- The paper introduces Nemotron 3 Ultra, a 550B-parameter open MoE LLM leveraging a hybrid Mamba-Attention architecture optimized for long-context agentic reasoning.
- It employs advanced LatentMoE routing and multi-token prediction to enhance sparse expert capacity, boosting inference throughput up to 1.6× over competitors.
- The integrated post-training pipeline with MOPD and RLVR significantly improves agent performance, ethical decision-making, and inference stability.
Nemotron 3 Ultra (also referred to as Nemotron Nano 3 in the text) represents a significant large-scale advance in open Mixture-of-Experts (MoE) language modeling optimized for agentic, long-context, and efficient inference scenarios. The model combines an immense scale, hybrid Mamba-Attention backbone, advanced sparsity via LatentMoE, and an intricate post-training pipeline built for robust agentic decision making, tool use, and verifiable reasoning.
Model Architecture and Pretraining
Nemotron 3 Ultra leverages a 550B total parameter (55B active per token) MoE architecture that positions it at the vanguard of inference-aware design for open LLMs.
The core architectural choices include:
- Hybrid Mamba-Attention Backbone: Adopts Mamba state space layers interleaved with sparse global attention, providing linear-time scaling in decoding, strong long-context handling (up to 1M tokens), and reduced KV cache footprint.
- LatentMoE Routing: Employs LatentMoE to maximize expert capacity per FLOP/cost, activating 22 out of 512 experts per MoE layer, scaling sparsely, and trading hidden dimension width for number of experts.
- Multi-Token Prediction (MTP): Native support for speculative decoding to accelerate inference, with dedicated MTP heads tightly integrated (Figure 1).
The pretraining phase encompasses 20 trillion text tokens sourced from a high-quality and extensively filtered blend. Key innovations in data include very large-scale code refreshes, injection of synthetic multi-choice and generative QA spanning diverse domains, fact-seeking and moral scenarios, and sophisticated legal domain datasets. The data mixture is dynamically controlled via a two-phase curriculum focusing on diversity (phase 1) and quality (phase 2) (Figure 2).
Training is performed primarily in NVIDIA's NVFP4 precision, with selective high-precision retention in the final layers and sensitive projections, marking the largest stable NVFP4 training to date. Abrupt loss divergences were encountered and extensively characterized, leading to early termination at 20T tokens, demonstrating the persistent challenges in ultra-scale pretraining with sparse architectures.

Figure 1: Nemotron Nano 3 layer pattern employing a hybrid Mamba-Attention architecture sparsely scaled via LatentMoE layers.
Post-Training: SFT, RLVR, and MOPD
Supervised Fine-Tuning and RL
The post-training pipeline is designed for agentic and tool-use environments, extending beyond classic instruction SFT and RLHF recipes. After large-scale SFT focused on agentic, reasoning, safety, search, tool-use, code, math, and multilingual scenarios, Nemotron 3 Ultra undergoes unified RLVR (Reinforcement Learning with Verifiable Reward) across an expansive set of environments.
Multi-teacher On-Policy Distillation (MOPD)
A central innovation is an asynchronous, multi-iteration MOPD protocol, in which over ten domain-specialized teacher models (optimized for domains such as SWE, GDPVal, search, terminal use, safety, etc.) provide dense, token-level distillation signals on student rollouts. This iterative student–teacher co-evolution bridges the gap between generalist student and domain-optimized specialists while avoiding instability from multitask RL.
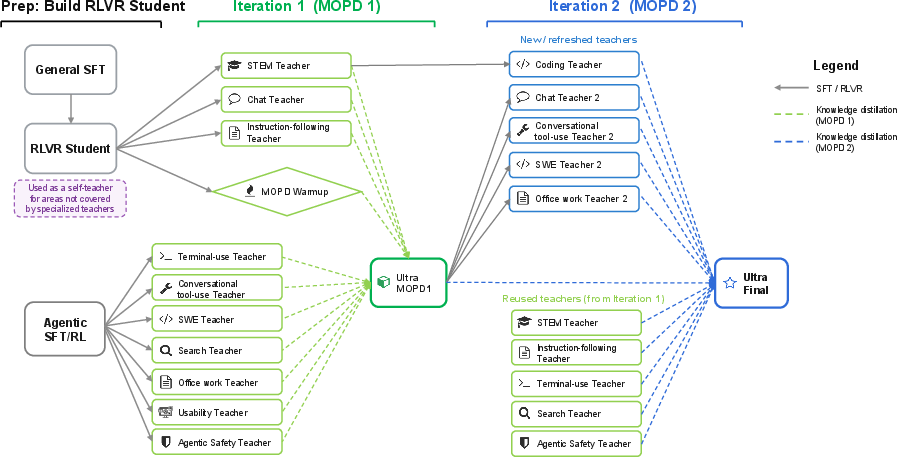
Figure 3: Two-iteration MOPD training pipeline for Nemotron Nano 3, showing iterative specialization and distillation from multiple teachers.
