NVIDIA Nemotron 3: Efficient and Open Intelligence
Abstract: We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces NVIDIA Nemotron 3, a new family of AI LLMs designed to be both very accurate and very fast. There are three sizes:
- Nano (smallest and most cost-efficient),
- Super (mid-size, built for busy, real-world tasks like IT ticket automation),
- Ultra (largest and most accurate for tough reasoning).
These models are “open,” meaning NVIDIA plans to release the model weights (the learned parameters), software, training recipes, and most of the data they used—so others can study, improve, and use them.
Key Questions the Paper Answers
- How can we make AI models that think well and respond quickly?
- How can we handle very long inputs (like huge codebases or long chats) without slowing down or breaking?
- How do we train models to use tools, solve math problems, write code, and follow instructions—all at once—without losing skills?
- Can we give users control over how much “thinking” the model does to balance speed and accuracy?
How the Models Work and Were Trained
To keep this simple, think of the model as a smart team working together with different roles. Here are the main ideas:
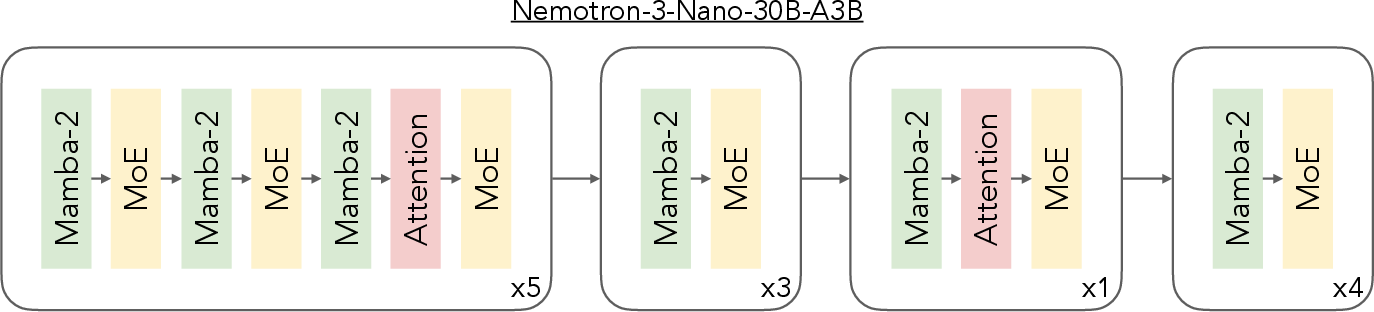
Hybrid MoE (Mixture-of-Experts) with Mamba and Transformer
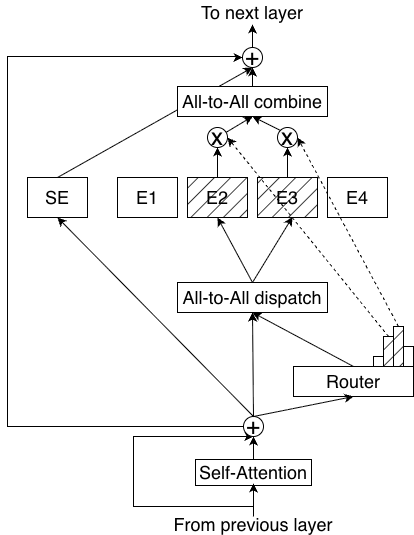
- Mixture-of-Experts (MoE): Imagine a team of specialists. For each piece of text (called a “token”), a router picks a few experts best suited to handle it. This makes the model smarter without making every part work on everything.
- Transformer attention: Like reading all previous notes to decide the next word—powerful but can be slow when the conversation gets long.
- Mamba-2 layers: Like keeping a compact running summary instead of rereading everything—much faster for long sequences.
Nemotron 3 mixes these: mostly MoE + Mamba-2 (fast), with a few attention layers (for high-quality “all-to-all” connections). This combo boosts accuracy while staying fast, especially for long reasoning tasks.
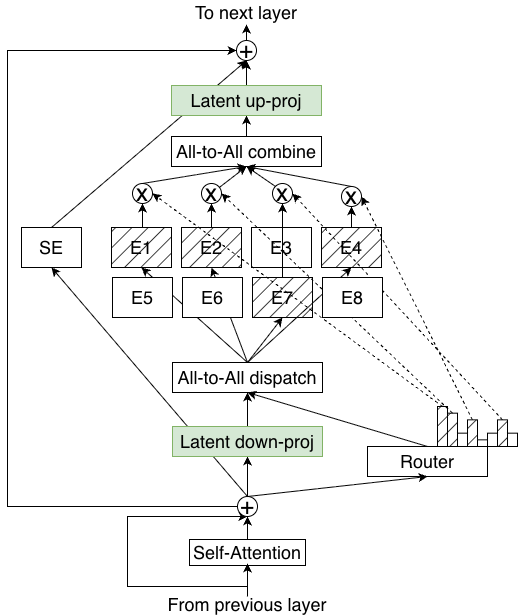
LatentMoE (A smarter way to use experts)
- In standard MoE, routing tokens to experts can be slow because each expert sees full-sized information.
