Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Abstract: We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Nemotron Nano 3, a new open-source AI LLM from NVIDIA. Its big idea is to be both smart and fast: it combines a “team of experts” design with two types of thinking engines to answer questions quickly without losing accuracy. It’s also trained to handle very long inputs (up to about book length) and to act more like a helpful “agent” that can plan, use tools, and solve multi-step tasks.
What the researchers wanted to achieve
In simple terms, the team aimed to:
- Keep answers as accurate as popular big models while making the model much faster.
- Use less compute and memory during use by activating only the parts of the model that are needed.
- Handle very long inputs (up to 1 million tokens).
- Improve “agentic” skills—things like multi-step reasoning, writing code, using tools, and working through tasks step by step.
- Train efficiently using small, compact number formats and share their models and datasets openly.
How they built and trained it (everyday explanation)
To reach those goals, they combined several ideas:
- “Team of experts” (Mixture of Experts, MoE): Imagine a big team where each member is a specialist. For every sentence the model reads, it picks a few specialists best suited to help and only asks them, not the whole team. This keeps the model efficient: it has 120 billion total parameters (think of them as knobs the model can adjust) but only about 12 billion are “active” at a time.
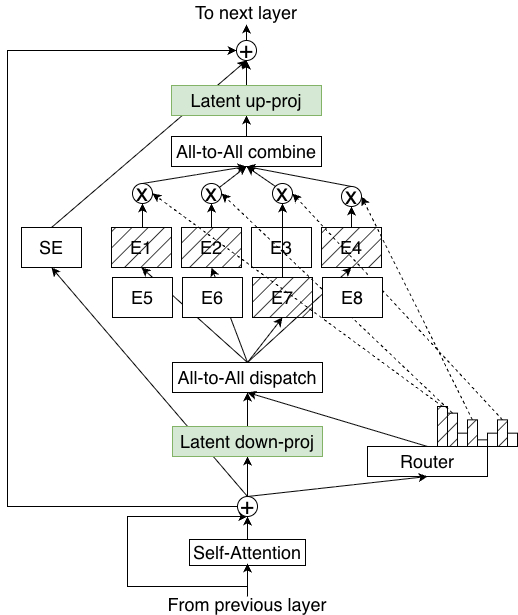
- LatentMoE (a smarter way to use experts): Before sending work to the specialists, the model compresses the information into a smaller space (like using a narrower hallway) so it’s faster and cheaper to pass around. After the specialists do their job, it expands the information back. Because it saves time and memory this way, the model can use more specialists and pick more of them per token—improving quality without slowing down.
- Hybrid Mamba + Attention:
- Attention (classic Transformer) is like a big group discussion where each word can “talk” to all other words. It’s powerful, but it gets slow for very long texts.
- Mamba is more like a fast conveyor belt that processes sequences efficiently with less memory.
- Nemotron Nano 3 mostly uses the fast conveyor belt (Mamba) and adds a few “global meetings” (attention layers) at key points so information can still flow across the whole text when needed. This keeps it quick and capable.
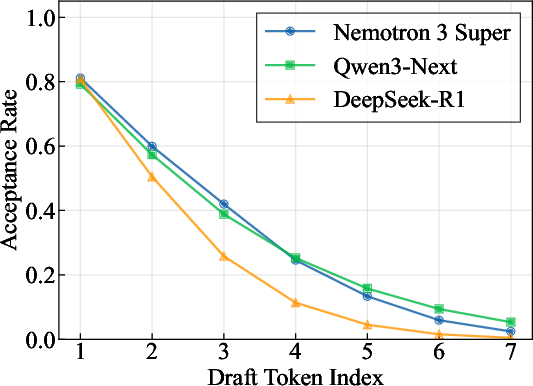
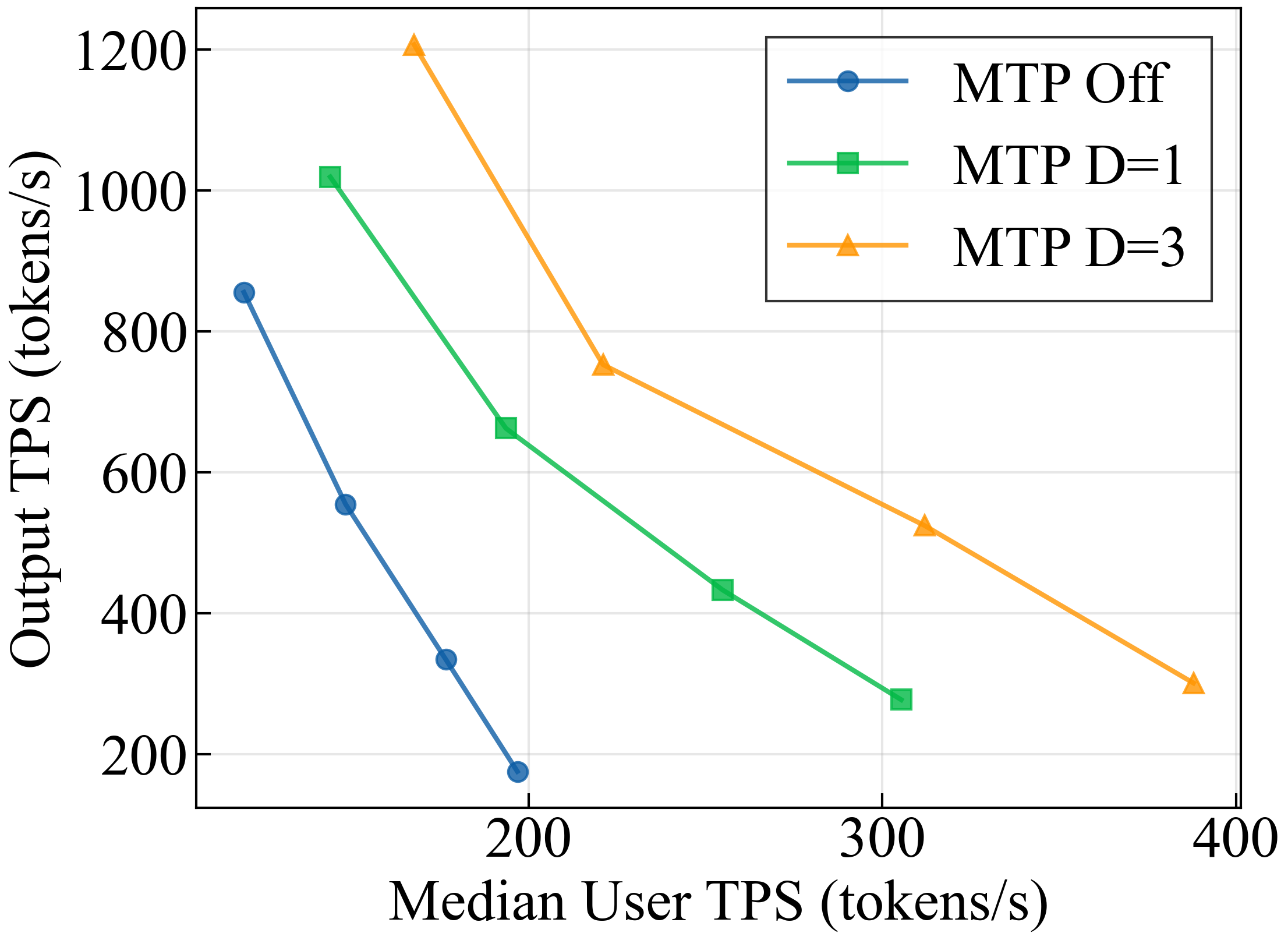
- Multi-Token Prediction (MTP) and speculative decoding: Instead of predicting one word at a time, the model learns to predict several words ahead and then quickly checks them—like drafting a few words and verifying them in a single go. This makes writing faster. Nemotron Nano 3 uses a shared prediction head that’s trained to be steady even when it feeds its own guesses back in, which helps the speed-up work for longer drafts.