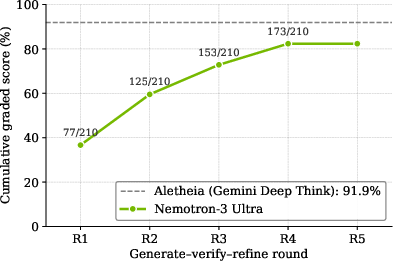
Ablations demonstrate MOPD closes the teacher–student gap by 70–90% in agentic domains; limitations appear primarily in single-turn reasoning domains where supervision via teacher disagreement is less effective. Warm-up SFT on the teacher's data distribution before MOPD measurably improves performance by mitigating distribution mismatch.
Quantization and Inference Optimization
Mixed Precision Quantization
The inference stack is deeply co-designed with hardware, using Model-Optimizer to quantize routed-expert weights to NVFP4 (FP4), shared experts and Mamba projections to FP8, and caches to FP16/FP8 depending on context, supported by tailored calibration schemes (Four-Over-Six and MSE-based scaling). The result is full compatibility with Blackwell GPU FP4 hardware math and highly memory-efficient deployment.
Cache size and memory considerations are pivotal—at moderate sequence lengths, the Mamba SSM cache can outstrip classic FP8 KV cache unless aggressively quantized and optimized with periodic checkpointing (Figures 14, 15).
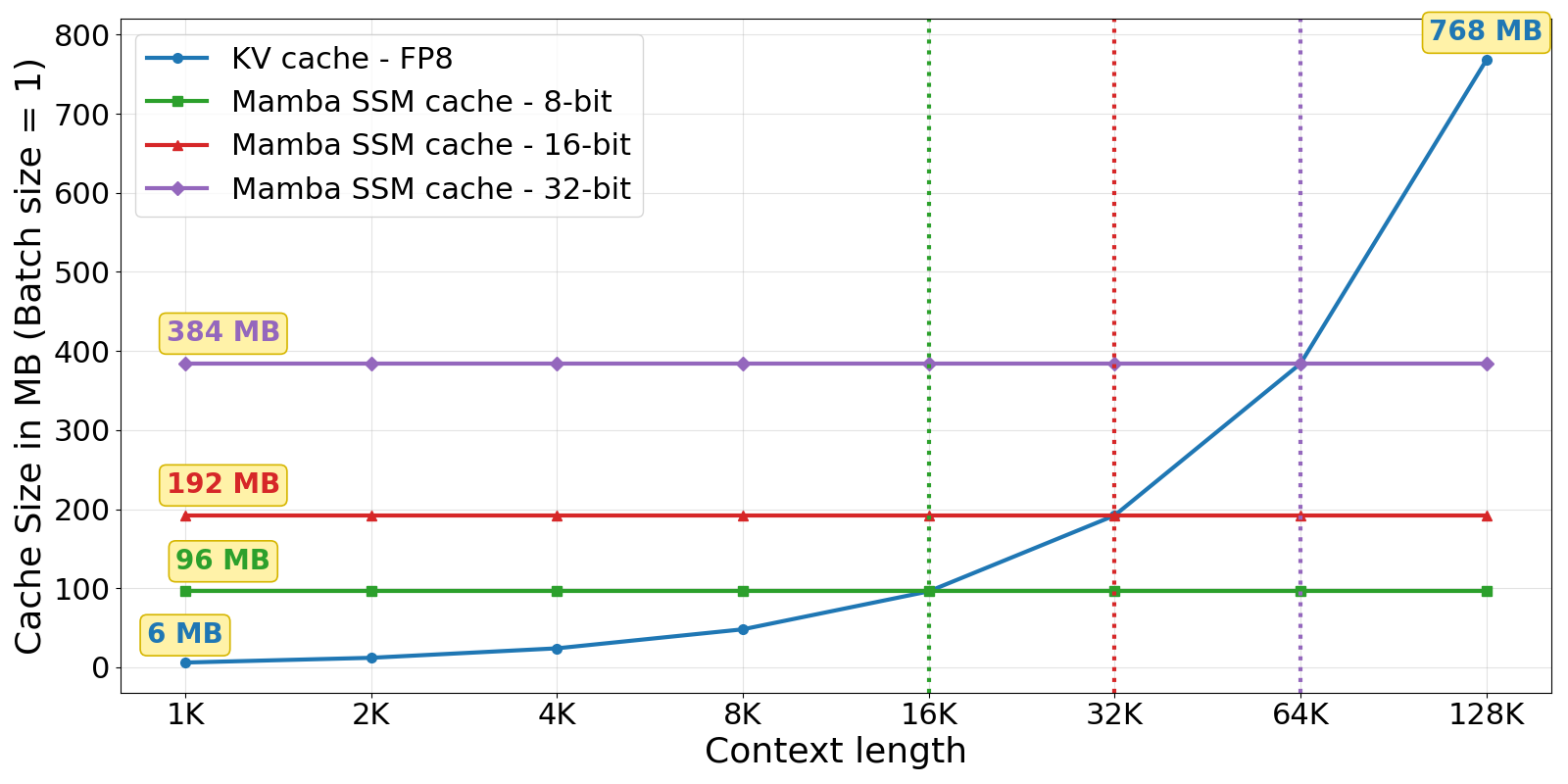
Figure 4: Cache size comparison for FP8 KV cache and Mamba SSM cache at different cache precisions.