- LatentMoE compresses tokens into a smaller “latent” form before sending them to the experts, then expands them back afterward.
- Analogy: Instead of mailing a thick folder to many specialists, you send a slim summary. Saving time and space lets you use more experts at once, which improves quality without slowing things down.
Multi-Token Prediction (MTP)
- The model learns to predict several future words at once, not just the next one.
- Analogy: Like drafting multiple words ahead so you can type faster and plan your sentence better.
- This helps the model think several steps ahead and speeds up generation (it works well with “speculative decoding,” a technique that accepts drafts quickly when they look correct).
NVFP4 Training (Efficient number format)
- Computers store numbers with different “precisions.” NVFP4 is a very compact number format that runs fast on NVIDIA chips.
- The team used NVFP4 to train huge models efficiently, while keeping a few sensitive parts in higher precision to avoid losing important details.
- Analogy: Using a smaller, faster ruler for most measurements, and a precise ruler for tricky parts.
Long Context (Up to 1 million tokens)
- “Context length” is how much text the model can consider at once.
- Nemotron 3 supports extremely long inputs (up to 1 million tokens), useful for:
- large code repositories,
- deep conversation history,
- multi-document research and retrieval (RAG pipelines).
- Because it relies more on Mamba-2 (which doesn’t depend on certain position tricks that break at long lengths), it handles long context more reliably.
Multi-Environment Reinforcement Learning (RL)
- RL teaches the model by letting it try tasks and learn from rewards (like points for correct answers or good behavior).
- Nemotron 3 trains on many kinds of tasks at the same time: math, code, tool use, instruction following, search, long context, and chat.
- This “all at once” approach helps the model grow many skills together without forgetting others.
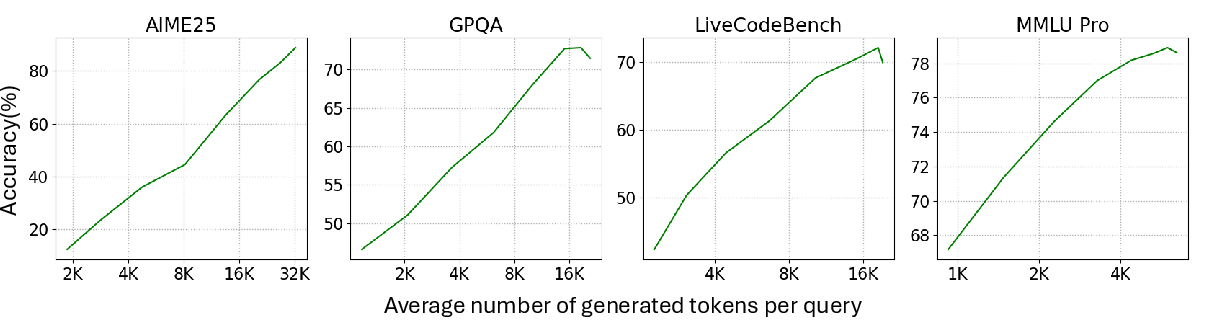
Reasoning Budget Control (User control at inference time)
- You can set a “thinking budget”: how many tokens the model should spend thinking before answering.
- If you cut the budget, you get faster replies; if you extend it, you may get better accuracy.
- Analogy: Asking a student for a quick answer vs. giving extra time for a detailed solution.
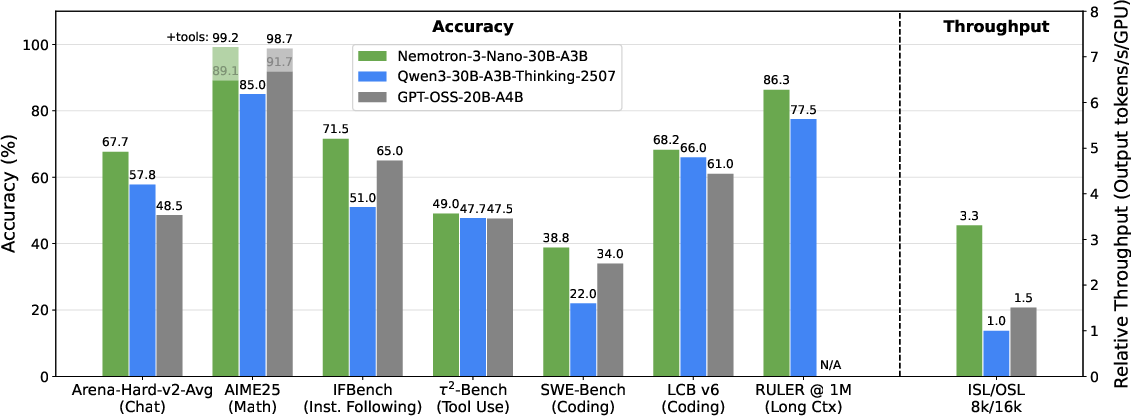
Main Results and Why They Matter
Here are the key takeaways from the paper’s experiments and engineering:
- Faster and more efficient:
- The Nano model is about 3.3× higher throughput than a similarly sized model (Qwen3-30B) on common reasoning tasks.