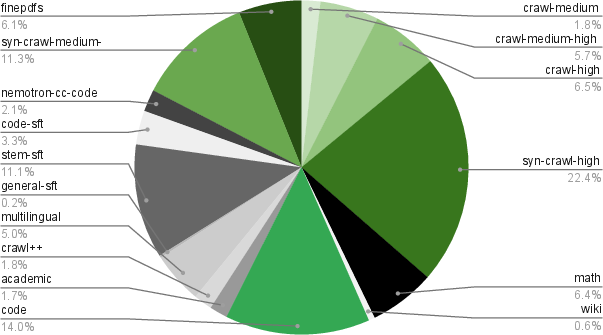
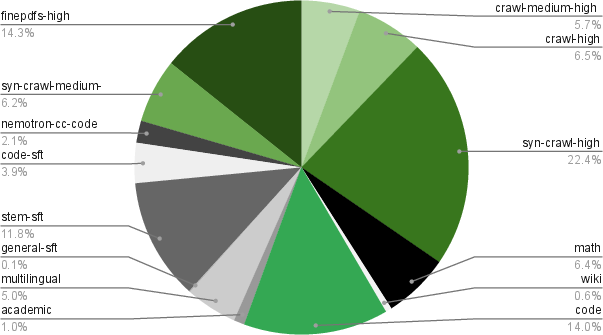
- Training efficiently with compact numbers (NVFP4): Computers store numbers with different levels of detail. NVFP4 is a very compact format that saves space and speeds up training. The team trained most of the model in this low-precision format and used higher precision only where it helped stability. They trained on a huge amount of text—about 25 trillion tokens—in two phases: first focused on diversity (lots of different sources), then on higher-quality data to polish skills.
- Teaching long memory: At the end, they added a special phase to teach the model to handle very long contexts (up to 1 million tokens), and then balanced that with shorter sequences so it stays good at math and other tasks.
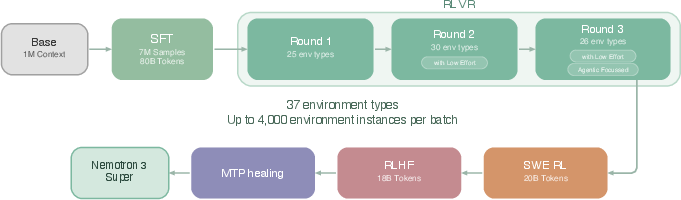
- Teaching “agent” skills: After pretraining, they used supervised fine-tuning and reinforcement learning (RL) with many tool-using and multi-step tasks. They improved their RL systems to be more robust and scalable so the model learns to plan, use tools, and solve harder problems.
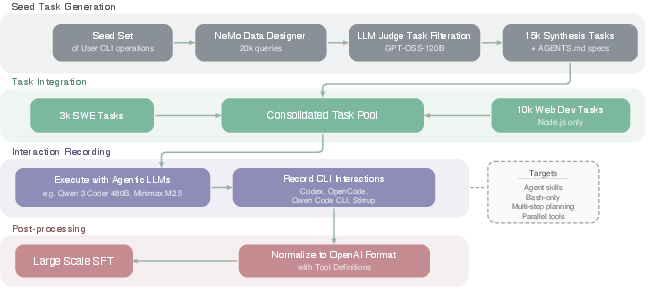
- Extra datasets to boost reasoning and coding: They created and cleaned large sets of synthetic problems and solutions in programming, logic, economics, and multiple-choice questions. They also checked for duplicates and leaks from popular benchmarks to keep training fair.
- Sharing: They released base and post-trained versions, plus quantized (compressed) versions for faster serving, and published datasets and training recipes so others can reproduce and build on the work.
