 9: Speculative decoding efficiency—net speedup vs draft placement cost; optimal at cheapest (all-GDN) draft.
Implications and Future Directions
Super Apriel establishes that single-checkpoint, multi-placement supernets can dominate fixed-architecture hybrids in both practical deployment flexibility and raw speed/quality tradeoffs. Placement can be selected at runtime, without retraining or duplicating infrastructure, supporting:
- Workload-adaptive deployment: long-context tasks use efficient layouts, short prompts use FA-heavy layouts.
- Robust comparative benchmarking: quality-efficiency curves can be swept by configuration selection, not model re-train.
- Speculative decoding natively: all draft/target pairs share training, maximizing acceptance rates.
Methodologically, this work provides a blueprint for integrating NAS-style supernet training, robust cluster-expansion surrogate ranking, and cost-driven exact placement search. It also exposes the limitations of small-scale ablation for architectural policy and points toward an RL-finetuning stage to further refine frontier placements under deployment domain reward.
Key technical caveats include cost model fitness for singleton placements (impacted by current vLLM implementation idiosyncrasies) and the limitation to the Apriel 1.6 teacher; generalization to other architectures and inclusion of more aggressive mixers like Mamba-2 or Lightning Attention is underscored as future work.
Conclusion
Super Apriel embodies a new paradigm for flexible LLM deployment: from a single fully-trained supernet, practitioners can select or schedule placements at inference to maximize throughput and quality for each workload—shifting performance–cost tradeoff from a release-time artifact to a serving-time policy. Empirically, the approach surpasses external hybrids in scaling speedup with context, matches teacher quality, and allows Pareto frontier traversal from one checkpoint. Open-source release of weights and tooling further amplifies community impact and reproducibility.
Figure 1: Super Apriel’s supernet architecture and training pipeline.
Figure 2: Surrogate-guided placement optimization workflow.
Figure 3: 15B-presets Pareto frontier—layerwise mixer patterns at optimal tradeoffs.
Figure 4: Placement ranking convergence—most non-frontier placements stabilize rapidly.
Figure 5: Top-k overlap during training; majority of early top placements persist post-convergence.
Figure 6: Training regime ablations (0.5B)—preset performance as a function of regime.
Figure 8: Throughput-quality sweep for multiple SFT strategies and comparison to external hybrids.
Figure 7: Placement-specific throughput (tokens/sec) across context lengths.
Figure 9: Speculative decoding speedup on Super Apriel, optimal at the most efficient draft placement.
References
- OSTAPENKO et al., "Super Apriel: One Checkpoint, Many Speeds" (2604.19877)