- MTP allows faster text generation with high acceptance of its “draft” predictions.
- Better accuracy with LatentMoE:
- LatentMoE consistently beats standard MoE across many benchmarks (general knowledge, code, math, and commonsense).
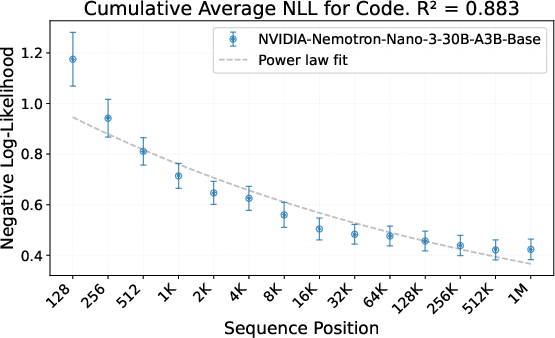
- Long-context reliability:
- Nemotron 3 keeps performing well as inputs get extremely long (up to 1M tokens), with smoother quality at long lengths than previous designs.
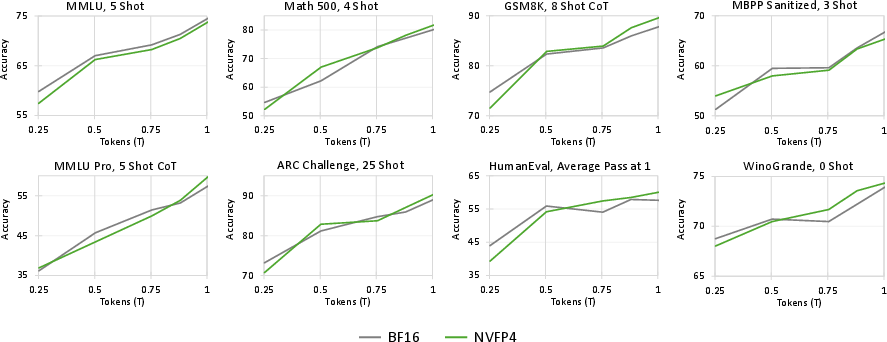
- Efficient training with NVFP4:
- Using compact numbers didn’t significantly hurt performance, especially as models get larger—meaning big speed/cost savings with similar accuracy.
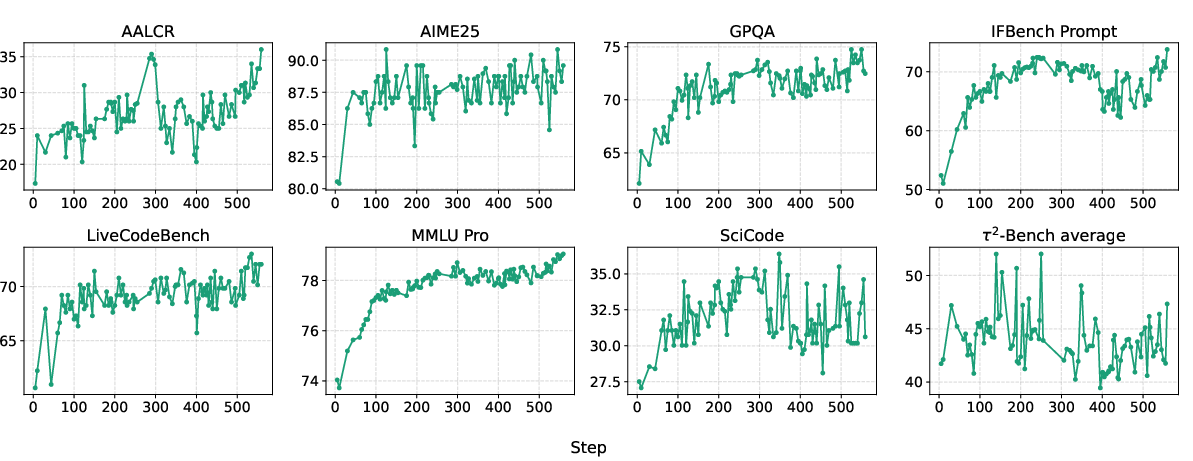
- Strong, broad capabilities from multi-environment RL:
- Training on many tasks together steadily improved performance in agentic tool use, reasoning, coding, and more.
- Practical control:
- Reasoning budget control lets users choose speed vs. depth for different needs.
What This Means Going Forward
Nemotron 3 shows that you can build AI models that:
- think well,
- respond fast,
- handle huge inputs,
- and are flexible enough for many real-world jobs (like automating IT tickets, coding help, research assistants, and multi-agent systems).
Because NVIDIA plans to openly release the models, code, training recipes, and most data, researchers and developers can:
- study how these models work,
- reproduce results,
- build on them to make new tools,
- and customize them for their own applications.