What they found
Here’s what the paper reports:
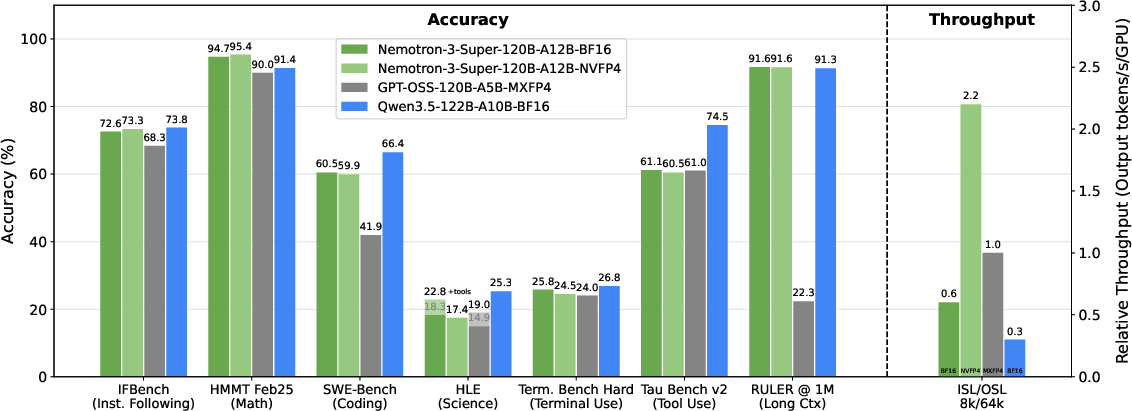
- Comparable accuracy, much higher speed: On popular benchmarks, Nemotron Nano 3 performs similarly to big-name 120B+ models but runs much faster. In one long-output test (8k input, 64k output), it achieved up to about 2.2× the throughput of one competitor model and about 7.5× that of another, as measured on NVIDIA’s newest GPUs.
- Very long context: It can handle inputs up to 1,000,000 tokens, which is useful for reading lengthy documents or working across many files.
- Strong “agentic” abilities: Thanks to extensive RL and tool-use training, it improves on tasks like software engineering, terminal usage, and general tool use.
- Multi-Token Prediction works well: The model’s built-in drafting-and-checking speeds up generation and maintains good acceptance rates (how many drafted tokens get approved), helping both speed and quality.
- Stable low-precision training: Training mostly in NVFP4 (very compact numbers) was stable across 25 trillion tokens. They carefully mixed in higher precision where needed and found that switching formats late in training didn’t noticeably improve final benchmark scores—so the low-precision plan was effective.
Why this matters
- Faster, cheaper AI at scale: Running large models is costly. Activating only the needed experts, using the Mamba+Attention hybrid, and drafting multiple tokens at once makes the model faster and more affordable to deploy.
- Handles long, real-world tasks: Being able to read and keep track of very long texts means the model can work across big documents, large codebases, or lengthy conversations without losing the thread.
- Better assistants and tools: Improved planning and tool-use mean smarter coding helpers, data analysts, and general-purpose AI agents that can break tasks into steps and get things done.
- Open resources for the community: By releasing models, data, and recipes, the work helps researchers and developers learn, test, and build improved systems more quickly.
- A path for future designs: LatentMoE shows how to co-design AI with hardware in mind—reducing memory and communication costs while keeping quality—pointing to a future where big models are both powerful and practical.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address.
- LatentMoE design space is under-explored:
- No ablations quantifying how latent dimension ℓ, the ratio d/ℓ, number of experts N, and top-K interact to shape accuracy, throughput, and memory across workloads and hardware.
- Lacking guidance on where LatentMoE layers should be placed in the stack and how many per block optimize quality vs. cost.
- Unclear robustness of routing and specialization in LatentMoE under distribution shift, long-horizon tasks, and very long contexts (e.g., expert collapse, churn, router entropy).
- Expert utilization and routing behavior are not reported:
- No metrics on token–expert load balance, capacity factor violations, token drops, or router entropy/temperature schedules at scale (K=22, N=512).
- Unclear whether experts meaningfully specialize by domain (code, math, multilingual), and how specialization evolves during training.
- Communication and scaling of MoE serving remain underspecified:
- Absence of sensitivity studies for all-to-all under different expert-parallel (EP) degrees, TP/PP/CP configurations, batch sizes, sequence lengths, and multi-node interconnects.
- No analysis of serving on heterogeneous interconnects (e.g., PCIe vs. NVLink/NVSwitch) and its impact on end-to-end latency.
- Hybrid Mamba–Attention architecture lacks ablation:
- No systematic study of the number/placement of attention “anchors” and their effect on long-range reasoning, retrieval, and long-context stability.
- Missing quantitative breakdown of memory/latency attributable to Mamba blocks vs. attention anchors, especially at 1M context.
- Long-context capability (up to 1M) is insufficiently evaluated:
- No benchmark results or failure analyses at 1M context (e.g., retrieval recall vs. distance, needle-in-a-haystack, cross-document QA, code navigation).
- After noticing math regressions post LC-phase, only an alternating 1M/4k schedule is mentioned—without quantitative results, scheduling ablations, or general guidance.
- Multi-Token Prediction (MTP) design is only partially validated:
- No ablation comparing shared-weight vs. independent-head MTP on both acceptance and downstream quality for varying draft depths.
- Acceptance is measured for a fixed draft length (7) and mostly unconditional settings; missing studies across temperatures, sampling strategies, batch sizes, and domain/task variability.
- No adaptive controller to tune draft depth based on real-time acceptance or tail-latency targets in multi-tenant serving.
- Throughput comparisons raise fairness and generality questions:
- Baselines use different precisions (MXFP4/BF16/FP8) and frameworks (vLLM/TRT-LLM), which can bias comparisons; apples-to-apples runs and standardized decoding/KV settings are missing.
- Results are confined to B200 hardware; portability to other accelerators/interconnects and framework configurations is untested.
- Minor hardware notation inconsistency (B200 vs. B300) needs clarification.