Throughput and Serving Strategies
The hybrid Mamba-Attention + LatentMoE stack brings considerable inference benefits:
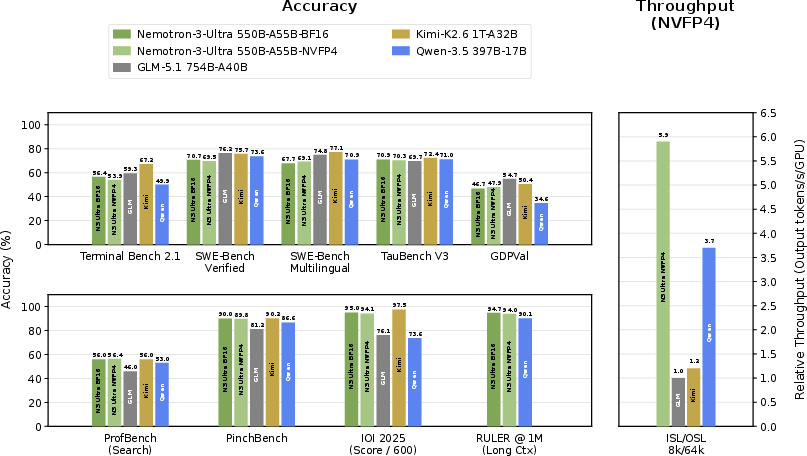
Agentic, Reasoning, and Long-Context Evaluation
Comprehensive benchmarking demonstrates Nemotron 3 Ultra's strong agentic, reasoning, and long-context performance:
Infrastructure and Scaling
The deployment of Nemotron 3 Ultra necessitated extensive infrastructure co-optimization:
- Ray GCS and Slurm Integration: Custom orchestration and node placement for efficient large-scale actor spawning and role assignment.
- NUMA and NVLink-Aware Placement: Precision placement to ensure expert parallelism and tensor parallelism maximize intra-node bandwidth.
- Optimized Caching and Initialization: JIT caches, container caching, and I/O minimization strategies reduced launch times at the scale of thousands of GPUs from nearly one hour to seconds.
- All-to-All Communication: Custom NVLinkOneSided and MoE chunking reduces MoE all-to-all bottlenecks.
Theoretical and Practical Implications
Nemotron 3 Ultra's release sets a new state-of-the-art in the public LLM space for agentic workloads, embedding design principles (hybrid Mamba-Attention, LatentMoE, MTP, and MOPD) that are likely to be foundational moving forward. The model's throughput scaling at sequence length and batch size makes it the preferred choice for long-running autonomous agents and ultra-long document reasoning. The rigorous analysis of training divergence, expert imbalance, and residual norm propagation at scale provides new insights into pretraining stability for sparse architectures.
The open-sourcing of all code, checkpoints (pre-trained, post-trained, quantized), and data cements Nemotron 3 Ultra as a platform for further research on scalable MoE architectures, inference acceleration, and agentic alignment.
Conclusion
Nemotron 3 Ultra demonstrates that highly-scaled, MoE hybrid LLMs can simultaneously deliver strong accuracy, agentic robustness, and unprecedented inference throughput by fundamentally co-designing architecture, data, training, quantization, and serving. This enables a new generation of open LLMs that are both efficient and reliable for the most demanding agentic workloads, setting a standard for future research and deployment in AI systems (2606.15007).