In short, Nemotron 3 could make powerful, efficient AI more accessible and practical—especially for tasks that need long memory, careful reasoning, and high-speed generation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Architecture disclosure and ablations for Super and Ultra are deferred; concrete layer patterns, expert counts, attention placement, and full training recipes for the larger models are not yet available for independent verification.
- Lack of systematic ablations on the hybrid Mamba–Transformer MoE design (e.g., number and placement of attention layers, ratio of Mamba to MoE, gating strategies) across diverse tasks and sequence length regimes to identify optimal patterns and failure modes.
- No analysis of tasks that may inherently depend on dense all-to-all attention at long ranges (e.g., cross-document relational reasoning), where sparse attention layers might bottleneck performance compared to dense Transformers.
- Unclear limits of 1M-token context: practical memory footprint, latency, throughput, and cost on real hardware for typical batch sizes; guidance for production serving (p50/p95/p99 latency, tail behavior) is missing.
- Missing evaluation of very-long-context utility beyond code: does NLL vs. position improve similarly for legal, biomedical, multilingual, or noisy web domains up to 1M tokens?
- Absence of long-context RL beyond 32k tokens; unclear whether capabilities trained at 32k extrapolate to robust tool-use and planning at 1M tokens without degradation.
- No head-to-head comparisons at 1M tokens on competitive long-context benchmarks versus leading long-context baselines, under identical hardware and decoding settings.
- RoPE removal in attention layers is asserted to help context extension, but there is no ablation on alternative position encodings or on whether attention layers without explicit positional signals degrade specific skills.
- LatentMoE design lacks sensitivity studies: how do performance, stability, and communication scale with the latent ratio d/ℓ, expert counts N′, top-K K′, and projection sizes across tasks and model scales?
- Unclear robustness of LatentMoE to expert collapse, routing skew, or capacity saturation; load-balancing objectives, entropy regularization, or gating-temperature schedules are not specified or ablated.
- No study of information loss or representation bottlenecks introduced by projecting to latent space for expert computation, especially for highly entangled features (e.g., multilingual, code syntax trees).
- Communication/system-level characterization of LatentMoE is limited: end-to-end all-to-all utilization, NIC saturation, topology awareness, and expert parallelization strategies on multi-node clusters are not reported.
- MTP design details are under-specified (e.g., number of predicted tokens, loss weighting, layer attachment points) and lack ablations on how each choice affects accuracy, calibration, and latency.
- Speculative decoding with MTP: acceptance rates beyond the first two tokens, quality under rejections, effects on error compounding, and domain-specific acceptance dynamics are not quantified.
- Interaction effects between MTP and RL (e.g., whether auxiliary multi-token heads improve or distort reward optimization, tool-use reliability, or chain-of-thought faithfulness) remain unexplored.
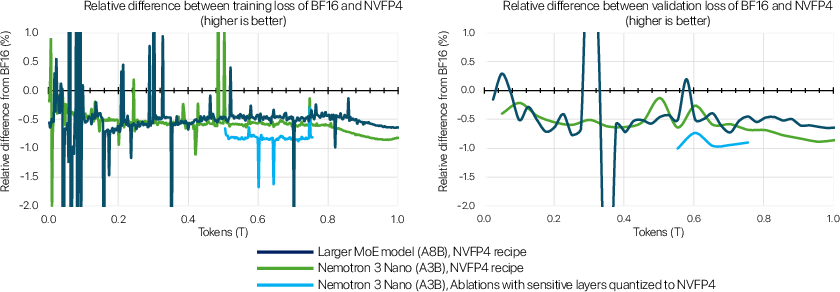
- NVFP4 training is shown to match BF16 loss closely, but the paper lacks failure-case analyses (e.g., gradient underflow/overflow regimes, rare-mode instabilities, catastrophic outliers) and recovery strategies at scale.
- No generalized procedure for selecting mixed-precision “safe” layers (QKV, attention projections, Mamba output projections, MTP); guidelines for other architectures or different scales are absent.
- Downstream evaluations for NVFP4 are only shown at 1T tokens on an 8B-active MoE; it is unclear whether parity persists at longer training horizons (e.g., 10T–25T), larger models, or safety-sensitive tasks.
- Energy efficiency and carbon impact of NVFP4 vs. FP8/BF16 (training and inference) are not quantified; power, thermal constraints, and throughput-per-watt comparisons are missing.
- Multi-environment RL setup is under-specified: per-environment reward design, aggregation/weighting policies, credit assignment across tools, safety constraints, and prevention of reward hacking lack transparency and ablations.
- No controlled attribution of gains across post-training components (SFT data, RL environments, MTP, long-context data); contribution analyses are needed to guide future optimization.
- Generalization and robustness gaps: performance on out-of-domain, adversarial, multilingual, low-resource, or distribution-shifted tasks—especially for long-context reasoning and tool-use—are not reported.
- Safety and alignment evaluations are not detailed: red-teaming coverage, jailbreak resistance, tool-use safety, refusal consistency under budget control, and chain-of-thought leakage policies are unspecified.
- Reasoning budget control lacks formal analysis of trade-offs: how partial thinking traces affect correctness, calibration, hallucination rates, and safety; robustness to adversarial or mistimed budget truncations.