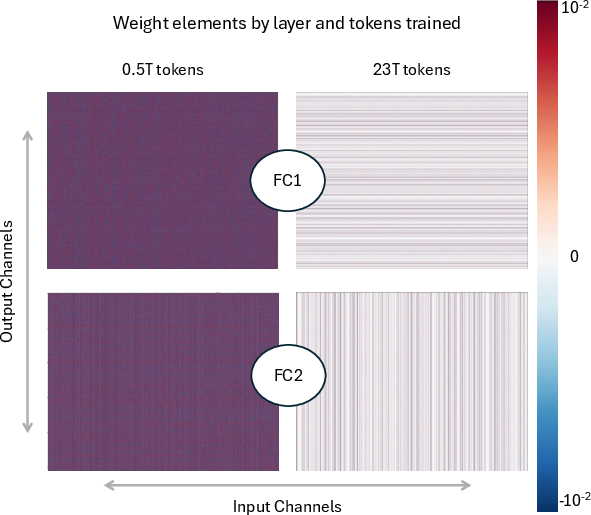
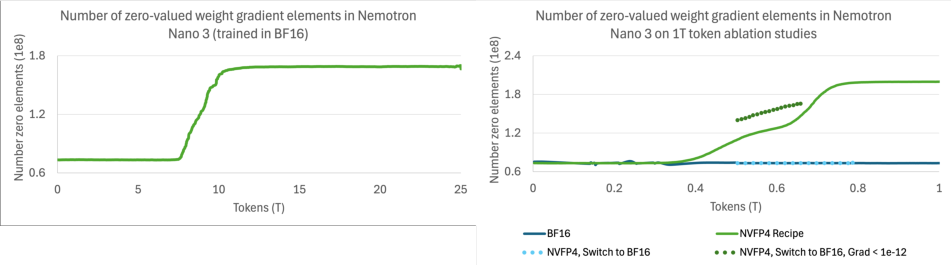
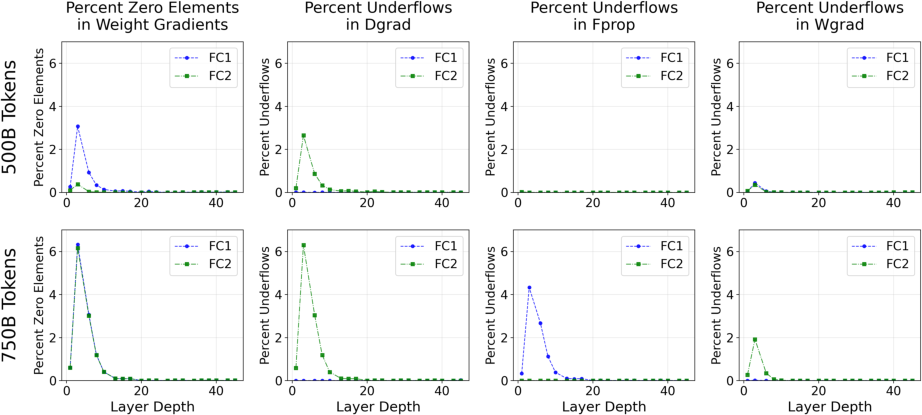
- NVFP4 pretraining underflows and emergent “dead channels” are not fully resolved:
- Impact of increased zero-valued gradients and channel magnitude patterns on generalization, safety, and domain performance is not quantified.
- Mitigations (e.g., alternative block sizes, per-channel scaling, dynamic scaling, mixed-precision per-tensor strategies, or routing-aware quantization) are not systematically explored.
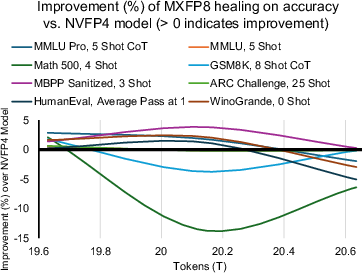
- Only one precision-switch experiment (to MXFP8 at 19T) is reported; earlier switch points, gradual/partial promotions, and adaptive schedules remain unexplored.
- Precision assignment by layer lacks ablation:
- Latent projections (BF16) and Mamba output projection (MXFP8) choices are motivated qualitatively; no systematic trade-off study vs. NVFP4 or alternative hybrids across quality/throughput.
- Quantization at inference is under-characterized:
- No accuracy deltas across NVFP4/FP8/BF16 for diverse tasks and sequence lengths; calibration procedures, outlier handling, and failure modes (e.g., rare-token or Mamba-state underflows) are not evaluated.
- Guidance for safe deployment thresholds (e.g., max draft depth under NVFP4) is absent.
- Checkpoint merging is only partially explored:
- Only minus-sqrt coefficients and fixed windows tested; alternative schemes (e.g., greedy soups, SWA, per-layer or expert-wise merges) and finer-grained checkpoint cadence remain open.
- MoE-specific issues (expert permutation mismatches, router drift across checkpoints) are not addressed.
- Agentic RL details and safety are insufficiently documented:
- The RL algorithm, reward design, off-policy corrections, exploration strategies, and stability controls are unspecified; no ablations linking each ingredient to observed gains.
- Reward model coverage, calibration, and robustness (e.g., reward hacking diagnostics) are not reported.
- Safety constraints during tool use (e.g., sandboxing, system prompt defenses) and post-RL safety evaluations are missing.
- Data governance and decontamination need expansion:
- Synthetic datasets rely heavily on model-generated content; broad decontamination is limited (e.g., code datasets decontaminated only against selected benchmarks).
- No human auditing or licensing analysis for web-derived and synthetic data; potential benchmark leakage and template overfitting risks persist.
- Tokenization choices and multilingual coverage, especially for long-context sequences and code, are not described.
- Multilingual capability is under-evaluated:
- Aside from a line in MTP acceptance, there is no systematic multilingual benchmarking (e.g., MGSM, XQuAD, XCOPA, long-context multilingual tasks), nor analysis of tokenization impacts on non-Latin scripts.
- Robustness and reliability remain largely untested:
- No evaluations for distribution shift, adversarial prompting, hallucination propensity, factuality/truthfulness (e.g., AdvBench, TruthfulQA), or failure analyses on long reasoning chains.
- Interaction between MTP speculative decoding and hallucination/consistency is not studied.
- Tool-use and SWE-Bench methodology lacks transparency:
- Limited details on environment determinism, tool configurations, budget/timeouts, and execution sandboxing; no transfer tests to unseen tools/repos or real-world workflows.
- Training/serving cost and sustainability are unreported:
- Missing reporting of total FLOPs, energy consumption, carbon footprint, and serving cost per 1k tokens under different precisions and draft depths.
- Component attribution is unclear:
- Combined improvements arise from LatentMoE, MTP, hybrid Mamba–Attention, data mixture, and LC-phase; controlled ablations isolating each component’s contribution to accuracy and throughput are absent.
- Scalability guidance is missing:
- No projections or experiments on scaling the design beyond 120B total (or to smaller edge models), varying active budgets, or changing K and N under different deployment targets.