- No per-task guidance for setting budgets (e.g., math vs. code vs. tool-use), nor adaptive controllers that modulate budget during inference based on uncertainty or difficulty signals.
- Throughput comparisons (e.g., 3.3× vs. Qwen3-30B-A3B) lack standardized measurement protocols: decoding parameters, hardware topology, batch sizes, KV cache precision, and end-to-end server overheads are not fully specified.
- Benchmark contamination safeguards and data provenance for evaluations (code, math, long-context) are not described, especially given the planned release of >10T tokens of training data.
- Data licensing and redistribution constraints are only broadly stated; replicability risks exist if critical datasets used in training/evaluation cannot be redistributed or are later retracted.
- Tool-use and multi-agent capabilities are claimed but not deeply evaluated: standardized agentic suites, compositional tool chains, inter-agent coordination metrics, and error taxonomies are absent.
- Memory planning for 1M contexts (KV cache for the few attention layers, activation checkpointing, paging/offloading strategies) is not documented; practical server sizing recommendations are missing.
- Cross-lingual and code-domain evaluations do not include live or contamination-controlled benchmarks (e.g., LiveCodeBench, multilingual long-context QA) under the presented long-context and MoE settings.
- Maintainability and upgrade paths are unclear: how do NVFP4-trained models behave under continued training, domain adaptation, or quantization for edge deployment without regressing long-context or RL-tuned capabilities?
- Open question on interoperability: how well do Nemotron 3 models plug into external RAG, vector DBs, and tool ecosystems under 1M context, and what retrieval strategies best complement the hybrid architecture?
Practical Applications
Below is an analysis of the paper’s findings and technologies translated into practical, real-world applications. Each item specifies sectors, potential tools/products/workflows, and assumptions or dependencies that may affect feasibility.
Immediate Applications
The following applications can be piloted or deployed now, primarily with Nemotron 3 Nano (released) and the open software stack (e.g., NeMo-RL and NeMo-Gym). Where Super/Ultra deliver additional gains (e.g., via LatentMoE or MTP), these are noted as near-term upgrades upon their release.
- Bold long-context RAG for enterprise knowledge and compliance (finance, legal, healthcare, energy, public sector)
- Description: Build retrieval-augmented generation systems that feed hundreds of thousands to 1M tokens (policies, contracts, filings, standards, EHR excerpts) into a single prompt for accurate summarization, cross-document reasoning, and traceable answers.
- Tools/products/workflows:
1M-Context RAGpipelines with chunking + hierarchical indexing; streaming context loaders; memory-aware batching; long-context evaluation harness (RULER-like).- Governance dashboards for citation tracking and redaction.
- Assumptions/dependencies:
- GPUs with sufficient memory and IO bandwidth; careful prompt window management to control cost; data privacy controls; robust document parsing at scale.
- Bold repository-scale code assistants (software)
- Description: Assist with refactors, dependency audits, security reviews, and migration planning over entire repos (hundreds of thousands to 1M+ tokens) using the model’s long-context capability and reasoning RL.
- Tools/products/workflows:
Repo-wide Assistantthat ingests full codebases, generates cross-file suggestions, PR diffs, test scaffolds; integrates CI/CD hooks and code owners.- Assumptions/dependencies:
- Efficient source indexing + context packing; guardrails for code safety; IP and license compliance.
- Bold high-throughput IT ticket and operations automation (ITSM, support operations, PSA)
- Description: Classify, de-duplicate, route, and resolve tickets; propose steps; generate change records; handle multi-step tool use (search, KB lookup, command invocation) due to multi-environment RL.
- Tools/products/workflows:
Ticket Orchestratoragent that calls CMDB, KB, status pages; uses function calling and multi-step tool-use policies learned via RL.- Assumptions/dependencies:
- Tool/API integration (service desk, monitoring, CMDB); audit trails; role-based access; early deployments can use Nano; Super is optimized for these workloads when available.
- Bold collaborative agent workcells for SOC triage and incident response (security, operations)
- Description: Parallel agent teams for alert triage, investigation steps, enrichment, and containment playbooks—leveraging model throughput and tool use.
- Tools/products/workflows:
SOC Workcellwith one agent for enrichment, one for hypothesis generation, one for action proposals; human-in-the-loop approvals.- Assumptions/dependencies:
- Reliable function calling; network segmentation and least-privilege execution; strong auditability and reversible actions.
- Bold reasoning budget control for cost-governed inference (all SaaS, platform teams)
- Description: A “deliberation slider” that bounds chain-of-thought tokens at inference time to trade accuracy for latency/cost on-demand (e.g., batch tier vs premium tier).
- Tools/products/workflows:
Budget-Aware Inference Gatewaythat sets per-request thinking caps; A/B tests for optimal accuracy–cost curves.- Assumptions/dependencies:
- Model variants trained for budget control (as in Nemotron 3); clear UX for cost-vs-quality; monitoring for task-specific inflection points.
- Bold long meeting, call-center, and case-history summarization (CX, sales, legal, healthcare)
- Description: Summarize multi-hour transcripts or long case files; extract action items, risk, compliance clauses; maintain long-running context across sessions.
- Tools/products/workflows:
Conversation Memorywith sliding windows + anchor summaries; role-based views; redaction and PHI/PII handling.- Assumptions/dependencies:
- Reliable diarization and ASR; data retention and privacy controls; latency budgets for very long prompts.
- Bold domain-adapted pretraining/fine-tuning with NVFP4 recipes (model builders, academia, labs)
- Description: Use NVFP4-based training recipes to reduce cost/time for custom domain models (e.g., biomedical, legal) with minimal quality loss.
- Tools/products/workflows:
NVFP4 Trainerpipelines using Transformer Engine + cuBLAS; quantization-aware training and checkpoint conversion utilities.- Assumptions/dependencies:
- Access to Blackwell-class hardware (e.g., GB300) and software stack; adherence to precision exceptions (BF16/MXFP8 layers) per the paper’s recipe.
- Bold transparent, replicable post-training via NeMo-RL and NeMo-Gym (academia, research, startups)
- Description: Build and study multi-environment RL for reasoning, math, coding, and tool use with open environments and training code.
- Tools/products/workflows:
Open RL Labfor GRPO training, masked importance sampling, rollout replay; standardized agentic benchmarks and eval harnesses.- Assumptions/dependencies:
- Sufficient compute for large-scale rollouts; reward design that avoids hacking; benchmark hygiene to prevent contamination.
- Bold cost-effective on-prem and VPC deployments (regulated industries)
- Description: Deploy open-weight Nemotron 3 Nano within private infrastructure for sensitive workloads (e.g., PHI/PII, trade secrets).
- Tools/products/workflows:
Private Inference Stack(Triton/vLLM-style serving) with rate-limiting, audit logging, and secret-scoped tool adapters.- Assumptions/dependencies:
- Confirm license terms for weights and data; capacity planning for long contexts; compliance attestations and DLP.
- Bold structured data and form-intensive workflows (back-office automation)
- Description: Extract, validate, and cross-check fields across very long PDFs and spreadsheets; reconcile conflicts with tool calls (search/lookup).
- Tools/products/workflows:
DocOps Agentthat performs multi-pass extraction, cross-document checks, and generates exception reports.- Assumptions/dependencies:
- Robust parsing; OCR quality for scans; human review thresholds for high-stakes fields.
Long-Term Applications
These require further model releases (Super/Ultra), scaling, systems engineering, validation, or regulatory approvals. The paper’s innovations (LatentMoE, MTP, NVFP4, 1M context, multi-environment RL) make these increasingly feasible.
- Bold MTP-driven ultra-low-latency assistants at scale (platforms, consumer apps)
- Description: Leverage integrated MTP + speculative decoding in Super/Ultra for consistently sub-100ms token latencies and long-form generation speedups.
- Tools/products/workflows:
Spec-Decoding Routerthat exploits high acceptance of early drafts; multi-tenant autoscaling.- Assumptions/dependencies:
- Availability of Super/Ultra; serving kernels supporting MTP heads; end-to-end latency budget including network.
- Bold autonomous software maintenance copilot (software, DevOps)
- Description: Multi-agent system that plans refactors, drafts PRs, updates configs, writes tests, and rolls out changes with risk-aware gates.
- Tools/products/workflows:
Repo Stewardwith policy-as-code for approvals; continuous evals on code quality and security.- Assumptions/dependencies:
- High-precision function calling; sandboxed execution; robust rollback and auditability; organization buy-in.
- Bold longitudinal clinical decision support (healthcare)
- Description: Contextualize full patient histories (notes, labs, imaging reports) for guideline-concordant suggestions and risk flags over 1M-token spans.
- Tools/products/workflows:
Longitudinal CDSwith evidence links, contraindication checks, billing code support.- Assumptions/dependencies:
- Regulatory validation (FDA/CE); strict privacy; domain-aligned training and calibration; bias and safety mitigations.
- Bold automated e-discovery and litigation strategy (legal)
- Description: End-to-end ingestion of massive discovery corpora with argument maps, counterfactuals, and citation graphs.
- Tools/products/workflows:
Discovery Navigatorthat aligns threads across custodians and time; counsel-in-the-loop sampling for verification.- Assumptions/dependencies:
- Court-acceptable audit trails; accuracy guarantees; reproducible queries; cost controls for 1M-token contexts.
- Bold enterprise digital twins with agent teams (manufacturing, logistics, energy)
- Description: Multi-agent orchestration to simulate, plan, and optimize operations using logs, manuals, and real-time telemetry; RL-improved policies.
- Tools/products/workflows:
Agentic Twinwhere planning, forecasting, and control agents collaborate; scenario stress-testing.- Assumptions/dependencies:
- Reliable tool APIs; safety interlocks; data latency constraints; change-management gates.
- Bold grid operations intelligence over long telemetry and incident logs (energy)
- Description: Forecast, anomaly detection, and root-cause narratives across months of SCADA, maintenance, and weather data.