- Curriculum and mixture sensitivity are not analyzed:
- Phase 1/2 blends are shown without sensitivity studies of mixture weights, ordering, or synthetic-vs-real ratios; optimal curricula for math, code, safety, and multilingual balance are unknown.
- Serving in production contexts is under-specified:
- No end-to-end queueing/tail-latency analysis under multi-tenant load with speculative decoding; admission control and adaptive scheduling policies (e.g., dynamic D, batch shaping) remain unexplored.
- Failure analyses are missing:
- No qualitative studies of long-context errors, speculative decoding rejection cascades, or NVFP4-induced sparsity patterns to guide future mitigation strategies.
- Reproducibility gaps:
- Precise compute budget, wall-clock, and parallelism topology for the full pretraining/RL runs are not comprehensively reported; seeds, checkpoint cadence, and exact evaluation harness configs for throughput are not fully specified.
Glossary
- Accuracy per FLOP: Model performance normalized by the number of floating-point operations required. "optimizes for both accuracy per FLOP and accuracy per parameter"
- Accuracy per parameter: Model performance normalized by the number of parameters, reflecting memory and bandwidth efficiency. "optimizes for both accuracy per FLOP and accuracy per parameter"
- All-to-all routing: A distributed communication pattern where token representations are sent to experts across devices, requiring all-to-all exchanges. "In throughput-oriented serving, distributed MoE inference is dominated by all-to-all routing."
- Autoregressive drafting: Recursively generating draft tokens using the same prediction head to enable longer speculative sequences. "improves robustness to the self-generated hidden states encountered during autoregressive drafting."
- Auxiliary-loss-free load balancing: Balancing expert utilization without using a traditional auxiliary load-balancing loss, often via adaptive routing adjustments. "we adopted an auxiliary-loss-free load balancing strategy~\citep{wang2024auxiliary, deepseekai2025deepseekv3technicalreport} with an update rate of "
- BF16: Bfloat16, a 16-bit floating-point format used to improve training stability and dynamic range over lower-precision formats. "The BF16 model still contains many small-magnitude gradients (<1e-12), but NVFP4 quantization underflows these values to zero."
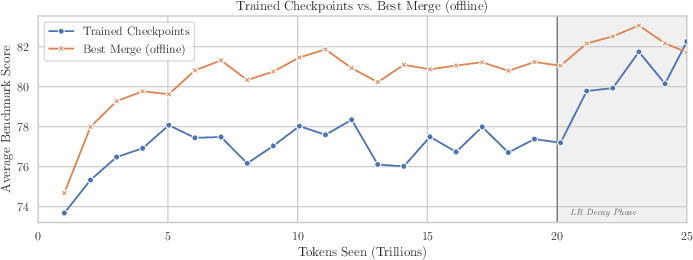
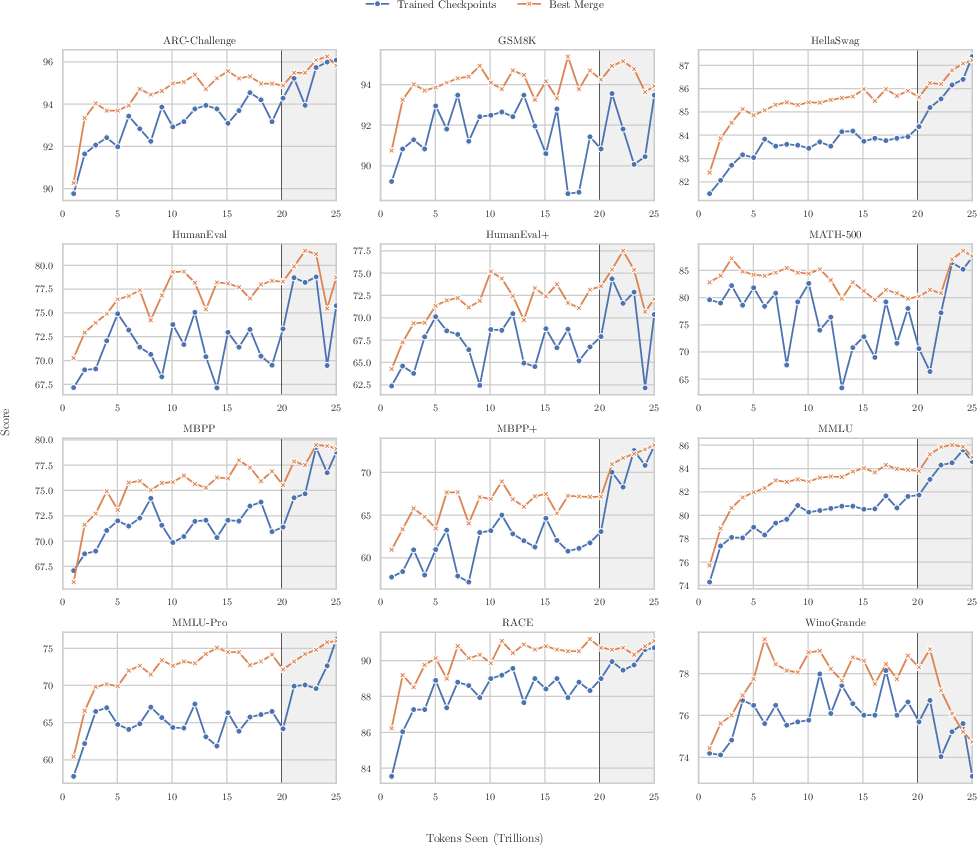
- Checkpoint merging: Averaging weights from multiple recent checkpoints to create a stronger evaluation model without extra training. "we apply checkpoint merging (weighted averaging over a sliding window of recent checkpoints) to produce stronger readouts of model quality"
- Context parallelism: Parallelization strategy that splits long sequences across devices to handle large context windows efficiently. "We used 64-way context parallelism"
- Continuous pretraining (CPT): Further pretraining on additional data or objectives to extend capabilities such as long-context handling. "we performed continuous pretraining (CPT) to equip the base model with long-context ability."
- Down-projection: A learned linear mapping that reduces hidden dimensionality before expert computation or routing. "via a learnable down-projection matrix ."
- E2M1: A low-precision floating-point element format with 2 exponent bits and 1 mantissa bit. "The NVFP4 format utilizes an E2M1 element format"
- E4M3: An FP8-like format with 4 exponent bits and 3 mantissa bits, often used for per-block scaling. "E4M3 micro-block scaling factors"
- Effective feature rank: The minimal representational dimensionality required by a task before quality collapses if reduced further. "A task-specific effective feature rank $r_{\mathrm{eff}$ imposes a lower limit on how much can be reduced"
- Expert biasing: Adjusting the router’s preferences to encourage balanced expert usage. "We utilized a sigmoid router score function complemented by expert biasing."
- Expert parallelism: Distributing experts across multiple devices to scale MoE models. "and 64-way expert parallelism to train on GB200 GPUs."
- FP8 KV-Cache: Storing attention key/value cache tensors in 8-bit floating-point to reduce memory and bandwidth. "For GPT-OSS-120B we use MXFP4 weights, MXFP8 activations, and FP8 KV-Cache; for Qwen3.5-122B we use BF16."
- GEMM: General Matrix-Matrix Multiplication, the core linear algebra operation for neural network layers. "NVFP4 GEMM kernels provided by Transformer Engine with the cuBLAS backend"
- Grouped-Query Attention (GQA): An attention variant with many query heads sharing a smaller number of key/value heads to reduce memory cost. "The attention layers employ Grouped-Query Attention (GQA) with 32 query heads and 2 KV heads (head dimension 128)."
- KV cache: Cached keys and values from attention layers used to speed up autoregressive generation, which grows with sequence length. "The primary systems bottleneck in modern sequence models is the quadratic growth of the KV cache in self-attention layers."
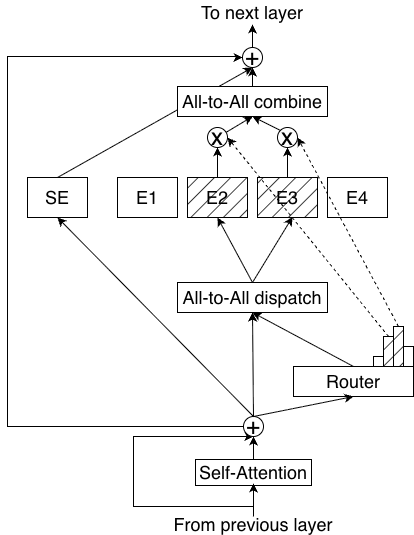
- Latent dimension: A reduced-dimensional space used for routing and expert computation to cut compute and communication costs. "tokens are projected from the hidden dimension into a smaller latent dimension for routing and expert computation"
- LatentMoE: An MoE architecture that performs routing and expert computation in a lower-dimensional latent space to improve efficiency. "Nemotron Nano 3 is our first model to use LatentMoE"
- Load balancing loss: A regularization term that penalizes uneven expert usage to ensure balanced routing. "paired with a standard load balancing loss with coefficient of "
- Mamba-2: A state-space model architecture enabling efficient, linear-time sequence modeling with constant-size state during generation. "we predominantly utilize Mamba-2 blocks~\citep{dao2024transformersssmsgeneralizedmodels}, which operate with a constant-sized state during generation"
- Micro-block scaling factors: Per-micro-block scaling values used during quantization to maintain numerical fidelity. "E4M3 micro-block scaling factors"
- Minus-sqrt decay: A learning rate decay schedule that follows a negative square-root curve. "we implemented a minus-sqrt decay schedule"
- Mixture-of-Experts (MoE): An architecture with many expert sub-networks where a router selects a subset per token, increasing capacity at fixed compute. "Mixture-of-Experts (MoE) architectures have emerged as a promising approach to maximize accuracy under fixed inference cost"
- MXFP8: A mixed-precision FP8 format used during training or fine-tuning to improve stability over lower-precision formats. "We promoted all tensors to MXFP8 at 19T tokens"
- NVFP4: NVIDIA’s 4-bit floating-point quantization format for weights, activations, and gradients enabling low-precision training. "Nemotron 3 Super was trained with the NVFP4 pretraining recipe"
- Pareto frontier: The set of operating points representing optimal trade-offs (e.g., between latency and throughput). "significantly shifts the throughput--latency Pareto frontier"
- Random Hadamard Transforms (RHTs): Orthogonal transforms applied to inputs to stabilize low-precision gradient computations. "Random Hadamard Transforms (RHTs) are performed on inputs to wgrad"
- RMSNorm: Root Mean Square Layer Normalization, a variant without learned mean/variance normalization. "use RMSNorm for normalization"
- Routing gate (gating network): The component that assigns tokens to experts based on learned scores. "all non-routed computations---including the routing gate (gating network), shared expert computation, and non-expert layers---remain in the full hidden dimension "
- Sharding: Partitioning model parameters across devices to enable distributed training and inference. "and sharding overhead."
- Sigmoid router score function: A gating mechanism that uses sigmoid-transformed scores to determine expert assignments. "We utilized a sigmoid router score function complemented by expert biasing."
- SPEED-Bench: A benchmark designed to evaluate speculative decoding performance and acceptance. "We evaluate MTP quality using SPEED-Bench~\citep{speedbenchnvidia}, a benchmark tailored for speculative decoding."
- Speculative decoding: An inference method where draft tokens are proposed and then verified by the main model to reduce latency. "enables native speculative decoding."
- Stochastic rounding: A probabilistic rounding scheme that reduces bias in low-precision arithmetic. "stochastic rounding is applied to gradient tensors."
- Tensor parallelism: Splitting tensor operations across devices to scale model training/inference. "2-way tensor parallelism"
- Top-22 routing: Selecting the 22 experts with highest scores per token for computation in each MoE layer. "We utilized a sigmoid router score function complemented by expert biasing. ... with 512 total experts and a top-22 routing mechanism ()."
- TRT-LLM: NVIDIA’s TensorRT-LLM inference framework optimized for high-throughput, low-latency LLM serving. "We measured throughput on B200 GPUs with vLLM and TRT-LLM and use the best out of the two frameworks for each model."
- Up-projection: A learned linear mapping that restores reduced latent representations back to the full hidden dimensionality. "projected back to dimension via a learnable up-projection matrix ."