- Tools/products/workflows:
GridOps Copilotwith playbook generation for disturbances; post-incident analyses.- Assumptions/dependencies:
- Integrations with OT systems; strict cybersecurity; validation on historical incidents.
- Bold policy analysis at government scale (public sector)
- Description: Read full bills, amendments, economic analyses, and public comments to produce comparative summaries, impact assessments, and drafting suggestions.
- Tools/products/workflows:
Policy Workbenchwith provenance and dissent/edge-case surfacing; multilingual handling.- Assumptions/dependencies:
- Transparent sourcing; bias analysis; human oversight; legal provenance requirements.
- Bold privacy-preserving continuous personal memory (consumer, productivity)
- Description: An on-device or private-cloud assistant maintaining years of notes, email, documents within a rolling million-token memory for truly contextual help.
- Tools/products/workflows:
Personal Context Vaultwith retrieval policies, forgetting/retention controls, and budget-aware answers.- Assumptions/dependencies:
- Efficient edge inference (likely Nano-class); strong local indexing; privacy UX; storage encryption.
- Bold model-training cost collapse via NVFP4 at ever-larger scales (model builders, cloud)
- Description: Extend NVFP4 recipes to train larger MoE hybrids and domain-specialized models with near-BF16 quality at materially lower cost/carbon.
- Tools/products/workflows:
FP4-at-Scalepipelines with precision-aware layer exceptions; automated stability checks.- Assumptions/dependencies:
- Broad hardware/software availability; generalized stability across architectures; kernel maturity.
- Bold pricing and SLO tiers based on reasoning budgets (platform economics)
- Description: Offer SKUs tied to explicit thinking-token caps and latency/accuracy guarantees.
- Tools/products/workflows:
Reasoning-SLO Managerthat enforces budgets and reports per-task accuracy/cost tradeoffs.- Assumptions/dependencies:
- Predictable accuracy–budget curves per domain; customer education; fair-use and abuse monitoring.
- Bold robotics and embodied agents with tool-API planning (robotics, industrial automation)
- Description: High-throughput planning and step-by-step tool invocation for inspection, repair, or warehouse tasks, with human approval.
- Tools/products/workflows:
Embodied Orchestratorbridging perception, planning, and actuation; offline simulation-to-real loops.- Assumptions/dependencies:
- Safety certification; reliable low-level control; latency constraints for closed-loop control.
- Bold financial risk/compliance analytics on long filings and rulebooks (finance)
- Description: Cross-reference positions, contracts, and regulatory changes across very large corpora to surface compliance gaps and what-if scenarios.
- Tools/products/workflows:
RegRisk Copilotwith traceable rationales and change impact matrices.- Assumptions/dependencies:
- Up-to-date rule ingestion; stringent accuracy thresholds; model governance and approvals.
Cross-cutting dependencies to monitor
- Networking and parallelism: LatentMoE increases expert count/top-K; all-to-all performance hinges on GPU interconnects (NVLink/InfiniBand) and cluster topology.
- Serving stack: Efficient Mamba-2 kernels, KV/state management, and scheduler support for very long contexts; MTP-aware serving for Super/Ultra.
- Data governance: Licensing for weights/data; contamination-free evaluation; safety and bias mitigations for high-stakes domains.
- Cost control: 1M-token contexts are powerful but expensive; use compression, hierarchical prompting, and budget control to bound spend.
- Tool-use reliability: Function calling schemas, sandboxing, and robust error recovery are essential for agentic workflows.
These applications translate the paper’s technical advances—hybrid Mamba–Transformer MoE, LatentMoE, MTP, NVFP4 training, 1M-token contexts, multi-environment RL, and inference-time budget control—into concrete products and workflows across industries, academia, policy, and daily life.
Glossary
- All-to-all communication: A distributed communication pattern where data is exchanged among all devices; in MoE, it routes tokens to experts and aggregates results, often becoming a bottleneck at high throughput. "the all-to-all communication required to dispatch tokens to experts and aggregate results emerges as the primary bottleneck."
- Asynchronous RL architecture: A reinforcement learning system design that decouples training from inference to improve sampling efficiency and scalability. "we employ an asynchronous RL architecture that decouples training from inference"
- BF16: Bfloat16, a 16-bit floating-point format commonly used for efficient training and evaluation with reasonable numeric range and precision. "Evaluations are performed in BF16."
- Block scaling: Quantization technique that applies a shared scaling factor to blocks of values to preserve dynamic range under low-precision formats. "block scaling factors with E4M3 format"
- Continued pre-training (CPT): An additional pretraining stage (often at longer sequence lengths or specialized data) to extend or refine model capabilities. "we included a continued pre-training (CPT) stage at a 512k sequence length"
- cuBLAS: NVIDIA’s CUDA Basic Linear Algebra Subroutines library providing optimized GPU primitives used here as a backend for transformer operations. "leveraging cuBLAS's backend for Transformer Engine."