- vLLM: A high-throughput LLM serving engine optimized for fast inference. "We measured throughput on B200 GPUs with vLLM and TRT-LLM and use the best out of the two frameworks for each model."
- Warmup-Stable-Decay (WSD): A learning rate schedule with an initial warmup, a plateau at peak LR, and a final decay phase. "The pretraining of Nemotron 3 Super 120B-A12B Base was conducted using a Warmup-Stable-Decay (WSD)~\citep{hu2024minicpm} learning rate schedule"
Practical Applications
Practical Applications Derived from Nemotron Nano 3
Nemotron Nano 3 combines a hybrid Mamba–Attention architecture, LatentMoE, and Multi-Token Prediction (MTP) trained with NVFP4 to deliver high-throughput, long-context, tool-using (agentic) capabilities. Below are actionable applications and workflows enabled by these findings, methods, and released assets.
Immediate Applications
These can be deployed now using the released checkpoints, datasets, and supported inference/training stacks.
- High-throughput long-form assistants for enterprises
- Sector: software, customer support, media, legal, finance
- What: Replace 120B-class dense models with Nemotron Nano 3 to handle long outputs (e.g., report generation, multi-step explanations) at lower latency and higher TPS (up to 2.2× vs GPT-OSS-120B and 7.5× vs Qwen3.5-122B on 8k-in/64k-out).
- Tools/workflows: TRT-LLM or vLLM serving; NVFP4/FP8 quantized checkpoints on NVIDIA B200/B300/GB200 GPUs; enable MTP for speculative decoding; batching via speed/latency Pareto tuning.
- Assumptions/dependencies: Access to NVIDIA Blackwell-class GPUs; framework versions supporting Mamba-2 and MoE; operational networking for all-to-all routing.
- Extreme long-context document QA and analysis (up to 1M tokens)
- Sector: legal, finance, research, government, enterprise knowledge management
- What: Ingest and reason over entire contracts, financial filings, research corpora, or complex SOPs without aggressive chunking.
- Tools/workflows: Long-context inference pipelines; hybrid Mamba reduces KV cache footprint during generation; optional alternating short- and long-context serving profiles.
- Assumptions/dependencies: GPU memory and scheduler support for ultra-long contexts; careful prompt budgeting; data governance/privacy controls.
- Code-assistant and software repair agents with tool use
- Sector: software engineering, DevOps, IT operations
- What: Leverage scaled RL on tool use and strong SWE-Bench performance for autonomous code edits, PR suggestions, test augmentation, and CLI/terminal automation.
- Tools/workflows: Integrate with OpenHands-like harnesses; enable function-calling and shell tools; CI bots for regression fixes and refactoring.
- Assumptions/dependencies: Secure sandboxes for code execution; approval workflows and guardrails; repository access permissions.
- Low-latency chat and interactive assistants via native speculative decoding
- Sector: customer support, product onboarding, coding help, operations copilots
- What: Use MTP’s shared-head speculative decoding to cut end-to-end latency without an external draft model, especially at small-to-medium batch sizes.
- Tools/workflows: Activate MTP (draft depth 1–3) in TRT-LLM; monitor acceptance lengths by domain (coding, math, RAG, etc.).
- Assumptions/dependencies: Integration correctness for acceptance/verification loop; domain-dependent acceptance variability.
- Cost- and energy-efficient pretraining/finetuning using NVFP4
- Sector: AI labs, model R&D groups (industry and academia)
- What: Reduce training FLOPs/energy by adopting NVFP4 GEMM kernels with targeted BF16/MXFP8 exceptions for stability-critical layers.
- Tools/workflows: Transformer Engine with cuBLAS backend; NVFP4 quantization of weights/activations/gradients; use the paper’s precision map.
- Assumptions/dependencies: Hardware support for NVFP4; monitoring for gradient underflows; selective BF16 for attention/MTP/latents as described.
- Rapid capability enhancement via open synthetic datasets
- Sector: education (EdTech), coding platforms, LLM fine-tuning providers
- What: Use released datasets (code concepts, algorithmic coding, formal logic, economics, MCQ with rationales) to improve reasoning and coding.
- Tools/workflows: Targeted post-training for specific skills; curriculum-style fine-tuning; educational content generation (quizzes, walkthroughs).
- Assumptions/dependencies: Alignment with licensing; decontamination and bias checks when combining with proprietary data.
- Efficient MoE-serving adoption through LatentMoE design
- Sector: model infrastructure, inference platforms
- What: Reuse LatentMoE patterns to reduce routed-parameter loads/all-to-all traffic (operate experts in a compressed latent space) for better accuracy per byte and per FLOP.
- Tools/workflows: Implement latent down-/up-projections; tune K and number of experts within bandwidth constraints; exploit expert parallelism.
- Assumptions/dependencies: MoE-aware runtimes (all-to-all optimized); profiling to select latent dimension vs. K/N trade-offs.
- RLHF/RM pipelines using released GenRM and RL environments
- Sector: alignment research, applied ML teams, policy labs
- What: Build or refine RLHF loops (rewards, preference modeling) for better multi-step tool-using behavior.
- Tools/workflows: Incorporate Qwen3-Nemotron GenRM for reward modeling; use released SFT/RL environments; asynchronous RL infrastructures.
- Assumptions/dependencies: High-quality preference data; safety/controllability in long-horizon tasks; compute for RL.
- Long-form content summarization and RAG at enterprise scale
- Sector: knowledge management, media, consulting, research
- What: Summarize large corpora, produce executive briefings, or enhance RAG by embedding more source material directly into the context.
- Tools/workflows: Hybrid long-context RAG (larger context + retrieval); memory-efficient decoding (Mamba).
- Assumptions/dependencies: Latency/throughput trade-offs; relevance filtering remains important even with large contexts.
- Training pipeline optimization via checkpoint merging for evaluation
- Sector: AI labs, MLOps for foundation models
- What: Use sliding-window checkpoint merging to obtain smoother “readouts” of quality in constant-LR phases, reducing the need for separate decay runs.
- Tools/workflows: Minus-sqrt decay emulation for merge coefficients; evaluate best-of-three window sizes (125B/250B/500B tokens).
- Assumptions/dependencies: Most effective on shorter annealing horizons; verify against downstream benchmarks; not a replacement for final decay at longer horizons.
- Quantized deployment to reduce memory/serve costs
- Sector: SaaS platforms, cloud providers, enterprise IT
- What: Use NVFP4 and FP8 inference checkpoints to lower memory footprint while maintaining quality; batch interactive workloads efficiently.
- Tools/workflows: TRT-LLM quantized kernels; mixed-precision KV-cache (e.g., FP8).
- Assumptions/dependencies: Quantization-aware serving; minor accuracy drift acceptable; hardware support for formats.
- Sector-specific long-context workflows
- Healthcare: longitudinal EHR summarization and protocol analysis (non-diagnostic decision support).
- Finance: analyzing 10-Ks, earnings calls, and risk/compliance documentation.
- Legal: full-contract review, clause extraction, and change tracking across versions.
- Education: persistent student-learning histories for truly personalized tutoring.
- Tools/workflows: Secure data connectors; permissioned data lakes; audit logs and human-in-the-loop review.
- Assumptions/dependencies: Regulatory compliance (HIPAA, SOX/SEC, GDPR); human oversight for critical decisions.
Long-Term Applications
These require further research, scaling, validation, or productization beyond what’s released.
- Trustworthy autonomous multi-tool agents for enterprise workflows
- Sector: software, IT operations, back-office automation
- What: End-to-end agents that plan, execute, and verify complex tasks across codebases, terminals, internal APIs, and ticketing systems.
- Dependencies: Robust safety/guardrails, formal verification of actions, improved long-horizon RL; enterprise sandboxing; provenance-aware auditing.
- Multimodal LatentMoE for efficient large-capacity vision/audio–language systems
- Sector: robotics, healthcare imaging, media analytics
- What: Extend hardware-aware latent expert routing to multimodal encoders/decoders for better accuracy per bandwidth in multimodal tasks.
- Dependencies: Co-design of routing across modalities; efficient multimodal all-to-all; dataset availability and licensing.
- On-device/edge deployment via distillation/pruning + NVFP4/Mamba
- Sector: embedded, mobile, autonomous systems
- What: Distill the 12B-active architecture into smaller hybrids that retain MTP and long-context behavior for edge hardware.
- Dependencies: Aggressive compression research; memory-aware decoding; specialized hardware kernels for Mamba/MoE.
- Full replacement of heavy RAG with massive-context processing
- Sector: enterprise search, business intelligence
- What: Shift from retrieval latency and index management to direct long-context reasoning when feasible.
- Dependencies: Memory scaling, scheduling, and cost models that favor giant contexts; continued advances in long-context inference stability.
- Standardized low-precision pretraining at scale (NVFP4 as a norm)
- Sector: AI labs, cloud training providers, sustainability initiatives
- What: Industry-wide adoption of NVFP4-like schemes to reduce energy and costs while maintaining quality.
- Dependencies: Broader hardware support; automated precision policies to avoid underflows (e.g., adaptive BF16 fallbacks); community benchmarks.
- Improved speculative decoding frameworks for large-batch MoE serving
- Sector: inference platforms, real-time assistants
- What: Generalize shared-head MTP to maintain high acceptance at longer drafts and with larger batches, integrating with batching schedulers.
- Dependencies: Deeper theory/metrics on acceptance vs. quality; jointly optimized batching and speculative policies.
- Domain-safe long-context healthcare and legal copilots
- Sector: healthcare, legal services
- What: High-stakes assistants operating over full records or contracts with transparent reasoning and calibrated uncertainty.
- Dependencies: Regulatory approval pathways, rigorous clinical/legal validation, data privacy-by-design, adversarial robustness.
- Curriculum design tools and assessments powered by synthetic data pipelines
- Sector: education, test prep, workforce upskilling
- What: Automated generation of calibrated, diverse problem banks (coding, economics, logic) aligned to standards and adaptive difficulty.
- Dependencies: Human review loops; bias mitigation; alignment with curriculum standards; psychometric validation.
- Finance-grade drafting and audit copilots
- Sector: finance, audit, compliance
- What: Drafting of regulatory disclosures and audit workpapers from long-context corpora with line-by-line justification and traceability.
- Dependencies: Explainability and provenance tooling; strict compliance controls; human sign-off mechanisms.
- Robust checkpoint-merging strategies as routine training control
- Sector: AI labs, foundation-model training platforms
- What: Generalize merge schedules and granularity to long decay phases and different architectures for consistent quality tracking and potential gains.
- Dependencies: Empirical exploration of coefficient schemes and save intervals; tooling baked into MLOps platforms.
- Green-AI policy benchmarks and certifications leveraging low-precision and efficient routing
- Sector: policy, standards bodies, sustainability
- What: Define and certify energy-efficiency practices (NVFP4, LatentMoE) as best-practice baselines for large-model training and serving.
- Dependencies: Transparent energy accounting; consensus metrics; industry adoption.
- Safety-first agent sandboxes and governance for tool-executing LLMs
- Sector: cybersecurity, enterprise IT governance
- What: Standardized execution sandboxes, least-privilege credentials, and policy engines for LLM agents that manipulate real systems.
- Dependencies: Security frameworks and off-the-shelf guardrails; action provenance and rollback; red-teaming of agent policies.
Notes on Feasibility and Dependencies
- Hardware/software stack: Best results assume NVIDIA Blackwell GPUs (B200/B300/GB200), MoE-all-to-all–capable interconnects, and up-to-date TRT-LLM/vLLM with Mamba-2, MoE, long-context, and MTP support.
- Precision management: NVFP4 training requires careful mixed-precision policies to avoid underflows; the paper’s layer-specific precision map should be followed.
- Data governance: Long-context and enterprise applications must enforce privacy, consent, and data residency.
- Safety and oversight: Agentic use cases need sandboxing, approval workflows, and human-in-the-loop verification, especially in high-stakes domains.
- Licensing and provenance: Use released weights and datasets under their respective licenses; assess synthetic data biases and domain coverage before deployment.
Collections
Sign up for free to add this paper to one or more collections.