- Flush-to-zero: Floating-point behavior where very small values underflow to zero, potentially losing information in low-precision formats. "Mamba output projection layers have high flushes to zero (up to 40% on Nano) when quantized to NVFP4."
- E2M1 (element format): A low-precision floating-point element format with 2 exponent bits and 1 mantissa bit used in NVFP4 tensors. "and the E2M1 element format."
- E4M3 (format): A floating-point format with 4 exponent bits and 3 mantissa bits, used for block scaling factors in NVFP4. "block scaling factors with E4M3 format"
- Gating network: The MoE routing mechanism that decides which experts process each token. "including the MoE routing gate (gating network)"
- GEMM: General Matrix-Multiply operations that underpin neural network layers and are optimized for different precisions. "NVFP4 GEMMs in fprop, dgrad, and wgrad."
- GQA: Grouped Query Attention, an attention variant that groups queries to reduce memory/computation while maintaining fidelity. "each attention layer uses GQA with only 2 KV heads."
- GRPO: A reinforcement learning algorithm (used here with masking) designed for stable optimization of LLMs. "we use GRPO \citep{deepseek-math} with masked importance sampling"
- KV Cache: The stored keys and values from prior tokens used by self-attention to enable efficient autoregressive generation. "which need to attend over a linearly increasing KV Cache during generation"
- KV heads: The number of key/value attention heads controlling memory and computation in attention layers. "GQA with only 2 KV heads."
- Latent dimension: A reduced-dimensional representation () used to perform expert routing and computation more efficiently. "a latent representation of smaller dimension "
- Latent space: The compressed representation space where LatentMoE experts operate to reduce communication and parameter loads. "operate entirely in this latent space"
- LatentMoE: A hardware-aware MoE design that projects tokens into a smaller latent space to increase expert count and top-K while keeping cost roughly constant. "LatentMoE is a novel architecture that implements this strategy."
- Mamba-2: A state-space model layer used as a cheaper alternative to attention, with constant memory during generation. "cheaper Mamba-2 layers— which require storing only a constant state during generation."
- Masked importance sampling: A variance-reduction technique in RL where sampling weights are adjusted and masked to account for policy discrepancies. "we use GRPO \citep{deepseek-math} with masked importance sampling"
- Micro-block scaling: Fine-grained quantization scaling applied to very small blocks (e.g., 16 elements) to maintain numeric stability. "fine-grained (16 element) micro-block scaling"
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of specialized expert networks, enabling sparse activation and scaling. "Mixture of Experts (MoE) layers face fundamentally different performance bottlenecks depending on the scenario."
- Multi-environment RL: Reinforcement learning across diverse tasks/environments trained simultaneously to improve broad capabilities. "The utility of multi-environment RL can be seen in Figure \ref{fig:multi-env-rl}"
- Multi-Token Prediction (MTP): Training/generation technique where the model predicts multiple future tokens, improving reasoning and enabling speculative decoding. "Multi-Token Prediction (MTP) has emerged as a highly effective technique"
- MXFP8: A mixed-precision FP8 format used selectively to preserve information when NVFP4 causes underflow. "we keep these layers in MXFP8."
- Negative log-likelihood (NLL): A standard probabilistic loss metric measuring how likely the model assigns the correct tokens. "we measure the negative log-likelihood (NLL) of tokens at various positions"
- NVFP4: NVIDIA’s 4-bit floating-point training format with specialized scaling designed for high-throughput, low-precision training. "using the NVFP4 number format."
- Random Hadamard Transforms (RHTs): Orthogonal transforms applied to inputs (e.g., before wgrad) to improve quantization robustness. "Random Hadamard Transforms (RHTs) on inputs to wgrad"
- RoPE: Rotary Position Embeddings, a positional encoding method that can hinder ultra-long context extension beyond training lengths. "Rotary Position Embeddings (RoPE) are a known hurdle to extending context beyond the training length."
- Rollout generation: The process of sampling trajectories/sequences from the model-environment interaction during RL. "accelerate rollout generation."
- RULER: A long-context benchmark evaluating retrieval and reasoning over very large input sequences. "RULER on 1M token input sequences"
- Speculative decoding: A generation acceleration technique where draft tokens are proposed and accepted by the main model to reduce latency. "delivering substantial speculative-decoding benefits"
- Sparse parameter scaling: Increasing capacity/accuracy by activating only a subset of parameters per token (as in MoE). "mixture-of-expert layers that allow for sparse parameter scaling"
- Stochastic rounding: A probabilistic rounding scheme that reduces bias in low-precision arithmetic. "and stochastic rounding on gradients."
- Supervised fine-tuning (SFT): Post-pretraining supervised training stage to align models to desired behaviors and tasks. "supervised fine-tuning (SFT) was performed at a 256k sequence length."
- Top-K active experts: The number of experts selected per token in MoE routing, impacting communication and nonlinearity. "the number of top- active experts "
- Transformer Engine: NVIDIA’s library/framework that orchestrates mixed-precision and optimized kernels for transformer training. "leveraging cuBLAS's backend for Transformer Engine."
Collections
Sign up for free to add this paper to one or more collections.